
基于改进DBSCAN的移动用户兴趣点提取方法
2015-02-27 00:55王忠民纪中伟
西安邮电大学学报 2015年6期
王忠民, 韩 娜, 宋 辉, 纪中伟
(1.西安邮电大学 计算机学院,陕西 西安710121;2.中兴通讯股份有限公司 终端事业部,上海 201203)
基于改进DBSCAN的移动用户兴趣点提取方法
王忠民1, 韩 娜1, 宋 辉1, 纪中伟2
(1.西安邮电大学 计算机学院,陕西 西安710121;2.中兴通讯股份有限公司 终端事业部,上海 201203)
针对移动智能手机用户历史轨迹数据的兴趣点提取问题,提出一种改进的DBSCAN聚类算法,利用采集到的经纬度数据,以及经纬度数据所对应时间的差值来确定邻域半径和最小阈值的方法,提取用户历史兴趣点。结果表明,该算法可以解决移动用户历史兴趣点的提取问题,实验证明该方法的有效性及可行性。
DBSCAN;移动轨迹;智能手机;用户位置
基于位置的服务[1]广泛支持需要动态地理信息的应用,如:信息查询(旅游景点、交通情况等)、急救服务(老年人行为监测)、车队管理、道路辅助与导航等[2]。文献[3]将DBSCAN(Density Based Spatial Clustering of Applications with Noise,DBSCAN)聚类算法应用于交通道路规划上,通过采集出租车的GPS(Global Position System,GPS)轨迹数据以及轨迹数据对应的时间,对数据进行分割,然后采用DBSCAN算法进行聚类提取出城市拥堵的区域以及拥堵的时间;文献[4]将DBSCAN算法应用于小区载频配置优化方面,通过对现网大量话务数据的统计分析,找出小区载频配置数和最佳话务量之间的关系,对载频配置进行优化。文献[5]通过减少区域查询次数及查询时间改进DBSCAN算法的时间效率,采用分治策略,将DBSCAN算法应用于网络流量HMM(隐马尔科夫模型)自动建模的问题中。文献[6]通过把数据均匀划分成分布均匀的网格,分别对每个网格单独处理来确定DBSCAN的邻域半径,提高DBSCAN聚类算法的准确率。此外,文献[7-14]从不同方面对DBSCAN算法分别进行改进,但都存在一个共同的问题,即DBSCAN算法对输入参数较敏感。
针对DBSCAN算法对输入参数敏感的问题,提出一种基于移动用户历史兴趣点的DBSCAN改进算法,通过地图定位采集的用户个人历史轨迹数据,定位方式为基站和WiFi(Wireless Fidelity)混合定位,利用采集到的经纬度数据,以及经纬度数据所对应时间的差值来确定邻域半径和最小阈值的方法,从历史数据中提取出移动用户兴趣点。
1 改进的DBSCAN算法
1.1 概念
定义1空间两点oi(xi,yi),oj(xj,yj)的距离
(1)
式(1)中xi,xj,yi,yj分别表示点oi,oj的横坐标和纵坐标。
定义2设点x,样本集Y={y1,y2,…,yi},其中yi表示样本点。则点x和样本集中点的最大距离和最小距离分别记为
maxd(x,yi), mind(x,ys),
(2)
其中,max和min分别表示距离d(x,y)中的最大值和最小值。
定义3设点集P={p1,p2,…,ps},用式(1)找出点集合P中的点pj,pj是距点pi最近的点,记作pi→pj。则合并点定义如下
①pi→pj且pj→pi,则合并为{pi,pj}
②pi→pj且pj→ps,则合并为{pi,pj,ps}
1.2 改进的DBSCAN算法
基于用户历史兴趣点的改进DBSCAN算法思想,通过连续两个不同位置点的时间差来找出可能的兴趣点,从而确定DBSCAN算法需要输入的两个参数,即邻域半径e和最小阈值Minpts,从而达到理想的聚类效果。
① 提取数据集中时间差大于5分钟的点,并进行合并。
将总数据集记为S={s1,s2,…,sn}
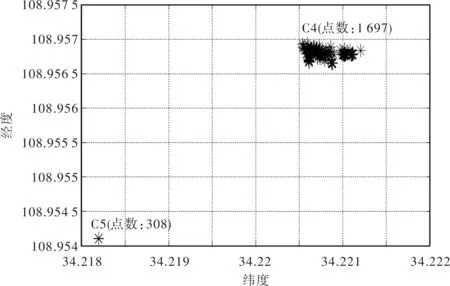
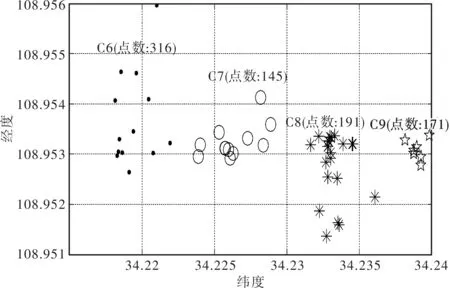
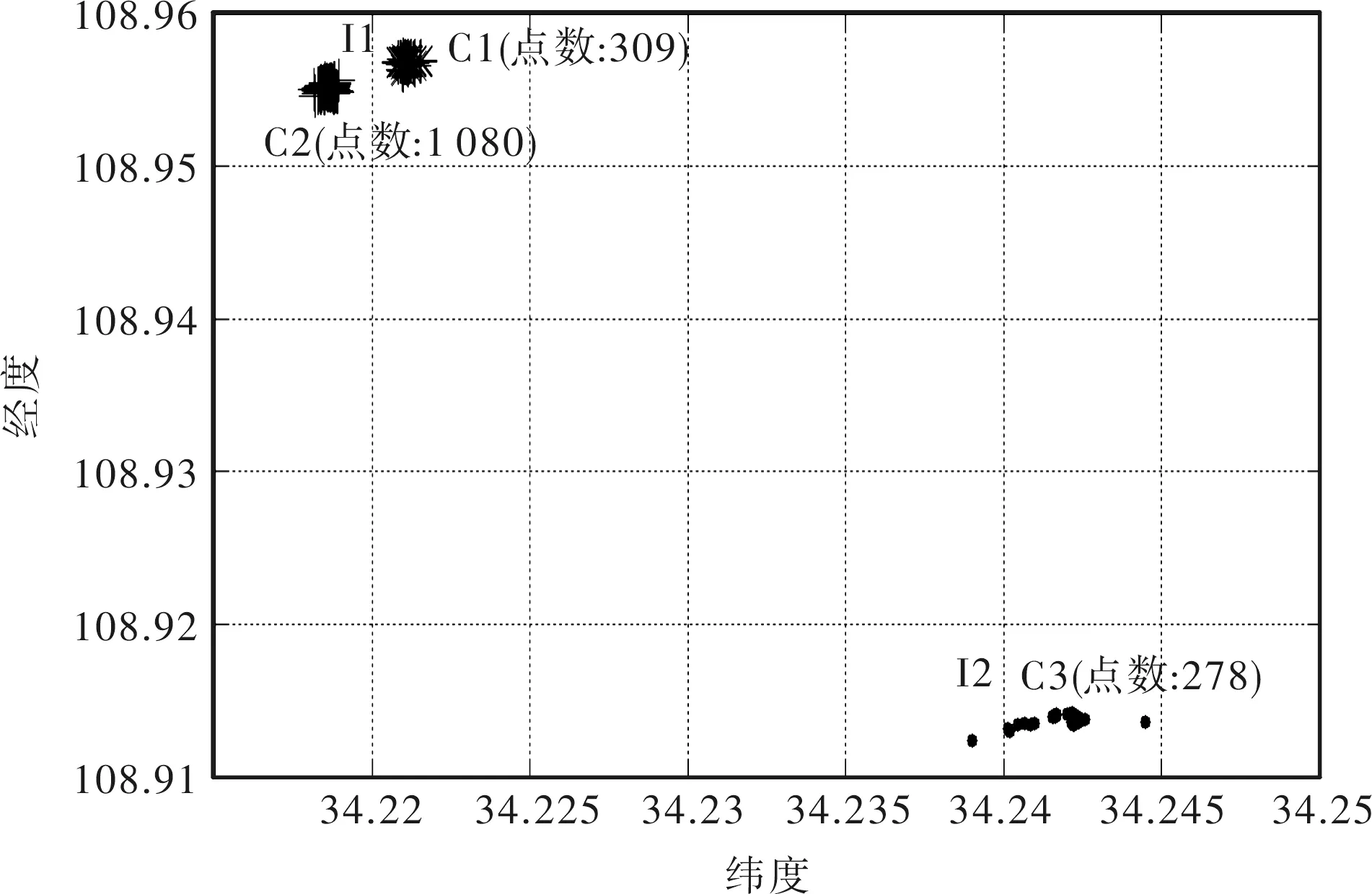
其中n为样本点数,∀si∈S,i≤n有对应的3个数据即{longitude,lantitude,currenttime},由于经纬度点代表位置点,所以简记为:∀si∈S,i≤n都有si={oi,ti}。对于相邻的两个位置点oi,oi+1之间的时间差记作Δt=ti+1-ti,将Δt≥5分钟的点oi,归于集合P,即P={o1,o2,…,os},s C={c1,…,cm},m≤s。 ② 计算各个合并数据集的均值,最大距离以及总数据集中最大距离内的点数。 ∀c∈C的均值,记为M={M(c1),…,M(cm)},其中M(cm)为合并后第m个集合的均值。根据两点间距离公式计算出M(ci)∈M,i≤m与其所对应的点集ci中各个点的距离,由定义2中最大距离可得集合 maxd(M(c),c)={maxd(M(c1),c1),…, (3) 式(3)中maxd(M(cm),cm)表示均值M(cm)与其对应的第m个点集中所有点距离中的最大值。并求得总数据集中M(ci)在其对应的maxd(M(ci),ci)距离范围内的数据量counts(i),有 counts={counts(1),…,counts(m)}, (4) 式(4)中counts(m)表示M(ci)在其对应的maxd(M(ci),ci)距离范围内的数据量。 ③ 确定邻域半径e和最小阈值Minpts的值 由此取集合(3)中最小值作为邻域半径e,式(4)中最小值作为阈值Minpts,即e=min{maxd[M(c),c]},Minpts=min(counts)作为DBSCAN的两个参数进行聚类。 虽然在上述对DBSCAN算法改进后能够确定出e与Minpts的值,但存在一个问题,即如果用户在距离较近的两个位置都呆的时间较长,那么上述改进的DBSCAN算法就不能将其分开,而是聚为一类,显然这样的聚类结果不是理想的聚类结果。针对这一问题,在第一次聚类得到的结果中,分别对每个类重新查找Δt≥2的点,按照第一次改进的DBSCAN算法计算出合并后点集的均值在所在点集的最大距离以及在最大距离内的点数。此处重新记作R和N,即为R={r1,r2,…,rm},N={N1,N2,…,Nm},其中rm表示合并后点集的均值在所在点集的最大距离,N1表示合并后点集的均值在最大距离范围内包含的点数。 取e=Rmin来作为邻域半径。对于最小阈值Minpts的估计,分为如下两种情况。 ① 如果Nmin≥100,那么取Minpts=Nmin。 ② 如果Nmin<100,这里使用Smiti Abir等人[15]提出的计算Minpts的方法,公式如下 (5) 式(5)中Nj∈N,rj∈R,j≤m,Nj表示第j个类中的点数,rj表示第j类的半径。TotalVolumej为包含所有Nj的超体体积,即 (6) 由于小范围内经纬度点之间的距离相当小,所以利用公式(5)计算Minptsj时应该对rj进行放大,直到计算后的min{Minpts1,Minpts2,…,Minptsm}≥100为止,取Minpts=min{Minpts1,Minpts2,…,Minptsm}作为最小阈值对所在类进行二次聚类。 1.3 使用改进的DBSCAN算法步骤 使用改进的DBSCAN算法的步骤描述如下: ① 初始化; ② 输入聚类数据,采用第一次改进的DBSCAN算法计算初始聚类集; ③ 根据得到的I个初始聚类集,数据集划分为I个部分; ④ 采用二次改进的DBSCAN算法分别计算出每个局部数据集的e值和Minpts值; ⑤ 分别对每个数据集进行DBSCAN聚类,得到最终的聚类结果。 2.1 数据采集 实验所使用的轨迹数据是通过智能手机所获取的连续数据,定位误差为200 m左右。用户每天的轨迹一般分为几种情况:① 小范围(住所或单位附近等距离较近的位置点);② 大范围(外出);③ 以及大范围和小范围混合(住所或单位附近等距离较近的位置点再加上相对较远的位置点)。考虑到时间及条件等因素,实验数据采集的地点范围定为1 km、3 km、6 km及以外。 2.2 实验方案设计 实验方案设计部分的数据是个人通过安卓手机采集的轨迹数据,对一次改进的DBSCAN算法和二次改进后的DBSCAN算法进行了实验对比。 为了检验算法的有效性,实验提出3种方案,分别如下: 方案1将用户的轨迹限定在1 km,1 km内的兴趣点为2个,如图1中的C4,C5; 图1 1 km的聚类结果 由图1可以看出,1 km的轨迹内停留时间较长的兴趣点为2个。 方案2采集数据的轨迹范围限定为3 km,3 km内的兴趣点为4个,分别对应图2中的C6, C7, C8, C9; 图2 3 km的聚类结果 由图2看出,3 km的轨迹范围内停留时间较长的兴趣点为4个,分别为C6,C7,C8,C9。 方案3采集数据的轨迹范围限定为6 km以及以外,6 km及以外的兴趣点为3个,如图3中的C1,C2,C3。 图3 6 km的聚类结果 由图3看出,6 km的轨迹范围内停留时间较长的兴趣点为3个,分别为C1,C2,C3。 2.3 实验结果 为了验证实验的可行性,分别让10人使用安卓手机在相同的轨迹和范围内采集数据,2.2中3种方案的轨迹每人各采集一次。对采集到的数据各采用一次改进的DBSCAN算法和二次改进的DBSCAN算法进行聚类,来提取兴趣点,实验结果如表1所示。 表1 聚类结果比较 由表1看出,对于不同的轨迹范围,使用二次改进的DBSCAN算法的聚类结果明显优于一次改进的DBSCAN算法的聚类结果。 DBSCAN算法能在具有“噪声”的数据集中发现任意形状的簇,但是存在问题即需要输入两个变量,如果变量的值选取不合理就会造成错误的聚类结果。针对这一问题提出了改进的DBSCAN算法以及二次改进后的DBSCAN算法,从用户历史轨迹数据中提取出用户兴趣点。实验表明,二次改进后的DBSCAN算法优于一次改进的DBSCAN算法。 [1] 周傲英,杨彬,金澈清,等.基于位置的服务:构架与进展[J].计算机学报,2011,34(7):1155-1171. [2] 郭瑞亮.基于移动终端的位置服务(LBS)系统的研究与实现[D].哈尔滨:哈尔滨工程大学,2012. [3] 刘畅,李治军,姜守旭.基于DBSCAN算法的城市交通拥堵区域发现[J].智能计算机与应用,2015,3(5):69-71. [4] 刘强,邓磊,贾振红,等.基于划分DBSCAN算法的小区载频配置优化[J].计算机工程与应用,2014,50(8):85-89. [5] 李双庆,慕升弟.一种改进的DBSCAN算法及其应用[J].计算机工程与应用,2014,50(8):72-76. [6] 冯少荣,肖文俊.DBSCAN聚类算法的研究与改进[J].中国矿业大学学报,2008,37(1):105-111. [7] 王兵.密度聚类算法的研究与应用[D].西安:西安电子科技大学,2012. [8] Dai Biru, Lin I Chang. Efficient Map/Reduce-based DBSCAN Algorithm with Optimized Data Partition[C]// IEEE Fifth International Conference on Cloud Computing.Taipei:IEEE Press,2012:59-66. [9] Pan Donghua, Zhao Lilei . Uncertain Data Cluster Based on DBSCAN[C]//2011 International Conference.Liaoning: ICMT,2011:3781-3784. [10]张丽杰.具有稳定饱和度的DBSCAN算法[J].计算机应用研究,2014,31(7):1972-1975. [11] Wu Qingfeng. DBSCAN:A novel clustering algorithm based on double sampling for DBSCAN[J]. Journal of Computational Information Systems, 2014,10(1):325-333. [12] Sun Peng, Han Chengde,Zeng Tao.S-DBSCAN:An algorithm for finding high density clusters based on DBSCAN[J]. Chinese High Technology Letters,2012,22(6):589-595. [13]吴明晖,张红喜,金苍宏,等.一种基于边缘密度距的聚类算法[J].计算机科学,2014,41(8):245-249. [14] Khan K,Rehman S U,Aziz K,et al.DBSCAN:Past, present and future[C]//2014 5th International Conference on the Applications of Digital Information and Web Technologies,ICAD/WT.Bangalore:ICADIWT, 2014:232-238. [15] Smiti A, Elouedi Z. DBSCAN-GM:An improved clustering method based on Gaussian Means and DBSCAN techniques[C]//INES2012.IEEE 16th International Conference on Intelligent Engineering System. Tunisia:IEEE Press,2012:573-578. [责任编辑:汪湘] An improved DBSCAN algorithm for extracting the mobile user’s interest points from the historical trajectory WANG Zhongmin1, HAN Na1, SONG Hui1, JI Zhongwei2 (1.School of Computer Science and Technology, Xi’an University of Posts and Telecommunications, Xi’an 710121,China);2. Terminal Division, ZTE, Shanghai 201203, China) In order to extract the mobile smart phone users’ historical interest points from their trajectory data, an improved DBSCAN(Density-Based Spatial Clustering of Applications with Noise) clustering algorithm is proposed in this paper. In this algorithm, the collected data of latitude and longitude, as well as the difference between the time corresponding to the latitude and longitude data are used to determine the neighborhood radius and minimum threshold. Results show that the proposed algorithm can effectively solve the problem of extracting the mobile users’ historical interest points. DBSCAN,moving trajectory,smart phone,user location 2015-09-06 国家自然科学基金资助项目(61373116);陕西省教育厅产业化培育项目(2012JC22);西安邮电大学青年教师科研基金资助项目(ZL2014-29) 王忠民(1967- ),男,博士,教授, 从事智能信息处理研究。E-mail:wzm_678@163.com 韩娜(1991- ),女,硕士研究生,研究方向为移动情景感知。E-mail:1198064502@qq.com 10.13682/j.issn.2095-6533.2015.06.022 TP393 A 2095-6533(2015)06-0102-04
maxd(M(cm),cm)},2 实验分析

3 结束语
猜你喜欢
农业工程学报(2022年7期)2022-07-09
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
吉林大学学报(理学版)(2020年3期)2020-05-29
铁道通信信号(2019年6期)2019-10-08
自动化学报(2018年7期)2018-08-20
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
雷达学报(2017年6期)2017-03-26
周口师范学院学报(2016年5期)2016-10-17
