
数字图书馆用户信息获取行为研究
2015-03-03 02:58:23陈越都平平王静
中国教育网络 2015年5期
文/陈越 都平平 王静 等
数字图书馆用户信息获取行为研究
文/陈越都平平王静等
随着数字图书馆的发展,用户对文献资源的利用方式逐渐转向在线形式。据教育部图工委统计, 国内高校2012年馆均电子文献采购经费180万元,是2007年的2.2倍。在电子文献资源的使用大幅增加的情况下,如何获取数字图书馆用户信息行为的相关信息,以便为数字图书馆信息平台建设、电子资源配置提供依据,成为值得研究的问题。
对网络用户信息行为的定量研究方法有日志数据挖掘、系统软件计数及网络数据采集等途径。这些方法在改善现有评估手段的同时,也不同程度的存在一定局限性,主要有以下几点:
1.数据获取对业务环境的依赖性强。日志挖掘方法中,用户端和服务器端缓存(Cache)、代理(Proxy)及防火墙地址转换(NAT)等技术都会影响对数据的获取和处理,从而削弱挖掘效果。获取系统软件计数数据时一般依赖电子资源数据库厂商提供,实时性较差且有时难以获得完整数据。
2.行为信息提取内容较少。基于服务端系统软件计数或日志挖掘的方法很难收集到用户端个体信息,现行的基于网络层统计的方法又侧重于用户行为模式的判断,忽略行为内容的分析。如基于snort的过量下载检测方法,其处理的数据层次局限于网络层,没有对应用层数据作进一步处理,基于DPI的pdf文件下载检测方法仅对特定类型进行捕获,同样也没有针对应用层信息进行分析和处理。
针对上述局限性,本文利用应用层特征分析技术对数字图书馆用户信息获取报文进行分解处理,讨论了相应处理过程并用算法予以实现,最终设计了系统原型并进行了开发与测试。
用户信息获取行为报文的应用层特征分析与检测
报文的特征分析
针对文献获取行为,利用Fiddler软件,我们进行了报文截取和分析。一个典型的下载请求如图1所示。

图1 用户请求报文结构
在该请求报文的首部字段中,即可获取提供下载报文的主机域名或IP地址,如:Host: libvip.cumt.edu.cn
对起始行中的Get请求进行分析,其中包含如下信息:
1.该下载请求的文件存放路径:
file=R1388765X�07�0245759469.pdf
2.下载文件名:
title=%e7%89%99%e9%be%88%e5%8d%9f%e5%95%89% e5%8d%95%e8%83%9e%e8%8f%8cPG2206%e5%9f%ba% e5%9b%a0%e7%aa%81%e5%8f%98%e6%a0%aa%e7%9a %84%e6%9e%84%e5%bb%ba.pdf
由此可见,对于特定电子资源站点的下载请求,可通过对相应报文的分析获取有意义的信息。文献获取报文具有如下特征:
1.HTTP首部字段中描述了目的主机信息,如域名、IP地址等;
2.在GET请求中,通过“参数名=值”的形式存放了与下载有关的信息,如文件名、存放路径、文件类型等;
3.在URL中,中文被重新编码,以%作为编码的转义标志。
基于特征分析的检测方法
基于上述报文特征分析过程,我们可以归纳出相应检测方法。首先进行网络层协议解析,获取报文的五元组(源IP地址、源端口、目的IP地址、目的端口、协议号)信息。其次,将承载行为特征的HTTP报文逐层拆开,获取目的主机域名、资源名称、文件特征等应用层信息。最后,将获得各类信息进行必要的编码转换工作,从而形成一条完整的用户资源利用行为记录,最终依照统一的数据结构存放在数据库中。
原型系统设计
设计原则
原型系统在设计时重点考虑了以下几个原则:无侵入数据采集、分布式预处理、动态URL元数据构建。提出上述设计原则的主要目的是:
3.解决大流量情况下的数据处理压力。系统采用分布式预处理结构。通过在分散的采集平台上通过预处理过滤措施指定业务流量,减少后端处理压力。
3.统一文献获取记录描述方式。为避免URL描述方式不一致带来的差异,将不同电子资源厂商的下载URL转换成统一的文献获取记录。在系统设计时以模块形式针对不同电子资源进行URL元数据格式设计,通过灵活的数据构建支持动态扩充被分析的电子资源目标。
原型架构
系统以一个采集节点、一个数据存储及分析节点、一个WEB查询服务节点的形式完成原型实现,整体架构如图2所示。
图2中WEB查询服务节点、数据分析及存储节点采用Java语言根据前述设计方案开发,综合使用了Struts2、Spring、Hibernate等开发框架。数据采集节点运行在CentOS操作系统平台上,与前面两个节点独立,并可以增加数量,实现系统处理能力的动态扩充。
与在服务器主机上部署代理程序等侵入式的数据采集方法不同,本系统采用交换机网络端口流量镜像功能,将目标业务流量镜像到分析平台所连接的网络端口。由于不需要获取资源服务器上的数据或在服务器上安装插件,可以方便的对各类用户信息获取行为进行计量。
数据用SPSS20.0进行分析,计数资料(%)表示,X^2检验;计量资料(±s),t检验。差异具有统计学意义(P<0.05)。
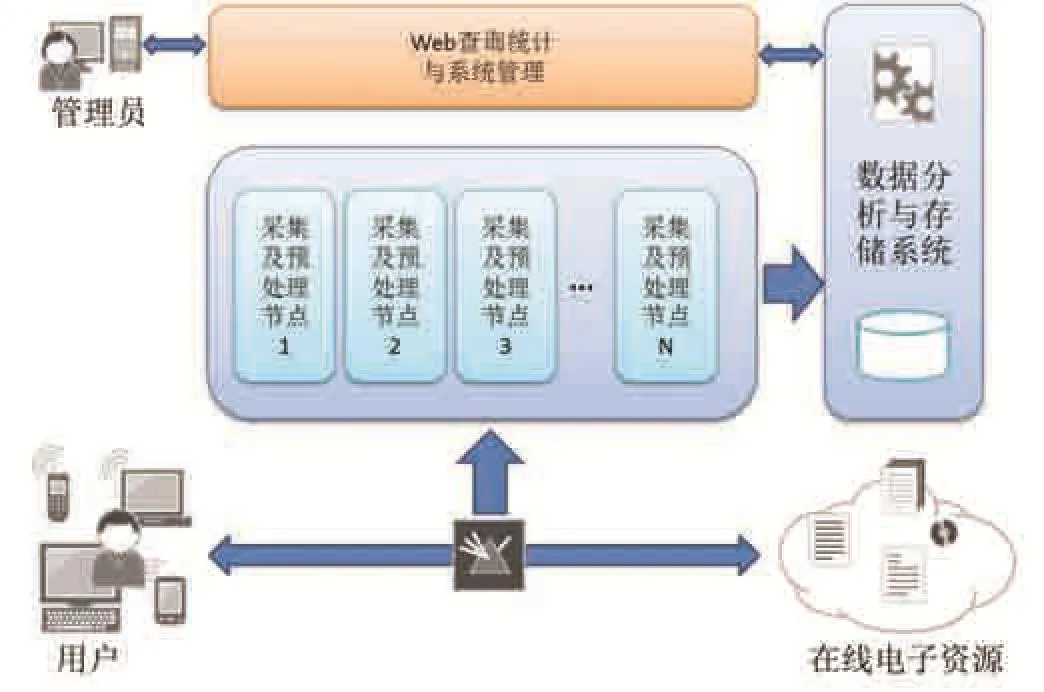
图2 系统实现架构
原型系统实现方法与工作过程
分布式预处理
在采集到的数据到达分析平台后,需要对相应网络数据报文进行预处理,以便去除非目的IP的数据报文,减少后续等待处理的网络数据数量,提高系统的处理能力。本系统使用的预处理工具是snort,这是一个开源的IDS(入侵检测系统)工具,我们利用其对数据报文的过滤功能实现相应预处理。其过滤器配置如下:
A l e r t t c p a n y a n y - > 202.119.200.80/32 80 (content:”filename”; msg:”cnki”; sid:”10000001”; priority:1;)
过滤器配置中content部分定义了需要进行匹配的字符串,msg部分定义了日志输出信息,sid部分定义了规则唯一的标识,priority部分则定义了规则的优先级。上述过滤规则定义了触发规则的动作,对应的协议以及包括IP地址、网络、端口在内的源与目的信息。通过这些限制,最终被收集到后端的数据能够被有效减少。通过在不同节点采用不用的预处理规则,还可以实现分布式的数据采集。
URL解码和元数据对象构建
在正确提取URL的基础上,需要对URL进行解码。URL中通过转义表示法表是安全字母表之外的二进制数据或字符,这种转义表示法包含一个百分号(%),后面跟着两个表示字符ASCII码的十六进制数。通常我们所得到的URL如下:
http://docdownload.cnki.net/ msldown/detractrequest.aspx? downtype=pdfdown&nettype= cnet&display=chinese&encod e=gb&filename=EpnN3kTe5Fz N3pkS4t0M3Zjb2IEVlFDe4UHc wMmZ1omRjZGOJRTVWJ3U4 d3bCBzZCRkQPtmUNlEehR3d 19COY52dXd3aiJVOLlVOXhD boh3ZmtkaxEUNwRDOndkTXR nM41EbwEEawwWO3NXQ2M 1Z0MTZG5UeDN0NT5GTm9WOkZkaYpVYNlkWuNmU1EDa Ud2dEhmc5YWRzYWT1hWRFF3R1MVNF1EdzJGN5UEWPJ DeuJndyJEZWpme1FDZQdDVKhmTNVWQudVdVlXc==QP 9cXVGdjY14WORtSd3EUdZJkMxJ2MrZVN3lnUFtUbxhGWB hVZylDd5cFS55UR4ZVWmtme1MWaBdUbIZjZZNWdvc2TW x2TM10ZBNlM15keyknSMFHbFJEdyEVS1sUc5kFZKtGbKx 2cxh0QnplbuJnMS9CNylTWTdVYihjWiF0a3onQx8ScUFXOZ dlel1UdShzNrgUUOp3cwR1TmJTYWdkV20UWaxWaDlnYC ZkRiZmT3ITeHVEZrdUewl1StRGbipFSJRnUZdGS&filetitle= %b4%d3OCW%bf%ce%cc%c3%b5%bdMOOC%d1%a7% cc%c3_%d1%a7%cf%b0%b1%be%d4%b4%b5%c4%bb% d8%b9%e9_%d5%c5%d5%f1%ba%e7&dbcode=CJFQ&d b=CJFQ2013&pager=22-29&zt=H127&doi=CNKI:SUN:XD YC.0.2013-03-007
其中存在形如“%bb%f9%d3..”等类似的编码。在系统实现中,我们将该编码转换成以可阅读的字符集形式。
不同电子资源站点所采用的请求URL格式存在差异,主要是请求URL的所提交的参数结构不同。同时,HTTP头部的其他信息结构只有内容上的不同,并没有数据结构的差异。如图3所示从CNKI下载电子资源的请求报文。
对上述报文中的起始行GET请求进行分析,可以看到该下载请求在标准的HTTP头结构上附加了几个特性化参数,如encode、nettype、doi等。针对不同电子资源的特性化下载信息,我们需要通过构建不同的文献获取行为元数据模型来进行描述。例如,针对上述CNKI用户信息行为,我们构建的用户信息行为元数据模型包含以下内容:
1. 资源描述数据
包括与单次行为相关的电子资源的名称、存储名、资源类型、编码类型、所在数据库等资源描述信息。

图3 用户信息行为请求报文结构
2.用户行为数据
包括单次下载活动的源地址、目的地址、主机名、下载方式、网络类型、下载时间等行为描述信息。
根据上述内容构建的一个信息行为记录元数据对象所包含的内容见表1。

表1 信息行为记录元数据对象内容
基于JavaEE开发平台,上述内容可以很方便的以对象的形式映射到业务系统中,作为业务系统中的逻辑实体来进行管理,同时也可以将其持久化到数据库中作为数据存储和分析的基础。通过定义不同的资源元数据对象,就可以对各种类型的用户信息获取行为进行描述。
应用层特征解析处理
业务下载具有典型的时间规律,在正常作息时间内下载量较大而在无人工作的夜间采集到的下载信息较少。为了能够平滑数据采集量的大小对后台分析产生的压力,本系统采用自行设计的缓存队列分时分析算法进行载荷数据应用层特征解析处理,其算法流程图如图4所示。

图4 应用层特征分析算法流程
该算法的特点是在系统中以缓存队列形式存放待处理的报文信息,根据系统处理能力动态调整每个批次的处理数量,在不丢弃任何信息的基础上尽力实现报文的实时解析。
原型系统上线测试及分析
原型系统开发完成后进行了上线测试,以我校当前购置的电子资源数据库作为分析目标,系统收集的电子资源捕获类型不限于PDF,只要是电子资源站点提供的各类资源格式都可以被采集用于统计。
在一周的时间内,已经获取可供分析的文献获取记录2万余条,如图5所示。通过分析测试获得的数据,我们可以观察到系统按照要求对相应报文的应用层数据进行了分解,不但获取了用户下载行为的一般特征信息,如五元组信息(源IP、源端口、目的IP、目的端口、协议类型),还进一步获取了用户资源访问对象的信息,如下载文件名、文件类型、数字对象唯一标识符、文件编码类型等信息。原型系统的测试验证了本文提出的基于特征层分解的信息获取行为检测方法的可行性。
基于对图书馆用户信息行为报文的应用层特征分解,本文提出了相应的检测与分析方法,并根据该方法实现了原型系统,其特点如下:
1.对数据报文进行一次采集即可同时完成网络层数据与应用层数据的检测分析;
2.实现对用户资源利用行为的各类信息的全面获取与记录;
3.利用分布式的数据收集与处理架构在实时采集数据的基础上保障了分析能力,并可以进一步实现处理能力的动态扩充;
原型系统为开展文献获取行为计量和利用分析提供了基础平台,后续尚需在数据关联分析方面开展进一步研究,以便进一步获取用户电子资源利用行为的全景信息。

图5 获取可供分析的文献获取记录2万余条
(作者单位为中国矿业大学图文信息中心)
(注:本文系江苏省教育厅高校哲学社会科学基金指导项目“数字环境控制下区域科技信息服务风险管控研究”(项目编号:2013SJD870017)的研究成果之一)
网管技巧读者服务
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24
小资CHIC!ELEGANCE(2021年45期)2021-01-11 03:51:12
铁道通信信号(2020年4期)2020-09-21 09:15:24
中国外汇(2019年11期)2019-08-27 02:06:30
英美文学研究论丛(2018年2期)2018-08-27 01:56:18
教育教学论坛(2016年49期)2017-02-27 21:19:25
剑南文学(2016年14期)2016-08-22 03:37:42
铁道通信信号(2016年8期)2016-06-01 12:10:21
电测与仪表(2016年21期)2016-04-11 12:43:52
人间(2015年20期)2016-01-04 12:47:08
