
核心网网管数据清洗及应用初探
2015-04-13 04:40高承山李福庆中讯邮电咨询设计院有限公司河南郑州450007
邮电设计技术 2015年12期
高承山,张 勇,李福庆(中讯邮电咨询设计院有限公司,河南郑州450007)
0 前言
目前,中国联通核心网网管数据主要包括2G、3G和4G网管指标,其中2G和3G网管指标已经纳入中国联通综合网管,而4G网管指标仍然分散于各厂家的专业网管中。由于核心网网元众多、网管数据来源复杂,业内缺乏完善的网管数据收集和管理的手段,因此对工程建设过程中前期规划建设阶段的指导作用有限。为了解决这些问题,笔者及同事开发了核心网网络建设运行支撑平台,该平台通过各种自动化工具对核心网网管数据进行自动整理分析汇总,为核心网网络建设提供技术支撑。本文主要介绍该平台所采用的一些技术。
1 系统概述
核心网网管数据的分析包括两部分。
a)后台数据处理:包括数据清洗入库和多维分析。核心网网管指标体系按照设备分为MSC Server、MGW、SGSN/MME、GGSN/GW、HLR/HSS 等5 种类型。由于设备存在入网、割接、调整、故障等各种非正常状态,厂家网管和综合网管之间北向接口对接问题等都会影响网管数据质量,因此网管数据入库后需要进行清洗。清洗后的数据,可以根据需求进行各种维度分析,如按照时间维度、地域维度等提取忙时数据。
b)前端数据展示:将后端处理之后的数据,通过可视化的Web 界面展示给用户,为规划、建设及业务发展提供决策支持。
根据上述需求,核心网网络建设运行支撑平台的系统架构如图1所示。
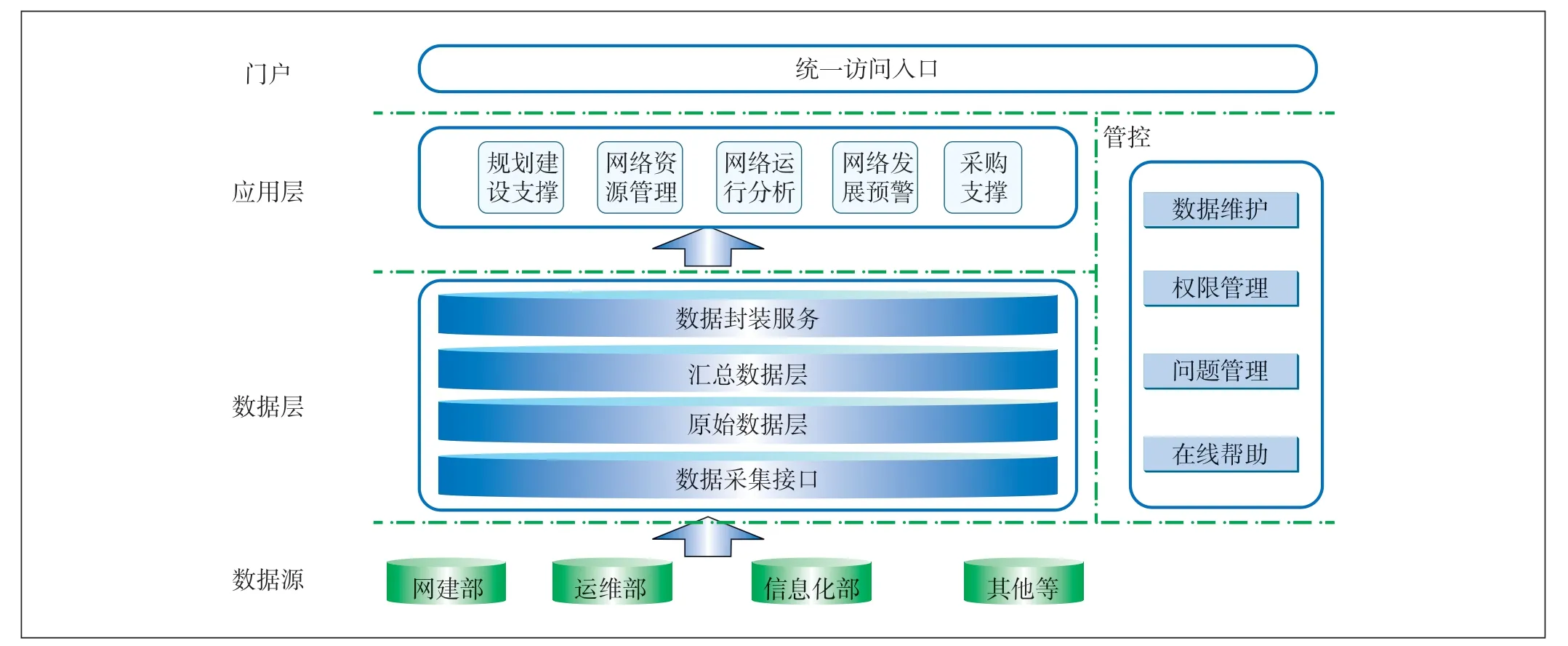
图1 核心网管数据分析管理平台架构
系统架构包括数据源、数据层、应用层、门户等几个模块,其中数据层主要负责后端的数据处理,源数据经过采集、清洗、入库、多维分析后,以数据服务的形式提供给前端应用层展示。
本文着重介绍数据层所采用的数据清洗及分析技术。
2 网管数据入库
2.1 网管报表细分
综合网管报表包含MSC Server、MGW、SGSN/MME、GGSN/GW、HLR/HSS 5 种设备类型的2G/3G 报表,每种设备类型包含配置报表和性能报表,共11 种类型的报表(其中MSC Server 的性能指标分布在2 个性能报表中),每种类型报表为1个CSV文件。其中性能报表为24 h报表:每套设备每个小时提取一次记录;配置报表为日报表:每套设备每天提取一次记录。每天的网管数据量约为11 个CSV 文件6 万行记录,共200个性能指标及70个配置指标。
厂家网管报表按照厂家和设备类型分省提取4G指标,目前共5个厂家、3种设备类型,分省提取约100个左右的CSV文件(见表1)。
2.2 ETL 工具简介
由于需要入库的文件、记录数较多,使用数据库本身提供的功能不能满足自动入库的需求,本文使用开源ETL工具Kettle对网管报表进行自动入库及清洗。
Kettle 是一款开源ETL 工具,其包含2 种脚本文件:转换和作业。其中转换是ETL 解决方案中最主要的部分,它负责对数据进行抽取、转换、过滤等操作,转换包括一个或多个步骤,如读取文件、过滤输出行、数据清洗或将数据加载到数据库;作业则完成对整个工作流的控制,一个作业包括一个或多个作业项,这些作业项以某种顺序来执行。
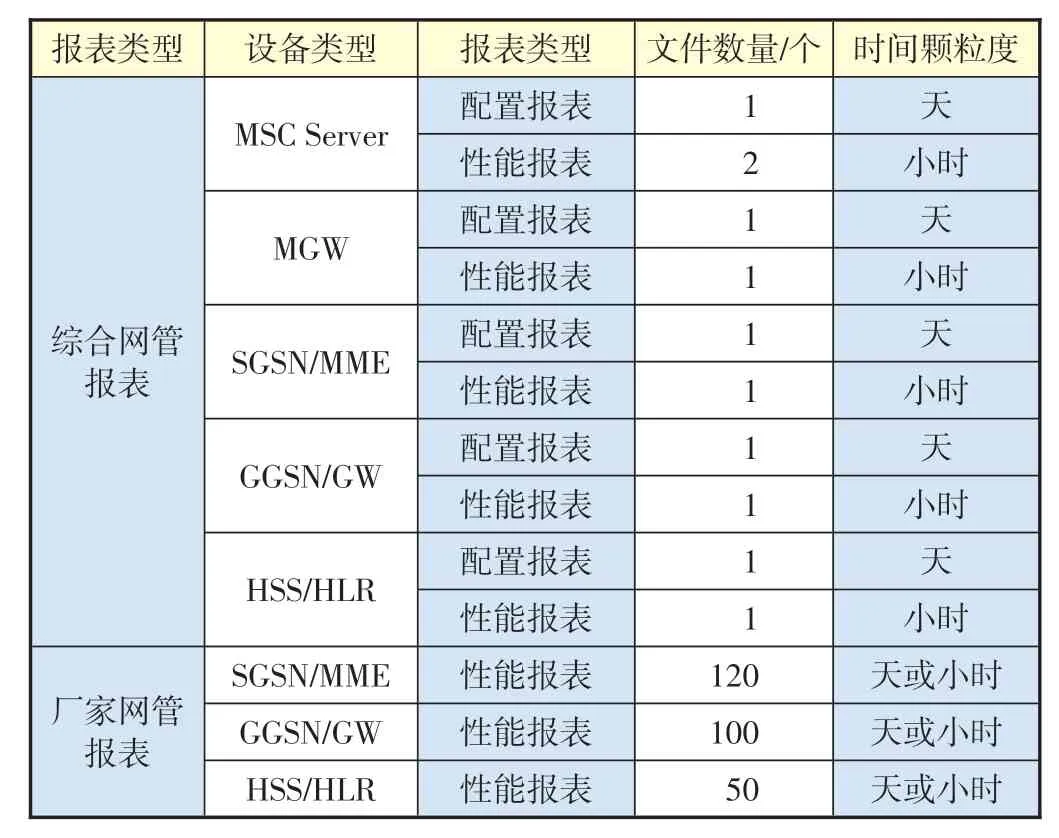
表1 网管报表信息
Kettle 工具集共包括4 个产品:Spoon、Pan、Chef、Kitchen。
Spoon:通过图形界面(GUI)设计ETL转换过程。Pan:通过命令行方式(CMD)批量执行由Spoon设计的ETL转换(例如使用时间调度器)。
Chef:通过图形界面(GUI)方式创建作业。
Kitchen:通过命令行方式(CMD)批量执行由Chef创建的作业。
2.3 网管数据入库
将定期获取的CSV 文件报表保存在“拟上传报表”文件夹中,针对每种类型的报表创建一个转换,将创建的所有转换加入到作业中,使用时间调度器定期执行作业,通过此过程可以完成网管数据的自动入库功能。
下面以MSC Server的性能报表为例,来说明Kettle转换的创建。
a)将提取到的网管报表CSV文件保存至“拟上传报表”文件夹中。
b)Kettle 转换过程根据通配符自动从“拟上传报表”文件夹中提取相应的报表文件。
c)Kettle转换逐行读取报表文件中的记录。
d)Kettle 根据指定的报表表头和数据库字段对应关系将记录保存至数据库。
针对所有类型的报表,需要将各种转换操作加入到作业中,具体如下(见图2)。
a)分类型上传报表,上传完成后需要将“拟上传报表”文件夹中对应文件移动至“已上传报表”文件夹。
b)如果上传错误,则将详细的错误信息以邮件方式发送至监控邮箱。
c)重复上述步骤。
3 数据清洗
由于网络、设备等因素的影响,从综合网管和厂家网管获取的报表数据会存在大量的“脏数据”,即数据存在缺失、噪声、重复等各种问题,如果直接使用会造成后续维度分析的结果出现较大的偏差甚至错误。因此需要对入库后的源数据进行数据清洗,清洗工作可以采用ETL清洗辅助人工清洗方式。
3.1 ETL 清洗
a)数据分析:首先对报表各指标进行分析,通过分析确定数据的错误类型。
b)定义数据检验规则:根据数据分析得到的结果定义数据检验规则,如地(市)名称为空、地(市)名称不在标准的地(市)名称范围内、CPU 利用率大于100%,VLR 登记用户大于正常值、话务量大于正常值等均视为需要验出的错误数据。
c)搜索、识别错误实例:根据数据检验规则,利用ETL 工具对原始表进行逐行检查,将检查出的错误数据字段的相关信息保存在数据库中的错误表中(见表2)。
d)对错误数据进行修正:根据数据库中错误信息表,利用数据库存储过程对错误数据进行修正。如地(市)名称为空,则需要根据设备ID 生成地(市)名称;如果地(市)名称不是标准的地(市)名称,则需要使用标准的地(市)名称进行替换。CPU 利用率、VLR 登记用户数、话务量等数值类型的错误需要用最近时间的正常值进行替换。
3.2 人工清洗
由于ETL清洗是针对全部同类型的设备设置统一规则,清洗后部分设备仍然存在错误数据,此时需要配合人工进行清洗(见图3)。
a)首先需要将ETL 清洗后的记录按照设备维度以曲线显示在Web页面中。
b)各省维护人员按照设备容量及经验判断是否有噪点。
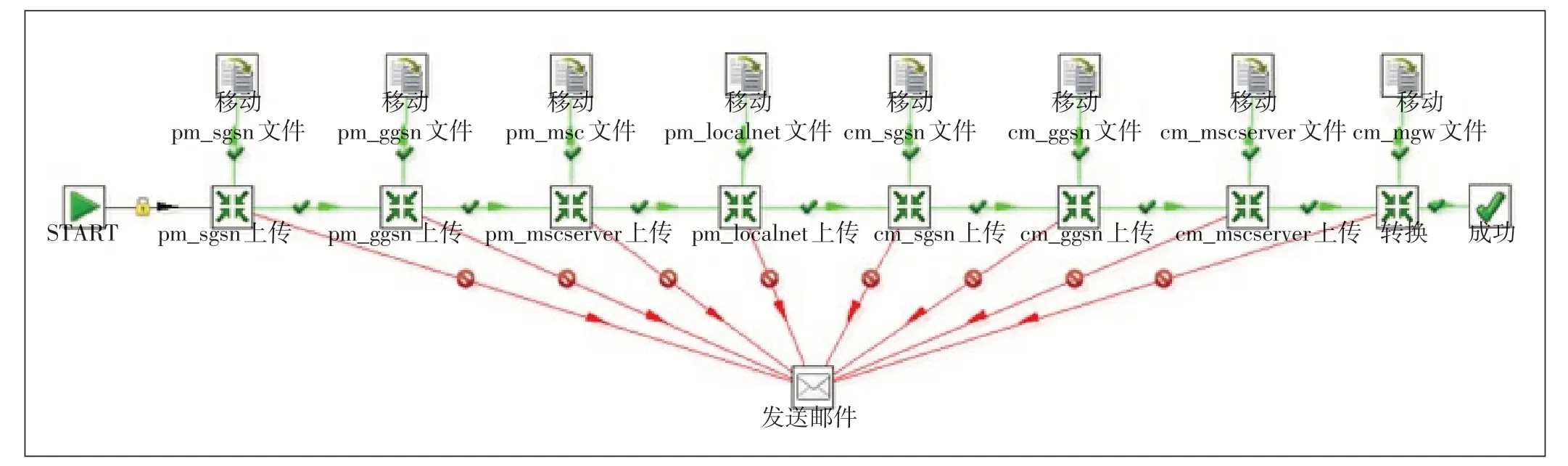
图2 Kettle作业流程示例

表2 数据库错误信息表

图3 通过Web图形进行人工校验数据
c)对噪点数据进行人工修改。
4 多维分析
为了向规划、建设及运行维护提供决策支持,需要对清洗后的网管数据进行多维度的分析,如端局VLR登记用户数、话务量等指标的各时间维度(日、月、年)的忙时分析和各地域维度(地(市)、省分、全国)的忙时数据分析。在分析过程中使用了开源的多维分析工具Mondrian 及多维查询语言Mdx,以下将介绍分析工具的使用及相关的多维分析流程。
4.1 基本概念
a)多维数据集:多维数据集是联机分析处理(OLAP)中的主要对象,是一项可对数据仓库中的数据进行快速访问的技术。多维数据集是一个数据集合,通常根据数据仓库的子集构造,并组织和汇总成一个由一组维度和度量值定义的多维结构。
b)维度:多维数据集的结构性特性。它们被用于在事实数据表中描述数据的分类和级别,这些分类和级别描述了一些相似的成员集合,用户将基于这些成员集合进行分析。
c)度量值:在多维数据集中,度量值是一组值,这些值基于多维数据集的事实数据表中的一列,而且通常为数字。此外,度量值是所分析的多维数据集的中心值。即度量值是最终用户浏览多维数据集时重点查看的数字数据。
d)维度成员:维度的一个取值称为该维的一个维度成员。
e)多维分析方法:上卷、下钻、切片、切块、旋转,从多个角度、多个侧面观察数据库中的数据。
f)模式:多维数据的事实表、维表、聚集表等存储于数据库中,属于物理模型;而数据立方体、维度、度量这些概念属于逻辑模型。多维分析引擎必须要理解逻辑模型,并能够映射到物理模型上。多维数据的模式就是用来描述这个逻辑模型以及到物理模型的映射的。
4.2 多维分析工具及查询语言
Mondrian 多维分析工具是一个以Java 实现的OLAP引擎。它本身不管理数据的储存,而是通过Mdx语言从关系数据库(RDBMS)中读取数据,然后经过Java API以多维的方式对结果进行展示。
Mondrian OLAP 系统由4个层组成,从最终用户到数据中心。
a)表现层:表现层决定了以何种方式向最终用户显示多维数据集,及它们如何同系统产生交互。表现层可以使用Pivot 表(一种交互式的表)、Pie、Line 和图表(Bar Charts)等方式。
b)维度层:维度层用来解析、验证和执行Mdx 查询要求。一个Mdx 查询要通过几个阶段来完成:首先是计算坐标轴(Axes),再者计算坐标轴Axes 中Cell 的值。
c)集合层:集合层负责维护和创建集合缓存,一个集合是在内存中缓存一组单元值,这些单元值由一组维的值来确定。
d)存储层:存储层是一个关系型数据库(RD⁃BMS)。它负责创建集合的单元数据,和提供维表的成员。
Mdx为MultiDimensional Expressions 的缩写,多维表达式,是标准的OLAP查询语言。
Mdx 很多方面与结构化查询语言(SQL)语法相似,但它不是SQL语言的扩展。
每个Mdx查询都要求有数据请求(select子句)、起始点(from 子句)和筛选(where 子句)。这些关键字以及其他关键字提供了各种工具,用来从多维数据集析取数据的特定部分。Mdx 还提供了可靠的函数集,用来对检索的数据进行操作,同时还具有用户定义函数扩展Mdx的能力。
Mdx基本语法结构:

其中:[axis specification]表示轴的成员选择;[silcer specification]表示切片上的成员,可以看成过滤信息;[silcer specification]为可选项,如果没有指定,取系统默认的维度成员作为切片。
4.3 多维分析示例
以入库后的电路域Msc Server 报表为例进行多维分析。
a)构造多维数据集(Cube)。经过清洗后的数据库表mss_c 为事实表,它可分为2 个维度,时间维度的mss表和地域维度的mss表(见图4和图5)。
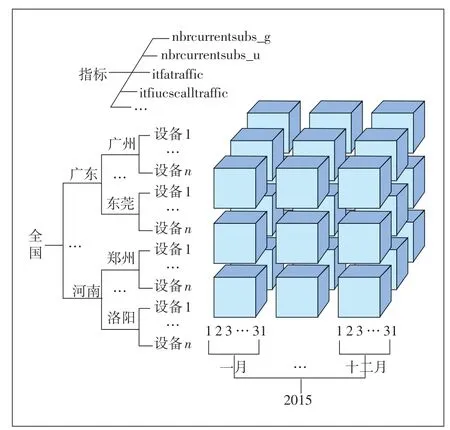
图4 多维数据集
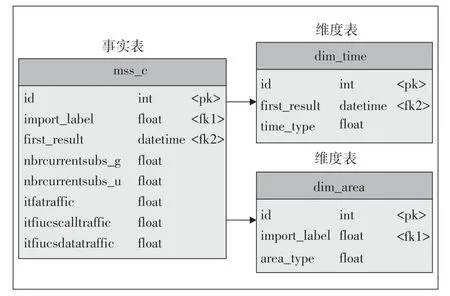
图5 维度表关系图
b)进行模式映射。一个模式定义了一个多维数据库,它包含一个逻辑模型、一组数据立方、层次和成员,并映射到物理模型(关系数据库)上。
(a)逻辑模型:为了编写Mdx查询语言而创建的,它包含数据立方、维、层次等。
(b)数据立方:事实表mss_c、维度表dim_time、维度表dim_area。
(c)度量包括:nbrcurrentsubs_g(VLR 中2G 登记用户数)、nbrcurrentsubs_u(VLR中3G登记用户数)、it⁃fatraffic(交换机的A 接口的占用话务量)、itfiucscall⁃traffic(交换机的Iu-CS接口话音业务的占用话务量)。
(d)维:dim_time、dim_area。
(e)层次(Hierarchies):time_type层次结构为(日、月、年),area_type 层次结构为(设备、地(市)、省分、全国)。
之后根据定义的逻辑模型编写mondrian模式配置文件(xm l文件)。
c)编写Mdx 查询。如查询郑州的日、月、年忙时数据,对应的Mdx查询语句如下。

其中:columns轴维度包含的是度量。rows轴维度包含的是维度中层次的所有成员。
4.4 结果应用
根据多维分析的结果,以图形方式展示分析后的数据(见图6)。
图6 分析结果展示
5 结束语
电信运营商每年投入大量资金进行网管系统的建设,但是这些网管系统大部分都专注于不同网络设备的运行维护,对网络的建设规划缺乏有效的指导。将离散的网管数据进行统一管理,构建网管大数据平台,从海量的网管数据中挖掘有效信息,可以使其更好地为网络建设服务。本文介绍了使用自动化工具对网管数据进行入库,数据清洗,多维分析,实现了网管数据的有效利用。
[1] Matt Casters,Roland Bouman,Jos van Dongen,et al. Pentaho Kettle解决方案:使用PDI 构件开源ETL 解决方案[M].北京:电子工业出版社,2014:120-130.
[2] QB/CU 250-2013 中国联通OSS-GSM/WCDMA/LTE 网络管理指标体系第四部分:电路域核心网指标定义与映射[S].北京:中国联通,2013:33-313.
[3] QB/CU 086-2010 中国联通OSS-GSM/WCDMA 网络管理指标体系第五部分:分组域核心网指标定义与映射[S]. 北京:中国联通,2010:18-184.
[4] QB/CU 246-2013 中国联通OSS-WCDMA/LTE网综合网管系统与网元管理系统间接口技术规范第三部分:与电路域核心网相关的信息模型[S].北京:中国联通,2013:3-126.
[5] QB/CU 248-2013 中国联通OSS-WCDMA/LTE网综合网管系统与网元管理系统间接口技术规范第七部分:与EPC相关的信息模型[S].北京:中国联通,2013:10-168.
[6] QB/CU X13-212(2014)中国联通OSS-GSM/WCDMA/LTE 总部移动综合网管系统技术规范[S].北京:中国联通,2014:30-36.
[7] QB/CU 252-2013 中国联通OSS-GSM/WCDMA/LTE 网络管理指标体系第七部分:EPC 指标定义与映射[S]. 北京:中国联通,2013:3-179.
[8] Baron Schwartz,Peter Zaitsev,Vadim Tkachenko,et al. 高 性 能MySQL[M].3版.北京:电子工业出版社,2013:202-204.
[9] Paul DuBois.MySQL 技术内幕[M].4版.北京:人民邮电出版社,2011:230-232.
[10]Pan Ning-Tan,Michael Steinbach,Vipin Kumar,et al. 数据挖掘导论(完整版)[M].北京:人民邮电出版社,2011:30-33.
[11]卢辉.数据挖掘与数据化运营实战:思路、方法、技巧与应用[M].北京:机械工业出版社,2013:129-130.
[12]Micheal Milton. 深入浅出数据分析[M]. 北京:电子工业出版社,2010:75-80.
[13]姚家奕.多维数据分析[M].北京:电子工业出版社,2007:50-56.
[14]Eric Thomsen. OLAP 解决方案:创建多维信息系统[M]. 2 版. 北京:电子工业出版社,2004:105-108.
[15]BD William,N Goodman,J Hyde. Mondrian in Action: Open source business analytics[M].Virginia:Manning Publications,2013:80-85.
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
中国计算机报(2019年46期)2019-01-13
通信电源技术(2018年3期)2018-06-26
中国建材科技(2018年5期)2018-01-26
互联网天地(2016年2期)2016-05-04
中小学信息技术教育(2015年12期)2015-12-17
新闻前哨(2015年2期)2015-03-11
中国质量与标准导报(2014年10期)2014-02-28
中小企业管理与科技·下旬刊(2009年8期)2009-12-31
