
天文大数据管理工具的设计与实现*
2015-03-22 11:31:36钟守波张彦霞赵永恒何勃亮
天文研究与技术 2015年4期
钟守波,韩 波,张彦霞,赵永恒,何勃亮
(1. 武汉大学国际软件学院,湖北 武汉 430079;2. 中国科学院光学天文重点实验室(国家天文台),北京 100012)
天文大数据管理工具的设计与实现*
钟守波1,2,韩 波1,张彦霞2,赵永恒2,何勃亮2
(1. 武汉大学国际软件学院,湖北 武汉 430079;2. 中国科学院光学天文重点实验室(国家天文台),北京 100012)
随着大型地面和空间观测设备的建设以及大型巡天项目的开展,天文数据以TB字节、PB字节,甚至EB字节计量,天文学进入了 “大数据” 时代。面对数据海洋,如何有效地存储和管理这些大数据是摆在天文学家面前的核心问题。数据存储和管理不仅仅是天文数据中心的任务,天文学家也需要有效地管理自己的科研数据。能够将海量的数据自动地存入数据库中是管理数据的基本前提,而高效的数据索引则是管理数据的核心要素,为此设计开发了天文大数据管理工具AutoDB,使用虚拟终端监视实现海量数据的自动入库,对数据自动创建全新的天空分区索引Q3C(Quad Tree Cube),对天文数据进行二维空间索引以便于高效的管理。天文大数据管理工具的改进和完善对天文学家后续研究中的数据融合、数据分析、数据挖掘提供了根本的保障,尤其对从事大数据的天文学家,拥有自动化的数据库管理工具,可以集中精力致力于科学研究。
大数据;数据库;数据管理;数据文件
目前,天文技术的发展越来越快,高科技的天文设备、仪器的使用,使得天文数据的观测已经进入 “大数据” 时代,每天产出海量的天文数据。在今后的数年内天文数据将积累到PB量级,数据量的增加给天文学的研究带来了希望,同时也带来了新的挑战,量变引起质变,数据量从GB跃升到PB后,需要更加高效的方法存储、管理、分析和挖掘这些数据[1-5]。在海量科学数据时代,天文研究的过程中天文学家需要不断地扩展视野,增加知识,对数据进行更加高效的组织、访问、整合与挖掘,其中最基本的工作就是数据的高效存储管理。所以高效快速地存储管理海量的天文数据,让天文学家能够快速地存储并分析数据,减少在技术上的使用障碍,变得越来越重要。在天文学界,天文工作者不断地开发各种数据管理工具,最为流行的是SAADA*SAADA, http://amwdb.u-strasbg.fr/saada/数据生成工具,支持转换FITS文件或者其他的存储格式(图片、表格、光谱)来创建SAADADB数据库,同时可以将数据部署在网络服务器上,数据库本身存储在本地机器上,天文学家不用编写任何代码。其中SAADADB数据库由SAADA产生,是基于关系数据库(MySQL*MYSQL, http://www.mysql.com/、PostgreSQL*PostgreSQL, http://www.postgresql.org/、SQLite*SQLite, http://www.sqlite.org/)由Java语言设计生成,同时需要网络应用服务器,如Apache*Apache, http://www.apache.org/、Tomcat*Tomcat, http://www.tomcat.apache.org/,数据管理操作非常简单。尽管SAADA的功能强大,但是对于致力于天文研究的天文学家学习和使用比较困难,例如各种类型数据库的部署、Java和网络服务器的部署等。就数据库的自动入库而言,只需要将数据导入底层数据库,并且可以直接从底层数据库调用数据,而SAADA会产生专有的SAADADB数据库,在后续的查询过程中需使用其指定的查询语法,增加了使用难度,同时在入库过程中,不会同时创建索引,用户需要在后续过程中创建索引,也不会使用数据库的扩展库,如PostgreSQL数据库的四叉树(Quad Tree Cube, Q3C)*Q3C, http://code.google.com/p/q3c/。这些因素导致SAADA自开发以来未得到广泛应用。鉴于此开发了一个简单实用的入库管理工具AutoDB,同时支持FITS文件和其他如CSV格式的数据文件,底层数据库支持MySQL和PostgreSQL,数据录入完毕后自动创建索引,用户在对数据进行管理、查询、分析时,直接使用简单通用的结构化查询语言(Structured Query Language, SQL)。斯滕伯格天文研究所莫斯科大学研究人员对比了几种数据库索引方式如Q3C与B-tree、R-tree在数据库查询时的性能*http://www.sai.msu.su/~megera/oddmuse/index.cgi/SkyPixelization,分别对数据建立Q3C索引、B-tree索引、R-tree索引进行锥形查询时,Q3C表现出更少的I/O密集型索引方式,其查询读取的索引块数比R-tree和B-tree小了很多。研究结果表明无论是消耗时间还是查询时索引块的使用,Q3C方案明显优于其他索引方案。由此可见,Q3C作为一种有效的空间索引策略,应用于天文数据管理是很必要的。常用的天文数据格式有文本格式和FITS格式。针对这两种数据格式,应用Q3C索引开发了自动化的天文数据管理工具。
1 数据库入库和管理工具AutoDB
随着天文数据的日益增加,存储和管理数据变得非常重要,尤其在数据的归档和管理方面,占有举足轻重的地位。通过对天文数据管理知识的了解,经过一系列的研究与开发,最终开发了一个高效的天文数据自动入库管理工具AutoDB,旨在帮助天文学家提高工作效率,促进天文学研究进展。
1.1 AutoDB的设计思路与方法
文[6]研究了基于Java语言开发的数据自动入库和交叉认证工具。文[7-8]基于Python语言实现了天文数据的自动入库和交叉证认,该工具能够自动添加分层三角网格(Hierarchical Triangular Mesh, HTM)的索引值,建立分层三角网格*HTM, http://www.skyserver.org/htm/索引分区,便于以后的交叉认证工作。分层三角网格是一种多层次、递归的球面分割方法,将天球分成多级的三角网络,每个网络有一个分层三角网格的索引值,利用分层三角网格可以将一个大星表从逻辑上分割为多个小星表,分层三角网格分级算法采用C语言编写,充分利用了C语言的高性能和Python语言的高效率。然而该程序仅支持底层数据库为MySQL,且只支持CSV格式的文件,文件中的数据不能为空,若为空则抛出错误,有一定的局限性。分层三角网格分区是对赤经和赤纬进行计算产生索引值实现天空分区,同时使用pcode_htmN数据列存储这些值,然后对其进行B-tree索引,方便后续的高效查询。首先,算法必须根据后续数据的复杂性进行优化,其次,先计算再存储势必有I/0性能限制,最后使用B-tree一维索引间接对赤经和赤纬索引,无法利用天文数据的空间性,若想实现一定半径内的查询需要非常复杂的结构化查询语言。为了解决这些问题,在深入分析原理的基础上,对自动入库管理工具进行全面的完善和改进:(1)底层数据库同时支持MySQL和PostgreSQL;(2)针对PostgreSQL数据库,使用一种新型Q3C索引,直接与数据库进行交互,无其他I/0交互,对赤经和赤纬进行空间索引,并且提供简单的SQL语句实现复杂的查询;(3)数据格式同时支持FITS和CSV格式;(4)数据优化,若其中存在为空的数据项,自动变为 ‘9999’ 或者 ‘NULL’,入库时不会出错。
1.1.1 底层数据库架构
工具的底层数据库基于MySQL和PostgreSQL两种数据库开发。这两种都是非常好的开源数据库,对于选择哪种数据库取决于哪种数据库更能满足用户的需求。之前采用MySQL数据库,然而由于数据量增加,数据表格越来越大,一个表格甚至达到了几十亿行,对于表本身的容量远远超过了物理内存,甚至建索引也不能改善性能,这样查询时间大大延长,在此情况下有必要对数据进行分表管理,即将表拆分为一系列较小的、与之相关联的子表进行替代,通过对子表的数据查询,相当于对整个表进行查询操作。对基于MySQL数据库分表来说,取决于数据引擎(InnoDB),不支持哈希分区表,而PostgreSQL数据库支持临时表、常规表以及范围和列表类型的分区表,而且PostgreSQL的表分区通过表继承和规则系统完成,所以可以实现更复杂的分区方式。索引方面,PostgreSQL支持 B-Tree、哈希、R-Tree和GiST索引,MySQL取决于数据引擎,大多数为B-Tree索引。由于天文数据具有空间属性,位置坐标为(赤经, 赤纬),索引是一个二维的。建立一个高效的索引非常重要,使用第三方扩展库如Q3C索引即是采用二维索引,又如使用PGSphere中的GIST索引,会使数据的查询更加高效。所以当数据量非常大的时候,或者需要使用第三方库时,对于空间点索引时,采用PostgreSQL比MySQL方便得多。但若数据量不是很大,对于亿行级以下的数据量,不需要第三方库支持创建索引的数据,则采用MySQL比较好。同时MySQL比PostgreSQL较为高效。面对种种数据管理的需求,增加PostgreSQL作为该入库工具的底层数据库是必要的,天文工作者可以根据自己的需求存储到不同的数据库中。
1.1.2 Q3C索引
庞大的数据储存在数据库中,准确高效地使用这些数据,必须对数据创建索引,索引不仅能够加快数据的查询速度,而且使数据的管理变得简单容易,可以大幅提高系统的性能。当然索引的创建也不是越多越好,因为索引过多会随着数据量的增加而加大数据库的负荷,降低系统性能,所以索引的使用要准确得当。在本系统中,由于对天文数据进行入库管理,数据的复杂性、空间性决定了普通的一维索引不能很好地解决数据的查询管理要求,所以使用一个全新Q3C(Quad Tree Cube)对天空分区索引,能够很好地对天文数据进行二维空间索引,Q3C索引方案为开源项目运用于数据库PostgreSQL中,在使用的同时可以随时进行修改,非常适用于学术研究,由于直接运用于数据库,使用者不需要书写任何算法,Q3C的产生是专门针对天文数据,目的非常明确。虽然普通的索引如B-Tree也能够用于天文数据,但是如果需要进行锥形查询,在不使用Q3C索引的前提下,查询SQL语句非常复杂,查询速度非常慢,而且也只能运用于数据量较少的情况下,数据过多极有可能导致内存不足而出现程序卡死现象,然而上面的问题对于Q3C索引来说都不存在,所以这种基于四叉树的空间索引非常实用。Q3C索引不仅能够提供天文数据特有的查询,而且提供交叉认证功能,这对以后的数据处理,很大程度地简化了工作量,同时又容易使用,而且不论是在查询方面,还是交叉认证方面,Q3C提供的简单的SQL语句能够执行处理工作,而HTM则需要从数据库中提取数据,然后利用算法进行处理,当数据量非常大的时候,程序的性能会受到影响。
1.1.3 支持的数据文件格式
入库管理工具同时支持两种类型的数据格式文件:CSV(Comma-Separated Values)格式文件和FITS(Flexible Image Transport System)格式文件。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。FITS格式是天文界常用的数据格式,它专门为在不同平台之间交换数据而设计。1988年的国际天文学联合会(International Astronomical Union, IAU)大会指定IAU的FITS工作组全权负责此格式的修订。FITS文件由文件头和数据组成。在文件头中存储对文件的描述,如观测目标、源的位置、观测时间、曝光时间等信息,同时也可以在文件头中注明观测时的视场、精度等,便于后期的数据管理和分析。文件头部分每行占80个字符,并以END结尾。FITS文件的容量大小通常比相同数据量的CSV文件小,在本地存储中占用硬盘容量小,且天文数据文件采用FITS格式存储的文件占大多数。针对FITS格式文件数据,开发了一个分析FITS头文件的工具,用来得到头文件中表格数据的列名和每个列对应的数据格式,方便在使用入库工具时编写readme文件。在输入不同格式文件时,工具自动判断文件的格式,选择相应的程序实现自动入库。
1.1.4 存储数据的优化
庞大的天文数据难免存在的超过数据库中最大数据存储大小的数据或者小于数据库支持的最小数据,在数据库中可以定义数据类型支持导入的数据,但这样便失去兼容性,使得不同数据库之间数据交换和融合变得困难,而且在文件中的数据项为空时,存储到数据库中会产生错误,所以在入库前有必要对数据进行优化。因为不符合要求的数据非常少,而且改变其大小不会影响后续的数据分析,故在入库前,在程序中把超出数据库最大支持数据的记录数和小于数据库最小支持数据的记录数更改为数据库所支持最大和最小的数据记录数,同时对于文件中为空的数据项,程序根据数据类型的不同,自动填充 ‘9999’ 或 ‘NULL’ 字样,方便数据的录入和后续的计算分析。
1.2 AutoDB流程图
在存储FITS文件的数据时,专门开发了一个分析FITS头文件的工具,方便存储时选择想要存储的数据列。在使用过程中,不需要编写任何代码,同时该工具有很好的易用性。根据不同的格式文件,有不同的入库流程,图1给出了文本CSV和FITS文件的入库流程。

图1 AutoDB入库流程图
1.3 AutoDB系统环境支持
AutoDB采用Python语言编写,推荐使用Linux操作系统。由于Python是跨平台语言,若在WINDOWS系统中使用,需要安装Python,一般的Linux发行版本自带Python程序,同时也需要下列数据库系统(异地或本地均可)和第三方库作为支持:
(1)PostgreSQL(9.0+):支持最新的SQL语法,更高的功能完整性;
(2)MySQL(5.1+):性能非常高效;
(3)Q3C(Quad Tree Cube):一种基于PostgreSQL数据库的新的天文数据索引概念,提供海量天文数据的查询与融合。
该工具同时嵌入了一个虚拟终端,用户可以根据虚拟终端的反馈,了解在使用过程中出现的错误,从而纠正错误,使程序完美地运行。
1.4 AutoDB图形用户界面
AutoDB图形入库界面如图2,用户可以选择入哪种数据库,入库的数据文件及数据的说明文件,创建HTM的级数,分次上传的记录数,赤经赤纬列等。在这里,用户可以直接点击程序运行图形界面,也可以手动在命令行中使用命令运行图形界面,图形界面和主程序是分开的,协助用户按照各个参数,收集起来,按照一定的规范得到收集的参数,供主程序使用,也就是说主程序不依赖于图形界面,用户可以手动编辑指定的文件运行主程序。
FITS头文件分析工具把FITS头中的数据输出到文件中,该文件名由用户定义,在FITS SOURCE FILE对应的一行中浏览添加FITS源文件,然后在FITS HEAD FILE一行中输入要创建FITS头文件名,界面如图3。
在使用入库工具时,用户需要编写readme文件供程序使用,其格式如下:第1行为各列列名(即数据库表中的列名字段,请参照MySQL/PostgreSQL对字段命名相关文档),以一个或者多个空行分隔;第2行与第1行相对应,为每列的数据类型(如float、char、varchar、double、int,具体参照MySQL/PostgreSQL数据类型相关文档),同样是以一个或者多个空格分隔,内容不能有引号,字段不能为空或NULL。同时在FITS文件入库时,需要参照头文件分析工具得出的头文件以及格式转换文件编写readme文件。头文件分析工具得到的头文件实例如图4,格式转换文件如图5。
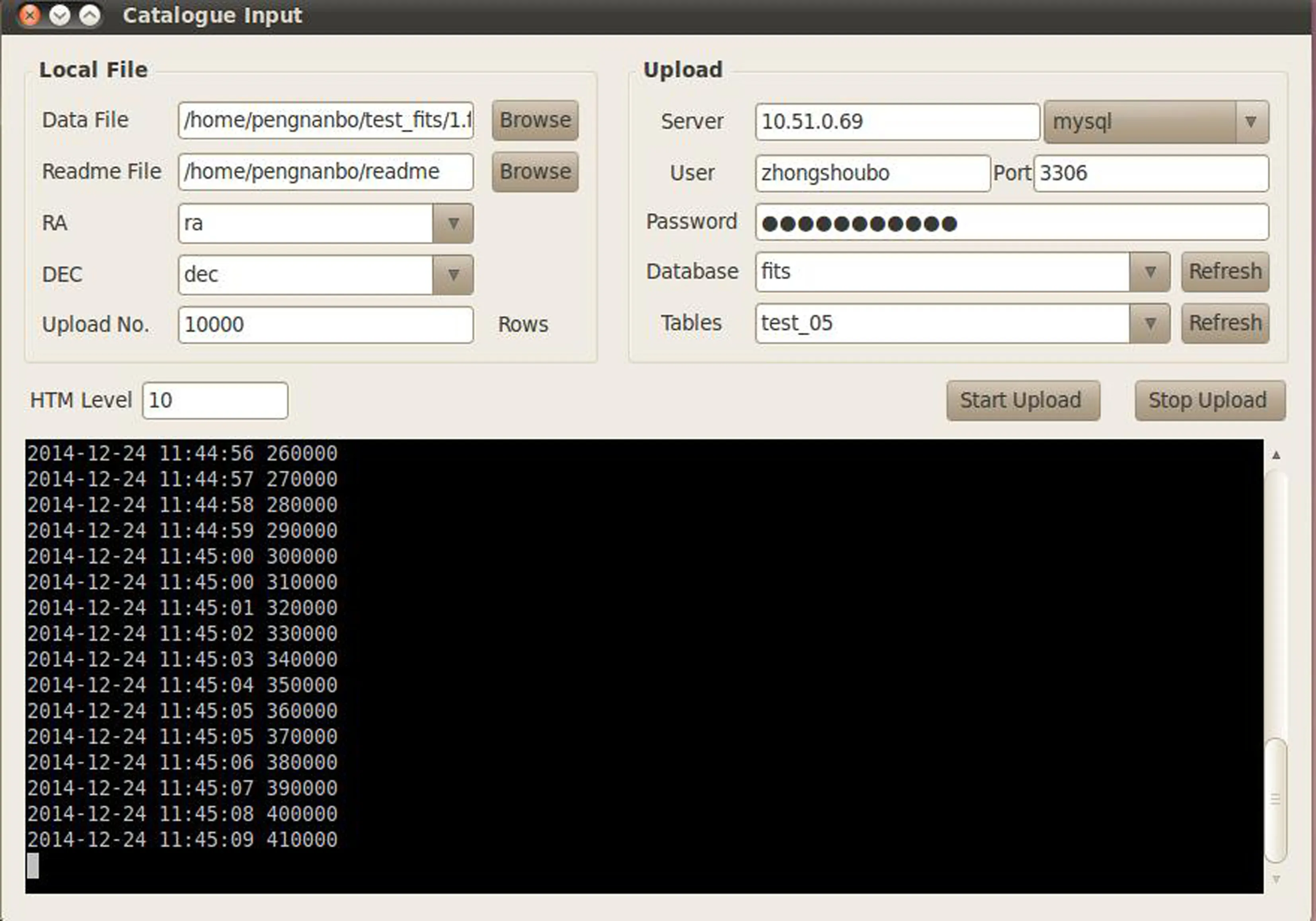
图2 自动入库工具界面
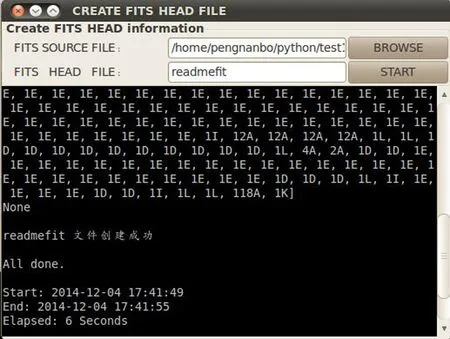
图3 FITS头文件分析工具界面

图4 头文件部分示例
readme样例文件,以PostgreSQL数据库为例:
DTEID SCRID OBS_ID RA DEC
Bigint bingint text float8 float8
编写readme文件完毕后,即可使用自动入库工具进行数据的录入,数据库可以由用户选择,数据库服务器可以是本地服务器或远程服务器。使用远程服务器时,应保证远程服务器支持远程连接,否则报错。

图5 头文件中格式的转换类型
2 实验结果
2.1 Q3C索引与非Q3C索引的查询性能比较
在使用索引时,最在意索引是否能够提高查询效率,对于具体选择哪种索引方式,要看哪种索引提高的性能更高。为此做了在数据库命令行的形式下使用SQL语句进行查询的实验。实验数据为Pan-STARRS数据,总共11 495 847个星表源数据。对比使用Q3C索引和不使用Q3C索引(对赤经与赤纬进行B-tree索引)的情况下,实现以赤经赤纬(5°, 50°)为中心,半径在0.1°到0.9°范围内的锥形查询,比较随着提取结果源数目的增多上述两种方案的查询时间,其结果如图6和图7。
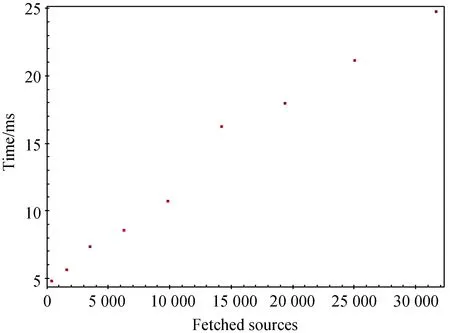
图6 Q3C查询时间图

图7 非Q3C索引查询时间图
从图7和图8可以看出,随着查询半径的增大,符合查询条件的源数目不断增多,同时查询时间以近似线性速度增长,说明查询元组数目越多,消耗的时间越多。还发现使用非Q3C索引的查询时间是使用Q3C索引时间的100多倍,可见Q3C索引方式的有效性。Q3C索引具有层次结构、平等区域、异维度分布等特性的天空分区方案,对天文数据的处理有得天独厚的优势。特别是在数据量大的情况下,使用Q3C数据索引,其表现不仅仅是数据查询速度的提高,对日后的交叉认证打下了很好的基础。
2.2 AutoDB工具的应用
AutoDB能够快速地将数据存储到相应的数据库,上传数据的速度与本地机器硬件性能、数据库的配置以及数据库服务器的位置(本地或异地)、数据量的多少以及索引的复杂程度有直接或间接的关系。建议在使用过程中本地机器不要运行太多的其他程序。
使用SDSS部分数据进行实验,总共有100 000 000行数据导入数据库,测试平台使用两台计算机,一台是本地数据库平台和程序运行平台,另外一台是远程数据库运行平台,通过百兆以太网访问远程数据库平台,具体配置如表1。

表1 实验平台软硬件配置
在实验过程中多次分别对本地和远程数据库进行入库,在入库时将数据分割为100 000 00行、200 000 00行、400 000 00行、600 000 00行、800 000 00行、100 000 000行导入数据库,得出实验结果如表2。单从数据上传的速度看,MySQL数据库的速度要优于PostgreSQL数据库。

表2 入库实验结果
3 总结与展望
针对当前天文大数据的特点,致力于开发高效、易用的海量天文数据自动入库工具。考虑到天文数据的海量、分布性等特点,分析了现有入库工具的优缺点,总结前人的设计成果,结合实际需求,应用高效的Q3C索引方案,改进开发了一个更加高效的大型天文数据自动入库工具AutoDB,同时参照国际上SAADA工具的功能。该工具能够协助天文工作者方便地存储、管理和处理数据,为后续研究工作中的数据融合、分析与挖掘做了铺垫,是海量异地异构多波段天文数据融合和挖掘工作的根本保障。AutoDB还有很多需要改进的地方,因为底层数据库的设计基于MySQL和PostgreSQL,所以用户在数据库选择方面只能选择MySQL和PostgreSQL,这点对用户来说有局限性。在自动入库工作中,数据库的性能是一个不能忽视的方面,性能是否良好直接影响中央处理器的利用率,所以有必要对数据库性能进行调优,在数据量大的时候,除了对数据表进行分表以外,也可以对数据库内存进行调整,达到最适合当前中央处理器工作的状态内存容量,同时也可以安装数据库的监控工具和趋势预测软件,如vmstat、iosta、top、Munin等等,对数据库进行实时监控,保证数据库在任何时刻处于高效状态。在程序编写方面,使用INSERT语句对文件的数据上传,而没有使用数据库自带的专有命令,这样会影响数据的插入速度和效率,由于专有命令没有一个接口程序引用,这在后续工作中进一步研究。参照SAADA工具的设计思路和优点,如SAADA工具支持大部分的关系数据库,不仅可以建数据库,而且可以收集不同的数据进行整合分析,同时能够将整理好的数据发布在网络上实现数据共享,下一步根据需求基于网络服务,实现网页建库和网页查询,这样工具使用起来更加方便,也会根据使用情况的反馈加以改进和提高。当然一个工具永远不是尽善尽美的,结合不断变化的需求,工具也要随之调整,从而一步一步地健壮,这样才能够与时俱进,不断地促进天文研究的发展。
[1] Zhang Y, Zhao Y. Astronomy in the big data era [J]. Data Science Journal, 2015, 14(11): 1-9.
[2] 张彦霞, 赵永恒. 数据挖掘技术在天文学中的应用[J]. 科研信息化技术与应用, 2011, 2(3): 13-27. Zhang Yanxia, Zhao Yongheng. The application of data mining technologies in astronomy[J]. e-Science Technology & Application, 2011, 2(3): 13-27.
[3] 张彦霞, 赵永恒, 崔辰州. 天文学中的数据挖掘和知识发现[J]. 天文学进展, 2002, 20(4): 312-323. Zhang Yanxia, Zhao Yongheng, Cui Chenzhou. Data mining and knowledge discovery in database of astronomy[J]. Progress in Astronomy, 2002, 20(4): 312-323.
[4] Zhang Yanxia, Zheng Hongwen, Pei Tong. Toolkit of automated database creation and cross-match[C]// Proceedings of the SPIE. 2012.
[5] 张彦霞, 赵永恒. 虚拟天文台: 科学、工具及应用[J]. 天文学进展, 2006, 24(3): 189-199. Zhang Yanxia, Zhao Yongheng. Science, tools and applications of the Virtual Observatory [J]. Progress in Astronomy, 2006, 24(3): 189-199.
[6] 高丹. 海量天文数据融合系统的开发与数据挖掘算法的研究[D]. 北京: 中国科学院国家天文台, 2018.
[7] 裴彤, 张彦霞, 彭南博, 等. Python多核并行计算在海量星表交叉证认中的应用[J]. 中国科学: 物理学 力学 天文学, 2011, 41(1): 102-107. Pei Tong, Zhang Yanxia, Peng Nanbo, et al. The application of multi-core parallel computing using Python language in cross-matching of massive catalogues[J]. Scientia Sinica: Pysica, Mechanica & Astronomica, 2011, 41(1): 102-107.
[8] 裴彤. 高效海量星表融合工具集的开发与GPU并行计算的天文应用研究[D]. 北京: 中国科学院国家天文台, 2011.
Design and Implementation of a Software Tool Package for Managing Massive Astronomical Data
Zhong Shoubo1,2, Han Bo1, Zhang Yanxia2, Zhao Yongheng2, He Boliang2
(1. Internationan School of Software, Wuhan University, Wuhan 430079, China; 2. Key Laboratory of Optical Astronomy,National Astronomical Observatories, Chinese Academy of Sciences, Beijing 100012, China, Email: zyx@bao.ac.cn)
As more large ground- and space-based observation equipments enter into service and more large-area sky survey projects progress, astronomical data are increasingly measured in terabytes, petabytes, or even exabytes. With astronomy entering the ‘massive-data’ era (‘facing a data ocean’), how to effectively store and manage the huge-quantity data becomes a central issue for astronomers. Astronomical data centers certainly need to store and manage massive data. Individual astronomers need to effectively manage their large amounts of data as well. The most basic task of management of data in huge amounts is to efficiently and automatically deposit data into a database. Moreover, efficient indexing of data is the key issue in application of data management. We have thus designed and developed a software tool package called AutoDB to manage massive astronomical data. In the AutoDB there is a virtual terminal for a user to monitor automatic storage of data. With the Q3C the AutoDB automatically creates new indexing based on sky partitioning and applies the technique of indexing in a two-dimensional space to effectively manage astronomical data. Improvement of data-management tools such as in our study can provide a sound basis for follow-up data fusion, data mining, and data analysis carried out by astronomers. Especially for astronomers using massive data, improved data-management tools allow them to focus on exploring scientific issues in their research.
Massive Data; Database; Data Management; Data File
国家重点基础研究发展计划 (973计划) (2014CB845700);国家自然科学基金 (61272272);国家自然科学基金委员会与美国德州农工大学联合基金 (11411120219) 资助.
2015-02-09;修定日期:2015-03-12
钟守波,男,硕士. 研究方向:大型数据管理和融合. Email: zhongshou bo@163 com
张彦霞,女,研究员. 研究方向:天文数据挖掘、天文信息学. Email: zyx@bao ac cn
TN919.5
A
1672-7673(2015)04-0510-08
CN 53-1189/P ISSN 1672-7673
猜你喜欢
军事文摘(2024年4期)2024-01-09 09:08:34
汽车实用技术(2022年10期)2022-06-09 11:33:52
汽车实用技术(2022年5期)2022-04-02 09:36:52
海洋信息技术与应用(2021年2期)2021-11-02 06:59:10
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
小学阅读指南·低年级版(2021年5期)2021-05-28 15:12:15
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
铁道通信信号(2020年4期)2020-09-21 09:15:24
电子制作(2019年13期)2020-01-14 03:15:18
