
大数据领域演进路径、研究热点与前沿的可视化分析
2015-04-13 08:53何晓萍
现代情报 2015年4期
何晓萍 黄 龙
(南昌大学图书馆,江西南昌 330031)
大数据领域演进路径、研究热点与前沿的可视化分析
何晓萍 黄 龙
(南昌大学图书馆,江西南昌 330031)
本文以Web of Science为数据源,运用信息可视化软件CiteSpace Ⅲ对所搜集的有关大数据研究的文献进行聚类分析和共引分析。通过CiteSpace Ⅲ生成的知识图谱并结合相关文献的研究内容,从演进路径、研究热点以及研究前沿三方面对大数据研究进行量化分析和解读。6篇关键节点文献很好地展示了大数据研究的演进路径,13个高频关键词和10个突现词表征了大数据的研究热点与研究前沿,得出结论:大数据的研究经历了从大数据的计算模型、具体概念、复杂性科学的理论研究到有关大数据社会科学层面、应用型实践层面研究的历程;大数据处理技术、大数据挖掘及大数据应用是大数据研究的三大热点;对大数据本身的研究、处理技术的研究、数据挖掘、系统、模型和网络的研究以及其绩效评估和数据管理的研究是大数据的研究前沿和发展趋势,文章旨在为现阶段大数据研究工作的深入开展提供参考。
大数据;CiteSpace Ⅲ;演进路径;研究热点;研究前沿;可视化
大数据是当下继云计算之后的一大热点词汇。2011年5月,信息存储资讯科技公司EMC在“云计算相遇大数据(Cloud Meets Big Data)”大会上正式提出了“大数据”的概念。几近同时,麦肯锡全球研究院(MGI)发布了一份研究报告《大数据:创新、竞争和生产力的下一个前沿领域》(Big data,The next frontier for innovation,competition,and productivity)[1],它研究了文档和数字数据的状态以及处理这些数据所带来的潜在价值。2012年1月,在瑞士达沃斯举行的世界经济论坛上,“大数据”是主要讨论的主题之一,该论坛上发布了一份题为《大数据,大影响》(Big Data,Big Impact)的报告,提出“数据已成为一种新的经济资产类别,就像货币或黄金一样。”[2]2012年3月,美国奥巴马政府在白宫网站上发布了《大数据研究和发展倡议》(Big Data Research and Development Initiative),该倡议涉及联邦政府的6个部门,这些部门承诺将投资超过两亿美元,来大力推动和改善大数据的提取、存储、分析、共享和可视化[3]。
无论是EMC、MGI的研究报告,世界经济论坛的论题,还是美国政府的倡议,都向人们预示着大数据时代的来临。国内外对大数据的研究不断增加,该领域的研究文献量也与日俱增,大量的研究文献使得人们难以对大数据的知识进行深入地研究。信息可视化是常用的数据挖掘方法之一,它可以利用人类在可视化形势下对模型和结构的获取能力来解决科技文献数量过大、无法快速进行有效交流的问题,可视化数据挖掘可以观察、发现、筛选和理解信息,发现数据和信息背后所隐藏的含义[4]。本文将运用信息可视化工具CiteSpace Ⅲ,以Web of Science数据库中收录的有关大数据研究的文献为样本进行聚类分析和共引分析,对大数据的研究热点、主题内容和发展趋势三方面进行量化分析和解读。
1 数据来源和研究方法
Web of Science是美国Thomson Scientific(汤姆森科技信息集团)基于WEB开发的产品,是大型综合性、多学科、核心期刊引文索引数据库,收录了8 000多种世界范围内最有影响力的、经过同行专家评审的高质量的期刊[5],以Web of Science为数据源进行研究,可以保证研究数据的全面性和权威性。本文选取了Web of Science数据库中的4个子库:Science Citation Index Expanded(SCI-EXPANDED)、Social Sciences Citation Index(SSCI)、Conference Proceedings Citation Index-Science(CPCI-S)和Conference Proceedings Citation Index-Social Science& Humanities(CPCI-SSH),检索方式选择高级检索,检索策略为:主题=(“big data”),时间跨度=所有年份,共检索到有关大数据得研究文献记录1 849条(检索日期:2014年10月12日)。
本文研究工具采用陈超美教授开发的信息可视化软件CiteSpace Ⅲ,其独到的创新之处在于绘制的一幅科学知识图谱,能够显示一个学科或知识域在一定时期发展的趋势与动向,形成若干研究前沿领域的演进历程[6]。将检索到的1 849篇文献题录信息(主要包括篇名、关键词、摘要、作者、参考文献等字段)导入到CiteSpace Ⅲ软件中。有关大数据研究的第一篇文献的发表于1993年,即所检索到的文献时间范围是1993-2014年,共计22年,以每2年设为1个时间分区(Time slicing),总共分为11个时间段;主题词来源(Term Source)选择标题(Title)、摘要(Abstract)、关键词(Author Keywords)和标识符(Keywords Plus);分析节点(Node Types)选择共引文献(Cited Reference);设置阀值(c,cc,ccv)为(2,2,15),(3,2,20),(4,3,20),c为最低被引次数,cc为本时间段内的共被引次数,ccv为规范化以后的共被引次数,每个时间段中选取被引次数最高的30篇文献。运行CiteSpace Ⅲ软件,得到大数据研究共引分析文献网络组图和知识图谱,就此分析关键节点文献。主题词类型(Term Type)有名词短语(Noun Phrases)和突现词(Burst Terms)两种,名词短语可以表达大数据的研究热点,而突现词则可表达大数据的研究前沿及发展趋势。
2 结果与分析
2.1 大数据研究文献的时间分布情况
对WOS数据库中大数据研究文献按年代变化进行时间分布分析,如图1所示,从图中可以看出,大数据的研究可以分为3个阶段:第一阶段从1993-2007年,为大数据的孕育阶段,该阶段大数据研究成果零散,发文量十分有限;第二阶段从2008-2011年,为大数据研究的起步阶段;第三阶段从2012-2014年,为大数据研究的上升阶段,研究文献剧增,且年发文量大于200篇,呈现出快速增长的态势,2014年的文献数据不全,但已有600篇,由此可以预测未来大数据的研究将保持迅猛增长的势头。同时,通过Logistic曲线拟合文献量的时间序列分布,发现大数据研究还处在快速上升时期,还没出现成熟前的“拐点”。
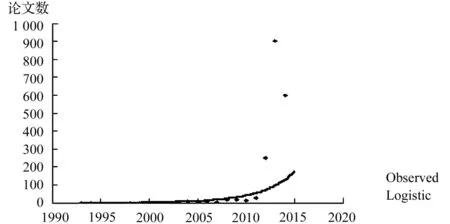
图1 大数据研究文献的年度时间分布
2.2 大数据研究的演进路径分析
信息可视化软件CiteSpace Ⅲ有两种显示共引网络图谱的视图方式,分别为聚类视图(cluster views)和时区视图(time-zone views)。时区视图的显示方式突出共引网络节点随时间变化的结构关系[6]。运行CiteSpace Ⅲ软件得到大数据研究文献共引网络节点的时区视图,图谱中共有182个节点,410条连线,如图2所示。

图2 大数据共引网络节点的时区视图
CiteSpace Ⅲ最突出的特点就是关键节点的计算测量,图中每个圆形节点代表一篇引文,节点大小与被引用次数有关,节点越大,被引频次越高,其文献价值也越大,当设置“标签字体大小依比例显示选项”后,被引频次高的引文在图中的字体也越大,同时,节点间的连线代表引用关系与引用时间,连线越粗则引用次数越多,连线颜色则提示引用时间,依时间先后序列由冷色向暖色改变[7]。从知识理论的角度看,关键节点文献通常是在该领域中提出重大理论或是创新概念的文献,也是最容易引起新的研究前沿热点的关键文献[8]。按被引频次的大小,表1列举出了图2中排名前六位的有关大数据研究关键节点文献,这些文献都是大数据研究的知识基础,结合图2,按时间顺序对表1中的关键节点文献进行分析,即可梳理出大数据研究发展的演进路径。
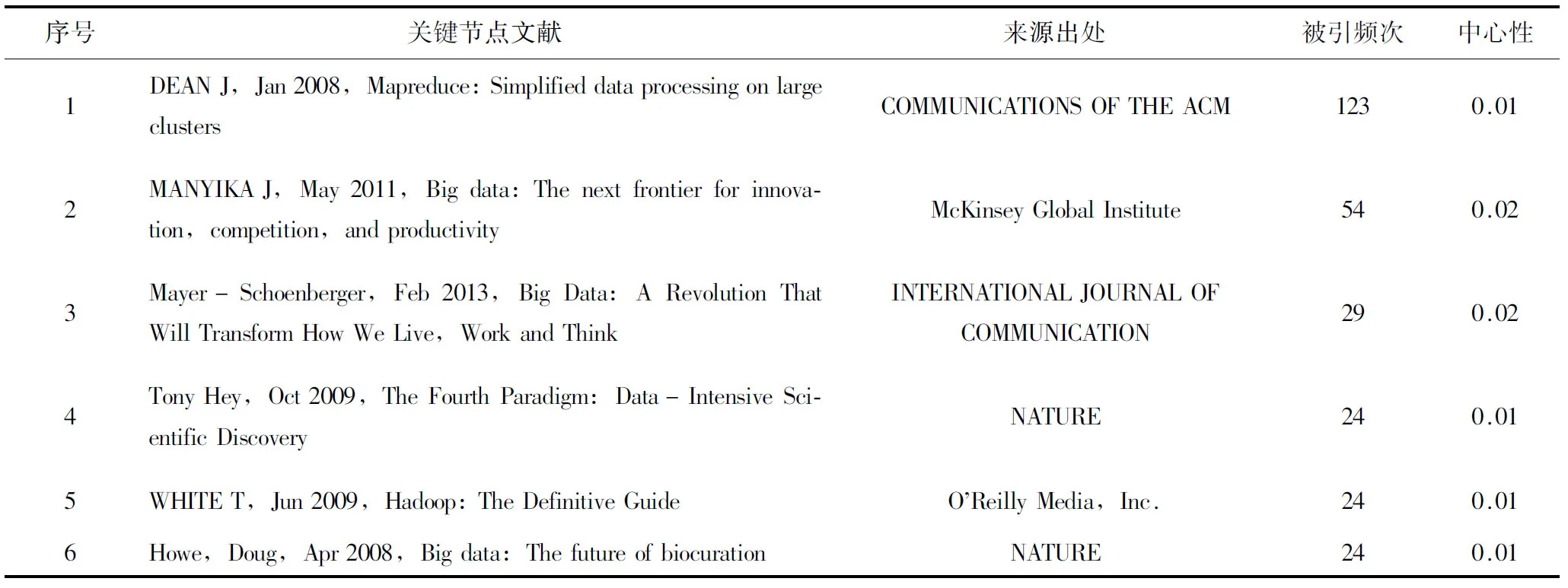
表1 大数据研究关键节点文献
第一篇文献是由MapReduce、BigTable 等系统的创造者Jeff Dean于2008年发表在《COMMUNICATIONS OF THE ACM》刊物上的《Mapreduce:Simplified data processing on large clusters》[9],文章借鉴函数式编程语言,强调了MapReduce的思想,将MapReduce模型用于大规模数据集的并行运算,包括“分布grep,分布排序,web连接图反转,每台机器的词矢量,web访问日志分析,反向索引构建,文档聚类等”。这说明借助关键技术对大规模数据进行深入的研究,最大限度地提升管理和使用大规模数据的能力开始成为研究的重点。
第二篇文献是由Howe,Doug于2008年发表在《NATURE》杂志上的《Big data:The future of biocuration》[10],文章基于大数据环境,提出了“生物文献数据结构化”这一概念,通过数据结构化来规范生物文献信息,从而提高生物学信息的获取率和利用率。这标志着大数据的研究在生物学学科得到广泛关注。
第三篇文献是由英国e-Science计划前首席科学家Tony Hey于2009年发表在《NATURE》杂志上的《The Fourth Paradigm:Data-Intensive Scientific Discovery》[11],该文探索了数据密集型计算以及未来计算技术的发展,揭示出数据分析已经成为继理论、实验和计算之后的第四种科学发现基础,是产生经济价值的新源泉。数据分析有助于市场预测、社会学以及医学等学科领域的知识规律发现和趋势预测,达成“真理尽在数据中”的效果,“数据科学”逐渐成为业界学者研究的新兴领域。
第四篇文献是由WHITE T撰写的《Hadoop:The Definitive Guide》[12]一书,于2009年由O’Reilly Media,Inc.出版社出版,书中展示了如何使用Hadoop构建可靠、可伸缩的分布式系统,程序员可从中探索如何分析海量数据集,管理员可以了解如何建立与运行Hadoop集群。作为处理海量数据集的理想工具,Apache Hadoop架构是MapReduce算法的一种开源应用,是Google(谷歌)开创其帝国的重要基石,更是打开“数据金矿”大门的金钥匙。
第五篇文献是由麦肯锡全球研究院(MGI)于2011年发布的研究报告《Big data,The next frontier for innovation,competition,and productivity》[1],该报告系统的阐述了大数据概念,麦肯锡认为,“大数据”是指其大小超出了典型数据库软件的采集、储存、管理和分析等能力的数据集。该定义有两方面内涵:一是符合大数据标准的数据集大小是变化的,会随着时间推移、技术进步而增长;二是不同部门符合大数据标准的数据集大小会存在差别。同时,报告详细列举了大数据的核心技术,深入分析了大数据在美国医疗卫生、欧洲联合公共部门管理、美国零售业、全球制造业和个人地理位置信息5个领域的应用,明确提出了政府和企业决策者应对大数据发展的策略。作为第一份从经济和商业维度诠释大数据发展潜力的研究成果,揭示出数据正在成为有形资本、人力资本这类产品的一个因素,如何让商业适应大数据,如何让大数据的更有利的管理和更有价值的分析,是一个全新的具有挑战的话题。
最后一篇是由被誉为“大数据商业应用第一人”的Mayer-Schoenberger于2013年在《INTERNATIONAL JOURNAL OF COMMUNICATION》杂志上发表的《Big Data:A Revolution That Will Transform How We Live,Work and Think》[13],文中前瞻性地指出,大数据带来的信息风暴正在变革我们的生活、工作和思维,大数据开启了一次重大的时代转型,其中最大的转变就是,放弃对因果关系的渴求,而取而代之关注相关关系。也就是说只要知道“是什么”,而不需要知道“为什么”,这就颠覆了千百年来人类的思维惯例,对人类的认知和与世界交流的方式提出了全新的挑战。该文还提出大数据的核心就是预测。大数据将为人类的生活创造前所未有的可量化的维度。大数据已经成为新发明和新服务的源泉,而更多的改变正蓄势待发,例如谷歌、微软、亚马逊、IBM、苹果、facebook、twitter、VISA等大数据先锋们已经开启了对大数据最具价值的应用历程。因此,该关键节点论文是大数据应用在大数据时代的一个重要标志。
通过以上关键节点文献的分析,可以得出,在2008年之前,由于大数据理论和基础比较缺乏,有关大数据研究的论文发文量比较低,且没有产生具有影响力的文献。从2008年开始,随着研究的不断深入,进入大数据领域进行研究的机构、学者等不断增加,有关大数据研究的论文发文量急剧增长,产生了许多重要的研究成果。大数据的研究经历了从大数据的计算模型、具体概念、复杂性科学的理论研究,到伴随大数据研究技术的全面拓展而进行的有关大数据社会科学层面、应用型实践层面研究的历程。
2.3 大数据研究热点分析
由于关键词是作者对文章核心内容的精炼与概括,体现文章研究价值与方向,因此在软件分析结果中,频次高的关键词常被用来确定一个研究领域的热点问题,另外,从文章中提取的名词短语也可以在一定程度上代表某学科的研究热点[14]。在CiteSpace Ⅲ软件中,节点类型选择关键词(Keyword)、主题词类型选择名词短语(Noun Phrases),并选择Pathfinder算法,运行CiteSpace Ⅲ软件得到由关键词和名词短语生成的大数据研究热点知识图谱,图谱中有342个节点,1 076条连线,如图3所示。

图3 大数据研究热点知识图谱
图3中的圆形节点和方形节点分别代表关键词和名词短语,节点的大小表示关键词或名词短语出现的频次,圆形节点越大,越可以体现大数据的研究热点,同样,方形节点越大,也在一定程度上代表了大数据的研究热点。选取出现频次大于等于40的热点名词术语,得到大数据研究热点词汇统计表,见表2。
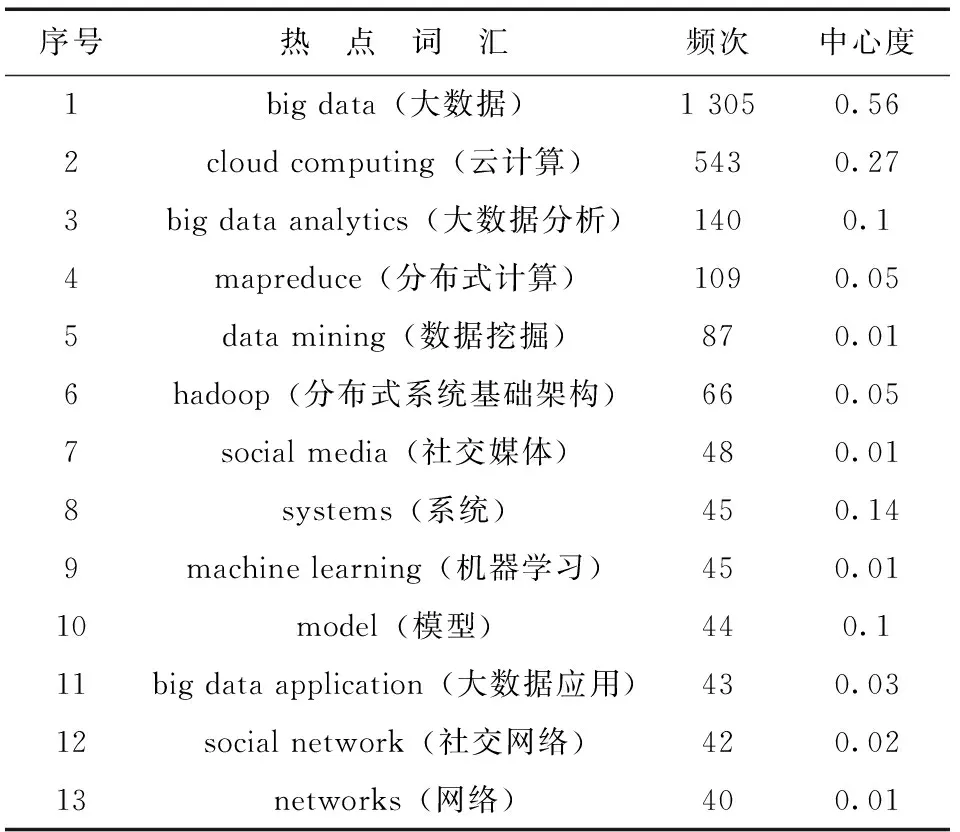
表2 频次大于等于40的热点词汇统计表
从图3和表2可以看出,出现频次最高的热点词为big data(大数据),达1 305次,且其中心度值(0.56)也位居首位,一方面,表明了选择“big data”为本文的研究主题具有一定的明确性;另一方面,也说明“big data”这一表述在学术界被普遍认可,且对大数据的研究也极其重视。其他高频热点词汇按出现频次高低分别为:cloud computing(云计算)、big data analytics(大数据分析)、mapreduce(分布式计算)、data mining(数据挖掘)、hadoop(分布式系统基础架构)、social media(社交媒体)、machine learning(机器学习)、model(模型)、big data application(大数据应用)、social network(社交网络)、networks(网络),同时,这些热点词汇正是前文所述多数关键节点文献研究的主要内容。
目前,大数据的研究热点可以从以下3方面来分析:(1)大数据处理技术的研究。这一研究热点主要涉及云计算、大数据分析、Hadoop、Mapreduce、模型等技术,尤其是Hadoop、Mapreduce带来的并行式和分布式算法,为更高效率的管理和处理海量数据集带来了可能。同时,云计算模式为大数据提供了存储空间和计算能力,是大数据处理技术的基础。(2)大数据挖掘的研究。这一研究热点主要涉及云计算、社交网络、社交媒体、数据分析、数据挖掘等。社交媒体、社交网络的普及产生了大量的数据,而沉睡的数据只是一堆低价值密度的垃圾,只有通过数据挖掘,才能发现和创造其潜在的价值,同时,大数据挖掘的实现也需要云计算技术支持。在业界,IT巨头们如:Google、微软、EMC、IBM、惠普等互联网公司都已经意识到大数据挖掘的重要意义,纷纷通过收购大数据分析公司,进行技术整合,希望从大数据中挖掘更多的商业价值[15]。(3)大数据应用的研究。这一研究热点主要涉及大数据应用、数据分析、机器学习等。与传统数据分析相比,大数据技术的核心目标之一即是从数据量大、数据结构类型多样的数据中挖掘信息和获取知识,而大数据技术这一目标的实现离不开机器学习的技术。通过机器学习高效智能地获取新知识,为数据分析应用带来价值是当今大数据应用研究的一大重点。
2.4 大数据研究前沿分析
陈超美认为,使用突现主题术语( surged topicalterms)要比使用出现频次最高的主题词(title words)更适合探测学科发展的新兴趋势和突然变化[16]。运用CiteSpace Ⅲ软件的突现词探测(Detect Bursts)技术,观察词频的时间分布,将突现词(Burst Terms)从大量的主题词中探测出来,从而揭示出大数据的研究前沿。主题词类型选择突现词(Burst Terms),运行CiteSpace Ⅲ软件,得到大数据研究前沿的网络图谱,如图4所示。探测得到10个突现词,见表3。

图4 大数据研究前沿的网络图谱
结合图4和表3可以看出,突变率最高的主题词为是“big data(大数据)”,达5.74,该主题词代表了大数据领域对大数据本身的研究,而且,对大数据本身的研究依旧可能是未来大数据研究的热点。除“big data(大数据)”以外,“mapreduce(分布式计算)”、“cloud computing(云计算)”、“hadoop(分布式系统基础架构)”这3个主题词的突变率也较高,说明mapreduce框架、云计算、hadoop框架的数据处理技术近年来备受研究者关注。同时,与数据处理技术有关的“data mining(数据挖掘)”、“systems(系统)”、“model(模型)”、“networks(网络)”,这4个主题词的突变率也比较高,分别是3.87、3.21、3.15和3.12,由此可以看出与大数据有关的数据挖掘、系统、模型及网络的研究是近年来大数据领域研究的重要前沿与发展趋势。此外,“performance(绩效)”和“management(管理)”这2个高突变词也说明了近年来大数据在绩效评估和数据管理方向研究的重视,有关大数据的绩效评估和数据管理也将成为未来几年内大数据研究的重点。
3 结 论
CiteSpace Ⅲ信息可视化软件具有较强的探测和分析某一学科演化路径、研究热点与研究前沿的功能,在上述大数据研究中得以完美体现,通过对Web of Science数据库中收录的有关大数据研究的文献进行聚类分析和共引分析,得到以下结论:
(1)大数据研究的演进路径:2008年,强调了MapReduce的思想,对大规模数据集进行并行运算,同时,大数据的研究开始向生物学学科渗透;2009年,探索了数据密集型计算以及未来计算技术的发展,揭示出数据分析已经成为继理论、实验和计算之后的第4种科学发现基础,并且,数据处理技术Hadoop的应用,为更高效的处理海量数据集带来了可能;2011年,系统地阐述了大数据概念,并介绍了大数据的核心技术,深入分析了大数据在不同领域的应用,明确提出了政府和企业决策者应对大数据发展的策略。2013年,前瞻性地指出了大数据带来的信息风暴正在变革我们的生活、工作和思维,大数据开启了一次重大的时代转型。
(2)大数据的研究热点概括为3个方面:一是大数据处理技术的研究;二是大数据挖掘的研究;三是大数据应用的研究。研究的内容逐渐从“概念化”走向“价值”。
(3)大数据的研究前沿有4个:一是对大数据本身的研究;二是有关大数据处理技术的研究;三是与大数据处理技术有关的数据挖掘、系统、模型和网络的研究;四是大数据绩效评估和数据管理的研究。海量数据的存储、管理、转换、绩效评估等问题,以及大数据在社会科学层面和应用型实践层面的研究将可能是大数据未来一段时间内的深度挖掘的方向和研究趋势。
[1]Big data:The next frontier for innovation,competition,and productivity[EB/OL].http:∥www.Mckinsey.com/insights/business technology/big data the next frontier for innovation,2014-10-12.
[2]科技中国.大数据时代[EB/OL].http:∥www.techcn.com.cn/index.php?Edition-view-185281-2.html,2014-10-12.
[3]中国云计算.大数据大事业-白宫发布大数据研究和发展倡议[EB/OL].http:∥www.chinacloud.cn/show.aspx?id=9349&cid=17,2014-10-12.
[4]赵蓉英,徐灿.信息服务领域研究热点与前沿的可视化分析[J].情报科学,2013,(12):9-14.
[5]百度百科.Web of Science[EB/OL].http:∥baike.baidu.com/view/3511061.htm?fr=aladdin,2014-10-12.
[6]Chaomei Chen.CiteSpace Ⅱ:Detecting and visualizing emerging trends and transient patterns in scientific literature[J].Journal of the American Society for Information Science and Technology,2006,57(3):359-377.
[7]赵智慧.文化遗产数字化研究演进路径与热点前沿的可视化分析[J].图书馆论坛,2013,(2):33-40.
[8]侯剑华,陈悦,王贤文.基于信息可视化的组织行为领域前沿演进分析[J].情报学报,2009,(3):422-430.
[9]DEAN J.Mapreduce:Simplified data processing on large clusters[J].COMMUNICATIONS OF THE ACM,2008,1(51):107-113.
[10]Howe D,Costanzo M,Fey P,et al.Big data:The future of biocuration[J].Nature,2008,455(7209):47-50.
[11]Tony Hey.The Fourth Paradigm:Data-Intensive Scientific Discovery[J].Nature,2009,462(7274):722-723.
[12]WHITE T.Hadoop:The Definitive Guide[M].USA:O’Reilly Media,Inc,2009:15-73.
[13]Mayer-Schoenberger.Big Data:A Revolution That Will Transform How We Live,Work and Think[J].INTERNATIONAL JOURNAL OF COMMUNICATION,2013,(7):2727-2729.
[14]赵蓉英,许丽敏.文献计量学发展演进与研究前沿的知识图谱探析[J].中国图书馆学报,2010,(5):60-68.
[15]何清.大数据与云计算[J].科技促进发展,2014,(1):35-40.
[16]陈超美.CiteSpace Ⅱ:科学文献中新趋势与新动态的识别与可视化[J].陈悦,等译.情报学报,2009,28(5):401-421.
(本文责任编辑:马 卓)
Visualization Analysis of Evolution Path,
Research Hotspots and Frontiers of Big Data
He Xiaoping Huang Long
(Library,Nanchang University,Nanchang 330031,China)
This paper used the literatures which were retrieved from the Web of Science with the capital of Big Data as data sources,and conducted the cluster analysis and co-citation by means of the information visualization software CiteSpace Ⅲ.Based on the knowledge mapping generated by Citespace Ⅲ and the relevant literature,it performed statistical analysis and data interpretation from three perspectives,namely,research hotspots,subject content and developing trends.6 critical node documents perfectly showed the evolution path of big data;13 high frequency keywords and 5 burst terms indicated the research hotspots and research fronts.Conclusion:the research of big data had experienced a process which from the big data calculation model,the specific concept,the theory research of complexity science to the research on big data of social science level and applied practice level,three research hotspots:big data processing,data mining and data application,the research frontier and developing trend of big data:the study of big data itself,the research of processing technology,the research of data mining and system,model and network,data management and performance evaluation,this paper aimed at providing the reference for carrying out the present research of big data.
big data;CiteSpace Ⅲ;evolution pathway;research hotspots;research frontiers;visualization
2014-12-15
何晓萍(1955-),女,教授,研究方向:情报学、图书馆学、教育技术学。
10.3969/j.issn.1008-0821.2015.04.010
G252
A
1008-0821(2015)04-0046-06
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
加油站服务指南(2022年6期)2022-07-28
云南化工(2021年8期)2021-12-21
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
车迷(2019年10期)2019-06-24
快乐语文(2018年7期)2018-05-25
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
