
基于Web挖掘的电子商务推荐系统研究
2015-01-16 05:26方传霞闫仁武
电子设计工程 2015年11期
方传霞,闫仁武
(江苏科技大学 计算机科学与工程学院,江苏 镇江 212003)
电子商务的兴起正在全世界范围内迅速改变传统商业模式[1],越来越多的顾客在电子商务网站活动日益频繁。商家若是能跟踪用户在网站上的浏览轨迹并进行行为分析,让企业更清楚掌握客户的需求,有针对性的开展网上销售。
基于Web挖掘的购物个性化推荐系统可以直接与用户交互,模拟商店销售人员向用户提供商品推荐,帮助用户找到所需商品,从而顺利完成购物过程[2]。电子商务推荐系统作为网站个性化服务之一,将Web挖掘技术应用于商务网站推荐系统中,对用户属性和行为进行学习,进而从中获取知识信息并产生推荐,不仅为电子商务领域的海量数据提供一种有效的处理方式,而且为电子商务推荐系统提供更加智能化、更加自动化和更高质量的推荐结果[3]。
1 Web挖掘技术在电子商务中的应用
1.1 面向电子商务Web挖掘的数据源
电子商务网站进行Web挖掘时,数据来源类型多、数据量大、非结构化等特点。数据源主要包括:服务器日志、代理服务器端数据、Web页面数据、页面链接数据、用户注册信息等。通过对这些数据源进行Web挖掘,能够发现隐藏在数据中的模式信息,了解用户行为,进行预测性分析,从而转化为商业价值。
1.2 面向电子商务的Web挖掘技术
应用于电子商务网站的Web挖掘技术主要包括关联规则、序列模式、分类分析、聚类分析应用等。关联规则发现交易数据中不同项之间的关联,从而找出用户购买行为模式,典型的应用就是“购物篮分析”;序列模式分析是Web日志数据,发现用户访问模式,同时挖掘商品的购买顺序以及时间间隔;分类分析目的是分析输入数据,通过训练集中数据表现,建立分类模型,包括朴素贝叶斯、决策树等分类算法;聚类相似浏览行为的用户,提取具有相似兴趣度用户,执行合理市场策略等。
2 电子商务的个性化推荐系统类型
完整的推荐系统一般由三部分组成[4]:收集用户信息的行为记录模块、分析用户喜好的模型分析模块和推荐算法模块,其中核心是推荐算法模块。可以根据电子商务推荐系统采用的推荐算法不同,将其划分不同类型的个性化推荐系统。
2.1 基于协同过滤的个性化推荐系统
传统的协同过滤的电子商务个性化推荐系统只是对用户购买行为之间的相似性感兴趣,主要是挖掘目标用户和历史用户之间购买行为的相似性,根据相似性生成推荐结果集,它是第一代被提出并且得到广泛应用的个性化推荐系统。
基于协同过滤的个性化推荐系统优点是能够为用户挖掘出新感兴趣的商品,而无需对商品的特征进行任何考虑,而且任何形式的商品都可以进行推荐,例如艺术品、电影、音乐、服务等。目前协同过滤个性化推荐是应用最广泛的推荐算法,但这种方法也面临多种问题,冷启动问题、评分矩阵稀疏问题,且随着系统用户和商品数量不断增长,系统性能会变差。
2.2 基于内容的个性化推荐系统
基于内容的推荐技术主要过程是:首先收集用户爱好信息,构建和维护用户概要信息库;其次,建立清晰、完整的用户爱好模型;再对文本集内的文本进行分词、词频统计、加权等过程从而生成每一个文本的文本向量;然后,计算用户向量和文本向量之间的相关系数,将相关系数高的文本发送给该用户的模型用户;最后,根据用户的反馈信息进行修正,以提高推荐信息的效率和质量[5]。
基于内容的个性化推荐系统可以根据用户和商品配置文件进行推荐,能够处理冷启动问题;推荐新商品和未流行的商品,发现隐藏的信息,不会受到评分矩阵稀疏问题影响;通过列出推荐项目的内容特征,合理解释推荐的理由,具有良好的用户体验。该推荐系统受到信息获取技术的制约,要求信息流是机器可以分析的形式,对机器识别的要求很高,且难度较大;基于内容推荐易产生重复推荐问题,且不易发现新的信息;信息识别的局限性,对商品信息的品质、风格无法进行准确的区分。
2.3 基于网络结构的个性化推荐系统
基于网络结构的推荐算法是周涛首次提出,该算法不用考虑用户和项目的内容特征,而只是把它们作为抽象的节点,首先将目标用户选择过的每个项目产品上设定初始资源,并将初始资源平均分配给项目的邻居用户,再将该用户的平均资源分配给选择过的所有项目,最后让每个项目都获得最终资源,并将项目的最终资源按大小排序且推荐前L个给目标用户,即完成推荐[6]。
基于网络结构的推荐算法是电子商务中个性化推荐系统的一个全新的研究方向,然而同样面临冷启动问题。
2.4 混合个性化推荐系统
协同过滤、基于内容以及基于网络结构的推荐算法在实际电子商务网站应用过程中都有各自的优缺点,因而在实际的推荐系统中需要结合不同的推荐算法组成混合推荐算法,提高推荐系统的性能。常见的混合推荐算法是将基于内容的推荐与协同过滤推荐组合。
2.5 基于Web挖掘技术的个性化推荐系统
Web挖掘技术根据挖掘对象的不同可分为3类:Web内容挖掘、Web结构挖掘和Web使用挖掘。基于Web挖掘技术的个性化推荐系统是通过浏览器的方式进行商品推荐,方便用户体验,增加推荐可信度。将Web挖掘技术与电子商务的个性化推荐系统结合,生成完全自动化的推荐,让用户体验完全个性化的购物体验,是电子商务推荐系统发展的必然趋势。
3 基于Web挖掘技术在电子商务的个性化推荐系统研究
3.1 传统的电子商务推荐系统应用模型
集成Web挖掘的电子商务应用推荐系统模型如图1[7]所示。

图1 传统的电子商务推荐系统模型Fig.1 Traditional model of e-commerce recommendation system
基于Web挖掘的电子商务系统模型中,主要是由业务数据、用户与站点互动所产生的数据、数据仓库、数据分析组成。业务数据是描述产品实体的数据信息,包含产品或服务的详细信息。
第二个要素是用户活动信息数据,包括用户的选择,访问方式,用户偏好,产品或朋友转发,特定页面或链接的点击率,用户的特性等详细信息。将所有收集到的信息存储到数据库或数据仓库;同时需要收集商品的评分页面数据,将这些数据作为分析引擎的一个输入,挖掘出用户可能喜欢的其他物品数据集,提交数据集给分析引擎,从而分析用户的行为。数据分析模块主要负责数据分析、决策支持等。在SQL Server中,包含两种数据挖掘算法:Microsoft决策树和Microsoft聚集,且能够与MS-Excel结合提供高效的数据挖掘方案。同样Oracle数据库也提供数据挖掘方案。整个分析的结果信息返回给用户,包括产品成交次数、产品服务的知名度,用户最佳选择等。
3.2 改进的电子商务推荐系统模块研究
现阶段电子商务个性化推荐系统对实时性能要求高,可以将推荐系统模块分为在线和离线两部分[8],系统基本的结构如图2所示。
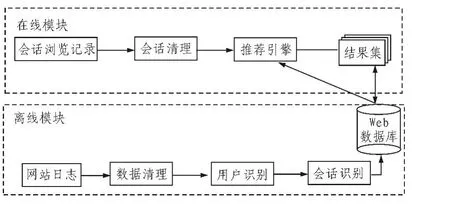
图2 改进的推荐系统模型Fig.2 Improved model of recommender system
1)离线模块
主要工作是生成各种页面和用户的聚类结果,生成关联分析的频繁项集,由数据预处理和Web数据挖掘组成。离线挖掘的结果集直接为在线模块提供支持。数据预处理和Web挖掘耗时较长,无法满足商务系统的实时性要求,故而将其放在离线部分。
2)在线模块
在线模块主要是动态实时地实现推荐引擎的过程,并且将推荐引擎产生的频繁项集添加到离线模块中。结合离线模块,提高个性化推荐的实时响应速度和伸缩能力,以及保证推荐系统提供给用户最优质的推荐服务。
3.3 构建多模块推荐个性化模型研究
在电子商务网站的实际应用中,不同的情形下,用户所需的推荐服务是不同的。注册用户登录网站首页时,需要推荐模块根据用户历史记录等,推荐用户感兴趣的热门商品或者广告信息;在很多电子商务网站中,交易完成后,用户可以对商品的质量、卖家服务、物流速度等满意度进行评价,当用户提交商品评价信息时,调用协同过滤推荐,更新“用户和项目评分”矩阵;用户在浏览商品或者站点搜索自己想要的商品,启用关联推荐模块进行推荐,且能够进行交叉销售。电子商务个性化推荐系统中,需要集成多种推荐模块类型来满足不同的应用需求,为用户提供更高质量的推荐服务,图3为多模块系统框架流程所示。

图3 多模块推荐系统框架Fig.3 Multi-module frame of recommender system
3.4 基于隐私保护的Web挖掘个性化推荐研究
Web挖掘的目标是从数据集中提取准确的信息满足商业的需要,也就决定着这个过程与客户密切相关,使得Web用户与管理者就数据隐私问题发生分歧。国外的立法和监管机构为保护用户隐私问题做出了很多努力,同样很多研究学者也在研究新的技术去实现保护用户隐私。W3C已开启了“隐私首选平台(Platform for Privacy Preferences,P3P)”项目,提出协议来解决Web用户与站点管理者的争端。
为保护用户隐私数据,基于隐私保护的Web挖掘可分为两个途径:随机扰乱方法和安全多方计算方法。随机扰乱适用于对单个数据记录和密集型数据集合进行随机变换;安全多方计算分为安全和计算方法、安全并集求法、安全计算交集大小方法和安全数量积计算方法。在Web挖掘的电子商务个性化中,添加隐私保护模块的是为了防止用户机密信息外泄,同时要求基于属性的统计保持不变,不会影响Web挖掘结果。Agrawal Srikant提出一种建立决策树分类实施对源数据中隐私信息进行扰动[9];Evfimievski etal提出一种交换数据的方式进行关联规则分析以达到保护隐私的目的。基于隐私保护的数据挖掘流程如图4所示。

图4 隐私保护的数据挖掘基本流程Fig.4 Basic flow of privacy protection based on web mining
如今,数据集基本上都是分布于不同的环境和不同地理位置,挖掘这样数据集,必须使用基于分布式的Web数据挖掘算法获得有效数据。在分布式数据挖掘中,处于不同地理位置的隐私数据更易被泄露。即使在某一环境中删除或者干扰敏感信息,利用这些不全面的数据信息与用户相关的其他数据库链接就有可能获取用户的敏感信息,即当分布式数据合并使用。电子商务网站中用户信息涉及到详细住址、电话号码、邮箱、银行卡信息等隐私数据,如何在电子商务平台进行基于隐私保护的Web挖掘成为热点问题。
3.5 注册用户与非注册用户推荐策略
Web用户分为注册用户和非注册用户,其相关推荐策略也有所不同:
1)对非注册用户分析是Web使用挖掘技术的一个难点。比如未注册的用户,浏览站点的页面统计信息、驻留时间;是否有后续访问行为;是否最终转换为注册用户。未注册用户缺乏唯一标示,可以根据IP地址前三位加上浏览器信息来大致定位未注册用户,经实验可以精确定位80%以上的用户[10]。采用协同过滤,将非注册用户聚类,选取权值较高的物品,推荐给用户。
2)注册用户则根据用户当前状态以及历史记录向用户做推荐。首先对用户的访问日志进行分析,从而得到用户当前访问的事务序列,取出当前访问事务中后N项与各个聚类中心进行比较并求出它与每个中心的相似度,最后将相似度值最小的类确定为该用户所属的类。由推荐引擎结合前面挖掘的结果集与当前用户的历史访问记录进行匹配,并根据计算结果对页面进行排序,预测用户将要访问的页面,最后将预测的结果页面的链接推荐给用户。
4 结束语
电子商务网站是交流和推广企业形象的一个关键渠道,本文介绍在电子商务典型Web挖掘技应用,电子商务个性化推荐系统类型以及传统的电子商务推荐系统模型和改进推荐系统模型,建立多模块的挖掘系统以及将数据隐私保护加入到基于Web挖掘的电子商务推荐系统中,针对注册用户和非注册用户采用不同的推荐策略。在电子商务和Web挖掘技术迅速发展的今天,将Web挖掘技术与电子商务网站更有效的融合,提高更高效的Web挖掘模型,将是未来电子商务发展的一个重要方向。
[1]毛国君.数据挖掘原理与算法[M].北京:清华大学出版社,2005.
[2]程宏水.网络数据挖掘在电子商务网站设计的应用[J].中山大学研究生学刊,2007,28(1):107-114.CHEN Hong-shui.Study on the design of e-commerce website based on web data mining[J].Sun Yat-sen Graduate Studies Journal,2007, 28(1):107-114.
[3]鲜学丰,杨元峰.一种基于Web数据挖掘的电子商务推荐系统[J].电脑知识与技术,2007(16):1046-1047,1058.XIAN Xue-feng,YANG Yuan-feng.An e-commerce recommendation system based on web data mining[J].Computer knowledge and technology,2007(16):1046-1047,1058.
[4]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.LIU Jian-guo,ZHOU Tao,WANG Bing-hong.Research progress of personalized recommendation system[J].Progress in Natural Science,2009,19(1):1-15.
[5]黄文荣,周长征.基于内容和协作的推荐系统的研究[J].计算机时代,2009(2):5-7,10.HUANG Wen-rong,ZHOU Chang-zheng.Reasearh of recommender system based on content and collaboration[J].Computer era,2009(2):5-7,10.
[6]Zhou T,RenJ,MedoM,et al.Bipartite network projection and personal recommendation[J].Phys Rev E, 2007,76(4):1-7.
[7]Siddiqui A T,Aljahdali S.Web mining techniques in ecommerce applications[J].International Journal of Computer Applications, 2013, 69(8):39-43.
[8]程德理,张新玲,黄立平.基于数据挖掘的个性化电子商务模型设计[J].情报杂志,2006,25(8):8-10.CHENG De-li,ZHANG Xin-ling,HUANG Li-ping.Design of personalization e-commerce model based on data mining[J].Journal of Infomation,2006,25(8):8-10.
[9]Rakesh Agrawal,Ramakrishnan Srikant.Privacy-preserving data mining[R].IBM Almaden Research Center,2006.
[10]张喆.电子商务公司Web数据挖掘研究[D].北京:北京交通大学,2011.
猜你喜欢
今日农业(2021年21期)2022-01-12
大众投资指南(2021年35期)2021-02-16
文苑(2020年4期)2020-05-30
知识经济·中国直销(2018年10期)2018-11-06
新闻传播(2018年12期)2018-09-19
电力与能源(2017年6期)2017-05-14
汽车与新动力(2016年6期)2017-01-04
公民与法治(2016年12期)2016-05-17
现代商贸工业(2016年35期)2016-04-09
信息通信技术(2015年6期)2015-12-26
