
大数据管理系统评测基准的挑战与研究进展
2015-04-06 08:24钱卫宁周敏奇金澈清周傲英
大数据 2015年1期
钱卫宁,夏 帆,周敏奇,金澈清,周傲英
华东师范大学数据科学与工程研究院 上海 200062
大数据管理系统评测基准的挑战与研究进展
钱卫宁,夏 帆,周敏奇,金澈清,周傲英
华东师范大学数据科学与工程研究院 上海 200062
数据库评测基准在数据库发展历史中的作用不可替代,而大数据环境中传统评测基准不敷应用。因此,从评测基准3要素,即数据、负载、度量体系入手,研究具有高仿真性、可适配性、可测量性的大数据管理系统评测基准,对大数据管理系统的研发和应用系统选型至关重要。基于此,在简要分析评测基准的基本要素和大数据管理系统发展过程的基础上,重点分析大数据管理系统的基准评测需求与挑战,然后通过社交媒体分析型查询评测基准BSMA,探讨了面向应用的大数据管理系统基准评测的设计和实现问题。
大数据管理系统;评测基准;数据生成;负载生成;性能度量体系
1 引言
数据库管理系统(DBMS)厂商间的激烈竞争造就了一个数千亿美元的市场。数据库基准评测(database benchmarking)确保了竞争的公平有序,从而引导了行业的健康发展。数据库评测基准是指一套用于评测、比较不同DBMS性能的规范,其所生成的性能指标值能够客观、全面地比较各个DBMS的性能差距[1]。
通常,新的数据库理论或数据管理技术被提出之后,会迅速诞生一批原型或商用系统。但技术上的差异常导致它们的性能表现不尽相同,从而引发系统开发商之间的争议。技术层面的争论和竞争促进了行业的发展;而诸多非技术因素的介入,则会破坏良性竞争。1983年发布的“威斯康星基准”[2],消弥了自关系型数据库管理系统(RDBMS)出现后纷争的性能口水战,促进了各DBMS厂商优化系统,并最终在常用负载(workload)下取得相近的性能。威斯康星基准的巨大成功以及以威斯康星大学DeWitt D J教授和图灵奖获得者Gray J为代表的一批学者对数据库基准评测的适时推动,有效地保障了20世纪80年代开始的30多年的数据库行业的健康发展。
随着“大数据”成为应用热点,越来越多的应用环境中,数据、应用和系统体现出“3V”的特性[3],即量大(volume)、多样(variety)、快速变化(velocity):数据同时具备“3V”的特性,即数据规模大、变化速度和增长速度快,且包含多源、异构和非结构化数据;应用中包含大量作用于大数据的多样化的负载,且很多负载要求在快速变化的数据上获得实时的结果;系统则需要同时适应数据与应用,在不同的接口层次上提供对大数据的多样化的管理和处理功能。
针对新兴的大数据应用环境,在以Hadoop为代表的海量数据处理技术日趋成熟的同时,一批新型大数据管理系统(big data management system,BDMS)积极涌现,以解决大数据管理与处理中的各种问题。
新型的数据、应用环境和系统决定了现有评测基准无法产生具有仿真能力的数据,不能反映应用需求,无法公平、有效地评测系统。在包括数据生成、负载生成、度量选取、评测基准架构与评测方法等在内的基准评测的多个方面,都需要研究、开发新的技术,以更真实地反映系统在典型应用环境中的表现。评测基准是对大数据应用环境中数据管理任务的规范化与定义,对大数据系统的研发具有指导意义。
基准制定是一个漫长的过程。RDBMS的基准评测经过30多年的发展,仍在不断完善。而影响力较大的早期大数据评测基准CALDA提出至今不过4年[4]。目前的相关评测基准在应用抽象、评测内容与方法、应用程度上都仍在初级阶段。可以预见,未来的5~10年评测基准将和BDMS的研发共同高速发展[5]。
另一方面,由于我国用户分布、商业模式、政策法规的特点,应用环境具有一定的特殊性。这种特殊性体现在数据、负载特性上。国外数据库厂商因对我国国情的不了解甚至是有意抵触,很难在短时间内研发出适合我国需求的系统和应用。面向具有特色的应用,制定评测基准,有助于引领大数据技术和系统的研发,为解决我国所面临的最急迫的大数据管理问题做出贡献,同时促进国内大数据系统的研发,提振国内大数据行业的发展。
本文将在简要分析评测基准的基本要素和大数据管理系统发展过程的基础上,重点分析大数据管理系统的基准评测需求与挑战,然后通过社交媒体分析型查询评测基准(benchmark of social media analysis,BSMA),探讨面向应用的大数据管理系统基准评测的设计、实现问题。
2 评测基准的基本要素
从宏观角度看,评测基准的3要素是数据、负载和度量体系,下面分别进行介绍。
● 数据:不同应用的数据具有不同的静态和动态特征,体现在结构、规模、数据分布、变化速率等多个方面。传统基准通常只采用固定数据结构和数据分布下的数据生成方法产生高仿真数据。而如何准确刻画大数据静态和动态特征,如何在特征已知或未知的情况下,高效地生成测试所需的海量数据是大数据管理系统基准评测所需要解决的问题。
● 负载:负载是作用于数据的访问和查询、更新、分析任务。大数据管理系统评测基准必须能够产生反映应用需求的多样化的负载(variety)。和数据一样,评测基准的负载必须在静态和动态特征上与应用具有相似性,即对于评价指标而言,模拟负载能够反映应用的需求。具有良好适配性的负载生成理论和方法是大数据管理系统基准评测的第二个要素。
● 度量体系:度量体系指对于性能进行评价的指标集合。指标可以是单一的,也可以是多维的。BDMS应用环境不同于传统DBMS。例如,新型硬件要求在评测时考虑非传统的性能度量,如忙时数据更新量(面向集群化的大内存系统)、热点数据更新频率等;开放的运行环境要求评测能够反映系统受干扰时的性能;分析型负载则将性能度量和结果的精确程度绑在一起。此外,性价比、能耗等因素进一步增加了BDMS度量体系制定的难度。
3 大数据管理系统及其评测基准需求
3.1 大数据管理系统的分类
大数据管理系统通常指那些基于集群环境,利用大容量内存、高速网络,支撑海量数据存储、索引、更新、查询、检索、分析和挖掘的数据管理系统。谷歌公司的GFS、MapReduce实现以及BigTable系统可以认为是最早出现的有代表性的大数据管理系统。而随着开源系统Hadoop的出现和相关开源生态圈的发展以及Berkeley Data Analytics Stack系列工具的快速发展,一大批系统和工具都可被归于BDMS的范畴,如图1所示[6]。这些系统的功能、接口层次、架构、实现技术、面向应用和所依赖的底层硬件各不相同,如何客观、公正地比较它们在不同应用场景下的性能,无论是对于系统开发者还是应用开发和系统选型人员来说,都是一个难题。这也是BDMS基准评测对于指导系统研发、系统选型,营造良好技术竞争环境的意义所在。
3.2 大数据管理系统基准评测需求
BDMS评测基准首先需要具备大数据建模与高仿真的数据生成的能力。具体而言,包括以下需求。
● 大数据静态和动态特征的刻画:对现实应用场景中的真实数据进行动态和静态特性的刻画,是形成数据生成理论的前提。数据的静态特征包括数据结构、数据分布、精确性以及时序关系等。在成熟的应用领域,数据静态特征往往已经有模型进行描述。但大数据的动态性(velocity)特征难以用单一模型进行刻画。对数据的静态和动态特性进行参数化的刻画是高仿真数据生成的前提。

● 高仿真的数据生成方法:大数据应用的特点决定了需要采用应用相关的数据生成方法。同时,大数据的复杂性和动态性决定了对数据特征的刻画无法由领域专家完成,而需要通过统计和机器学习自动进行。
● 动态数据高效持续生成:大数据不断变化、持续更新。因此,评测基准需要具备采用并行数据生成、流式数据生成等技术,仿真真实的海量、快速变化的动态数据的能力。
其次,BDMS评测基准还需要具备能够满足多场景需求的综合负载生成能力,具体介绍如下。
● 负载特性刻画与建模:常见负载包括数据访问、数据检索与查询、数据更新、批处理、迭代运算、聚集计算等,它们的处理代价各不相同。应用中的负载常常是复合的,且负载的分布随时间而变化。同时,负载作用于不同的数据对象(负载参数(argument)),其处理代价也是不同的。而且负载参数的分布也是动态、多样的。具备丰富、灵活的负载特性刻画能力,是准确模拟应用负载的前提。
● BDMS原语与操作模式的抽象:BDMS的访问接口具有多样性。在不同层次的BDMS服务上,分别定义兼容多种系统的负载描述,是实现BDMS基准评测的前提之一。这一需求也是BDMS评测基准与传统数据库管理系统评测基准的一项重要区别。
● 可适配的负载自动生成方法与系统框架:应用的负载各不相同。为每个应用定制负载生成器,成本高、效率低,不能满足同一数据集上共生多种应用的BDMS基准评测需要。因此,给定负载特性刻画,生成不同接口层面的代表性负载和相应负载参数,是另一项重要的BDMS基准评测需求。
第三,负载相关的度量体系与测量方法对于BDMS评测基准至关重要。
● BDMS度量的基本特征与度量体系:BDMS系统的性能评价包括多项非传统的度量,包括数据分析的实时性、系统的弹性能力,即环境变化时的自动管理能力、精度与性能的复合度量、能耗和能效比等。因此,需要制定可重复、可核实的新度量体系。这又是一项显著不同于传统数据库管理系统评测基准的需求。
● 影响度量可测量性的不确定因素的量化与相关性分析能力:多种不确定因素会影响最终的评测结果。云计算、多租户、虚拟机环境都可能放大这种影响,造成评测结果的不客观、不可重复等问题。因此,需要对影响可测量性的因素进行量化和相关性分析,并进一步修正度量体系,以保证评测结果的客观和全面。
● 新的测量方法学:基准评测要求其过程和结果具有可解释性、可重复性、可审计性。测量方法要求对这些特定现象进行准确记录和描述。另一方面,大数据应用的数据和负载常具有非稳态、爆发性特征,即在特定时刻数据或负载量剧增。BDMS基准评测方法必须具有可伸缩性,使得对爆发性的数据和负载,评测过程和结果仍有意义。此外,评测的结果还必须通过公开的方式报告评测环境、评测过程和评测结果。
3.3 大数据管理系统基准评测的挑战
大数据管理系统的一个重要特点是“同类适用(one size fits a bunch)”,即一个系统所针对的是具有相似特点的一类(bunch)应用,而不是所有应用。它不同于传统数据库管理系统的“一体适用(one size fits all)”特点[7]。这也是不同BDMS之间的差异明显大于传统数据库管理系统间差异的主要原因。系统间的显著差异为基准评测制造了障碍。为了应对这一情况,BDMS评测基准也应具有“同类适用”的特点,如图2所示。
具体而言,评测基准需要满足高仿真性、可适配性以及可测量性。
● 高仿真性,即生成的数据和负载在对于性能度量有明确影响的特征上具有高仿真性。
● 可适配性,即通过参数定制,基准评测套件可适配于不同领域,以对应BDMS系统的“同类适用”特点。可定制、可适配的评测基准对于降低评测成本具有重要意义,这是BDMS评测所特有的问题,也是难点所在。
● 可测量性,即基准评测结果在开放、动态应用环境中仍有意义,开放、动态的大数据应用环境向评测结果的可解释性、可重复性、可审计性、公平性提出了挑战。这一问题需要通过对BDMS进行更细致的建模以及大量的实验和实验结果分析加以解决。
BDMS评测基准还需要满足我国特有应用特点的需要。例如,在“双十·一”促销、“春运”抢票、优质金融理财产品发售等应用中,后台系统都会遭遇短时间的超高峰值负载压力。一方面,这是传统零售、运输、金融等行业“互联网化”的必然结果;另一方面,我国人口的巨大基数导致了此类负载压力远大于国外同类应用。如何模拟这类峰值(spike)场景,并进行准确的、有推广意义的评测,是一个重要的研究问题。此外,欺诈检测、情分析等应用由于与文化、国情紧密相关,因此在我国此类应用也具有特殊的负载。BDMS评测基准的研究与制定还需要反映这些特殊应用的需要。
4 BSMA:面向社交媒体数据分析型查询的基准评测
4.1 BSMA框架

图2 BDMS评测基准的“同类适用”特点
BSMA是一个社交媒体数据分析型查询评测基准[8,9],它包含了社交媒体数据的形式化描述规范和一个真实的社交媒体数据集,定义了24个测试查询,提供了评测系统查询性能的工具以及用于产生社交媒体时间轴(timeline)的数据生成器BSMA-Gen[10]。BSMA的系统结构如图3所示[9],BSMA所针对的数据定义如图4所示[9]。其自带的真实数据集和数据生成器所产生的模拟数据都符合这一数据定义。
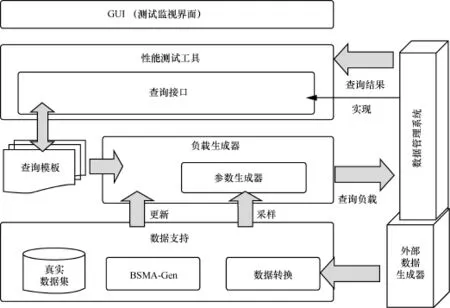
图3 BSMA框架
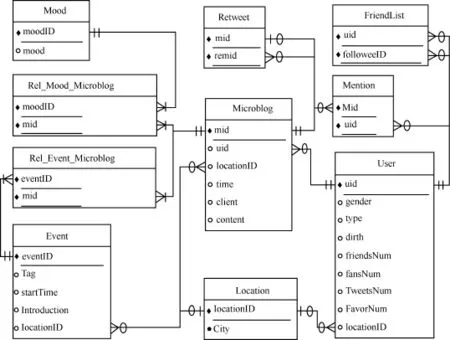
图4 BSMA数据定义
社交媒体数据分析具有典型的大数据应用的特征:首先,社交媒体数据并非传统的关系数据,具有时序数据、文本和多媒体数据、图数据和结构化数据的多重特征;其次,社交媒体数据量大、更新速度快;第三,社交媒体数据分析通常分析任务复杂、具有较高的实时性要求。BSMA的研究是BDMS评测基准研究的一项初期工作,从中可以体现研究问题和难点所在。
4.2 数据生成区获取发布者和社交网络信息以确定一个元素的f指针时,该元素的输出会被推迟,以等待远程从节点的信息到来。采用这种异步传输、延时生成的策略,每个元素的生成都不需要等待网络通信。实验表明,BSMA-Gen可以确保生成的时间线在转发结构、时序分布、用户消息数等方面符合预先给定的分布和参数,且吞吐率(即单位时间生成的元素数)与从节点个数呈线性增长关系。
为了完成模拟社交媒体时间线的生成任务,BSMA-Gen完成2个基本工作:模拟真实的社交媒体数据分布和高效产生时间线[10]。
BSMA-Gen产生时间轴,即消息数据流,每一条消息可表示为一个元组:m=<t, c, u, f>。其中t是信息发布的时间,c是内容,u是发布者,f是一个指向源消息的指针。当该消息是原始消息时,f为null;而当该消息为转发消息时,f指向被转发的消息(此消息也可能是转发的)。现在的生成器版本产生的数据只包含结构信息t、u、f,并不包含内容信息c。
BSMA-Gen将每个用户发布信息的过程模拟成非齐次泊松过程(nonhomogeneous Poisson process),从而可根据不同配置参数产生带有相应分布的社交媒体时间轴数据。
社交媒体时间线中的元组间转发相关性随着时间间隔变大而衰减。BSMA-Gen采用衰退函数模拟这一关系,并通过维护历史元组缓冲池和待产生元组缓冲池实现了元素的流式产生。同时,为了进一步加快时间线的产生速度,BSMA-Gen采用主从(master-slave)结构,由主节点进行发布者社交网络划分。每个从节点负责一个分区中所有发布者所发布的消息组成的部分时间线的生成。当一个从节点需要从其他分
4.3 负载
BSMA提供了24个典型社交媒体数据分析型查询负载1https://github. com/c3bd/BSMA。每个负载反映了一种或多种社交媒体数据分析的特性。BSMA负载主要覆盖了以下3类查询特性。
● 社交网络查询(social network query,SNQ):社交网络的查询围绕消息发布者的关系展开。它的目标是查询社交网络的某个特定模式或子图。
● 时间线查询(timeline query,TQ):在社交媒体中,时间线(timeline)是指以时间逆序排列的消息序列,序列中消息的条数即时间线的长度。时间线广义上可分全局时间线(global timeline)和局部时间线(local timeline)两种,全局时间线中的消息来自社交媒体中的任意用户,而局部时间线则限制了用户范围。时间线查询的本质是对于时间序列的查询。
● 热点查询(hotspot query,HQ):热点是指在某个特定的时间线内消息中满足某些过滤条件且统计值最大的某类元素的集合。由于社交媒体中数据的统计值分布常符合幂律(power-law)分布,对热点的查询在进行数据连接(join)和聚集(aggregation)计算时往往需要远超出查询其他元素的存储和计算开销。
处理这些负载可能需要对两个大的集合(关系)进行连接操作、对大集合进行多属性查询或对大集合进行聚集计算,而这些操作的处理通常是耗时、耗存储资源的。因此,这些负载能够测试数据管理系统在社交媒体数据分析这一特定应用中的性能表现。
4.4 评测指标与评测方法
BSMA使用以下3个性能评判指标。对于24个典型负载的组合,计算出这3个指标的值,以此来衡量查询处理性能。当然,查询执行的正确性是性能度量的基本前提。
● 吞吐率指标:吞吐率指单位时间内完成的查询数。在这里,吞吐率指标度量的是在不同线程数设置下能达到的吞吐率最高值,这个值越高意味着性能越好。
● 延时指标:延时指一个查询从发起请求到返回结果所需的时间。在这里,延时指标度量的是在不同线程数设置下所达到的次高吞吐率下(即系统未过载时)的查询延时,这个值越低意味着性能越好。
● 扩展性指标:扩展性指随着吞吐率的提高系统维持延时的能力。在这里,扩展性指标度量的是用最小二乘法拟合多个数据点的直线斜率。这些数据点对应不同线程数设置下的吞吐量(横坐标)和延时(纵坐标),拟合直线越平滑意味着扩展性越好。
5 相关工作
数据库评测基准研究在关系数据管理和非关系型数据管理方面均取得较大进展。针对大数据管理领域的基准评测工作则刚起步。图5概要地展示了数据管理系统评测基准的发展过程[11]。
5.1 面向关系模型的数据库系统评测基准

图5 数据管理系统评测基准的发展
早期数据库评测基准主要针对RDBMS,相关研究持续至今。事务处理委员会(TPC)是事实上的工业化标准组织,已经提出多个基准来评测RDBMS[12]。现有RDBMS评测基准可被划分为3类:面向联机事务处理(OLTP)、面向联机分析处理(OLAP)以及同时支持OLAP和OLTP的评测基准。
● 面向OLTP的基准:面向OLTP的基准评测包括威斯康星基准[2]、DebitCredit[13]、AS3AP[14]、TPC-C和TPC-E2http://www.tpc. org等。其中,TPC-C和TPC-E目前仍在使用。它们分别仿真仓库订单管理应用和证券交易应用。
● 面向OLAP的基准:此类基准的负载包含大量聚集查询,包括SetQuery[15]、SSB[16]、TPC-H和TPC-DS等。其中TPC-H和TPC-DS目前仍在使用,分别模拟商务采购应用和决策支持应用。
● 同时支持OLAP和OLTP的基准:部分新兴数据管理技术支持同时具有OLAP和OLTP需求的应用。CH-Benchmark基准有效融合了TPC-C和TPC-H两个基准,同时支持OLAP和OLTP评测3http://wwwdb.in.tum.de/ research/projects/ CH-benCHmark/。CBTR则提供了OLAP/OLTP复合负载[17]。
5.2 面向非关系型数据的基准设计
数据管理技术发展的过程是不断地将非结构化数据结构化,纳入DBMS,从而降低管理成本、提高利用效率的过程。针对各种非关系型数据,有不同的基准对相关技术和系统进行评测,见表1。
5.3 面向大数据管理技术的基准编程模式(paradigm)。此类基准主要评测MapReduce实现的性能。面向特定功能的此类基准包括:模拟TPC-H的MRBench[33]、评测HDFS文件系统的TestDFSIO[34]、Hadoop自带的Sort[34]和用于测试Pig的PigMix[35]等。此外,一些基准可同时评测多种功能,如评测Hadoop整体性能的GridMix4http://hadoop. apache.org/ mapreduce/docs/ current/gridmix. html、混合功能基准Intel HiBench5https://github. com/intelhadoop/Hibench以及涵盖了常用数据挖掘和数据仓库操作的CloudRank-D[36]。
● BDMS基准评测:CALDA基准可比较不同BDMS的性能[4]。YCSB[37]及其扩展YCSB++[38]可从性能和可扩展性两个层面评测云服务系统。Floratou等人对面向文档的NoSQL系统、面向决策支持的系统以及商用的DBMS进行了性能评测[39]。Rabl等人则比较了6种开源数据存储系统在不同负载下的性能[40]。
● 面向应用的大数据基准评测:BigBench是一种面向商品零售业的基准,扩展了TPC-DS[41]。LinkBench是一个由Facebook提出,基于真实社交网络应用的大规模图数据评测基准[42]。而LDBC则是由欧盟资助的链接数据管理基准评测组织,并已发布多个评测基准[43]。
不同的BDMS的功能和接口各不相同。当前的BDMS基准评测研究工作从以下3个方面展开。
● 评测MapReduce功能的基准:MapReduce是大数据处理中最常用的
5.4 国内的相关工作

表1 典型的面向非关系数据管理任务的评测基准
针对新型计算机系统的基准评测、新型DBMS的性能测试、新型数据库基准评测等问题,国内学者也开展了广泛而深入的研究。
在新型计算机系统的基准评测方面,中国科学院计算技术研究所提出了ICTBench6http://prof.ict. ac.cn/ICTBench/,包含面向数据仓库负载的DCBench[44,45]、面向BDMS的BigDataBench[46,47]和面向云计算系统的CloudRank[36]3个部分。中国人民大学孟小峰等人提出了CloudBM基准来评测云数据管理系统[48]。清华大学郑纬民等人利用代表性的基准测试对NAS存储系统进行了研究、比较和分析[49]。
大数据应用中广泛使用了包括内存数据库、NoSQL/NewSQL系统在内的大量新型DBMS。中国人民大学王珊等人利用TPC-H评测了多款内存数据库的性能[50];杜小勇等人使用TPC-DS基准,在100个节点的集群上,对5种主流的开源BDMS进行了全面深入的测试与分析,并在2013年的中国大数据技术大会上报告。华东师范大学金澈清等人提出了MemTest,以评测内存DBMS的主要性能特性[51]。清华大学王建民团队在NoSQL数据库基础上,实现了MOLAP引擎,并使用TPCDC基准进行了测试[52]。此外,他们在OLAP系统的性能测试[53]、DBMS性能测试[54]等方面做了重要的基础性工作。上海交通大学使用BigDataBench来评测数据中心上的资源共享策略[55];西安交通大学则使用这一基准来诊断大数据系统中的性能瓶颈[56]。
在BDMS的评测基准开发方面,BigDataBench包含了6个应用场景的数据集合和19类负载[46,47]。华东师范大学提出了一种面向社交媒体数据分析型查询处理的评测基准BSMA[8,9];提出了一种并行社交媒体数据生成方法,以仿真微博等社交媒体数据[10]。周敏奇等人则设计了一种更为通用的可扩展的高仿真数据生成器框架[57]。而清华大学则针对工作流数据管理系统的负载生成开展了研究[58]。
6 结束语
在“大数据”热潮下,大数据管理系统的研发和应用进展迅速,而相应的评测基准理论和方法研究则刚刚起步。针对大数据应用,特别是我国金融、电信、电子商务等具有鲜明应用特点的大数据应用的特点,遵循“同类适用”原则,从数据生成、负载生成、性能指标体系和测量方法这3个角度入手,解决应用环境适配和仿真、科学和公平评测、评测结果比较与分析等问题,是大数据管理系统评测基准研究的重要问题。现有的工作从应用和系统建模、数据仿真、数据和负载的高效生成、多维度性能指标设计等角度开展了研究。但对于设计和实现具有良好仿真能力、高适配能力的评测基准而言,非结构化数据仿真、超高负载环境模拟与评测方法、兼顾分析效果和性能的度量指标、开放环境下的性能评测和评测结果分析等问题仍是具有挑战性的研究问题。
[1] Gray J. Benchmark handbook for database and transaction system (2nd edition). San Francisco: Morgan Kaufmann, 1993
[2] Bitton D, DeWitt D J, Turbyfil C. Benchmarking database systems: a systematic approach. Proceedings of the 9th VLDB Conference, Florence, Italy, 1983
[3] Laney D. 3D Data Management: Controlling Data Volume, Velocity and Variety. Technical Report, Meta Group, 2001
[4] Pavlo A, Paulson E, Rasin A, et al. A comparison of approaches to largescale data analysis. Proceedings of ACMSIGMOD/PODS Conference, Providence, Rhode Island, USA, 2009
[5] Carey M J. BDMS performance evaluation: practices, pitfalls, and possibilities. Proceedings of the 4th TPC Technology Conference, Istanbul, Turkey, 2012
[6] Volker Markl. Big Data. VLDB Database Summer School (China) Slides, 2013
[7] Stonebraker M. Technical perspective one size fits all: an idea whose time has come and gone. Communications of the ACM, 2008, 51(12)
[8] Ma H X, Wei J X, Qian W N, et al. On benchmarking online social media analytical queries. Proceedings of Graph Data-management Experiences & Systems, New York, USA, 2013
[9] Xia F, Li Y, Yu C C, et al. BSMA: A benchmark for analytical queries over social media data. Proceedings of the VLDB Endowment, 2014, 7(13): 1573~1576
[10] Yu C C, Fan X, Qian W N, et al. BSMAGen: a parallel synthetic data generator for social media timeline structures. Proceedings of the 19th International Conference on Database Systems for Advanced Applications, Bali, Indonesia, 2014
[11] 金澈清, 钱卫宁, 周敏奇等. 数据管理系统评测基准: 从传统数据库到新兴大数据. 计算机学报. 2015, 38(1): 18~34 Jin C Q, Qian W N, Zhou M Q, et al. Benchmarking data management systems: from traditional database to emergent big data. Chinese Journal of Computers, 2015, 38(1): 18~34
[12] Nambiar R, Wakou N, Masland A, et al. Shaping the landscape of industry standard benchmarks: contributions of the transaction processing performance council (TPC). Proceedings of the 3rd TPC Technology Conference, Seattle, Wa, USA, 2011
[13] Bitton D, Brown M, Catell R, et al. A measure of transaction processing power. Datamation, 1985, 31(7): 112~118
[14] Turbyfill C, Orji C, Bitton D. AS3AP-An ANSI SQL Standard Scalable and Portable Benchmark for Relational Database Systems. Chapter 5, Benchmark handbook for database and transaction system (2nd edition). San Francisco: Morgan Kaufmann, 1993
[15] O’Neil. Revisiting DBMS benchmarks. Datamation, 1989, 35(9): 47~52
[16] O’Neil P, O’Neil B, Chen X D. The Star Schema Benchmark (SSB). University of Massachusetls, Boston, 2007
[17] Bog A. Benchmarking Transaction and Analytical Processing Systems: The Creation of a Mixed Workload Benchmark and Its Application. Berlin: Springer, 2013
[18] Cattell R G G, Skeen J. Object operations benchmark. ACM Transactions on Database Systems, 1992, 17(1): 1~31
[19] Carey M J, DeWitt D J, Naughton J F. The OO7 benchmark. Proceedings of ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 1993
[20] Anderson T L, Berre A J, Mallison M, et al. The HyperModel benchmark. Proceedings of the 2nd International Conference on Extending Database Technology: Advances in Database Technology, Venice, Italy, 1990
[21] Carey M J, DeWitt D J, Naughton J F, et al. The BUCKY object-relational benchmark. Proceedings of ACM SIGMOD International Conference on Management of Data, Tucson, Arizona, USA, 1997
[22] Runapongsa K, Patel J M, Jagadish H V, et al. The Michigan benchmark: towards XML query performance diagnostics. Information Systems, 2006, 31(2): 73~97
[23] Yao B, Ozsu M T, Khandelwal N. XBench benchmark and performance testing of XML DBMSs. Proceedings of the 30th IEEE International Conference on Data Engineering, Chicago, IL, USA, 2004
[24] Bōhme T, Rahm E. Multi-user evaluationof XML data management systems with XMach-1. Proceedings of the Workshop on Efficiency and Effectiveness of XML Tools and Techniques (EEXTT), Heidelberg, Germany, 2002
[25] Schmidt A, Waas F, Kersten M, et al. XMark: a benchmark for XML data management. Proceedings of the 28th International Conference on Very Large Data Bases, Hong Kong, China, 2002
[26] Li Y, Bressan S, Dobbie G, et al. XOO7: applying OO7 benchmark to XML query processing tools. Proceedings of Conference on Information and Knowledge Management, Washington, DC, USA, 2001
[27] Nicola M, Kogan I, Schiefer B. An XML transaction processing benchmark. Proceedings of the 26th ACM SIGMODSIGACT-SIGART Symposium on Principles of Database Systems, Beijing, China, 2007
[28] Werstein P. A performance benchmark for spatiotemporal databases. Proceedings of the 10th Annual Colloquium of the Spatial Information Research Centre, Dunedin, New Zealand, 1998
29 Myllymaki J, Kaufman J. DynaMark: a benchmark for dynamic spatial indexing. Proceedings of the 4th International Conference on Mobile Data Management, Melbourne, Australia, 2003
]30] Jensen C, Tiesyte D, Tradisauskas N. The COST benchmark-comparison and evaluation of spatio-temporal indexes. Proceedings of the 11th International Conference on Database Systems for Advanced Applications, Singapore, 2006
[31] Düntgen C, Behr T, Güting R H. BerlinMOD: a benchmark for moving object databases. The VLDB Journal, 2009, 18(6): 1335~1368
[32] Arasu A, Cherniack M, Galvez E, et al. Linear road: a stream data management benchmark. Proceedings of the 30th International Conference on Very Large Data Bases, Toronto, Canada, 2004
[33] Kim K, Jeon K, Han H, et al. MRBench: a benchmark for MapReduce framework. Proceedings of the 14th IEEE International Conference on Parallel and Distributed Systems, Melbourne, Victoria, Australia, 2008
[34] White T. Hadoop权威指南(第二版). 周敏奇, 王晓玲,金澈清等译. 北京: 清华大学出版社, 2011 White T. Hadoop: The Definitive Guide. Translated by Zhou M Q, Wang X L, Jin C Q, et al. Beijing: Tsinghua University Press, 2011
[35] Daniel. Pig mix. https://cwiki.apache.org/ confluence/display/PIG/PigMix, 2013
[36] Luo C, Zhan J, Jia Z, et al. CloudRank-D: benchmarking and ranking cloud computing systems for data processing applications. Frontiers of Computer Science, 2012, 6(4): 347~362
[37] Cooper B, Silberstein A, Tam E, et al. Benchmarking cloud serving systems with YCSB. Proceedings of ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 2010
[38] Patil S, Polte M, Ren K, et al. YCSB++: benchmarking and performance debugging advanced features in scalable table stores. Proceedings of ACM Symposium on Cloud Computing, Cascais, Portugal, 2011
[39] Floratou A, Teletia N, DeWitt D J, et al. Can the elephants handle the NoSQL onslaught. Proceedings of the VLDB Endowment, 2012, 5(12): 1712~1723
[40] Rabl T, Gómez-Villamor S, Sadoghi M, et al. Solving big data challenges for enterprise application performance management. Proceedings of the VLDB Endowment, 2012, 5(12): 1724~1735
[41] Ghazal A, Rabl T, Hu M, et al. BigBench: towards an industry standard benchmark for big data analytics. Proceedings of ACM SIGMOD/PODS Conference, New York, USA, 2013
[42] Armstrong T G , Ponnekanti V,Borthakur D, et al. LinkBench: a database benchmark based on the Facebook social graph. Proceedings of the ACM SIGMOD/ PODS Conference, New York, USA, 2013
[43] Boncz P A, Fundulaki I, Gubichev A, et al. The linked data benchmark council project. Datenbank-Spektrum, 2013, 13(2):121~129
[44] Jia Z, Wang L, Zhan J, et al. Characterizing data analysis workloads in data centers. Proceedings of IEEE International Symposium on Workload Characterization, Portland, OR, USA, 2013 [45] Xi H F, Zhan J F, Zhen J, et al. Characterization of Real Workloads of Web Search Engines. Proceedings of IEEE International Symposium on Workload Characterization, Austin, TX , USA, 2011
[46] Wang L, Zhan J F, Luo C J, et al. BigDataBench: a big data benchmark suite from internet services. Proceedings of the 24th IEEE International Symposium on High Perfornance Computer Architecture, Orlando, Florida, USA, 2014
[47] Zhu Y, Zhan J. BigOP: generating comprehensive big data workloads as a benchmarking framework. Proceedings of the 19th International Conference on Database Systems for Advanced Applications, Bali, Indonesia, 2014
[48] 刘兵兵,孟小峰,史英杰. CloudBM:云数据管理系统测试基准. 计算机科学与探索, 2012, 6(6): 504~512 Liu B B, Meng X F, Shi Y J. CloudBM: a benchmark for cloud data management systems. Journal of Frontiers of Computer Science and Technology, 2012, 6(6): 504~512
[49] 付长冬, 舒继武, 沈美明等. 网络存储系统性能基准的研究、评价与发展. 小型微型计算机系统, 2004, 25(12): 2049~2054 Fu C D, Shu J W, Shen M M, et al. Evaluation, research and development of performance benchmark on network storage system. Journal of Chinese Computer Systems, 2004, 25(12): 2049~2054
[50] 刘大为,栾华,王珊等. 内存数据库在TPC-H负载下的处理器性能. 软件学报, 2008, 19(10): 2574~2584 Liu D W, Luan H, Wang S, et al. Main memory database TPC-H workload characterization on modern processor. Journal of Software, 2008, 19(10): 2574~2584
[51] Kang Q Q, Jin C Q, Zhang Z, et al. MemTest: a novel benchmark for inmemory database. Proceedings of the 5th Workshop on Big Data Benchmarks, Performance Optimization, and Emerging Hardware, Hangzhou, China, 2014
[52] Zhao H W, Ye X J. A practice of TPCDS multidimensional implementation on NoSQL database systems. Proceedings of the 5th TPC Technology Conference, Trento, Italy, 2013
[53] 赵博,叶晓俊. OLAP性能测试方法研究与实现. 计算机研究与发展, 2011, 48(10): 1951~1959 Zhao B, Ye X J. Study and implementation of OLAP performance benchmark. Journal of Computer Research and Development, 2011, 48(10): 1951~1959
[54] 叶晓俊,王建民. DBMS性能评价指标体系. 计算机研究与发展, 2009, 46(增刊): 313~318 Ye X J, Wang J M. DBMS performance evaluation indicators. Journal of Computer Research and Development, 2009, 46(suppl.): 313~318
[55] Ning F F, Weng C L, Luo Y. Virtualization I/O optimization based on shared memory. Proceedings of the IEEE International Conference on Big Data, Santa Clara, USA, 2013
[56] Chen P, Qi Y, Li X, et al. An ensemble MIC-based approach for performance diagnosis in big data platform. Proceedings of the IEEE International Conference on Big Data, Santa Clara, USA, 2013
[57] Gu L, Zhou M Q, Zhang Z J, et al. Chronos: an elastic parallel framework for stream benchmark generation and simulation. Proceedings of the 31stIEEE International Conference on Data Engineering, Seoul, Korea, 2015
[58] Du N Q, Ye X J, Wang J M. Towards workflow-driven database system workload modeling. Proceedings of the 2nd International Workshop on Testing Database Systems, Providence, Rhode Island, USA, 2009

钱卫宁,男,华东师范大学数据科学与工程研究院教授、博士生导师,研究兴趣包括互联网环境下的数据管理、大数据管理系统评测基准、社交媒体数据分析、知识图谱构建与应用等。

夏帆,男,华东师范大学数据科学与工程研究院博士生,研究兴趣包括分布式查询处理、社交媒体数据基准测试、社交媒体数据管理。

周敏奇,男,华东师范大学数据科学与工程研究院副教授、硕士生导师,研究兴趣主要包括内存事务处理系统、内存分析处理系统、计算广告学。

金澈清,男,华东师范大学数据科学与工程研究院教授、博士生导师,研究兴趣主要包括基于位置的服务、数据流管理、不确定数据管理和数据基准评测。

周傲英,男,华东师范大学长江学者特聘教授、数据科学与工程研究院院长,研究兴趣主要包括Web数据管理、数据密集型计算、内存集群计算、分布事务处理、大数据基准测试和性能优化。
Qian W N, Xia F, Zhou M Q, et al. Challenges and progress of big data management system benchmarks. Big Data Research, 2015008
Challenges and Progress of Big Data Management System Benchmarks
Qian Weining, Xia Fan, Zhou Minqi, Jin Cheqing, Zhou Aoying
Institute for Data Science and Engineering, East China Normal University, Shanghai 200062, China
Database benchmarking has stimulated the development of data management systems and technologies. In big data environments, benchmarking should be revisited. Therefore, research on benchmarks for big data management systems is a key problem for big data research and applications. Benchmark design can be achieved from three different perspectives, i.e. data, workload, and performance measurements. After the brief introduction to these three elements and the progress of big data management system research, the requirements and challenges to benchmarking big data management systems were analyzed. Through the introduction to a benchmark for analytical queries over social media data, named as BSMA, the issues of design and implementation of a benchmark for big data management systems were discussed.
big data management system, benchmark, data generation, workload generation, performance measurement
2015-05-01;修回时间:2015-05-07
国家自然科学基金资助项目(No. 61432006),上海市教委科研创新重点项目(No.14ZZ045)
Foundation Items:The National Natural Science Foundation of China (No. 61432006), The Shanghai Municipal Education Commission Scientific Research Innovation Key Project (No.14ZZ045)
钱卫宁,夏帆,周敏奇等. 大数据管理系统评测基准的挑战与研究进展. 大数据, 2015008
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
家庭影院技术(2021年2期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
化工设计(2020年6期)2020-01-13
数学年刊A辑(中文版)(2019年3期)2019-10-08
中国自行车(2018年11期)2018-12-03
劳动保护(2018年8期)2018-09-12
中国自行车(2017年1期)2017-04-16
公民与法治(2016年19期)2016-05-17
