
基于AST 的程序代码相似性度量研究
2015-01-12 02:45:22孙琳琳杨友星
吉林大学学报(信息科学版) 2015年1期
朱 波,郑 虹,孙琳琳,杨友星
(长春工业大学计算机科学与工程学院,长春130012)
0 引言
随着计算机网络技术的飞速发展,信息资源在方便快捷获取的同时,资源的抄袭现象愈加普遍。其中,在计算机程序设计类课程中,学生间的抄袭情况极为严重。澳大利亚蒙纳什(Monash)大学对其学生中的代码抄袭现象进行调查统计显示:高达85.4%的学生承认抄袭过他人的作业[1,2]。另外,在软件商业领域,不同软件企业因为软件产品相似所引发的产权纠纷也越来越多。为扼制不良抄袭学风,加强对知识产权的保护力度,对程序代码相似性度量的研究显得日趋重要。
笔者在研究国内外程序代码抄袭检测的基础上,针对Java程序中常见的抄袭手段,提出一种基于AST的检测Java程序代码抄袭的方法。首先对程序代码进行预处理,减少冗余信息;然后对预处理后的代码进行遍历生成AST;最后通过采用自适应阈值选取方式,对AST进行相似度计算,判定是否抄袭,最终生成相似度检测报告。
1 相关定义
1.1 相似度定义
Yamamoto等[3]给出了两个软件系统的相似度的定义。对于两个软件P和X,软件P是由元素P1,P2,…,Pm组成,P 的集合构成表示为{P1,P2,…,Pm}。同样,软件 X 由元素 X1,X2,…,Xn组成,其元素的集合表示为{X1,X2,…,Xn}。其中P,X中的元素可以表示软件P和X中的文件或代码行。
假设能求出Pi与Xj(1≤i≤m且1≤j≤n)间的匹配,用集合Rs表示所有的匹配对(Pi,Xj),其中Rs⊆P×X,则P和X的相似性定义为
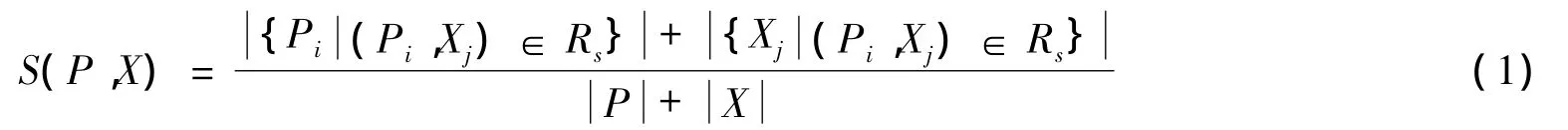
根据式(1)可看出,相似性S为一个比值,由Rs中元素的个数比上P和X中元素的个数和所得。如果Rs较小,相应的S也较小。当Rs=Ø时,S=0;当P和X完全相等时,S=1,则说明软件P和X存在抄袭现象。
目前对于相似度没有统一的定义,而程序代码的相似度与上述的软件系统的相似度相同,所以可将相似度定义为定量比较两个程序源代码之间的相关性,其结果一般用某个数值表示。
1.2 程序代码相似性度量方法
现在常用的程序源代码相似性度量方法主要有4种[4]:空间向量法、Token序列法、抽象语法树法以及程序依赖图方法。
1)空间向量法。空间向量法是将存在于程序中的操作符、操作数等作为程序的特征,把程序及其结构以特征向量的形式表征,再通过度量任意2个向量之间的距离衡量程序之间的相似程度。
2)Token序列法[5]。Token序列法是将输入的源代码经过词汇分析器分析,在一定规则的约束下将源代码转换成Token序列,然后利用匹配算法(LCS:Longest Common Subsequence)度量程序间的相似程度。这样做可以检测出具有不同句法但却有相似功能的代码段,往往会隐藏程序的组织结构。
3)抽象语法树法。抽象语法树(AST:Abstract Syntax Tree)是程序编译阶段的一种中间表示形式,可以比较直观地表示出程序代码的语法结构,并含有程序代码结构显示所需的全部静态信息。其通过比较子树与其他子树之间的相似程度对程序的相似性进行度量。该方法体现了程序的语义结构,具有较高的相似性度量效果。
4)程序依赖图法。程序依赖图(PDG:Program Dependence Graph)可表示程序内部数据以及控制依赖关系,能在语义级别上对程序代码进行分析,但该方法在程序依赖图构造和比较过程中时间开销较大。
2 基于抽象语法树的相似性度量
基于抽象语法树的相似性度量方法分为代码预处理、构造抽象语法树、相似度计算和阈值分析生成检测报告。如图1所示,先将代码进行预处理,消除冗余信息,以便提高效率;再进行词法语法分析生成抽象语法树;最后通过抽象语法树遍历生成的属性、方法等语义标记序列进行相似度计算,与自适应阈值对比分析,生成最终的检测报告。
2.1 代码预处理
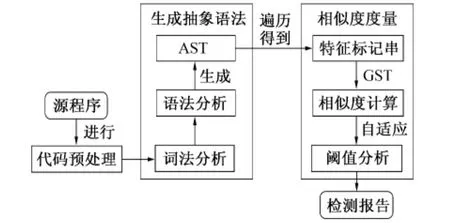
图1 相似度度量流程图Fig.1 Similarity measure flow chart
为加快系统的运行速度,减少生成抽象语法树时的冗余信息,提交源程序后,必须过滤一些存在于源代码之中的对相似度检测没有影响的信息,如空格、注释等。笔者以Java程序为例,说明对源程序代码的预处理,主要有以下几方面:
1)去掉程序中所有在符号“//”之后、“/* */”和“/** */”之间的程序注释内容;
2)将程序开始部分所有以“import”开头的引包代码删除;
3)过滤掉程序中存在的空行;
4)删除每行程序代码中的第1个非空字符之前的所有空格和“Tab”键;
5)保留运算符等描述程序代码的逻辑功能的代码部分;
6)在保证语义的情况下,对能等价替换的语句进行统一化处理,如将i=i+1,i++,++j统一替换为一种形式;
7)对Java程序中的主函数框架部分统一使用“main{}”进行替换;
8)在不改变程序语义的情况下,将输出语句“System.out.print();”和“System.out.print-ln();”等价变换为“out(输出内容)”。
2.2 生成抽象语法树
将完成代码预处理的程序转换成与之对应的抽象语法树,从而在语义的基础上为相似性度量提供一个高效规范的数学模型。创建抽象语法树的规则设定为从叶子节点开始创建,先创建父节点后创建子节点,再将它们关联起来。创建AST算法描述如下。
1)解析空的代码创建一个空的AST:
①定义语言规范;②设置字符的编码方式;③设置编译单元节点;④得到空的AST。
2)创建类,把类节点作为编译单元的子节点:
①创建类节点;②添加类名;③添加类可见性;④将类节点连接为编译单元的子节点。
3)创建函数方法,并作为类节点classDec的子节点:
①添加方法名;②添加方法可见性;③添加方法体;④将方法节点连接为类节点的子节点。
4)创建方法体中的方法语句,并以此作为类节点methodDec的子节点:
①对方法体中的语句进行分析,设置节点;②根据循环语句、条件语句等分类设置节点。
在生成抽象语法树后,可以从待检测程序的抽象语法树中将源程序的属性、方法等语义信息遍历取出,以便为后续的相似性度量提供语义支持。
将生成的抽象语法树的属性、方法取出,放入Block数组中。获取源程序中的属性集合,并将其放入attribute_array[]数组中;获取源程序中的方法集合,将其放入method_array[]数组中。
对待问题“求解2 000以内的质数”,其源程序Test01.java和抄袭程序Test04.java(重新排版程序顺序格式)的抽象语法树遍历后存储信息提取对比分析结果如图2和图3所示。

图2 Test01的AST信息遍历Fig.2 Test01 AST information traversal
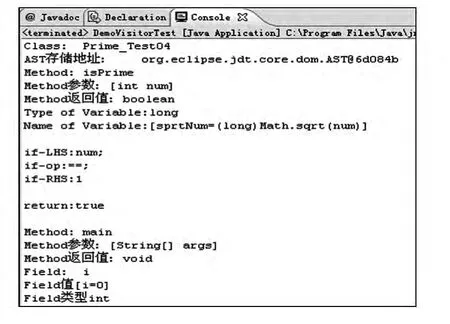
图3 Test04的AST信息遍历Fig.3 Test04 AST information traversal
由图2和图3可以看到,源程序和抄袭程序生成抽象语法树后其程序的结构及语义信息。将其转换成字符串序列后可进行相似性计算。
为清晰地进行数据存储和更新,可将源程序的语义信息存储到表中,方便后续使用。具体实现步骤如下。
1)将数据存储表(DST:Data Store Table)定义为一个三元关系D=(Class,Field,Method),其中Class表示类名、Field表示属性名、Method表示使用该变量的方法名。
2)将函数信息表(MIT:Method Information Table)定义为一个四元关系M=(Class,Method,Method_call,Method_para),其中Method表示方法名、Method_call表示被调用的方法、Method_para表示函数的参数信息。
3)将类名和方法名作为主键,在获取程序语义信息时向表中填入数据。
2.3 相似性度量
将需要检测的源程序的语义信息存储后即可将属性、方法等结构语义信息遍历取出,利用JDT(Java Development Tooling)平台并调用ASTParser类形成序列代码,再通过贪婪字符串匹配算法(GST:Greedy String Tiling)[6,7]计算提交的源程序之间的相似性度量问题。该算法的伪代码如下。

GST算法可以尽可能找出两个子串中的匹配,对属性方法形成的子串中可能存在的最大匹配进行检测,进而为相似性度量提供支持。
GST算法运行结束后,会得到最大匹配集合tiles,通过该集合可以进行源程序与抄袭程序的相似度计算。将所有匹配序列的长度和记为SSum,源程序P和抄袭程序T可通过公式

进行程序间的相似性度量检测。其中Pl和Tl分别为源程序和抄袭程序的AST序列代码长度。
2.4 阈值的选择
笔者在进行相似性度量时,先根据多种抄袭手段修改源程序,得到若干个修改后的抄袭程序。再将源程序与抄袭程序进行相似性度量,每次相似性度量结果用相似度Ssim表示。而在程序代码抄袭检测过程中,仅依靠单次检测相似度的高低进行抄袭判定是不恰当的,只有当相似度的值超过某个设定的阈值时,才能判定为抄袭。
笔者采用自适应阈值法,根据源程序、检测次数等因素的不同自动调节每次检测的阈值,避免了经验化设置阈值的弊端。设进行n次相似度检测的阈值为Sthreshold,其计算如下

其中Smax为n次检测中得到的相似度最大值,Smin为n次检测中得到的相似度最小值。
3 实验分析
3.1 实验数据
对问题“求解2 000以内的质数”,选取一个含有13个Java语言程序代码的测试集,其中Test01为Java源程序。将Test01与其他12个Java程序(Test02…Tset13)构成12对测试对进行相似性度量检测。
其中12对测试程序分别对应12种抄袭手段[8]:1)程序完整拷贝;2)修改程序注释;3)重新排版程序格式;4)重命名标识符;5)重排序代码块;6)代码块内语句重排序;7)常量替换;8)修改表达式中的操作符或操作数顺序;9)改变数据类型;10)增加冗余的语句或变量;11)表达式拆分;12)替换控制结构为等价的控制结构。
3.2 实验结果与分析
实验对比系统使用Moss系统[9],该系统采用串匹配算法(Winnowing算法[10,11])通过将处理字符串放入哈希表再从表中选取一个子集进行比较,以此进行相似性度量。对12对程序进行相似性度量得到的相似度结果及相同度量程序下Moss系统的检测结果如表1所示。

表1 相似度检测结果Tab.1 Similarity detection results
通过相似度检测结果得到的实验系统与Moss检测系统的结果对比分析图如图4所示。

图4 相似度对比分析图Fig.4 Similarity comparison analysis chart
根据式(3)计算本次测试集的阈值Sthreshold=0.75,若相似度Ssim大于Sthreshold,则判定为抄袭。通过实验结果对比分析可以看出,笔者设计的基于AST的相似性度量方法对不同的抄袭手段有较好的检测效果。特别是对程序完整拷贝、标识符的重命名、代码块语句顺序的重排序以及表达式的拆分度量检测方面有较为显著的效果。但对度量增加冗余代码等抄袭手段仍然有一定的误差。主要是因为增加冗余代码容易使生成的AST序列长度与源程序有较大的变化,产生误差。
4 结语
笔者提出一种利用AST检测Java程序代码的相似性度量方法,在语义的层次上达到了度量检测的目的。实验分析和测试表明,该方法能较好地检测多种抄袭手段,相比Moss抄袭检测系统也具有较高的检测效率,达到了预期的效果。但在增加冗余代码等方面,用该方法进行度量时还有一些不足之处,相似度有一定程度的降低。
今后将进一步研究以弥补不足之处,如:通过格式化源码进一步去除冗余信息;扩大测试集,增强实验说服力;完善成为可进行多种语言代码的抄袭检测系统,从而提高实验系统的扩展性和适应性。
[1]SHEARD J,DICK M,MARKHAM S,et al.Cheating and Plagiarism:Perceptions and Practices of First Year IT Students[C]∥Proccedings of the 7th Annual SIGCSE Conference on Innovation and Technology in ComputerScience Education.New York:ACM Press,2002:183-187.
[2]GEORGINA C,MIKE J.Source-Code Plagiarism:A UK Academic Perspective [R].Warks:Department of Computer Science,University of Warwick,2006.
[3]YAMAMOTO T,MATSUSHITA M.Measuring Similarity of Large Software Systems Based on Source Code Correspondence[D].Osaka:Division of Software Science,Graduate School of Engineering Science,Osaka University,2002:4-5.
[4]熊浩,晏海华,郭涛,等.代码相似性检测技术:研究综述[J].计算机科学与技术,2010,37(8):9-14.XIONG Hao,YAN Haihua,GUO Tao,et al.Code Similarity Detection:A Survey [J].Computer Science,2010,37(8):9-14.
[5]刘云龙.基于Token的结构化匹配同源性检测技术研究[J].计算机应用研究,2014,31(6):1841-1845.LIU Yunlong.Token-Based Structured Code Matching Homology Detection Technology [J].Application Research of Computers,2014,31(6):1841-1845.
[6]MICHAEL J WISE.String Similarity via Greedy String Tiling and Running Karp-Rabin Matching[D].Sydney:Department of Computer Science,University of Sydney,1993.
[7]MICHAEL J WISE.Neweyes:A System for Comparing Biological Sequences Using the Running Karp-Rabin Greedy String Tiling Algorithm[C]∥Third International Conference on Intelligent Systems for Molecular Biology.Cambridge,England:[s.n.],2006:393-401.
[8]赵长海,晏海华,金茂忠.基于编译优化和反汇编的程序相似性检测方法[J].北京航空航天大学学报,2008,34(6):711-715.ZHAO Changhai,YAN Haihua,JIN Maozhong.An Approach Based on Compiling Optimization and Disassembling to Detect Program Similarity[J].Joumal of Beijing University of Aeronautics and Astronautics,2008,34(6):711-715.
[9]AIKEN A MOSS:A System for Detecting Software Plagiarism [EB/OL].(2009-02-01). [2012-10-08].http:∥theory.stanford.edu/~aiken/moss/.
[10]SAUL SCHLEIMER,DANIEL S WILKERSON,ALEX AIKEN.Winnowing:Local Algorithms for Documemt Fingerprinting[C]∥ACM SIGMOD 2003.San Diego:ACM Press,2003:204-212.
[11]李香云,葛华.Winnowing算法在作业剽窃检测中的应用[J].安徽科技学院学报,2013,27(4):42-45.LI Xiangyun,GE Hua.Application of the Winnowing Algorithm in Assignment Plagiarism Detection [J].Journal of Anhui Science and Technology University,2013,27(4):42-45.
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学物理学报(2022年5期)2022-10-09 08:56:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
河北画报(2020年8期)2020-10-27 02:54:20
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
电子技术与软件工程(2017年24期)2018-01-17 09:32:09
软件工程(2016年11期)2017-01-17 16:56:57
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
俄罗斯问题研究(2013年1期)2013-03-11 15:44:01
