
基于复述技术的汉语成语翻译方法研究
2015-04-21 08:30:00陈毅东史晓东苏劲松
中文信息学报 2015年4期
罗 凌,陈毅东,史晓东,苏劲松
(1. 厦门大学 智能科学与技术系, 福建 厦门 361005;2. 厦门大学 软件学院,福建 厦门 361005)
基于复述技术的汉语成语翻译方法研究
罗 凌1,陈毅东1,史晓东1,苏劲松2
(1. 厦门大学 智能科学与技术系, 福建 厦门 361005;2. 厦门大学 软件学院,福建 厦门 361005)
汉语成语是汉语的精华,拥有特有的语言形式,并经常出现在汉语中。但是由于汉英统计机器翻译训练语料中成语的稀疏性和现今大多机器翻译系统并没有对成语进行特殊的处理和研究,在汉英机器翻译中成语的翻译并不理想。针对该问题,本文提出了基于复述技术的两种方法来提高汉英统计机器翻译系统中成语翻译的能力。方法1: 测试集成语复述替换;方法2: 训练集成语复述替换。实验结果表明,方法1可以解决成语未登录词问题,提高成语翻译能力。方法2可以解决训练语料中成语稀疏问题,改善翻译训练模型。
统计机器翻译;成语翻译;复述
1 引言
汉语成语是汉语特有的语言形式,是一个固定短语,一般表达一个固定的语义,它简短精辟,大多是约定俗成的四字结构,并且富有深刻的思想内涵。汉语成语是汉语词汇系统的重要组成部分,在汉语书面或者日常会话中经常出现,特别是在文学作品中尤为频繁, 而在新闻领域中成语的使用频率相对较低。尽管如此,经刘长征等人[1]调查,2005年全年15种报纸的语料共使用四字格成语915 533次,文本总数为591 315个,平均每个文本使用成语1.5次。由此可见成语在汉语语句中出现地相当频繁。而在现今汉英统计机器翻译研究中,汉语成语在统计机器翻译系统中存在的问题并没有引起太多的关注,事实上,由于成语在翻译训练语料中的稀疏性导致了翻译系统对包含成语的句子的翻译质量比较糟糕。本文分别对Google在线机器翻译系统*http://translate.google.cn/和使用开源工具Moses自行训练的短语机器翻译系统进

表1 成语翻译出错实例
行了包含成语句子的翻译测试,测试结果表明现今汉英统计机器翻译系统对汉语成语这部分的翻译还是存在不少问题。
具体地,测试一,从成语词典*http://cy.5156edu.com/中随机抽取400条成语,并从网络上爬取包含该成语的句子作为测试集,对Google在线机器翻译系统进行测试,人工对翻译结果进行评测,结果表明,400句测试集中,共143句成语翻译存在问题,占句子总数的35.75%;测试二,从NIST04,05,06中抽取包含成语的句子共352句作为使用FBIS训练的Moses短语系统测试集,人工对翻译结果进行评测,结果表明,86句成语翻译存在问题,占句子总数的24.43%。根据观察,这些问题主要是: 第一,成语作为未登录词致使翻译系统无法翻译;第二,训练数据中部分成语比较稀疏,导致对齐和翻译错误。一些问题实例可见表1,调查结果表明,现今的统计机器翻译系统对成语的翻译并不理想,并且这个问题普遍存在。
针对该问题,本文提出了基于复述技术的两种方法来提高汉英统计机器翻译系统中汉语成语的翻译能力,方法1: 测试集成语复述替换,用以解决成语作为未登录词的问题。方法2: 训练集成语复述替换,用以解决训练集中成语稀疏问题。
本文其他部分安排如下: 第二节阐述使用复述解决成语翻译问题的原因以及总体思路;第三节介绍如何获取成语复述,并提出了复述替换选择的方法;第四节提出了两种将成语复述替换应用到实际的汉英统计机器翻译系统中的方法,并进行了详细描述;第五节给出相应的实验结果及分析;第六节给出相关结论以及未来的研究方向。
2 总体思路
对于成语翻译问题首先最容易想到的解决办法是构建一个汉英成语翻译词典,当待译的语句中出现成语时,直接通过查找词典来进行成语翻译。
但是这样的做法有以下三个弊端: 第一,现今并没有一个公开免费的汉英成语翻译型电子词典,要编写一个这样的汉英成语词典需要大量的人力和物力;第二,词典翻译基本都是一对一,这样相同的成语在不同句子中的翻译都是同样一个结果,结果单调,也会影响句子的通顺度;第三,如果要做汉语除英语以外其他语言的翻译,那么又需要构建其他语言的成语翻译词典。
在语言学界,汉语成语的翻译已经有不少研究,如果我们将语言学中的一些理论借鉴到机器翻译中的成语翻译问题上,那么在很大程度上可以解决以上弊端。
从20世纪60年代起,国外已逐渐形成了较为系统的翻译语言学理论。对等翻译就是西方翻译理论中的一个核心概念[2]。其中尤金奈达是西方语言学派翻译理论的主要代表,提出了许多有着深远影响的翻译理论,功能对等就是其中之一[3]。
功能对等理论主张翻译时不求文字表面的死板对应,而要在两种语言间达成功能上的对等。他强调译文最基本的要求是使目标语的读者能理解和欣赏原文读者对原文的理解和欣赏[4]。
在语言学界,已经有不少研究证明了功能对等理论对汉语成语翻译的适用性[2,5-6]。受功能对等理论的启发,我们可以在成语翻译中利用自然语言处理领域中的复述技术来解决成语翻译问题。所谓复述(Paraphrases),主要是研究短语或者句子的同义现象[7]。本文使用复述来替换源语言端的成语,以达到功能对等的效果,再进行翻译。
这种做法有三大优点:第一,将成语替换成了更常见的短语,降低了翻译难度;第二,获取了成语复述库后,对于汉语到其他语言的成语翻译同样可以进行;第三,替换源语言端,翻译结果仍依赖训练语料的统计结果,以致翻译结果不至于单一。
由于复述现象的普遍性,在统计机器翻译的各个阶段复述研究已经有着重要的应用[8]。前人研究表明,复述可在多个方面改进统计机器翻译。首先,复述改善翻译模型训练[9-12];其次,复述可以提高调参效果[13-15];再次,通过复述改写待译语句来提高翻译质量,解决未登录词问题[16-21];另外,复述还可以改善机器翻译自动评测[22-24]。
根据对等理论以及前人在机器翻译中复述应用的研究,本文提出了两种基于复述技术的汉语成语翻译方法。方法1: 测试集成语复述替换,将测试集中未登录的成语进行复述替换,再进行解码翻译;方法2: 训练集成语复述替换,将训练集中分布稀疏的成语替换成相应复述,改善翻译训练模型。
3 成语复述的获取及替换选择
3.1 成语复述的获取
要进行成语复述的替换首先要构建成语复述库,成语复述的获取自然成为了首先要解决的问题,它为后面的工作奠定了重要的基础。近些年来,复述作为自然语言处理的一个重要研究方向得到了学术界越来越多的重视,研究者们相继提出了多种获取复述的方法和模型[25-28]。本文对前人提出的最有效也最具代表性的几种方法加以实现和改进来获取汉语成语复述,这其中包括:
方法1: 基于单语平行语料库的成语复述抽取方法。
方法2: 基于双语平行语料库的成语复述抽取方法。
方法3: 基于词典的成语复述抽取方法。
对于每种方法抽取出的成语复述,我们都进行了人工评测,并且计算了准确率,本文还对每种方法的优缺点进行了分析和比较,特别注明,本文中的成语识别均基于在线词典②中的成语匹配。
抽取复述短语的一个最直观的想法便是从一个含有大规模复述句对的单语平行语料中提取复述短语。Barzilay和McKeown首先提出了利用单语平行语料获取复述短语[25],他们获得的复述对经过人工评测准确率达到85%。借鉴他们的研究,我们首先从网上收集了小说《钢铁是怎样炼成的》的两本不同中文译本。筛选出包含成语的句子,然后通过计算句对间同现词的个数进行句对齐,构建平行句对,总共748对。接着计算成语和相应平行句中短语的上下文相似度,取其左右各四个词作为上下文,最后取相似度最高的短语作为其复述。相似度计算均根据词重叠率计算而得。
但由于可用的单语平行语料的规模限制以及单语文本类型领域的限制,Bannard和Callison-Burch[27]提出了基于“枢轴法(pivot approach)”从双语平行语料库中抽取复述短语,他们使用了统计机器翻译的短语表,若采用自动词对齐,准确率可达到64.5%。该方法的基本假设是:若两个短语e1和e2对齐相同的外文翻译短语f,则e1和e2便是一对复述短语。本文重现了该方法,具体地,本文使用了FBIS约20万句对双语平行语料,首先经过Giza++[29]对齐,并根据基于短语的统计机器翻译方法[30]获取了短语表。然后从短语表中查找与成语拥有相同外文翻译的短语,并取其中最大概率的短语作为该成语的复述。
由于上述两种方法的资源比较有限,获取的成语复述的数量较少,所以本文提出从成语词典注释中提取成语复述的方法,该方法可以得到大规模的成语复述。现在网络上电子成语词典资源比较丰富并且容易获取,经过比较和分析,本文最终选择在线成语词典②用来抽取复述。该词典与其他同类词典相比,收集的成语相对全面,现已经收录41 843条成语,而且该词典注释简明扼要,更利于成语复述的抽取。经过分析,本文编写了一些句子规则模板来从成语解释中提取成语复述。
对于上述三种方法获得的成语复述,我们都从中随机抽出了200对,进行人工评测标注,并计算了准确率,为了更好地对每种方法加以比较,我们将各种方法使用的语料资源、抽取得到的成语复述规模及其准确率进行了总结,详见表2。
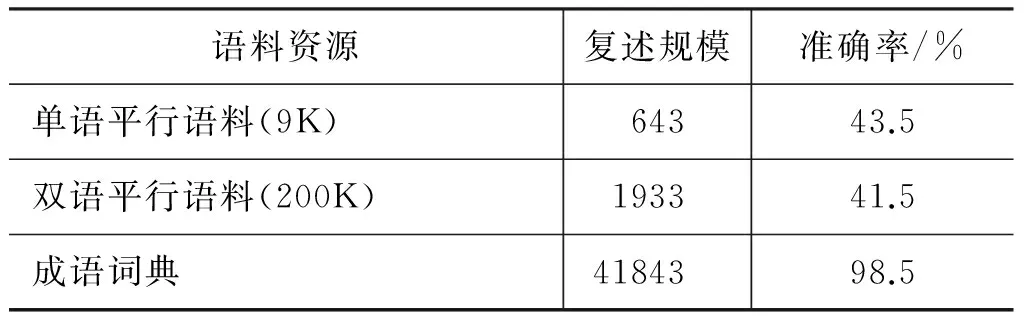
表2 成语复述获取方法对比表
其中‘K’表示的是单位“千”
基于前人的复述抽取方法对于成语这个特殊短语来说还是存在不少问题。从语料资源获取的难度上看,由于网络上相同名著的不同汉语译本比较少,基本都是同一版本,所以单语平行语料获取的难度比双语平行语料和成语词典大得多;从获取的成语复述规模来看,由于单语平行语料和双语平行语料的规模、领域受限,从中获取到的成语复述规模自然受限,而成语词典包含了大量成语,可以得到大规模的成语复述;从抽取成语复述结果的准确率来看,由于单语平行语料中句子意思并不一定完全一致,所以获取的成语复述准确率比较低,双语平行语料由于成语的稀疏性等问题,导致成语对齐结果不准确,由此获得的成语复述准确率也不高,而成语的解释就是成语的意思,所以基于词典方法准确率可达到98.5%。
3.2 成语复述的替换选择
通过上述不同方法,我们将获取的复述整合成一个复述库。表3展示了复述库的一些实例。同一个成语可能会有多个不同的复述,这样在进行复述替换时就需要进行复述选择。
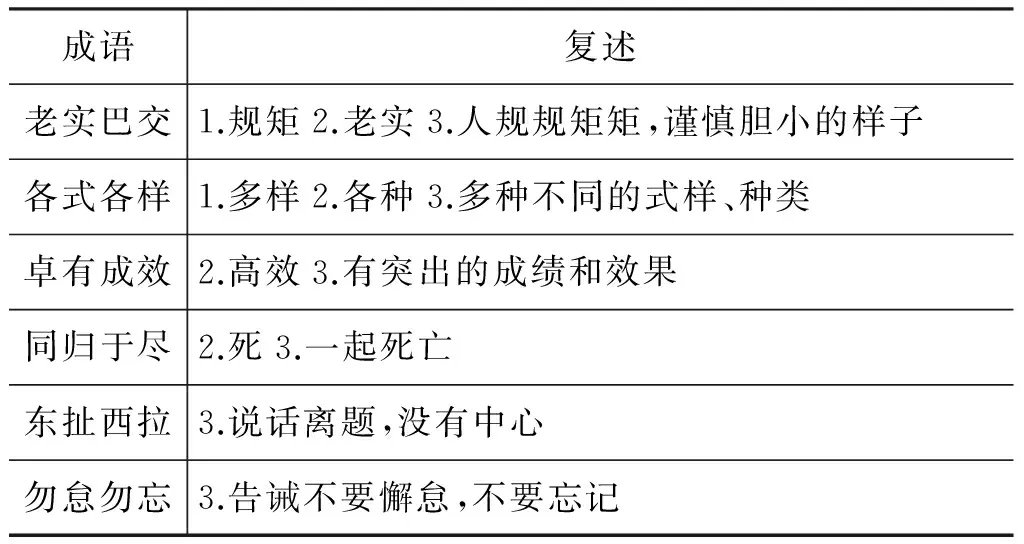
表3 成语复述实例
其中,1指基于单语平行语料的方法,2是基于双语平行语料的方法,3是基于词典的方法
通过对复述实例的观察发现基于单语和基于双语的方法抽取出来的复述基本是词级别,而基于词典的方法抽取出来的复述基本是短句级别。根据这些特点我们可以制定一些规则来进行复述选择。首先我们对待译的句子进行句法分析,然后根据句中的依存关系将成语进行分类,再根据我们制定的规则进行成语复述替换选择。
由句法分析我们将成语分成四类: 名词性成语、修饰性成语、动词性成语和其他成语。这里我们使用哈工大的依存句法分析工具LTP来进行成语的分类,将满足表4相应依存关系的成语分到相应的成语类别中。
将成语进行分类后,我们使用如下的规则进行复述替换选择:
• 不选择包含训练集中未登录词的复述。
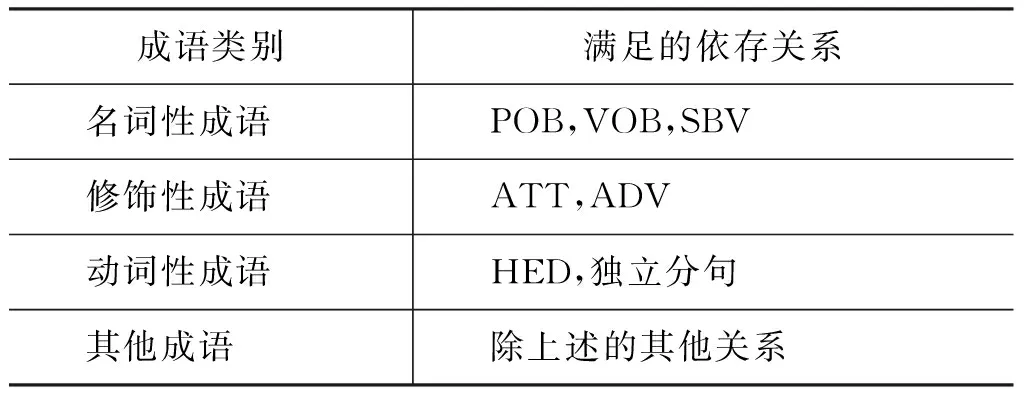
表4 成语分类规则表
• 对于动词性成语和其他成语,我们使用基于词典的方法抽取出来的复述。
• 对于名词性成语和修饰性成语,我们使用基于单语平行语料的方法和基于双语平行语料的方法抽取出来的复述。如果同一个成语存在多个词级别的复述时,我们使用N元语言模型进行打分,选取得分最高的作为该成语最终的复述替换。
由于基于词典的方法抽取出来的复述多为短句级别,而且比较全面,准确率也比较高,这样适合作为独立分句的动词性成语和其他成语的复述替换。而基于单语平行语料和双语平行语料的方法抽取出来的复述基本都是词级别,根据名词性成语和修饰性成语在句子中充当的成分,词级别的复述进行替换比较合适。后面实验要进行的成语复述替换选择都是使用本节的方法。
4 汉英SMT中成语复述替换方法
受前人在机器翻译中复述应用的研究启发,针对成语在统计机器翻译中存在的问题,本文提出了两种方法来提高汉英统计机器翻译系统中成语的翻译能力,方法1: 测试集成语复述替换;方法2: 训练集成语复述替换。
下文将分别介绍两种方法,包括方法的流程图、详细研究方法以及该方法的优势与不足。
4.1 方法1: 测试集成语复述替换
将测试集中的成语替换成相应的复述,改写待译语句,再进行机器翻译解码。其流程图如图1所示。其中,机器翻译训练部分包括获取短语表和训练语言模型;解码部分首先对待译的测试集进行成语复述的替换,然后再进行统计机器翻译解码,得到译文。
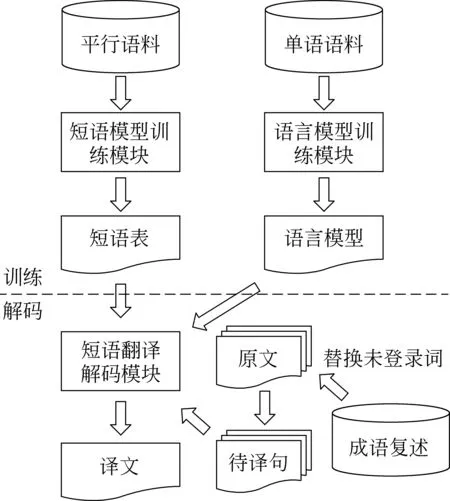
图1 方法1流程图
由于获取的成语复述一般都是些常用词汇,所以替换后可以解决未登录词的问题,起到了降低翻译难度的作用。但这样的替换存在的缺陷是,由于没有对替换后的句子进行处理,在一些情况下,会影响句子的通顺度。
4.2 方法2: 训练集成语复述替换
数据稀疏问题一直是统计机器翻译中的一个重要问题,经实验,有一定数量的成语在训练集中比较稀疏,这对词语对齐和短语概率计算都会有一定的影响。本文将对训练集中稀疏的成语进行复述的替换,试图改善模型训练,在解码时,为了防止产生未登录词,因此对测试集也做了相应替换。其流程图如图2所示。其中,在训练模块,把成语用它的所有
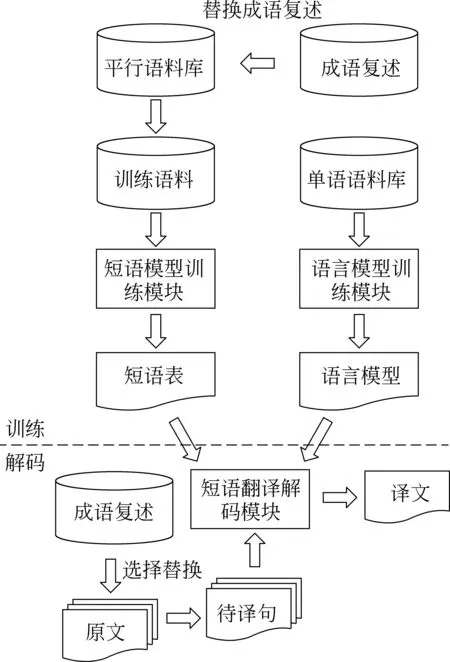
图2 方法2流程图
复述进行替换,形成的句对集全部加入训练集(为了让频率不失真,我们将所有句子都统一放大相同倍数),得到新的训练语料,再进行训练获取短语表;在解码模块,首先对待译的测试集做成语复述的选择替换,然后再进行解码翻译,得到译文。
大部分成语由于稀疏性问题在进行词对齐时,常常会对空或者对错,而成语复述大多是由常见的通俗词语组成,经过成语复述的替换,由训练过程来自动选优,对词对齐和短语概率计算会起到纠正作用,改善翻译模型训练。
5 实验与讨论
5.1 实验设置
我们把本文提出的方法应用到实际的汉英统计机器翻译系统中来验证它们的有效性。本文实验中用到的系统都是基于开源工具Moses中的短语统计机器翻译系统。
实验中我们使用的训练语料为FBIS语料,开发集使用的是NIST MT 2002的测试集,测试集有使用到NIST MT 2005、NIST MT 2006的测试集,还有从NIST MT 2004~2006测试集中提取出包含成语的句子作为一个测试集,下面称作NIST-Idiom。实验中使用的语言模型是通过SRILM工具根据Gigaword语料训练出的四元语言模型。词语对齐工具采用的是GIZA++。对于实验结果,我们采用大小写不敏感的BLEU[31]、GTM[32]、Meteor[33]和人工评测来评价翻译质量,其中人工评测是根据译文结果按0~5分打分,然后将每句的得分相加除以测试集中句子总数作为该测试集译文结果的分数,由三个不同的人打分最后取平均值作为最终分数。表5展示了我们所用的实验数据。
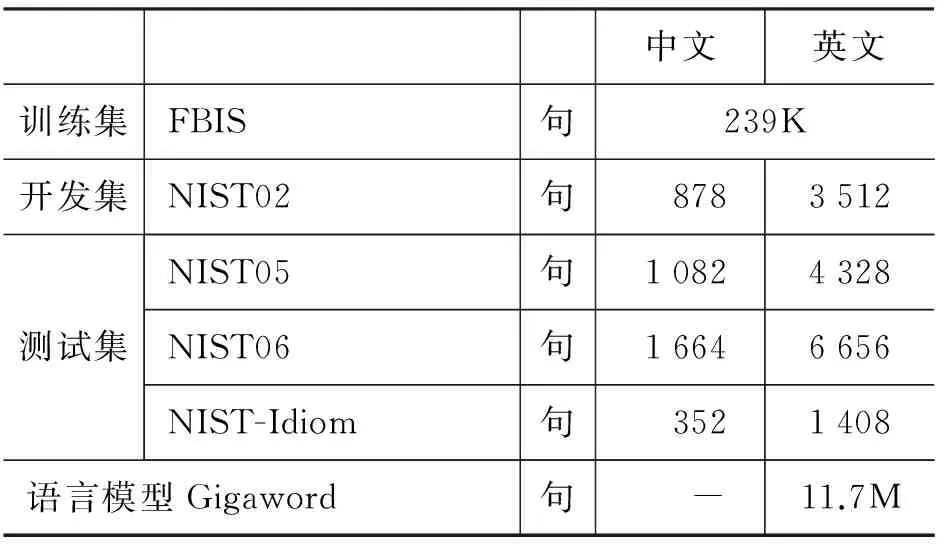
表5 实验数据
其中‘K’表示的是单位“千”,‘M’表示的是单位“百万”
根据上一节提到的成语复述在统计机器翻译中的应用,本文分别对方法1和方法2设置了性能测试实验,具体实验结果和分析将在下面详细介绍。
5.2 方法1性能测试实验
由于网络上汉英资源相对比较丰富,我们找到了一部英汉汉英词典(73 003词对),为了和利用词典的方法进行比较,我们设置了两个Baseline(BL1和BL2)。BL1只用了FBIS进行训练,BL2使用了FBIS和词典资源进行训练。我们将方法1在两个Baseline上都进行了实验。实验中不仅替换了测试集中的未登录成语,还根据成语在训练集中出现的次数进行相应的测试集成语复述替换对比实验。首先我们使用NIST05和NIST06作为测试集。但是由于NIST05和NIST06中包含成语的句子占整个测试集的比例太小,评测结果基本不变,表6给出了方法1在BL1上的结果,这样的结果无法验证方法1的有效性。所以我们又构建了NIST-Idiom测试集来进行测试。实验结果见表7。
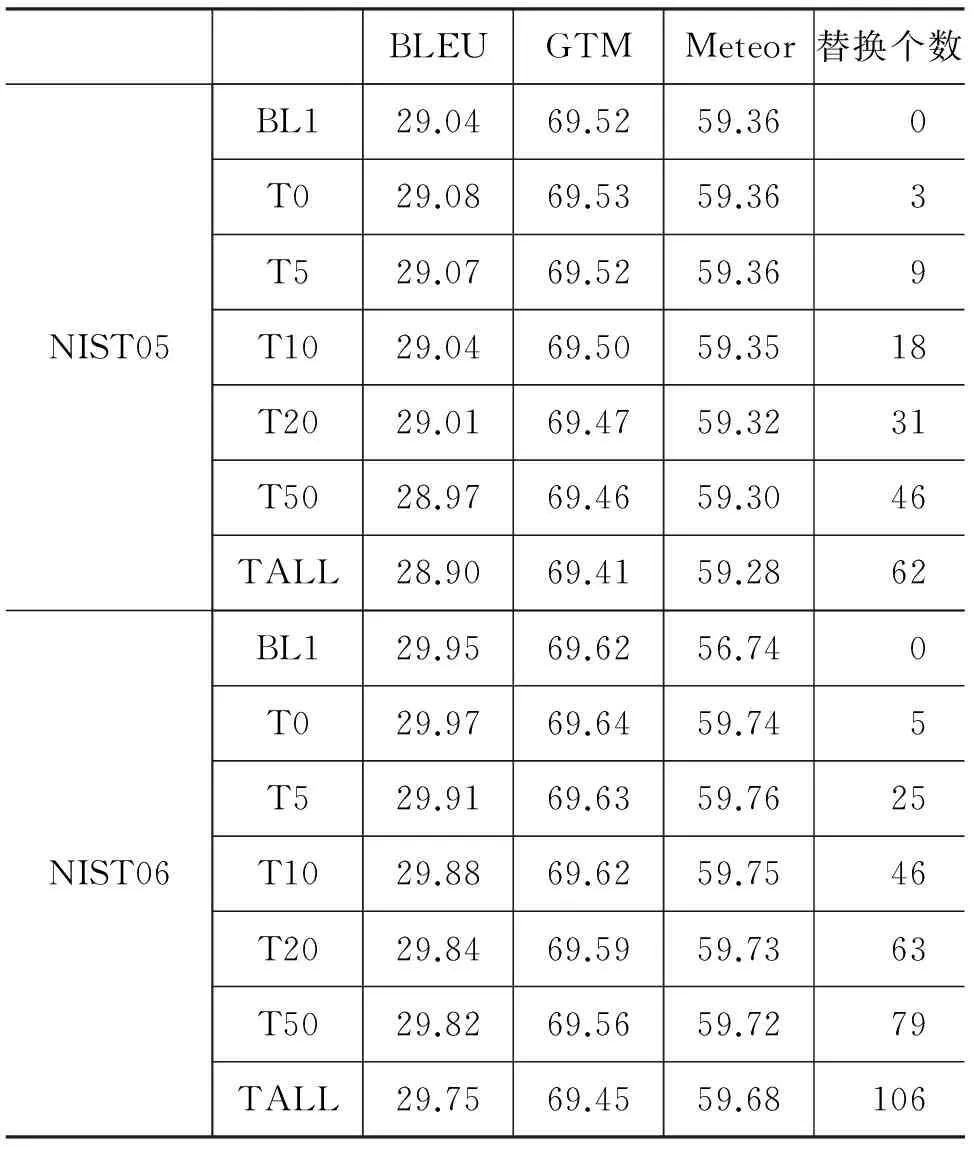
表6 方法1在NIST05和NIST06上的结果
“Tn”表示将测试集里在训练集中出现次数小于等于n的成语替换成相应复述。其中T0表示替换未登录词,TAll表示替换测试集中全部成语。
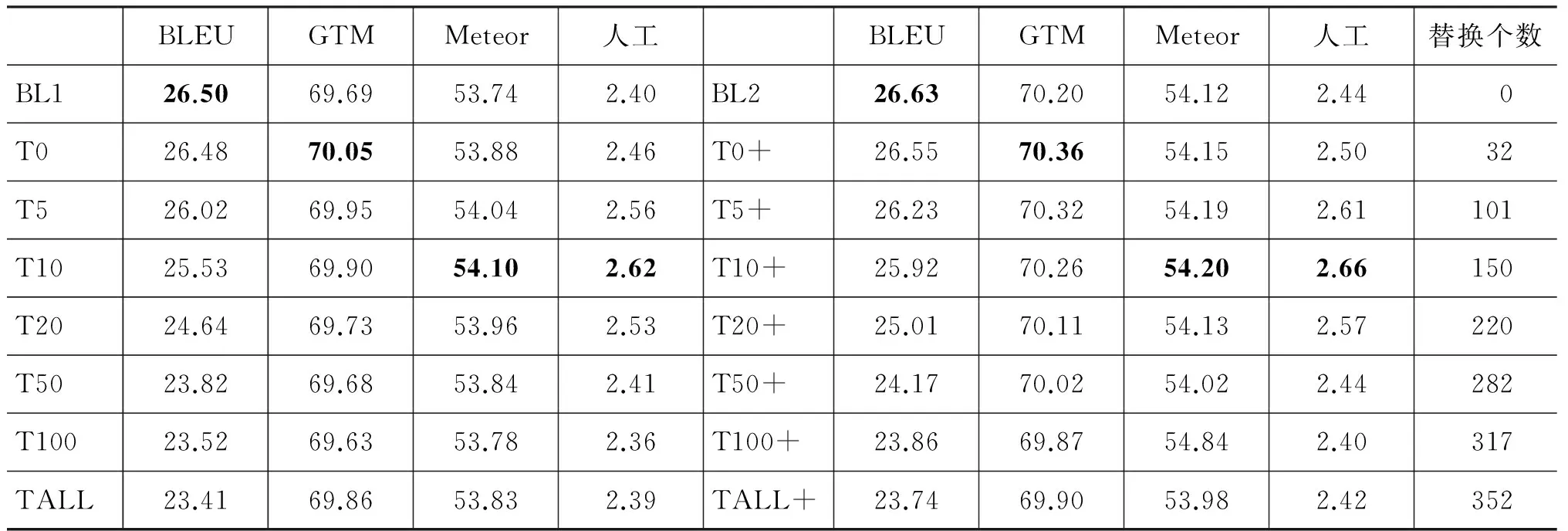
表7 方法1在NIST-Idiom上的结果
“Tn”表示将测试集里在训练集中出现次数小于等于n的成语替换成相应复述。其中T0表示替换未登录词,TAll表示替换测试集中全部成语。“+”表示是在BL2上的实验结果。
从表7可以看出,无论是在BL1还是BL2上,使用方法1替换测试集中的未登录词,在GTM、Meteor和人工评测上都有所提升,在BLEU上略微有些下降。原因可能是BLEU方法是基于N元匹配,而替换成语复述后,替换部分往往会比原句长,导致得分偏低。通过对翻译结果的查看分析发现,尽管BL2中加入了词典,但是该词典包含的成语还是比较少,并未解决成语翻译的问题,方法1在BL2上也还是有效的。从实验结果还可以看出,对于训练集中出现次数小于等于10的成语,在测试集中做相应的替换,得到的Meteor和人工评测分数最高。说明方法1不仅能解决成语未登录词的问题,还可以在一定程度上提高训练集中稀疏成语的翻译能力。
表8展示了翻译结果对比的一些示例,包括两个正例和一个反例。从第一个正例来看,替换成语未登录词不仅可以解决未登录词无法翻译的问题,还对未登录词周边的部分翻译有所改进。从第二个“1s”表示替换前的源语言句子,“1t”表示“1s”对应的系统翻译结果;“2s”表示成语复述替换后的源语言句子,“2t”表示“2s”对应的系统翻译结果。其中前两个是正例,后一个是反例。

表8 方法1翻译结果对比示例
正例可以看出,由于训练集中部分成语过于稀疏,对齐结果常常出错或者对空,该类成语即使不是未登录词,也是无法正确翻译,替换这类成语可以提高其翻译能力。但从反例可以看出,有些替换后的待译句子并不通顺或者出现句法错误,这种情况下翻译效果并没有得到改善。
5.3 方法2性能测试实验
本实验将方法2用在BL1基线系统上,对 NIST05、NIST06和NIST-Idiom测试集进行测试。我们根据成语在训练集中出现次数来对训练集中该成语进行复述替换,并按不同出现次数做了实验对比,实验结果见表9。
从表9中可以看出,尽管在不同的测试集,几种评测方法并不完全一致,每个测试集的最佳替换效果也不是同一个频数的替换,不过替换训练集中出现次数在20以下的成语,在三个测试集上的翻译结“Rn”表示将训练集中出现次数小于等于n的成语替换成相应的成语复述。其中RAll表示替换训练集中全部成语。BL2是加入词典资源的基线系统。
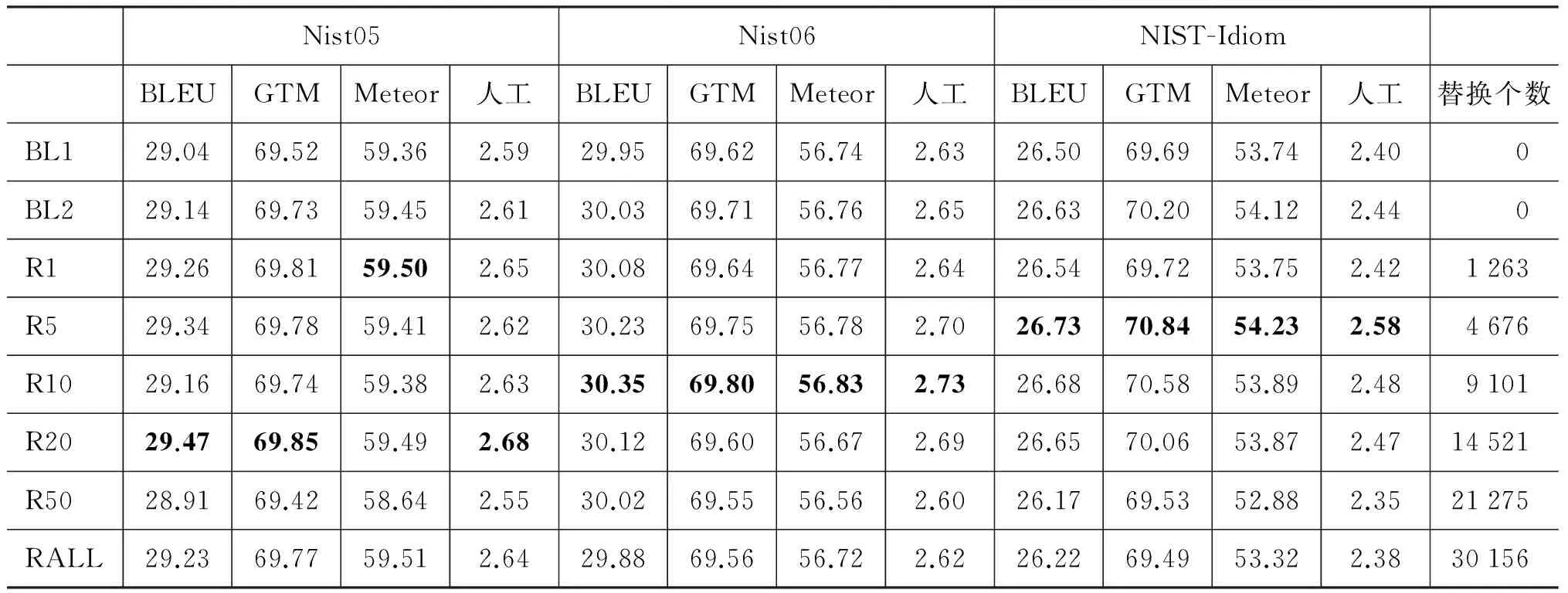
表9 方法2在NIST05、NIST06和NIST-Idioms上的结果
果相比基线系统各项指标上都有所提高。和加入词典资源的BL2相比,方法2在测试集上的最佳效果要优于BL2。
对比方法2和方法1,方法2从训练集角度改善了翻译模型训练,提高了模型的翻译质量,方法1从测试集的角度解决了未登录成语的翻译,在NIST-Idiom测试集上,方法2在自动评测方法的优势比方法1大,方法1在人工评测上会有更大的优势。
实验结果表明,将训练集中出现次数较少的成语替换成其复述,使其转换成了较常见的词语组合,对词对齐和短语计算概率有所影响,可以改善翻译模型训练。相比之下,替换出现次数较高的成语,翻译结果概率相比基线系统有所下降,说明出现次数较高的成语在训练时大多已经能形成正确的对齐,而替换后产生了噪声,反而影响了翻译效果。
6 结论与未来工作
本文针对汉英统计机器翻译中成语翻译存在的问题,引入了复述的方法,根据获取复述的特点提出了复述替换择优的方法,并分别应用在汉英统计机器翻译测试集和训练集中,来改善成语翻译问题。实验结果表明,利用复述技术能够有效提高汉英统计机器翻译系统中的成语翻译质量。
由于现在基于词典的成语复述抽取获取的复述大多是短句级别,比较难扩展,并且其他方法获取的成语复述又很少,所以现在的成语复述库比较单一,使得在复述替换时并没有较多的复述进行选择。在未来的研究工作中,我们将研究如何改进基于词典的成语复述抽取,使该方法抽取的成语复述更为简洁扼要,这样就可以使用一些基于语义的方法来扩展成语复述,使其更加丰富而不至于单一。同时,在成语复述的应用研究中,除了在机器翻译中的应用,如何在自然语言处理其他领域有更好的应用,也是我们下一步研究的方向。
[1] 刘长征,秦鹏. 基于中国主流报纸动态流通语料库(DCC)的成语使用情况调查[J]. 语言文字应用,2007, 8(3): 78-86.
[2] 衡孝军. 从社会符号学翻译法看汉语成语英译过程中的功能对等[J]. 中国翻译,2003,24(4): 23-25.
[3] 谭载喜. 新编奈达论翻译[M]. 北京: 中国对外翻译出版公司,1999.
[4] Eugene A Nida. Language, Culture and Translating[M]. Shanghai: Shanghai Foregin Language Education Press,1999.
[5] 谢媛媛. 功能对等和汉语成语翻译[J]. 安徽农业大学学报,2007,16(2): 137-139.
[6] 王俊义. “功能对等”理论对成语翻译的适用性[J]. 河北理工学院学报,2001,1(3): 87-89.
[7] 刘挺,李维刚,张宇,等. 复述技术研究综述[J]. 中文信息学报,2006,20(4): 25-32.
[8] 胡金铭,史晓东,苏劲松,等. 引入复述技术的统计机器翻译研究综述[J]. 智能系统学报,2013,8(3): 199-207.
[9] F Bond,E Nichols,DS Appling,et al. Improving statistical machine translation by paraphrasing the training data[C]//Proceedings of the International Workshop on Spoken Language Translation. Waikiki,USA,2008: 150-157.
[10] P Nakov. Improved statistical machine translation using monolingual paraphrases[C]//Proceedings of the 18th Biennial European Conference on Artificial Intelligence. Patras,Greece,2008: 338-342.
[11] R Kuhn,B Chen,G Foster,et al. Phrase clustering for smoothing TM probabilities-or,how to extract paraphrases from phrase tables[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Beijing,China,2010: 608-616.
[12] A Max. Example-based paraphrasing for improved phrase based statistical machine translation[C]//Proceedings of the 2010 Conference in Empirical Methods in Natural Language Processing. MIT,USA,2010: 656-666.
[13] N Madnani,NF Ayan,P Resnik,et al. Using paraphrases for parameter tuning in statistical machine translation[C]//Proceedings of the Second Workshop on Statistical Machine Translation. Prague,The Czech Republic,2007: 120-127.
[14] N Madnani,P Resnik,BJ Dorr,et al. Are multiple reference translations necessary? Investigating the value of paraphrased reference translations in parameter optimization[C]//Proceedings of the 8th Conference of the Association for Machine Translation in the Americas,Waikiki,USA,2008: 993-1000.
[15] N Madnani,BJ Dorr. Generating targeted paraphrases for improved translation[J]. ACM Transactions on Intelligent Systems and Technology,2013,4(3): 1-26.
[16] T Mitamura,E Nyberg. Automatic rewriting for controlled language translation[C]//Proceedings of the NLPRS 2002 Workship on Automatioc Paraphrasing: Theories and Applications,Tokyo,Japan,2001: 1-12.
[17] K Yamamoto. Machine translation by interaction between paraphraser and transfer[C]//Proceedings of the 19th International Conference on Computational Linguistics,Taipei,China,2002: 1107-1113.
[18] Y Zhang,K Yamamoto. Paraphrasing of Chinese utterances[C]//Proceedings of the 19th International Conference on Computational Linguistics,Taipei,China,2002: 1163-1169.
[19] M Shimohata,E Sumita,Y Matsumoto. Building a paraphrase corpus for speech translation [C]//Proceedings of the 4th International Conference on Language Resources and Evaluation,Lisbon, Portugal,2004: 1407-1410.
[20] T Onishi,M Utiyama,E Sumita. Paraphrase lattice for statistical machine translation [C]//Proceedings of the ACL 2010 Conference Short Papres,Uppsala,Sweden,2010: 1-5.
[21] J Du,J Jiang,A Way. Facilitating translation using source language paraphrase lattices[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing,MIT,USA,2010: 420-429.
[22] Y Lepage,E Denoual. Automatic generation of paraphrases to be used as translation references in objective evaluation measures of machine translation[C]//Proceedings of the 2nd International Joint Conference on Natural Language Processing,Jeju Island,Korea,2005: 57-64.
[23] L Zhou,CY Lin,E Hovy. Re-evaluating machine translation results with paraphrase support[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing,Sydney,Australia,2006: 77-84.
[24] G Russo-Lassner,J Lin,P Resnik. A paraphrased- based approach to machine translation evaluation[R]. College Park,USA: University of Maryland,2005.
[25] R Barzilay,K R McKeown. Extracting Paraphrases from a Parallel Corpus[C]//Proceedings of ACL/EACL. 2001:: 50-57.
[26] 李维刚,刘挺,李生. 基于双语语料库的短语复述实例获取[J]. 中文信息学报,2007,21(5): 112-117.
[27] C Bannard,C Callison-Burch. Paraphraseing with Bilingual Paraller Corpora[C]//Proceedings of ACL,2005: 597-604.
[28] R Higashinaka,K Nagao. Interactive Paraphrasing Based on Linguistic Annotation[C]//Proceedings of COLING,2002: 1218-1222.
[29] Franz Josef Och,Hermann Ney. Improved statistical alignment models[C]//Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics,Hong Kong,2000: 440-447.
[30] Philipp Koehn,Franz Josef Och,,Daniel Marcu. Statistical phrase-based translation[C]//Proceedings of HLT-NAACL,2003: 127-133.
[31] Kishore Papineni,Salim Roukos,Todd Ward. BLEU: a Method for Automatic Evaluation of Machine Translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics,Philadelphia,2002: 311-318.
[32] Joseph P.Turian,Luke Shen,I Dan Melamed. Evaluation of Machine Translation and its Evaluation[C]//Proceedings of MT Summit IX,New Orleans,LA. 2003: 386-393.
[33] Satanjeev Banerjee,Alon Lavie. METEOR: An automatic metric for MT evaluation with improved correlation with human judgement[C]//Proceedings of Workshop on Intrinsic and Extrinsic Evaluation Measures for MT and/or Summarization at the 43th Annual Meeting of the Association of Computational Linguistics, Ann Arbor, Michigan, 2005: 65-72.
Chinese Idiom Translation Based on Paraphrasing
LUO Ling1, CHEN Yidong1*, SHI Xiaodong1, SU Jinsong2
(1. Cognitive Science Department, Xiamen University, Xiamen, Fujian 361005, China;2. Software School, Xiamen University, Xiamen, Fujian 361005, China)
Chinese idioms are frequently used in all kinds of Chinese texts. However, since Chinese idioms are relatively sparse in most training corpora for Chinese-English SMT systems, translation quality of the idioms are not satisfactory. And to the best of our knowledge, there is very little research on handling the translation of Chinese idioms. This paper proposes two methods to improve the translation of Chinese idioms by paraphrases in Chinese-English SMT. In the first method, we paraphrase the Chinese idioms in the test set, while in the second method, we paraphrase the Chinese idioms in the training set. The experimental results show that both methods could significantly improve the performance of the Chinese-English SMT system.
statistical machine translation; idioms; paraphrases

罗凌(1988—),硕士研究生,主要研究领域为自然语言处理与机器翻译。E-mail:robert_ai_xmu@163.com陈毅东(1977—)博士,副教授,主要研究领域为自然语言处理与机器翻译。E-mail:ydchen@xmu.edu.cn史晓东(1966—),博士,教授,主要研究领域为自然语言处理与机器翻译。E-mail:mandel@xmu.edu.cn
1003-0077(2015)04-0166-09
2013-08-15 定稿日期: 2014-03-13
国家自然科学基金(61005052);国家科技支撑计划(2012BAH14F03);中央高校基本科研业务费专项资金(2010121068);福建省自然科学基金(2011J01369)
TP
A
猜你喜欢
文苑(2019年24期)2020-01-06 12:06:50
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
海外华文教育(2016年1期)2017-01-20 08:21:58
外语教学理论与实践(2016年1期)2016-06-11 05:51:46
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:16
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
语言与翻译(2014年1期)2014-07-10 13:06:14
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
