
基于SVM、TSVM与ELM的图像检索算法对比研究
2015-04-29 00:44:03张志强刁琦张太红
智能计算机与应用 2015年3期
张志强 刁琦 张太红


摘 要:分类算法应用于图像检索中,可有效解决图像检索中的分类问题,缩小低层特征与高层特征之间的鸿沟,提高检索精度。以图像颜色与纹理特征并结合图像分块特征作为低层综合特征,借鉴词袋(Bag of Words)模型,利用K均值(K-means)聚类算法,分别采用支持向量机(SVM)、直推式支持向量机(TSVM)以及极限学习机(ELM)三种学习机制,对corel图像库进行分类检索。实验表明,ELM分类器的识别准确率高于SVM和TSVM分类器,且检索速度快。
关键词:图像分块;词袋模型;K均值;SVM;TSVM;ELM
中图分类号:TP393 文献标识码:A 文章编号:2095-2163(2015)03-
Study of Image Retrieval Algorithm based on SVM, TSVM and ELM
ZHANG Zhiqiang, DIAO Qi, ZHANG Taihong
(Institute of Computer and Information Engineering,Xinjiang Agricultural University, Urumqi 830052,China)
Abstract : Classification algorithm is applied to image retrieval, which can effectively solve the problem of classification of image retrieval, narrowing the gap between low-level features and high-level features, improve the retrieval precision. In image color, texture features combined with the feature of image content features as low comprehensive, draw lessons from the word Bag (Bag of Words) model, using k-means (K - means algorithm, support vector machine (SVM) were used respectively, straight push support vector machines (TSVM) with extreme learning machine (ELM) three learning mechanism, classifying corel image database retrieval. Experiments show that the ELM classifier recognition accuracy is higher than the SVM and TSVM classifier, and the retrieval speed.
Keywords: Image Block; Bag of Words; K-Means ; SVM; TSVM; ELM
0 引 言
伴随着互联网和多媒体技术的蓬勃发展,传统的以文本为基础的图像检索技术,因为完全依靠人工标注,工作量很大并且存在一定程度上的主观性。以内容为基础的图像检索技术,借助于视觉特征和其它许多领域学科,实现了方便、快速、准确的查询与检索。基于内容的图像检索,提取图像的低层特征与语义特征,更加全面地描述了图像信息,为检索准确率提供了客观且可靠的算法依据。机器学习在图像检索中的应用,缩小了底层特征与高层语义之间的鸿沟,从以计算机为中心转向以用户为中心,使得检索结果更加吻合用户的检索意图。
研究可以简单地将图像检索技术看成是二分类的问题。通过对学习机制的应用,大大提高了图像检索的准确性。在1995年, Vapnik及其合作伙伴提出支持向量机的方法,支持向量机(SVM)技术在以下三个方面表现出很好的优势:(1)小样本;(2)非线性;(3)高维度模式识别。SVM分类器技术被业界普遍认为是一种比较有效的分类技术之一[1]。针对传统意义上支持向量机(SVM)技术的不足之处,Vapnic及其工作人员对支持向量机(SVM)进行了发展,进一步提出了直推式支持向量机(TSVM)[2],这种技术在一定程度上提高了测试集的分类性能,但存在很难求得SVM最优解的问题。Huang等提出极限学习机神经网络训练框架,即ELM(Extreme Learning Machine),其学习速度快,泛化性好,已广泛应用在分类问题[3]。
本研究从图像提取颜色特征和纹理特征,并且结合图像的分块综合特征,实现综合底层特征的SVM、TSVM以及ELM三种分类算法的图像检索技术的仿真,同时又进行了三种分类算法的对比。在本实验中,颜色特征采用HSV非均匀量化颜色直方图,纹理特征采用灰度共生矩阵,而将MATLAB2013a选取作为仿真软件。
1特征选择
1.1颜色空间选取及量化
以颜色为基础的图像检索系统技术具有良好的鲁棒性和实用性,以HSV的颜色特征为基础的图像检索算法使用全局的颜色特征来进行检索,这种算法思路对于图像的旋转、图像的平移、图像的尺度变化依赖性比较小,具有很好的鲁棒性,由于图像颜色特征的提取算法比较容易实现,因此这种算法在图像检索领域中表现出相当可观的适用性[4]。
RGB的颜色空间是最基础性的高频常用颜色空间。同时,这也是最不均匀的颜色空间之一。所以,RGB色彩空间并不符合人类对色彩空间的感知。然而,HSV的色彩空间是一种面向人类视觉感知的空间模式,其三个要素是:H(色调)、S(饱和度)、V(亮度)比较符合人类眼睛对色彩的感知。HSV的色彩空间的亮度分量与其色彩信息没有任何关系,并且相应色调及饱和度均符合人类对色彩的感知。实验时,需要将RGB的立方体色颜空间转换为更符合人类眼睛色彩视觉的HSV(纺锤体色颜空间)。
为了降低高维度特征计算的复杂度,研究应该把各种颜色归纳到具有代表的颜色上。这样,就需要对HSV(纺锤体色彩空间)进行数学量化。研究中,将HSV (纺锤体色彩空间)的3个分量量化为16、4、4的等级。具体量化公式如下:
(1)
(2)
(3)
把H(色调)、S(饱和度)、V(亮度)这三个分量合成为一个具有代表性的特征向量L:
(4)
其中,Qs、Qv分别是S和V的量化级数。取Qs=4、Qv=4,得
(5)
L的取值范围为[0,1,…,255],共256种颜色。量化以后的特征向量大大弱化了S(饱和度)分量和V(亮度)分量对检索结果的影响。
1.2灰度共生矩阵
在1973年,Haralick及其工作人员从统计学的角度,发展出了灰度共生矩阵方案。灰度共生矩阵方法被业界公认为行之有效的方法,与其它方法相比,灰度共生矩阵方案具有较强的适应能力和鲁棒性[5]。
假如f(x,y)是一幅灰度类别的图像,从图像中选取任一小片区域R,并定义S为所选区域中具有特定空间联系的像素对的集合。那么,灰度共生矩阵可表示为:
(6)
其中, 为图像中任意像素和其它相邻像素距离方向和水平方向的夹角, 为对应的偏离距离。有 ,
另有, 表示在集合 中对 有贡献的数目。
在实际应用中,为减小计算量,需对式(4)进行归一化,即如式(7)所示:
(7)
为了减少计算中θ的方向个数,同时降低计算的复杂度,研究通常需要计算θ分别取值为00、450、900、1350这四个方向上的灰度共生矩阵。根据在共生矩阵基础上提取的数字统计量,在此主要选取五种描述纹理统计量,分别为:能量、相关性、熵、对比度,逆差矩。
2学习机制
2.1 SVM
支持向量机(SVM)技术是一种以统计学习理论为基础的数据挖掘方法[6]。构建一个最优超平面,使得离超平面最近的不同的样本点之间的间隔最大,并且有效控制VC维大小,与此同时进一步降低机器学习的复杂度是它的主要思想。本文技术在解决小样本问题方面具备显著优势。当进行小样本训练的时候,并不需要拥有特定问题的前期知识,就可以很好地控制学习机器的推广能力。因此,这项技术在图像检索中可以有效提高检索的准确性能[7]。
在分类的技术问题上,SVM技术解决了在低维特征空间不可分类的问题,使高维空间变得可分。误差惩罚参数C和核函数形式及其参数设置[8]则是影响SVM分类器的两个关键因素。选择不同的核函数或者对相同的核函数设置不同参数对其分类性能都可以产生一定影响。这里使用MATLAB自带的Libsvm软件包,根据训练图片特征构造出训练模型,实现对测试图像样本的预测。线性核、多项式核以及RBF核是常用的核函数,一般情况下,我们选择RBF核及径向基核函数。
2.2 TSVM
传统支持向量机技术(SVM)需要首先依据训练样本集归纳总结出分类函数,而后利用上面归纳总结出的分类函数对测试集样本的类别进行划分。相对于传统支持向量(SVM)机,直推式支持向量机(TSVM)可以直接利用已知样本集对测试集样本类别进行估计[9]。大批量的无标签样本可以更好地刻画样本空间的数据特性,这一点使得训练的分类获得了更好的推广性能[10]。
研究给出了独立同分布的具有标签的训练数据集(x1*,y1*),…,(xn*,yn*),y∈{-1,1},与来自同一分布的无标签数据x1,…,xn,在线性不可分的情况下,可以把直推式支持向量机的学习描述为优化问题: (8)
研究可知,这是一个NP问题。对于大批量的无标签样本,将很难求出全局的最优解[11]。为了解决这个问题,可以结合K均值聚类算法来考虑。这样,就不仅提高了全局的搜索性能,同时还加快了收敛的速度。
2.3 ELM
对于前馈神经网络(BP)的输入层,连接的权值不需要迭代调整。Huang提出了极限学习机(ELM)。极限学习机(ELM)具有速度快、泛化性好的特点,所以,已经大规模地实施应用在分类问题[12]上。对于给定的含有N个不相同的训练集样本集 ,并且给出前馈网络的激活函数g(x)以及隐含层节点数L,那么,极限学习机算法步骤如下[13]:
(1)随机给出网络隐含层的连接权值:
(9)
(2)计算隐含层的输出矩阵H。
(3)输出权值β的正则化最小二
乘解:
(10)
由此,即可用下面公式来表示极限学习机的分类过程:
(11)
3 改进算法
3.1 图像分块特征
由于色彩空间的分布存在区分性,基于此,可将图像分成若干个子块[14]。由于分块图像具有良好的旋转、平移、尺度和变形不变性,所以,适合作为研究对象。因此,研究得到的检索结果更能符合人类的视觉特性。图像的空间分布信息对图像相似性的判断影响比较大,同时,图像分块确实又注重图像的空间分布信息,三者结合起来将能更加全面地描述图像信息,使得检索结果更趋准确可靠。为了使用标准的SVM学习和检索,研究则将Bag of Words模型应用到图像检索中。
3.2 Bag of Words算法描述
Bag of Words算法,是一种基于语义特征提取与描述的、有效的物体识别算法,具体起源于基于语义的文本检索算法。基本思想是:对于一个文本,忽略其词序和语法、句法,仅仅将其看作是一些词汇的集合,并且文本中的每个词汇都是独立的[15]。类似于文本分类算法,Bag of Words算法首先要提取图像的特征点信息,然后通过描述方式将其转化为特征描述符(也即:图像的所有局部特征),然后,利用K-Means方法对描述符进行聚类分析,就可以得到每个类的聚类中心,所有的聚类中心的集合便成为视觉词汇,最后利用机器学习的方法对多个类别的描述符进行训练。其算法包括三个步骤:(1)提取描述符;(2)生成视觉单词;(3)分类识别。大规模图像检索中应用Bag of Words模型,不仅可以大大减小计算量,而且检索效果较佳。
3.3 Bag of Words模型
Bag of Words模型源于表示文档方法,实质是文档中任意位置出现的任何单词,都不受文档语意影响而独立选择。每个文档可以用一个N维向量进行表示,使用计算机工具完成海量文档的分类问题。
研究将Bag of Words模型应用在图像表示,为了能表示一幅完整图像,需要将图像视为文档,也就是多个视觉词汇的集合,且相互之间没有特定顺序。K-means算法就是一种基于样本间相似度测量的间接聚类算法,具有理论可靠、算法简单、收敛速度快[16]的特点。
实验将图像库里的图像大小分成50*50,采用重叠的分块方式,并提取每块的颜色纹理综合特征,由于图像大小不同,故分块的数量也不同。为了能用标准的SVM学习与检索,借鉴Bag of Words模型,实现步骤如下:
(1)用K-Means算法对训练图像的所有分块的颜色与纹理特征进行聚类,找出聚类中心点,构造视觉词汇;
(2)将每幅图像的分块特征向量在聚类中心点进行映射,得到图像的映射向量;
(3)以图像的映射向量作为图像的特征向量,再利用SVM学习与检索。
用K-Means算法将训练类的所有图像示例聚成100类,并产生每一类的投影特征,建立每小类的视觉字,分别计算训练与测试类的投影特征。
4 实验对比分析
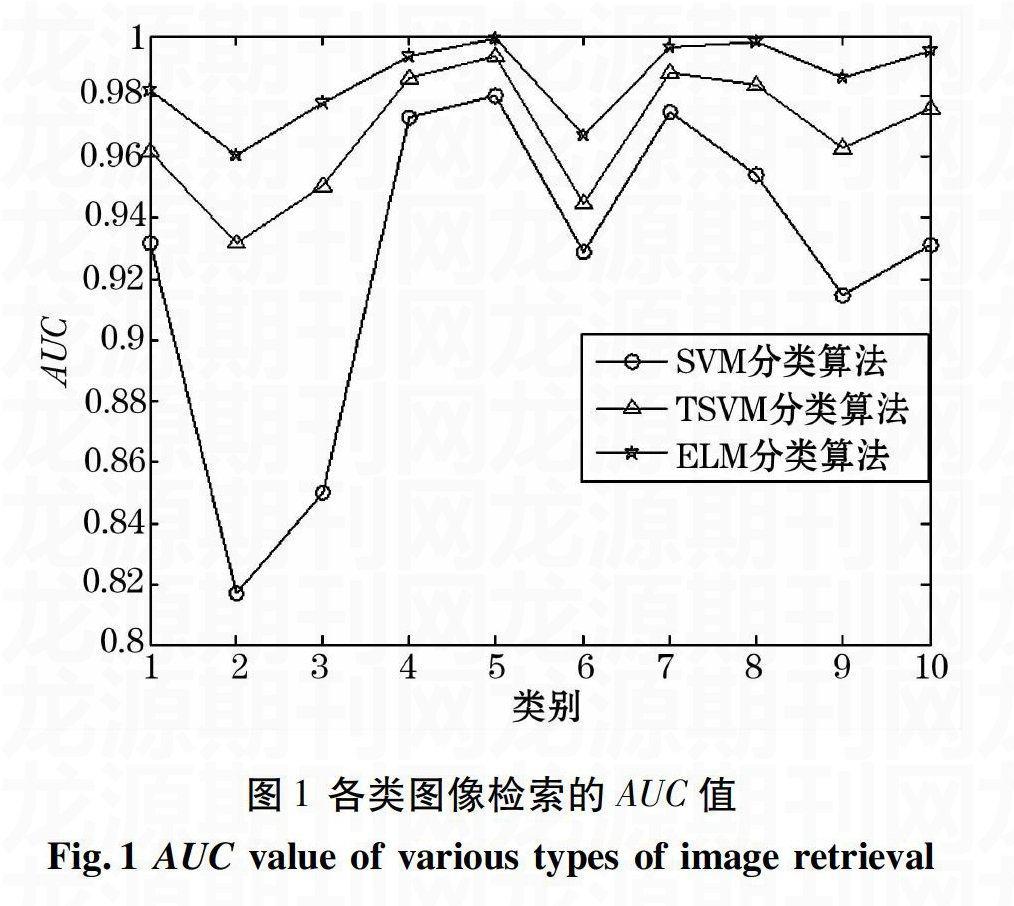
研究采用corel图像数据库的图像作为本实验的素材,图像库里面一共有10类的1 000张图像,并且每类有100张。在此选取每类的前40张图像作为训练样本,而后60张图像作为测试样本,检索相似度较大的前20张图像并将其显示出来。用ROC曲线与AUC值作为评价分类器性能的指标,各类图像检索所需时间如表1所示,各类图像检索的准确性如图1所示。
表1各类图像检索时间(/s)
Tab.1 various types of image retrieval time (/ s)
图像类名 SVM TSVM ELM
非洲人 31.076 30.501 28.921
海滩 12.131 20.939 18.530
建筑 27.088 26.928 23.528
车 24.205 23.406 21.563
恐龙 22.022 20.281 18.647
大象 34.062 30.177 28.559
花 25.090 23.381 21.509
马 32.760 30.501 28.430
山 33.913 30.593 28.563
食物 25.021 23.533 21.400
图1各类图像检索的AUC值
Fig.1 AUC value of various types of image retrieval
5结束语
颜色纹理特征实现SVM图像检索仿真的基础上,结合图像分块特征,弥补了图像空间分布信息,三者结合作为图像提取特征,使得检索结果更加准确。与SVM(支持向量机)和TSVM(直推式支持向量机)学习机制相比,ELM分类算法具有更高的检索准确性,并且检索速度更快。
参考文献:
[1] ZHOU X S, HUANG T S. Relevance feedback in image retrieval: a comprehensive review[J].ACM Multimedia Systems Journal,2003,8( 6) : 536-544.
[2] GAMMERMAN A, VAPNIK V, VOWK
V. Learning by transduction[C]//Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence,San Francisco: Morgan Kaufmann Publisher, 1998:148-156.
[3] HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: theory and applications[J]. Neurocomputing, 2006, 70(1/3):489-501.
[4]张磊,傅志中,周岳平.基于HSV颜色空间和Vibe算法的运动目标检测[J].计算机工程应用,2014,50(4):181-182.
[5] 徐少平,李春泉,胡凌燕,等.一种改进的颜色共生矩阵纹理描述符[J].模式识别与人工智能,2013,26(1):91-94.
[6]DENG Yining, MANJUNATH B S. Unsupervised segmentation of color-texture regions in images and video[J]. IEEE Trans. On Pattern Analysis and Machine Intelligence,2001,10(5):800-810.
[7]Vapnik V.The Nature of Statistical Learning Theory[M]. New York:Springer Verlag,1995:11-14.
[8]奉国和.SVM分类核函数及参数选择比较[J].计算机工程与应用,2011,47(3):126-127.
[9]JOACHIMS T.Transductive inference for text classification using support
vector machines[C]//Proceedings of the 16th International Conference on Machine Learning ( ICML), San Francisco: Morgan Kaufmann Publishers,1999:200-209.
[10]王立梅,李金凤,岳琪.K均值聚类的直推式支持向量机学习算法[J].计算机工程与应用,2013,49(14):144-146.
[11]齐芳,冯昕,徐其江.基于人工鱼群优化的直推式支持向量机分类算法[J].计算机应用与软件,2013,30(3):293-295.
[12] HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: theory and applications[J]. Neurocomputing,2006,70(1/3):489-501.
[13]王杰,郭晨龙.小波核极限学习机分类器[J].微电子学与计算机,2013,30(10):73-75.
[14]郭丽,黄元元,杨静宇.用分块图像特征进行商标图像检索[J].计算机辅助设计与图形学报,2004,16(7):969
[15]赵理君,唐娉,霍连志,等. 图像场景分类中视觉词包模型方法综述[J].中国图象图形学报,2014,19(3):333-342.
[16]曾接贤,王军婷,符祥. K均值聚类分割的多特征图像检索方法[J].微电子学与计算机,2010,27(8):226-227.
