
大数据将与AI形成良性循环
2015-02-28 07:36王劲
机器人产业 2015年4期
□文/王劲
大数据将与AI形成良性循环
□文/王劲
大数据、人工智能是近几年炙手可热的词汇,但是,你是否想过,如果将两者结合起来会产生哪些意想不到的魔力呢?在国内互联网市场独占搜索鳌头的百度公司,正在尝试将两者结合成新的源动力,来推动更多行业的快速发展。

在各种O2O服务层出不穷、360行裂变为3600行的今天,用户对服务的需求也迅速增长。谁能够更好地满足他们,显然就可以获得市场先机。
百度现在正努力地索引着真实世界。通过对真实世界的索引,把海量数据沉淀下来,成为百度大数据的基础和重要组成部分。百度通过大数据连接3600行,打通线上和线下,把线上和线下的数据融合起来,产生核聚变,进而迸发出新的能量,让大数据成为3600行的商业新能源。
大数据重新定义资产
谷歌执行董事长艾瑞克·施密特曾经说过,现在全球每两天所创造的数据量等于从人类文明至2003年间产生的数据量的总和。互联网用户产生的数据包括语音、图像和视频,同时应用于物联网、智能监控等领域的各种智能设备产生的数据更是漫无边际、浩如烟海。而海量数据的危机并不单纯是数据量的爆炸性增长,它还牵涉到数据类型的改变。原来的数据都可以用二维表结构存储在数据库中,如常用的Excel软件所处理的数据,称之为结构化数据。但现在由于互联网多媒体应用的出现,使诸如图片、声音和视频等非结构化数据占到了很大比重。而产生智慧的大数据,往往是这些非结构化数据,能否在短时间内把数据处理好决定了数据的价值,这就需要新的技术突破,使数据成为最有价值的资产。
数据的采集、处理和应用的过程可以影响新的数据的产生,从而形成反馈。百度的反馈过程是一个正向反馈,使系统更有效率。百度大数据将与行业数据深度融合,最终帮助行业内企业能够实现数据的闭环。
以O2O为例,通过目前相关的软件和技术,百度可以对每一家门店的顾客信息进行深度挖掘,帮助门店了解用户群体,实施精准营销,实现精细化运营。而通过精细化运营可以让商家获得更多的客流和流水。同时更多的客流和流水形成新的数据,又被百度采集,使正向循环越变越好,越来越高效,这是大数据发挥价值最为关键的地方。
“百度大数据+”是百度面向各行业开发大数据的平台,包括数据融合、洞察用户、智能模型和匹配能力,同时基于数据融合对群体用户进行立体画像描绘,对线上线下用户行为分析,对从“多屏”到“跨屏”的用户进行识别。百度有决策模型、推荐模型和绿色模型,此外,百度还开发了七个服务模块,包括了行业洞察、营销决策、客群分析、舆情监控、店铺分析、推荐引擎以及数据加油站。百度数据已在零售、O2O、旅游、金融、保险、房地产等方面与商家深入合作,并取得了可喜的成果。
王劲 百度公司高级副总裁

图1 需要新技术突破使数据成为有价值的资产
大数据助力零售业
线下零售业面临电商竞争挑战压力非常大。线下零售业如何利用互联网和新的技术赢得新的竞争优势,已成为业界关心的话题。线下零售业竞争最关键的核心是看谁能提供最好的用户综合体验。谁的体验好,谁就能赢得先机。
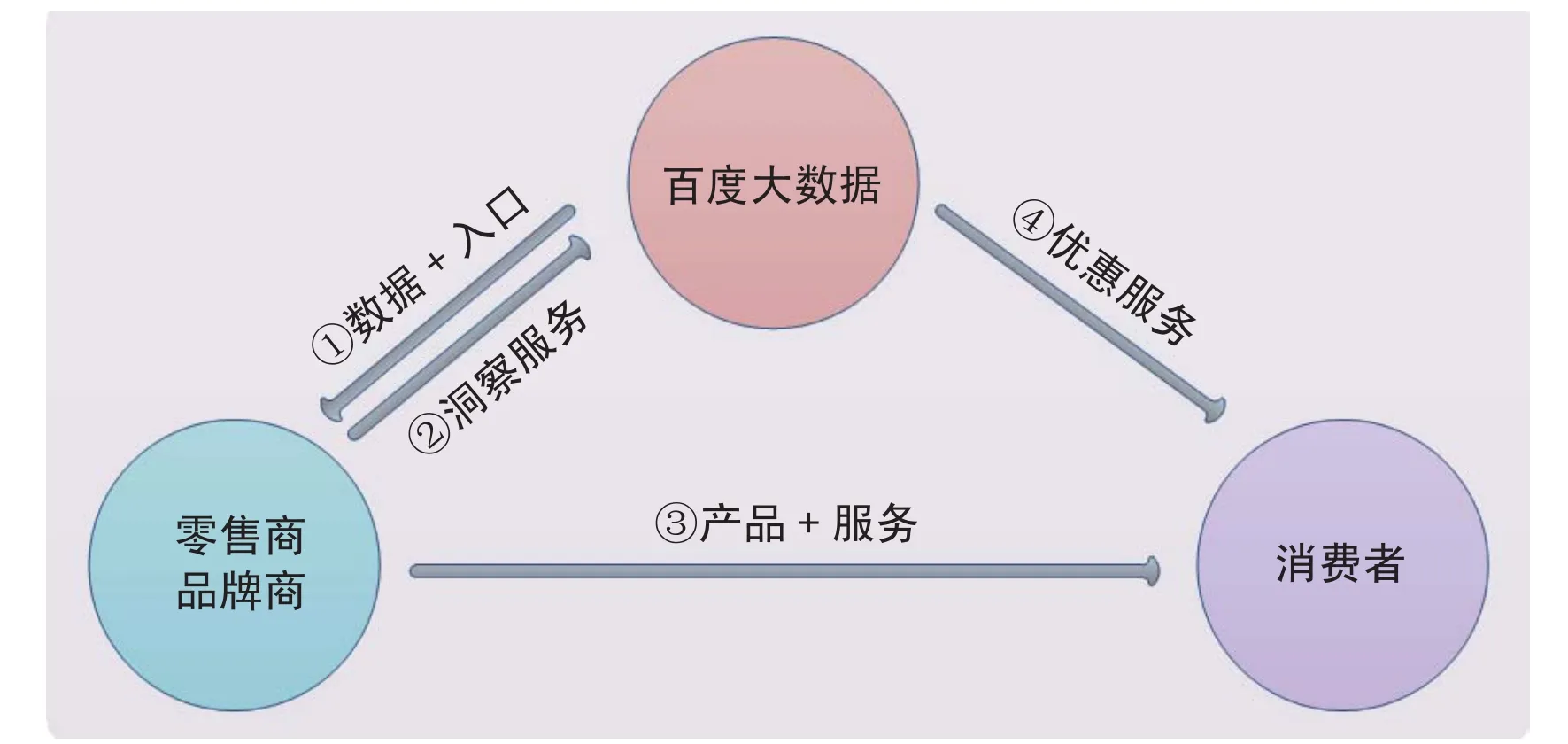
图2 大数据助力零售业
过去传统零售业与百度合作,是希望通过百度的搜索和“凤巢”推广,把线上的用户导流到线下,使之也变成他们的客户,这是单向导流。而百度大数据可以对用户有更全面、更深入地了解,百度能够更好地了解这些用户的特性,更好地识别用户的需求,从而帮助线下企业为用户提供个性化营销方案或个性化服务。
不久前,百度和北京朝阳大悦城在大数据方面展开了合作。在充分保障用户隐私和安全的前提下,把百度海量的线上数据和朝阳大悦城线下多年积累的数据结合在一起,从而更好地洞悉用户的需求。基于此类大数据,百度和朝阳大悦城制订了一些更有针对性、更精准的推广计划。这种个性化的推广计划在很大程度上提升了朝阳大悦城的销售量,其会员销售额提高了12%,未购买品牌推荐转化率提升了五倍,非活跃会员到场消费率提高了53%。这只是双方合作的第一期,仅是在推广服务方面进行的合作。下一阶段,双方还将通过百度糯米和朝阳大悦城的合作,实现线上和线下服务的打通,将大数据的威力再提高一个层次。
大数据助力互联网金融
互联网金融是现在热门的话题。金融行业希望能够得到互联网公司的大数据,也希望能够得到互联网公司的技术支持。他们希望通过此类结合实现“弯道超车”,能把中国的金融业提高到一个新层次。把线上的海量数据和线下的金融数据结合在一起,这将对基金选股、风险控制、信用评估有很大的帮助。
过去金融行业的分析师在做决策的时候,一般从几十甚至几百个维度来作判断。当有了互联网大数据之后,分析师已能够非常准确地监控上万个纬度的数据。而且不仅根据这上万个纬度的数据来做决策,还能够实时监控数据的变化,对这些变化知其然,且还可知其所以然。
百度和国金证券已在大数据合作方面做了非常有意义的尝试。百度将线上和线下的数据结合在一起,通过对这些海量数据进行复杂计算,挑选出20多个有效的互联网因子,并用这些因子建立数学模型,助力选股和买卖决策。基于上述大数据的合作,国金证券金融产品的年化收益提升了5%~8%,信息比率IR提升了0.6~0.9,最大回撤降低了3%~5%。有了大数据的强大技术支持,分析师在股票与基金的选择上,实现了更大的收益,更好地控制了风险。未来百度将和国金证券进行新的尝试,共同建立一个新的量化基金。希望通过这种创新和尝试,帮助互联网金融企业找到更加可行的发展道路。
除了基金,互联网金融另一个重要领域是保险业。保险公司每降低一个百分点的风险,就意味着比竞争对手有更大的优势。百度已经与新华保险、安盛天平在大数据方面开展了合作。百度利用保险公司多年积累的线下数据,圈定了一大批低赔付人群样本,将这些人群的线上线下数据融合并进行建模,通过人工智能算法,挖掘出这些人的特征。百度在6亿网民中通过海量计算,将具有相同特征的人筛选出来,从而发现更多的低赔付人群,其准确率超过85%。百度希望在这些尝试之后,能够将这些技术进行广泛地推广。
人工智能重新定义效率
最近几年,计算机在语音、图象和自然语音的理解上取得了很大突破。由通过鼠标、键盘与计算机交互的方式,正在向通过与计算机对话、图像识别等方式改变。这些方式都在增加用户与互联网交互的频率,这将大幅度提升人机交流的效率。
人工智能目前的学习能力较弱,推理能力还无法与人脑相提并论。但在此领域,只要给予研发人员足够的时间和数据,即可使人工智能的学习和推理能力超越人类。几年前,计算机战胜国际象棋大师的例子充分说明了这一点。
目前,正是人工智能发展的良好时机。一方面,有海量数据提供模型学习,数据越多特征就越多,模型就能判断更精准;另一方面,深度学习技术也在快速地发展,类似人脑神经一样去分析解释数据的技术已日渐成熟,未来将出现类似人脑的智能。人工智能的应用基础是大数据,用户量越大所产生的数据就越多,模型就愈加优化,人工智能的智能性就越强,将更符合人类的思维习惯。例如用户在使用搜索引擎若无法获得所希望的信息时,就需自己想办法换一种搜索方法。但是通过人工智能技术,机器人已经能够记住用户上一次与机器人对话的内容,并且能够理解用户的意图,随后根据用户的提问进行交互。百度的“度秘”就是通过大数据和人工智能理解人的语言,实现多轮交互。
深度学习与大数据结合
深度学习有多层次的结构,能够从众多数据中将所需要的信息充分挖掘出来,正是深度学习与大数据的结合形成了此次人工智能潮浪的巨大推动力。
百度投入巨大的资源用于百度大脑的PADDLE深度学习平台的开发,其可以支持百度各类海量数据并能够灵活地推出各种不同的深度学习模型的结构,在网页搜索、广告排序、数据中心管理、百度杀毒等方面已得到了广泛应用。
在百度看来,机器的感知能力正在超越人类水平。在语音方面,人的识别错误率是8%,而百度能将机器的识别错误率控制在6%以内;在人脸识别方面,百度的错误率只有0.23%,低于人类识别的错误率。

图3 开放人脸识别服务
无论是人脸识别还是图像文字识别技术,百度都通过APIStore开放出来。百度端到端的机器翻译能力使得百度对机器翻译质量有了极大地提升。端到端的学习模式抛弃了人为的硬性分解和人为的特征构造,通过一个完整的模型直接进行学习。这样的模式已应用于语音识别、图像识别、机器翻译中并已取得成功。百度提出将传统人工智能中不同的分支,例如图像识别、语言理解和语言生成等紧密结合在一起,形成统一的神经元网络,让机器人像儿童学习知识一样,方便用户在未来可像教儿童学习一样地教机器人。
人工智能正在形成良性循环,更多的数据、更好的产品、更强的智能正在构建组合成一个闭环,伴随人工智能使用者不断地增多,机器将变得越来越聪明。
目前人工智还存在很多问题,主要包括:缺少小数据的学习能力,即通过少量关键数据来实现深度学习;不能通过自主探索环境来学习;缺少通过与人交流进行学习的能力。
深度学习在语音合成中的技术创新
百度在智能语音技术上的成果是LSTM声学模型,LSTM即长短时记忆网络模型也就是模拟人脑。该算法优势明显,其一是长时间的轨迹记忆和瞬态记忆的统一;其二是模拟人脑选择性遗忘;其三是更精准的轨迹建模。百度的技术创新就是混合多层结构来解决海量数据训练的效率和稳定性问题。

图4 人工智能正循环

图5 语音识别 - LSTM声学模型(长短时记忆网络模型)
每个人的说话方式各有不同,所带来的问题就是某些语句识别率不高,传统技术很难解决这个问题。百度为此推出了声学模型自适模式,为每个人推出个性化模型,将识别错误率下降到10%~15%。
百度语音开放平台可为智能手机提供语音拍照,驾驶助手,语音助手等功能;为电视厂商提供语音搜索和语音指令功能;提供领先的车载解决方案,优化车机设备的抗噪性能;为智能设备厂商提供语音技术支持;为智能手表提供语音输入和语音搜索功能。百度还将推出随机数字串声纹识别,实现用户用声音进行注册、账户登陆等功能,其错误率已降低到千分之一;个性化TTS功能可合成用户希望得到的声音;音频检索模块将提供音频内容互动平台。
(本文根据王劲在2015百度世界大会上的演讲整理而成,未经本人审阅)

图6 语音识别-声学模型自适应
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
导航定位学报(2022年2期)2022-04-11
意林·作文素材(2021年9期)2021-07-06
阅读(快乐英语高年级)(2019年5期)2019-09-10
阅读(快乐英语高年级)(2019年2期)2019-09-10
当代陕西(2019年14期)2019-08-26
小说界(2018年5期)2018-11-26
青年与社会(2018年2期)2018-01-25
小猕猴智力画刊(2017年7期)2017-08-09
中学数学杂志(初中版)(2016年5期)2016-11-01
