
基于网络爬虫的导航深度服务信息自动采集
2015-03-28 06:10:48陈睿嘉康志忠张卫涛
测绘工程 2015年1期
陈睿嘉,康志忠,张卫涛
(1.中国地质大学 土地科学技术学院,北京100083;2.广东瑞图万方科技股份有限公司,广东 佛山528305)
基于位置的服务(location based services,LBS)是集GIS技术、定位技术、通信技术、网络技术等为一体的能提供多种形式服务的以位置信息为核心的信息服务框架[1]。如今,传统地图服务日渐无法跟上生活服务需求,杨小晴等提出将楼盘信息通过Google Map融合发布为地图服务[2]。随着互联网发展,网络中包含大量实时地理信息,互联网环境下的地理信息Web服务搜索引擎已成为当前的一个研究热点[3]。主题爬虫应用策略作为地理信息搜索引擎应用的核心和基础,是研究的重点之一。Refractions Research、GIDB、Skylab Mobile Systems等均基于Google API开发了支持OGC(Open GIS Consortiu m)标准的 Web地图服务(Web Map Service,WMS)爬虫[4];Li等根据 主题特征计算URL(Universal Resource Locator)及页面的权重以优化提取队列[4];武昊等提出了一种基于主题相关度的地理信息Web服务爬虫策略[5];张春菊等提出基于网络爬虫的地名数据库维护方法[6];苗海等利用开源爬虫NWeb Crawler定制正则表达式设计一种基于相似聚类算法的垂直搜索引擎
本文基于传统地理信息爬虫在专题垂直搜索应用中的不足,提出一种基于主题爬虫设计思想,自动采集各服务信息网站提供的POI深度服务信息的方法。
1 深度服务信息定义及结构
导航兴趣点(POI)是指在导航地图中可以用查询的方法检索的信息关注点,泛指一切可以抽象为点的地理对象,在导航地图中以入口点或位置点的方式给出。POI结合导航功能的实现,主要记录内容包括检索点的绝对位置坐标、所属行政区划编码、名称信息、地址信息、电话信息、类型编码、对象唯一标识码、所对应道路路网弧段ID号、点关系类型、显示等级等相对长时间不会变动的内容。网络中存在大量服务网站平台发布与维护POI实时服务信息,如:时光网发布电影院当天上映电影信息、中票在线发布剧场近期演出信息、去哪网发布酒店房间信息等,其最快更新频率一般情况下为1 d。
本文定义深度服务信息继承POI结构,以天为周期从网络抓取实时发布的服务信息,并获取本地时间作为抓取日期字段,生成深度服务信息点特征入库,其内容如表1所示。

表1 深度服务信息数据结构
本文内容主要研究网络信息抓取方法以及网络信息与POI点匹配方法。
2 深度服务信息自动采集
深度服务信息自动采集流程如图1所示。采集方法流程分为以下3步:
1)根据原地图矢量数据对POI的分类编码检索某一类POI点(如电影院)名称、地址、经纬度等数据按定义结构生成深度服务信息点,服务信息字段空缺。

图1 深度服务信息采集算法
2)使用网络爬虫获取该类主站下(如时光网)发布服务信息的服务地点URL;并通过DOM技术[6]解析、提取每个URL中服务地点的名称、地址及服务信息。
3)对步骤1)中得到的每一深度服务信息点中的name、address字段依次与步骤2)中获取的每个URL对应的名称、地址分别计算字符串相似度,选择最优URL页面的深度服务信息填入当前空缺服务信息字段,使用算法分别为编辑距离(Levenshtein距离)[8]和最大公共子序列(Longest Common Subsequence,LCS)[8]。
2.1 网络爬虫设计
网络爬虫是搜索引擎的重要组成部分,其基本原理是从一些“种子”站点出发,通过HTTP等协议请求并获取网页资源,分析页面内容并提取链接,以循环迭代的方式访问整个网络[5]。主题网络爬虫根据一定的网页分析算法过滤与主题无关的链接,保留主题相关的链接并将其放入待抓取的URL队列中;然后根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止[9]。本文设计的爬虫采用广度优先策略,参考基于相似聚类算法的垂直搜索引擎中正则表达式的应用[7],设计了两个正则表达式,分别用于过滤外链与匹配目标URL。
URL是代表网页地址的字符串,所需要的某一类服务地点URL具有相似的结构。正则表达式正是用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串,可用于识别相似的字符串结构。以时光网为例,可以将表达式1设计为:“http://.*mti me.*”,即匹配包含“mti me”的 URL。对目标URL进行抽样分析,如:新华国际影城大钟寺店 URL 为 http://theater.mti me.co m/China_Beijing_Haidian/3129/,耀莱国际影城 URL为http://theater.mti me.com/China_Beijing_Haidian/2486/。可 将 表 达 式 2 设 计 为:“http://t heater.mti me.com/China_Beijing_[A-Z]?[a-z]+/[\d]+/”。提取出所有相似结构的URL后,可使用网页文本解析方法提取名称、地址和服务信息。
2.2 网页文本解析
网页文本解析与提取通过DOM技术[6]实现。URL页面通常是HT ML格式文本。HT ML(Hyper Text Markup Language)是超文本标记语言,其基本思想是用描述标记来提供描述文档结构的附加信息[10]。
DOM技术是当前用于解析HT ML网页最常用的技术,根据网页结构标记将文本解析为树形结构,形成以HT ML为根节点的结构明晰、层次好的DOM标记树,树中的每个节点由网页中的所有标记属性对构成,如图2所示。
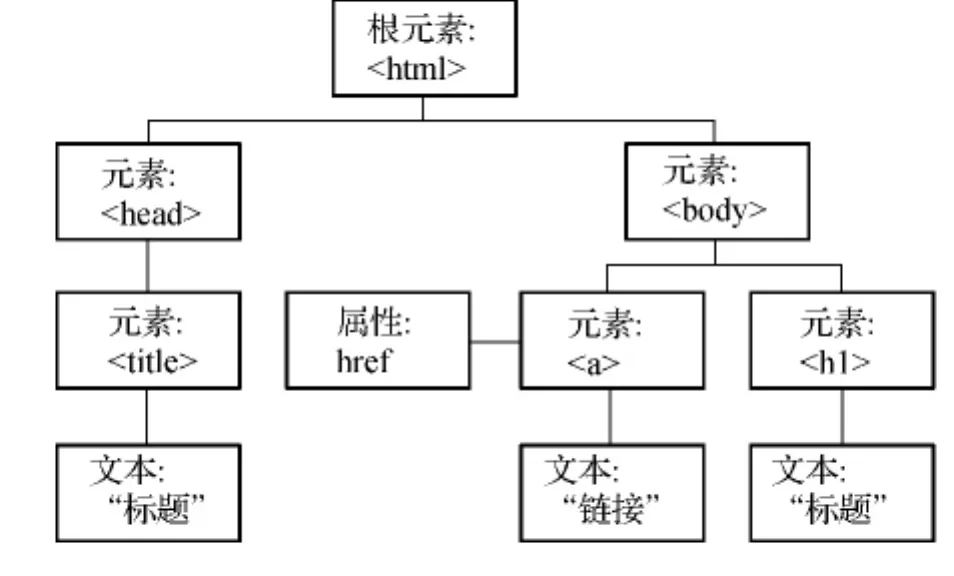
图2 DOM树形结构
由于同一网站发布不同地点服务信息的网页结构一致,地点名称、地址和服务信息存在于DOM树某一固定叶子节点上。如国中票在线家大剧院主页中一段源代码:
“<li class=“ticket_list_tu fl”>
<a href= “http://www.chinaticket.co m/view/9958.ht ml”target=“_blank”title=“中国国家芭蕾舞团《大红灯笼高高挂》”class=“ticket_list_title”>中国国家芭蕾舞团《大红灯笼高高挂》</a>
<span> 时 间:2013.01.18 - 2013.01.19     票价:100.00元 -680.00元</span>
</li>”
显然,只需从属性为“ticket_list_t u fl”、标签为“<li>”的节点中提取完整语句,过滤标签符号。该地点的名称、地址也可在其他叶子节点中获得。
2.3 基于目标网页名称、地址的相关度计算方法
Li等、武昊等、张春菊等以及苗海等设计的专题爬虫对主题字符串进行分词,构建向量空间模型,并利用TF-IDF算法计算网页文本内容与主题相似度[4-7]。向量空间模型法依赖于分词词库的构建,而TF-IDF向量定权法需要对网页文本进行大量取样,整体复杂度较大。本文设计提取网页对应地点名称、地址字符串计算与主题点特征相似度的方法,并对LCS算法计算地址相似度过程进行改进。
在专题垂直搜索应用中,目标网页内容之间的差异相比传统主题搜索具有更明显的规律,其差异性主要表现在地点位置描述部分,即地点的名称、地址字符串,可通过网页中的名称、地址与POI的名称、地址相似程度判定该网页服务信息与POI点的相关程度:将继承自POI主体的name与address字段对每个URL文本中解析得到的名称、地址字符串分别计算名称相似度与地址相似度,并取两者均值作为当前点特征与当前URL相关度,从URL列表中选择相关度最大者作为最优匹配结果,并将其解析得到的服务信息作为点特征服务信息字段。但若当前特征点表示的地点在URL列表中不存在,将会选择与之相似度最大的错误页面作为匹配结果,对此可设定一阈值,若结果大于阈值则匹配成功,否则放弃匹配。通过实验验证,阈值设定在0.5时就可得到正确结果。
字符串相似度寻找两个字符串的公共子串,利用公共子串的长度根据相应的公式来衡量两个字符串的相似程度。字符串相似度在很多领域都有广泛的应用,如在抄袭检测系统、自动评分系统、防代码剽窃系统、数据清洗、网页搜索和DNA序列匹配等。目前,字符串相似度度量算法有很多,如编辑距离算法(Levenshtein Distance)、最长公共子串算法(LCS,Longest Co mmon Subsequence)、Heckel算法、贪心字符串匹配算法(Greedy String Tiling,GST)及 RKR-GST算法(Running Karp-Rabin Greedy String Tiling,RKR-GST)等[10]。本文名称的相似度使用编辑距离计算,地址相似度使用最大公共子序列计算,并针对地址相似度计算过程做出改进。
2.3.1 编辑距离计算名称相似度
编辑距离是用来计算从原字符串转换到目标字符串所需要的最少的插入、删除和替换的数目。该算法能对顺序匹配进行有效查找,可准确识别地点名称描述相似程度。编辑距离算法步骤如下[8]:
1)得到字符串1长度m,字符串2长度n,如果m=0,则编辑距离为n;如果n=0,则编辑距离为m。
2)构造一个(m+1)×(n+1)大小矩阵 Distance,矩阵第1行依次赋值为0,1,2,…,m,第1列依次赋值为0,1,2,…,n。
3)对矩阵从左到右,每一列从上到下依次计算:设i为矩阵行号,j为矩阵列号,0≤i≤m,0≤j≤n,若字符串1第i个字符与字符串2第j个字符相同,按式(1)计算;若字符串1第i个字符与字符串2第j个字符不相同,则按式(2)计算。

4)最后计算矩阵右下角的值即为两字符串编辑距离,并通过式(3)计算相似度为

然而,由于大量存在同商家分店,如:“新华国际影城大兴店”与“新华国际影城良乡店”相似度极高,却不表示同一地点,加入地址相似度作为参考,可提高匹配准确度。
2.3.2 最大公共子序列计算地址相似度
地址匹配包括精确匹配和模糊匹配。当地址信息表达符合编码规则标准时,直接将地址进行标准化处理,处理成地址数据库中表达的标准格式,从而实现与地址数据库的精确匹配。当地址信息表达不符合编码规则标准时,采用模糊匹配进行处理[1]。
而张春菊、唐旭日等使用条件随机场模型(CRF)将地址识别为“北京市;东城区;北三环东路;36号”的模式,分别对每一部分匹配[6,11]。此方法的准确性依赖于完善的地名词库。本文通过改进LCS算法计算地址相似度。
最长公共子序列算法是将两个给定字符串分别删去零个或多个字符,但不改变剩余字符的顺序后得到的长度最长的相同字符序列。其算法的运行步骤如下[8]:
1)得到字符串1长度m,字符串2长度n,如果m=0,n=0,则LCS为0。
2)若m,n都不为0,构造一个(m+1)×(n+1)大小矩阵LCS,将其第1行第1列的值置0。
3)初始化矩阵LCS,设i为矩阵行号,j为矩阵列号,0≤i≤m,0≤j≤n,若字符串1第i个字符与字符串2第j个字符相同,则使LCSi,j=1,否则使LCSi,j=0。
4)对矩阵从上到下,每一行从左到右依次计算:若字符串1第i个字符与字符串2第j个字符相 同,且 LCSi-1,j= LCSi-1,j-1,则 使 LCS i,j=LCSi,j-1,否则使 LCSi,j=Max(LCSi-1,j,LCSi,j-1),矩阵中最大值即为最大公共子序列。
按LCS计算相似度原始方法,可按式(4)[8]计算相似度为

可按此方法计算“北三环东路36号”与“北京市东城区北三环东路36号环球贸易中心E座B1/F1/F3”相似度仅为53%,但这两种描述表达的是同一个地点,极大影响了匹配准确度。本文针对这一特征改进LCS计算地址相似度方法,如式(5)所示。

由此计算以上两地址相似度为100%,有效地提高了地址相似度计算准确度,最终通过取名称、地址相似度均值,作为稳健的匹配依据。
3 实验与分析
本文通过以上方法流程设计了基于网络爬虫的导航深度服务信息自动采集系统原型,以北京市部分区域的导航地图数据为POI数据来源,分别从时 光 网 http://theater.mti me.com/China_Beijing/、中票在线htt p://www.chinaticket.co m/beijing/venue.ht ml中抓取电影信息与剧目信息为实验,在Windows 7操作系统下使用java语言实现,具有良好的可移植性。
3.1 POI信息检索
通过SQL语言检索导出基础POI数据ID、Name、Type、X、Y字段内容。获取北京市150家电影院、136家剧场。图3、图4分别为电影院、剧场部分检索结果。

图3 电影院POI数据

图4 剧场POI数据
3.2 网络爬虫结果
检索POI数据的同时,爬虫开始抓取电影院主页与剧场主页URL。理论上只要爬行一定的深度就可得到所有主页URL,为兼顾效率与数量,以爬行两层为实验,在时光网与中票在线中分别抓取到匹配以下两正则表达式:“http://t heater.mti me.co m/China_Beijing_[A-Z]?[a-z]+/[\d]+/”、“http://www.chinaticket.co m/beijing/venue/[\d]+.ht ml”的URL列表,包括46个电影院主页与70个剧场主页,如图5、图6所示。
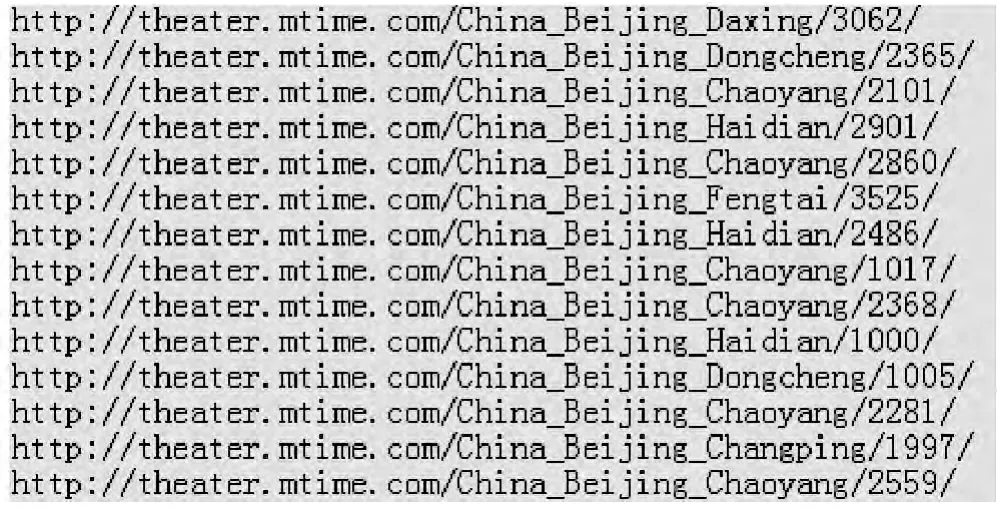
图5 电影院爬虫结果
3.3 网页文本解析
根据网页文本解析模块解析每个URL,图7、图8分别为图5、图6中第1个URL解析、提取名称、地址、服务信息内容与实际网页显示结果对比,证明了网页文本解析方法的准确性。图7表示的网页虽然包含了第2天的电影信息,但隐藏在其包含的另一 URL中,“http://theater.mti me.co m/Chi-na_Beijing_Daxing 3062?d=20130421 不影响 当天抓取结果。
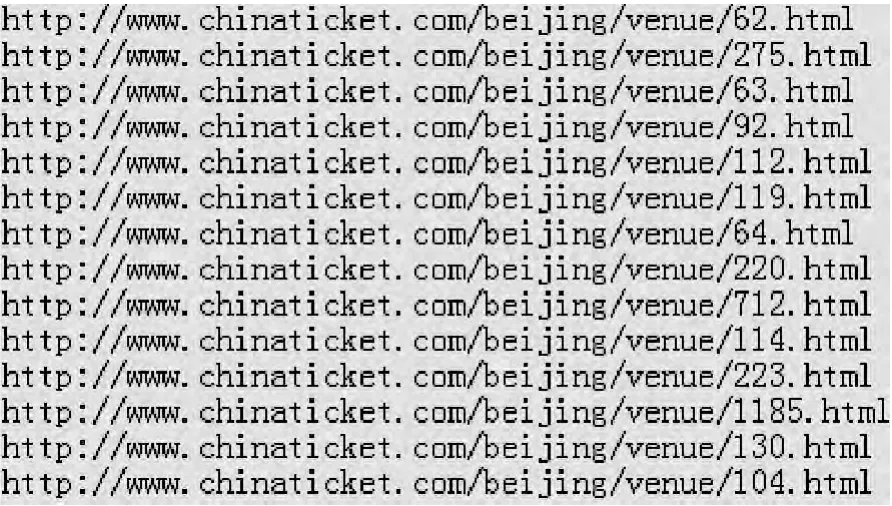
图6 剧场爬虫结果
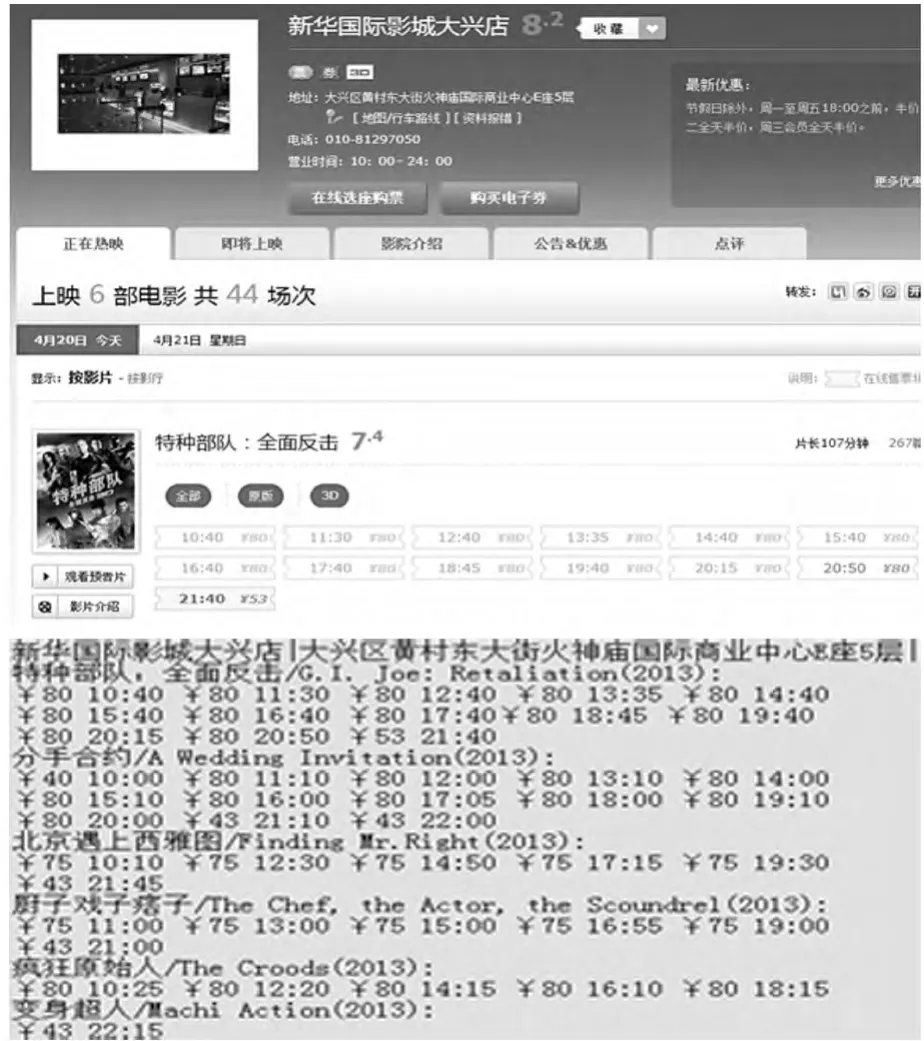
图7 电影院解析结果

图8 剧场解析结果
3.4 基于目标网页名称、地址的相关度计算结果
根据基于目标网页名称、地址的相关度计算方法对每个点特征与所有URL计算相关度,并匹配一最佳URL。图9为“新华国际影城大兴店”与URL相关度计算结果,其对应POI点的name、address字段分别为“新华国际影城大兴店”、“大兴区黄村东大街”,左边为每个URL解析得到的名称、地址,右边表达式表示“(名称相似度+地址相似度)/2=相关度”。
设定阈值为0.5以下时,可能得到错误匹配结果,如图10所示,但若所取阈值越大,得到的匹配结果越少,可能舍弃了正确的匹配结果。图11为相关度阈值为0.5时电影院、剧场对应POI与其相关度最大的URL名称、地址对比,结果全部正确。

图9 相似度计算结果

图10 阈值为0.4时错误匹配结果

图11 电影院、剧场匹配结果
3.5 入库及更新
最终,按以上相关度匹配结果依次将解析URL得到的服务信息作为匹配点特征的深度服务信息字段并入库,并且以天为周期采集、更新。单次入库结果如图12所示,图13为5月29日至31日对新华国际影城大兴店连续3 d采集的服务信息结果。

图12 入库结果

图13 连续采集结果
4 结 论
互联网逐渐成为日常生活获取信息的主要来源,搜索引擎以及爬虫技术则是从互联网上快速获取深度服务信息的捷径。本文通过实验取得了较好的结果,从理论、实验上证明了方法的准确性和广泛适用性。而采集得到的深度服务信息不但可以直接提供给用户,更可以结合路径规划、实时交通信息等提供深度决策服务,如:附近最便宜的旅馆、附近可赶上的电影等。
为了更快速、高效地获取网络信息,爬虫性能优化也是爬虫技术的研究重点。本文爬虫设计仍有较大性能优化空间,甚至可以直接基于Nutch、Heritrix等成熟开源爬虫进行二次开发。
[1] 李清泉,杨必胜,郑年波.时空一体化GIS-T数据模型与应用方法[J].武汉大学学报:信息科学版,2007,32(11):1034-1041.
[2] 杨小晴,罗畏,黄文嘉.基于Google Map的楼盘信息发布系统的设计与实现[J].测绘工程,2011,20(2):49-52.
[3] 白玉琪,杨崇俊.空间信息搜索引擎研究[J].中国矿业大学学报,2004,33(1):90-94.
[4] LI W W,YANG C W,YANG C J.An active crawler for discovering geospatial Web services and their distribution patter n–A case study of OGC Web Map Ser vice[J].Inter national Jour nal of Geographical Infor mation Science,2010,24(8):1127-1147.
[5] 武昊,廖安平,何超英,等.基于主题相关度的地理信息Web服务爬虫研究[J].地理与地理信息科学,2012,28(2):27-30.
[6] 张春菊,张雪英,朱少楠,等.基于网络爬虫的地名数据库维护方法研究[J].地球信息科学学报,2011,13(4):492-499.
[7] 苗海,张仰森,岳明.基于聚类算法的垂直搜索引擎技术研究[J].北京信息科技大学学报,2013,28(1):41-44.
[8] 牛永洁,张成.多种字符串相似度算法的比较研究[J].计算机与数字工程,2012,40(3):14-17.
[9] 刘金红,陆余良.主题网络爬虫研究综述[J].计算机应用研究,2007,24(10):26-29,47.
[10]王志琪,王永成.HT ML文件的文本信息预处理技术[J].计算机工程,2006,32(5):46-48,67.
[11]唐旭日,陈小荷,张雪英.中文文本的地名解析方法研究[J].武汉大学学报:信息科学版,2010,35(8):930-935,982.
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
股市动态分析(2016年17期)2016-10-20 13:51:33
股市动态分析(2016年13期)2016-10-17 13:53:39
股市动态分析(2016年11期)2016-10-11 13:56:32
股市动态分析(2016年10期)2016-09-30 13:59:11
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
