
基于信令数据的交通出行分布异常检测
2015-04-13 04:14李纪华刘建玲肖瑞
移动通信 2015年21期
李纪华,刘建玲,肖瑞
(中国联合网络通信有限公司北京市分公司,北京 100038)
1 引言
基于信令数据在交通领域的挖掘应用具有很大价值,由于目前智能移动终端的渗透率越来越高,因此移动信令的数据包含了用户的出行行为特征、出行时间及出行地点等信息。这些信息不仅能够用来分析用户的出行偏好和出行方式,还可以预测用户的出行时间分布,为交通部门、城市规划部门提供巨大的参考意义。基于信令数据的交通出行分布异常检测的方法不仅能够轻量级反映用户的出行分布规律以及出行异常情况,大大提高城市交通部门的信息化水平,而且能够节省城市交通部门昂贵的硬件支出与维护,因此受到了越来越多研究者的关注。
2 异常检测的方法
异常检测又叫偏差检测,其目的是把不满足一定分布或者反常的对象找出来,以达到管理异常对象的目的。异常检测的方法有以下5种:
(1)基于分布的方法
基于异常分布的方法的原理是通过分析整个数据集的分布规律,例如二项分布、泊松分布或正态分布等,利用概率等原理发现一些分布不一致的数据。该方法的优点是具有较高的异常检测效率,但缺点就是使用者很难确定数据集的分布。
(2)基于深度的方法
基于深度的方法的原理是通过把数据映射到数据集的K维向量中,然后赋给数据一个深度值,最后利用异常检测的方法把深度较小的值找出来。该方法的优点是可以计算高维数据的异常性,缺点是该算法随着数据维度的增大计算复杂度迅速增加,导致检测效率大大降低。
(3)基于距离的方法
基于距离的方法的原理是通过计算1个点O在一定距离D内的数量,如果数量小于某一个阈值,则判定O点为异常点。该算法的优点是容易使用,在实际场景使用较多,但缺点也很明显:对线性分布的数据异常检测的准确性很低。
(4)基于聚类的方法
基于聚类的方法的原理是通过对相似性的计算,找出数据集中不同的类簇,对小类簇进行判别从而得出异常对象。该算法的优点是不需要考虑数据的分布以及聚类的种类,适用于海量数据的检测,缺点是由于利用相似性进行数据的度量,因此处理高维数据时效率相对较低。
(5)基于密度的方法
基于密度的方法的原理是通过测量给定范围的密度,如果该密度超出一定阈值,那么可以认定该范围是异常区域。该算法的优点是计算简单,能够很好处理不同密度的区域,缺点是计算复杂度很高,对于高维数据的计算效率相对较低。
3 基于空间密度聚类方法进行交通出行 分布异常检测
基于空间密度聚类方法进行交通出行分布异常检测主要解决的技术问题是如何利用移动运营商一系列的信令数据进行分析挖掘,从而识别交通出行分布的异常,通过结合移动通信技术和大数据挖掘技术,使得交通部门及城市建设规划部门能够降低分析用户出行状态的成本,通过用户出行的规律间接反映城市道路交通结构的合理性,为智慧交通的建设提供很好的支撑作用。
3.1 DBSCAN算法的介绍
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)的基本原理是:对于簇中的每一个点,在设定的半径范围内至少包括设定数据的点。该算法把具有足够密度的区域划分成一类,优点是对于带“噪音”的空间数据可以发现任何形状的聚类,聚类速度很快。
3.2 基于DBSCAN算法的交通出行分布异常检测 过程
(1)通过小区切换法识别道路上的用户
拥有智能手机的用户在道路上发生语音或者数据业务的时候,信令会记录用户在连续多个小区发生的小区切换,如果一个用户在一段时间内连续发生多个小区切换的现象,则认为该用户的地理位置在道路上。表1是通过对信令数据提取的字段表:
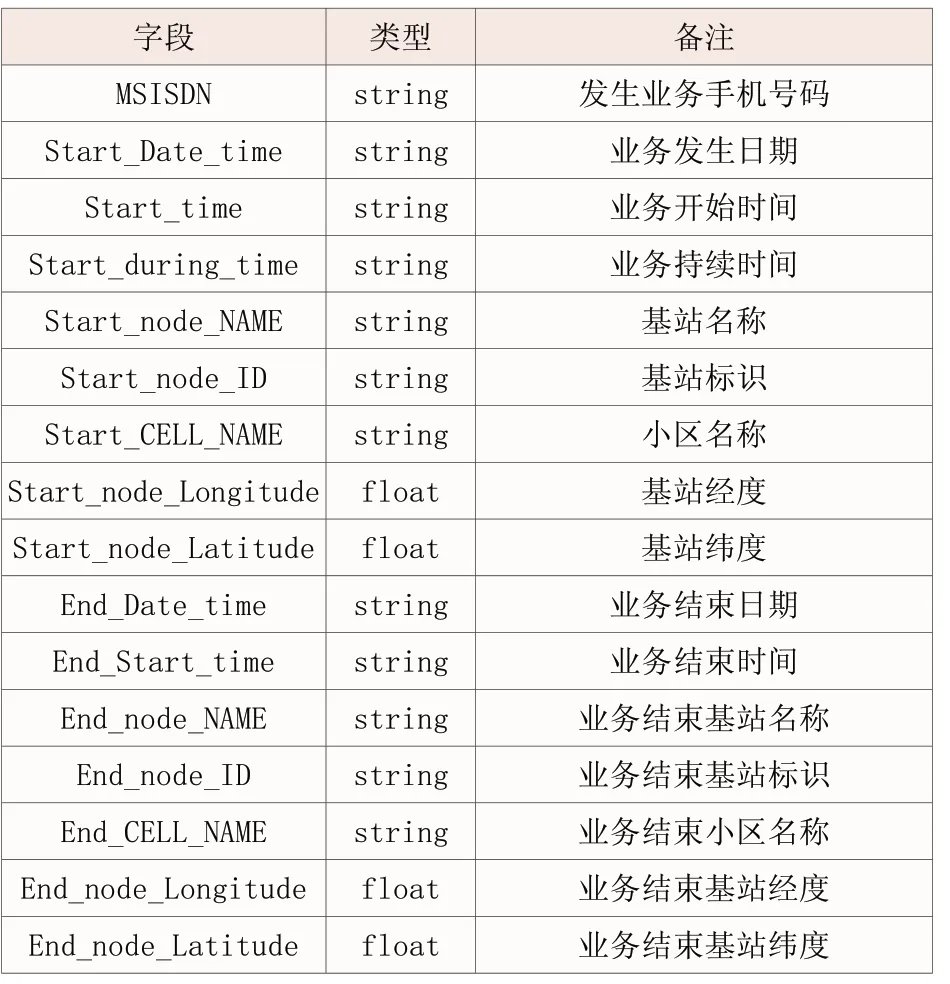
表1 基于小区切换法识别道路上用户
(2)基于手机信令的用户定位
1)路测方式获得用户定位的信息库
本文首先把道路划分成一个30m×30m的网格,然后利用路测方式确定每一个网格可能接收到的小区数量以及相应的场强,建立小区-网格定位的位置信息库。
2)位置信息库匹配定位的过程
信息库定位算法最大特点就是仅仅通过小区就能实现用户的定位,无需增加额外的设备。位置识别依靠表征目标特征的数据库进行,其定位过程主要包括训练阶段和定位阶段,具体如下:
◆训练阶段的目标在于建立一个位置信息识别数据库。首先选择参考点分布,确保能为定位阶段的准确位置估计提供足够的信息。接着依次在各个参考点上测量来自不同接收小区的电平,将相应的小区号码与参考点的位置信息记录在数据库中,直至遍历关注区域内所有的参考点。
◆在定位置信息识别数据库后,依据一定的匹配算法将待测点上接收的小区号码、电平值与数据库中的已有数据进行比较,计算位置估计值。
3)基于KNN算法的位置识别
KNN(K-Nearest Neighbor,最邻近规则)算法的基本原理是:首先计算测试点与识别库中参考点之间的相似度距离,按照距离的降序选出前k个近邻值,有以下公式:
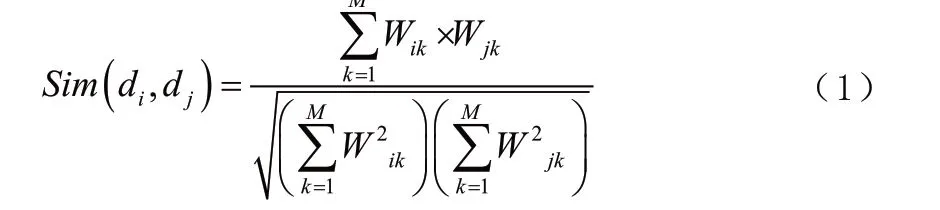
其次计算测试点的k个近邻值每类的权重,计算公式如下:
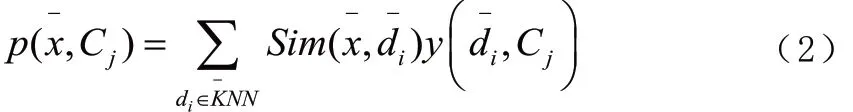
(3)基于DBSCAN的交通出行分布异常检测
1)交通出行分布异常点的确定
通过计算道路上出行用户的局部密度,当局部密度大于设定的值时,则认为该点是交通出行分布异常点(异常点也就是异常网格),有如下公式:

其中,γi表示道路网格数据集与网格xi之间的距离小于设定距离的网格个数;δi表示设定的局部距离,一般该道路的总网格长度的1%~2%为最佳距离。
2)交通出行分布边界的确定
一旦确定出行异常点,下一步就是对非异常网格进行归类,具体步骤是:按照网格的密度从大到小进行遍历;通过密度获得每一个异常点的网格编号;按照密度大小的方法对异常点进行降序,按照每一个异常点所包含的网格密度的顺序确定异常点的边界。按照降序方法的好处在于异常点之间的交叉区域由于先进行了降序的处理而能够快速确定边界。
4 实验结果
本文采用某地市某运营商提供的2015年8月1号到8月28号的IUCS接口数据和IUPS接口数据,IUCS数据约为3TGB,IUPS数据约为15TGB,包含400多万用户的数据,其中IUCS数据约150亿条,IUPS数据约200亿条,实验结果如图1所示:
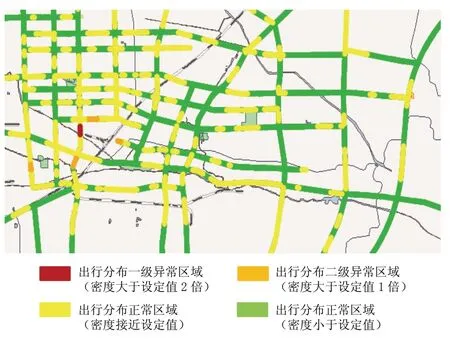
图1 交通出行分布异常检测图
该系统是基于20个集群搭建的Hadoop平台进行数据处理和分析,采用SSH框架实现Web的加载与渲染,以每0.5h为颗粒度来展现某地市道路出行分布异常检测情况。本文把基于DBSCAN算法找出的交通异常点发生的区域与实际的交通路况进行验证,情况基本比较吻合。
5 结束语
基于信令数据的交通出行分布异常检测的方法不仅能够快速发现交通出行分布的异常检测,而且具有投资小、数据采集简便、实用性强及计算复杂度小的优点,因此应强化其在智慧交通领域的应用。
[1] ESTER M, KRIEGEL H, SANDER J, et al. A densitybased algorithm for discovering clusters in large spatial databases with noise[C]. Portland: AAAI Press, 1996: 226-231.
[2] QIAN Wei-ning, GONG Xue-qing, AO Ying-zhou. Clustering in very large databases based on distance and density[J]. Journal of Computer Science and Technology, 2003,18(1): 67-76.
[3] ZHOU Shui-geng, ZHOU Ao-ying, CAO Jing, et al. A fast density-based clustering algorithm[J]. Journal of Computer Research and Development, 2000,37(11): 1287-1292.
[4] ESTER M, KRIEGEL H P, SANDER J, et al. Incremental clustering for mining in a data warehousing environment[C]. New York: Morgan Kaufmann, 1998: 323-333.
[5] Alex Rodriguez, Alessandro Laio. Clustering by fast search and find of density peaks[J]. Science, 2014,344(6191): 1492-1498.
[6] Rakesh A, Johanners G, Dimitrios G, et al. Automatic subspace clustering of high dimensional data for data mining applications[J]. Data Mining & Knowledge Discovery, 1994,27(2): 94-105.
[7] Hans-Peter Kriegel, Peer Kroger, Alexey Pryakhin, et al. Effective and efficient distributed model-based clustering[C]. Houston: Data Mining, 2005(11): 8-19.
[8] Maria Halkidi, Michalis Vazirgiannis. Clustering validity assessment: Finding the optimal partitioning of a data set[C]. California: Data Mining, 2001: 187-194.
[9] 熊忠阳,孙思,张玉芳,等. 一种基于划分的不同参数值得DBSCAN算法[J]. 计算机工程与设计, 2005,26(9): 2319-2321.
[10] 杨静. 分层模糊最小——最大聚类算法及其在图像聚类中的应用研究[D]. 合肥: 合肥工业大学, 2007.
[11] 许慧. 基于数据分区和QR*树的并行DBSCAN算法研究[D]. 哈尔滨: 哈尔滨工程大学, 2007. ★
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
铁路通信信号工程技术(2019年10期)2019-11-06
数学年刊A辑(中文版)(2019年3期)2019-10-08
中国交通信息化(2019年2期)2019-03-25
消费导刊(2017年24期)2018-01-31
电子测试(2017年15期)2017-12-18
北京航空航天大学学报(2017年6期)2017-11-23
雷达学报(2017年6期)2017-03-26
浙江大学学报(工学版)(2016年10期)2016-06-05
互联网天地(2016年2期)2016-05-04
