
成像制导中的多处理器并行及二值化算法研究*
2015-03-09 06:34卢军,怯新现,张天凡等
现代防御技术 2015年2期
关键词:嵌入式系统
成像制导中的多处理器并行及二值化算法研究*
卢军1,怯新现2,张天凡1,李哲1
(1.湖北工程学院 新技术学院,湖北 孝感432000;
2.湖北航天技术研究院 计量测试技术研究所,湖北 孝感432000)
摘要:导弹成像制导涉及大量图像处理和计算,一般系统实现多以高性能单或多处理器为核心。讨论了一种嵌入式多处理器系统的基本结构,利用平台特有的FSMC总线同时支持静态分割和任务级调度2种并行算法,并以此进行图像二值化算法的并行化研究。试验结果分析表明,该设计能够支持2种并行化算法,成倍减少图像处理的时间。
关键词:嵌入式系统;多处理器系统;FSMC总线;二值化算法;并行算法
0引言
导弹成像制导中空间导航、目标定位均涉及大量图像处理和计算,一般系统实现多以高性能CPU,FPGA或DSP等单核处理器或微控制器作为处理核心,例如文献[1]利用DSP实现成像制导;文献[2]图像在精确制导中的应用;文献[3]电视制导武器系统图像跟踪;文献[4]反坦克导弹电视制导图像处理系统等中均涉及大量的数字图像处理任务。因此,提高大规模数字图像处理能力成为武器装备性能提升的一个重要方面。
当前绝大部分高性、超级能计算机系统以Intel,IBM为代表的多核处理器为基础构建[5],而在四代到五代计算机体系的发展中,嵌入式多核、多处理器系统因其高性能、高可靠性、低功耗[6-8]等特点在空间图像处理、空间计算等领域日益受到关注。
提出一种基于ARM的嵌入式多处理器系统的基本结构,利用平台特有的FSMC总线实现了一种同时支持任务静态分割和任务级并行处理的结构,尝试从SMP方向进行研究。
1基于嵌入式多处理器系统
1.1系统结构
当前典型的多处理器结构主要以FPGA,DSP,ARM多种组合方式的AMP(异构系统)结构为主,如:文献[9]高性能异构多处理器平台,由FPGA和SPI流处理器组成;文献[10]提出了一种多处理器异构系统可以增加系统的冗余能力;文献[11]用FPGA实现互联的多DSP并行系统结构,如图1所示。文献[12-13]也以FPGA和DSP组合多处理器系统。

图1 FPGA与DSP并行处理异构系统结构框图Fig.1 FPGA and DSP parallel processing heterogeneous system architecture diagram
AMP的好处是可以利用不同处理单元的特性分别针对特定任务进行处理以加强系统的处理能力,但设计复杂、编程难度较大、通用性较低。因此尝试设计一种基于ARM的SMP多处理器系统弥补这些缺陷并加以验证。设计上使用五片芯片构成一个分布式存储MIMD结构单元,其中主处理器(主机)选用STM32F107,从处理器(从机)选用STM32F103RG,为每个处理器配备64Mbit的SRAM;主从机通过SPI总线连接,并通过平台特有的FSMC总线与存储器连接。验证流程主要分为设计输入、综合、功能仿真、实现、配置下载、下载后板级调试检错这几个步骤[14-15]。系统结构简图如图2所示。

图2 基于FSMC总线的多处理器系统结构简图Fig.2 FSMC bus based multi-processor system architecture diagram
该结构可以使用SMP也可以使用NUMA结构,非常规的AHB总线连接模式,可以通过高速以太网将多个系统构成群集[16],具有以下特点:
(1) 主机负责与外部进行数据/任务交互,在内部负责任务调度并处理部分任务,大多任务交给从机具体处理;
(2) 主机和从机拥有各自独立访问存储空间,但只允许主机访问从机存储空间以分派任务数据;而它们之间的调度主要通过硬件方式的信号量机制实现,因此无需传统处理过程的两次数据传输,可以节省大量通信开销;
(3) 主机和从机构成异步结构,从机之间则具有高度的并行性,可以实现任务级并行。
1.2二级流水线处理机制
图2所示结构中主机和从机采用特殊的FSMC总线结构连接,可以同时支持任务级别并行(算法11)和静态负载平衡(算法22)并行调度,通过对从机的调度可实现从机在两个时间周期内交替传送(分派)并处理任务,形成二级流水线处理过程,提高程序的并行性,从而较大幅度提系统的运行性能,如图3所示。
现结构主要使用外部存储器,如能利用处理器自有缓存则可以进一步优化调度流程。
1.3多工作模式切换
系统支持多种工作模式的切换以满足不同任务环境和算法的需求,是因为考虑到导弹制导的实际工作环境和可靠性要求。例如,在导弹飞行的初期和中期,可将绝大部分处理器资源用于姿态控制与导航,而在末端进行目标识别和制导时将调度更多处理器参与图像处理工作,如图4所示;如果某个处理器出现故障,可以将其负担的任务迁移到其它处理器,从而提高系统冗余度,提高系统的可靠性。
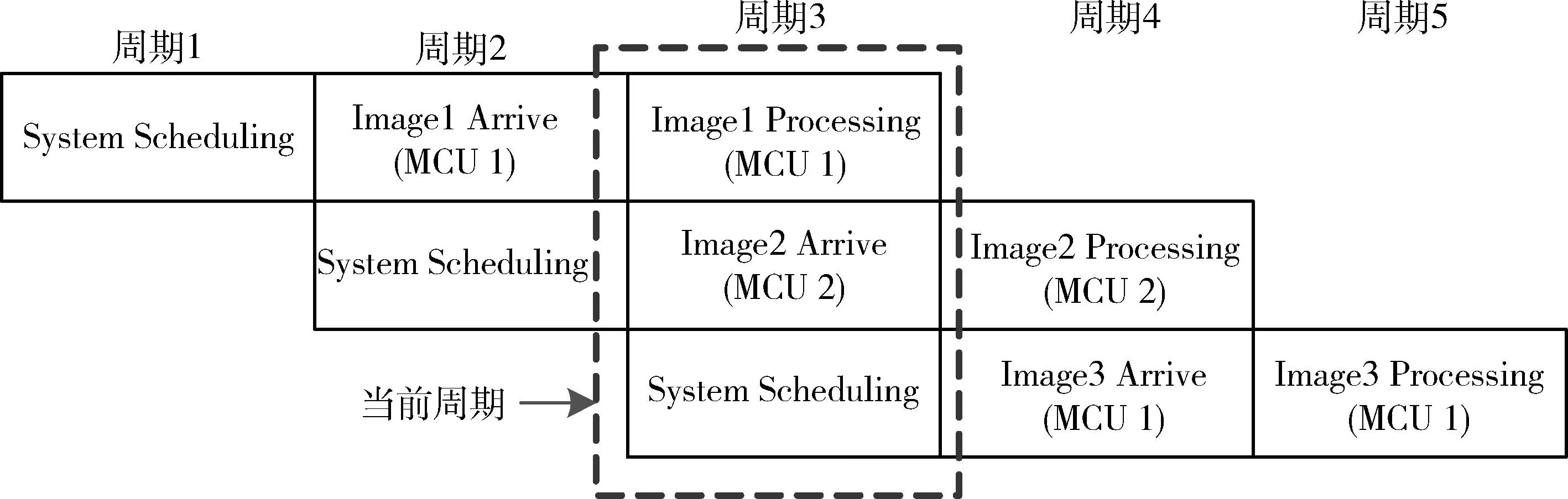
图3 系统的二级流水线处理过程示意图Fig.3 Two-stage pipelining processing system diagram

图4 导弹飞行中的处理器资源分布示意图Fig.4 Processor resource distribution diagram of a missile in flight
2图像二值化算法
成像制导中最基本的图像处理是图像二值化操作,因此以算法的并行化过程对系统基本性能进行测试。二值化算法是通过设定某个阈值,把具有灰度级的图像变换成只有2个灰度级的黑白图像。假设输入图像为的矩阵F[0,…,M-1,0,…,N-1],输出图像为M×N的矩阵G[0,…,M-1,0,…,N-1],假设阈值为T,那么图像二值化的算法为

(1)
3并行算法设计
任务模型:假设有R幅大小为M×N的图像待处理,系统中有n个处理器可以处理任务;系统中消息传递时间固定为TSR且与任务规模无关,单位字节传输时间为TW,如果一次传送E字节,则一次消息传递所需的总时间为T=TSR+TWE。
3.1静态任务分割算法

3.2任务级并行处理算法


主机主进程(){在从机上创建子进程管理对象;判定各从机空闲状态;将一个任务写入空闲从机,并通知该从机处理;接收从机任务完成信号并进行计时统计处理;若所有任务完成且没有新任务,则终止所有进程,否则循环执行本过程}从机子进程(){检查主机任务(中断)信号;有任务则从对应存储空间取任务并进行计算;完成任务,向主机发送完成(中断)信号}

图5 任务级并行处理算法流程简图Fig.5 Task-level parallel processing algorithm diagram
4算法分析
前面简单分析了2种算法的效能,这里再进行详细分析:
(1) 计算步
通过算法可知,对每个处理机来说,平均要执行NM/n个赋值运算步。
(2) 通信步
算法1:主处理机要把F矩阵发送给n个处理机,还要接收返回的计算结果,所以通信步为2n。
算法2:由于FSMC共享存储器的特性,待处理数据由主机调度直接由图像设备写入相应处理器存储空间,而结果无需回送主机并可直接转交给控制设备,因此通讯步为2。
(3) 计算复杂度和通信复杂度
从计算步的分析可知,两种算法的计算时间复杂度均为O(NM/n),算法1空间复杂度为O(NM/n),算法2空间复杂度为O(NM),关于通信复杂度:
算法1:根据静态任务分配策略,可以求出总的通讯量为

(2)
所以算法1的通信复杂度为O(NM).
算法2:只需将F矩阵发送给从机而无需回传结果,因此通讯数据量为NM,通信步为2,因此总通信量为
Ctlp(n)=2+NM.
(3)
任务调度所需通讯次数不随任务规模的增加而变化,算法2的通信复杂度为O(NM).
(4) 并行度
并行度计算仅考虑计算开始到完成之间的时间,因此理想的并行度为n。
(5) 加速比和效率
根据渐进加速比的计算公式

(4)
若有n台处理机可用,设一个赋值步的计算时间为,并且不考虑通信开销时,

(5)

(6)
所以,该算法理论上加速比可达到n(N),效率可达1。
(6) 系统加速比和系统整体效率
根据前文分析,系统在理想状况下的加速比和系统效率为:
对于算法1:


(7)

(8)
由于算法2不对任务进行分割,因此以R个任务的并行性进行分析算出其理想加速比和效率:

(9)

(10)

(11)

(12)
5系统测试
根据以上算法,在实验平台中选择规模为160×120,320×240,640×480 3种尺寸的任务分别进行了实际的测试,其结果如表1,2所示。
将2种算法所需的计算时间除以100得到的数值和效率值在一个范围内,便于进行比较,如图6所示。
从以上实验数据中,可以得到以下结论:

表1 静态分割算法测试表

表2 任务级并行算法测试表

图6 静态负载和任务级并行处理在不同任务 规模下效率折线图Fig.6 Efficiency line chart of static load and task-level parallel processingunder different scales of the task
(1) 由于任务粒度的关系,算法1的整体效率低于算法2;同期算法1所需的计算时间增长幅度也明显高于算法2,计算时间的增长导致了效率曲线在规模增加后逐步收敛;
(2) 算法1需要的通信步较多,其总执行时间约为算法2的2倍。但系统计时精度为毫秒级,低于毫秒无法有效计算,因此在任务规模较小时误差较大,因此以上测试的初始效率约为63%;
(3) 随着处理机数的增加,2种算法的加速比和效率都得到了增长,但算法2的增长幅度较快。特别是算法1的执行效率没有明显提升,这是因为貌似均衡的分割算法导致了各个任务之间分配的不均衡,分割算法产生了通讯,也就影响了其整体效率的提升;
(4) 表1,2中规模为640×480的图像处理时间均低于40 ms,满足连续图像的实时处理要求。但实际应用中还可能需要进行如均衡化、降噪等处理,这将延长处理时间,降低实时性处理能力。以中值滤波为例,系统采用基于冒泡法排序的串行化算法约需4 259 ms,而快速排序的FSMF算法[17]可以将时间复杂度降低到O(NlnN);NSMF可以将3×3模板的比较次数降低到30次;基于统计思想的SMF算法和FMF算法需要21次比较;文献[18]仅需要18次比较,这都可以较大幅度的提高系统的吞吐量。分别采用以上算法后优化,对于规模为640×480的图像处理结果如表3所示。

表3 中值滤波算法的多种优化并行处理结果对比
从表3中可以看到不同任务所需的时间差异是巨大的,图像二值化串行时间需要72 ms,而基于冒泡法排序的中值滤波任务则需4 259 ms,根本达不到图像的实时化处理要求,但是也应看到通过并行算法以及处理机数量就可以成本减少处理时间,与此同时如果能够对具体任务本身所需的基本算法进行改进,可以更大幅度的减少处理时间,如基于快速计算的中值滤波在并行度为4时需606 ms完成任务,相比基础的冒泡法已经提升了7倍的性能。
6结束语
针对成像制导中图像处理系统构建的具有FSMC特殊总线的SMP多处理器并行处理系统,由主机进行任务调度和快速切换,支持静态任务分割和任务级并行处理,大大提高了系统的处理能力。研究并实现了图像处理中基础的二值化并行处理算法以及中值滤波算法的性能度量。虽然系统的单项任务处理能力能够满足需求,但对于实际中复杂多任务任务处理的能力还不足,这与目前选用的STM32本身的处理能力有关,后续研究中可以使用性能更好的如Cortex-A7/A8架构的系统提升基础运算能力并重点关注复杂任务的并行化处理过程。
参考文献:
[1]尹哲春,张福欣,马红艳.基于DSP的成像制导仿真图像生成技术研究[J].电子设计工程,2010,18(6):87-88,92.
YIN Zhe-chun, ZHANG Fu-xin, MA Hong-yan. Imaging Guidance Simulation and Image Generation Technology Based on DSP [J]. Electrical Design Engineering, 2010,18 (6) :87-88,92.
[2]祝明波,陈麒,张东兴.图像在精确制导中的应用综述[J].飞弹导航,2013(11):70-74,84.
ZHU Ming-bo,CHEN Qi, ZHANG Dong-xing. Overview of Image Applications in Precision-Guided [J]. Missile-Guidance, 2013(11):70-74,84.
[3]鲍学良,范惠林,刘成亮.电视制导武器系统图像跟踪方法研究[J].吉林大学学报,2012,30(4):355-360.
BAO Xue-liang, FAN Hui-lin, LIU Cheng-liang,et al. Image Tracking Method for TV Guidance Weapon System[J]. Journal of Jilin University, 2012,30 (4):355-360.
[4]刘光灿,白廷柱, 黄飞江.反坦克导弹电视制导图像处理系统设计[J].激光与红外,2011,41(1):79-83.
LIU Guang-can, BAI Ting-zhu, HUANG Fei-jiang. TV-Guided Anti-Tank Missile Designed Image Processing System [J]. Laser and Infrared, 2011,41 (1):79-83.
[5]MCNAIRY C, Bhatia R Montecito.A Dual-Core,Dual-Thread Itanium Processor[C]∥ IEEE Micro, 2005, 25(2):10-20.
[6]Lee Trong-Yen,Fan Yang-Hsin,Cheng Yu-Minetal. Hardware Oriented Partition for Embedded Multiprocessor FPGA System[C]∥Proceedings of the 2the International Conference on Innovative Computing, Information and Control (ICICIC 2007),Kumamoto, Japan,2007.
[7]TOLEDO F,MARTINEZ J, FERRANDEZ J. FPGA-Based Platform for Image and Video Processing Embedded Systems[C]∥Proceedings of the 2007 3rd Southern Conference on Programmable Logic(SPL’07),2007:171-176.
[8]LI Yong,WANG Zhi-ying,ZHAO Xue-mi,et al. Designg of a Low-Power Embedded Processor Architecture Using Asynchronous Function Units[C]∥Lecture Notes In Computer Science,2008:354-363.
[9]全巍,文梅,伍楠,等.高性能异构多处理器平台及其应用[J].计算机工程与科学,2011, 33(1):60-65.
QUAN Wei,WEN Mei,WU Nan, et al. High Performance Heterogeneous Multi-Processor Platforms and Applications [J].Computer Engineering and Science, 2011, 33 (1): 60-65.
[10]刘品阳.一种多处理器异构系统设计与实现[J].计算机技术与发展,2011,21(5):179-182.
LIU Pin-yang. A Multi Processor Design and Implementation of Heterogeneous Systems [J].Computer Technology and Development, 2011, 21 (5) : 179-182.
[11]颜露新,张天序,邹胜,等.用FPGA实现互联的多DSP并行系统结构[J].系统工程与电子技术,2005,27(10):1757-1775.
YAN Lu-xin,ZHANG Tian-xu, ZOU Sheng, et al. Realized by FPGA Interconnects System of Multi-DSP Parallel Structure [J]. Systems Engineering and Electronics, 2005, 27 (10):1757-1775.
[12]王洁,张淑燕,刘涛,等.基于FPGA的嵌入式多核处理器及SUSAN算法并行化[J].计算机学报,2008,31(11):1995-2004.
WANG Jie, ZHANG Shu-yan, LIU Tao, et al. Embedded Multi-Core Processor Based on FPGA and Parallelization of SUSAN Algorithm [J]. Computer Journal, 2008, 31 (11): 1995-2004.
[13]吕雷,王明昌,秦金明.基于FPGA的多DSP红外实时图像处理系统[J].现代电子技术, 2010(22):97-99.
LÜ Lei, WANG Ming-chang, QIN Jin-ming. Based on Multi-DSP FPGA Real-Time Infrared Image Processing System [J]. Modern Electronic Technology, 2010(22):97-99.
[14]YAN Li-ke, SHI Qing-song, CHEN Tian-zhou,et al. An on-Chip Communication Mechanism Design in the Embedded Heterogeneous Multi-Core Architecture[C]∥Proceedings of the 2008 IEEE International Conference on Networking ,Sensing and Control(ICNSC),2008:1842-1845.
[15]Vermeulen Bart. Functional Debug Techniques for Embedded System[J].IEEE Design and test of computers, 2008,25(33):208-215.
[16]张天凡. 基于Cortex嵌入式架构的智能储物管理系统[D].武汉:武汉大学,2012:10-12,33,56-60.
ZHANG Tian-fan. Embedded Intelligent Storage Management System Architecture Based on Cortex [D].Wuhan: Wuhan University,2012:10-12,33,56-60.
[17]Rafael C Gonzalez,Richard E Woods. Digital Image Processing [M].New Jersey: Prentice Hall,2010:178-179.
[18]董付国,原达,王金鹏.中值滤波快速算法的进一步思考[J].计算机工程与应用,2007,43(26):48-49.
DONG Fu-guo, YUAN Da, WANG Jin-peng. Further Consideration of Fast Median Filtering Algorithm [J].Computer Engineering and Applications, 2007,43 (26): 48-49.
Multiprocessor in Missile Guidance Systems and Research of Binarization Algorithms of Parallel Algorithms
LU Jun1, KAI Xin-xian2,ZHANG Tian-fan1, Li Zhe1
(1.Hubei Engineering University,College of Technology,Hubei Xiaogan 432000,China;2.Hubei Institute of Aerospace Technology,Institute of Measurement and Testing technology, Hubei Xiaogan 432000,China)
Abstract:Missile guidance involves a large amount of image processing and calculations, and generally system realization takes single or multi high performance processorsasits core. The basic structure of an embedded multiprocessor system is analyzed, and the platform-specific FSMC bus is used to support static segmentation and task-scheduling two parallel algorithms, and further study the parallelization of image binarization algorithm. Test results show that the design can support two parallel algorithms, greatly reducing image processing time.
Key words:embedded systems; multiprocessor systems; FSMC bus; binarization algorithm; parallel algorithms
中图分类号:TJ765.3
文献标志码:A
文章编号:1009-086X(2015)-02-0103-07
doi:10.3969/j.issn.1009-086x.2015.02.017
通信地址:432000湖北省孝感市学院路158号E-mail:mail.lujun@gmail.com
作者简介:卢军(1975-),男,湖北孝昌人。副教授,硕士,研究方向为网络信息安全与多智能体协同控制。
基金项目:湖北省自然科学基金(2014CFB576);湖北工程学院自然科学基金(201515)
* 收稿日期:2014-10-20;
修回日期:2014-12-05
猜你喜欢
计算机教育(2016年8期)2016-12-24
电脑知识与技术(2016年28期)2016-12-21
计算机教育(2016年10期)2016-12-19
电脑知识与技术(2016年27期)2016-12-15
科学与财富(2016年15期)2016-11-24
电脑知识与技术(2016年24期)2016-11-14
计算机教育(2016年7期)2016-11-10
计算机教育(2016年7期)2016-11-10
