
一种面向多核系统的Linux任务调度算法
2015-01-06 08:20顾乃杰任开新吴志强
计算机工程 2015年2期
曹 越,顾乃杰,任开新,张 旭,吴志强
(中国科学技术大学a.计算机科学与技术学院;b.安徽省计算与通信软件重点实验室;c.先进技术研究院,合肥230027)
一种面向多核系统的Linux任务调度算法
曹 越a,b,c,顾乃杰a,b,c,任开新a,b,c,张 旭a,b,c,吴志强a,b,c
(中国科学技术大学a.计算机科学与技术学院;b.安徽省计算与通信软件重点实验室;c.先进技术研究院,合肥230027)
针对Linux任务调度算法在多核系统中交互性能差的问题,提出一种分组任务调度算法GFS。根据多核系统硬件特性,自动配置物理距离近的一组CPU共享一个任务运行队列,通过平衡组内CPU对任务运行队列的访问竞争与任务迁移的代价,实现组间任务运行队列的负载均衡,减少调度延迟。通过优先调度唤醒任务,加快多核系统中交互任务的响应速度。测试结果表明,在不同任务负载下,GFS能够明显降低交互任务的平均响应时间,从而有效提高多核系统交互应用的调度性能。
多核系统;调度算法;交互性能;自动配置;唤醒任务;负载均衡
1 概述
Linux操作系统由于具有良好的稳定性和安全性,在超级计算机、PC、嵌入式系统等领域都有广泛应用,但是不同系统的调度目标不同[1],如超级计算机主要考虑优化任务的吞吐量,PC主要考虑减少任务响应时间,Linux的目标是支持所有应用场景,使得其调度算法很难完全满足所有系统的需求。
目前,多核技术在交互性能要求高的场景,如即时通信(Instant Messaging,IM)服务器、Web服务器上的应用越来越多。交互任务需要和用户进行交互,经常等待用户输入而处于睡眠状态,一旦唤醒应该尽快执行,获取用户输入并交互,否则影响用户体验。对于这类任务,调度目标是减少任务响应时间[2],而Linux在设计上侧重考虑超级计算机,其调度算法CFS(Completely Fair Schedule)偏向于提高任务的吞吐量,导致算法对多核系统的交互任务调度效率不高[3]。
针对多核系统的交互任务调度问题,目前有较多研究。文献[4]提出一种基于缓存竞争优化的调度算法,利用性能监测单元刻画任务的缓存竞争强弱,通过轮询优化任务调度顺序,避免在同一个CPU上同时运行多个缓存竞争力强的任务,从而提高调度效率,但是该算法需要计算任务的缓存竞争特性并进行任务重分配,带来了额外的调度开销。文献[5]提出一种全局调度算法BFS(Brain Fuck Schedule),所有CPU共享一个任务运行队列,不需要负载均衡操作,任务可以在所有CPU上运行,算法可以减少交互任务的响应时间,但是可扩展性较差,在系统CPU数或任务数比较多时由于队列访问竞争代价增大,导致调度效率明显下降。本文提出一种分组任务调度算法GFS(Group Fair Schedule),自动配置亲缘关系近的一组CPU共享一个任务运行队列,任务在组内CPU间迁移代价较小,在系统负载严重不均衡时可以进行组间任务迁移以提高调度效率,并通过优先调度唤醒任务,减少交互任务的响应时间。
2 相关知识
2.1 Linux调度器
Linux调度器主要有2种核心操作:周期调度函数scheduler_tick和主调度函数schedule[6]。前者在时钟中断处理中被调用,负责定期更新调度相关的统计信息。后者在任务睡眠、终止或者从中断、异常及系统调用返回时被调用,完成实际的任务调度。
2.2 CFS任务调度算法
自Linux2.6.23内核发布以来,Linux采用CFS作为任务调度算法[7]。算法基本思想是在真实硬件上模拟理想的多任务处理器,使所有任务尽可能公平获得CPU[8]。
为实现这种思想,CFS引入虚拟运行时间来表示任务在CPU上的执行时间。为使每个任务获得相近的执行时间,调度器每次选取虚拟运行时间最小的任务进入运行。运行时,高优先级任务虚拟运行时间增长速度比低优先级任务慢,从而获得更多的调度机会。每个CPU维持一个以红黑树为数据结构的任务运行队列,红黑树的节点名称为任务名称,键值为任务虚拟运行时间,如图1所示。

图1 CFS任务运行队列架构
由于任务运行队列以红黑树作为数据结构,队列中虚拟运行时间最小的任务为红黑树最左侧的任务。
任务新建时,任务虚拟运行时间为红黑树最左侧任务的虚拟运行时间加上与队列负载有关的一个经验值;任务唤醒时,虚拟运行时间调整为红黑树最左侧任务的虚拟运行时间减去与睡眠时间有关的一个经验值。将新任务插入红黑树并更新队列负载,如果CPU没有运行任务,或者当前运行任务虚拟运行时间比新任务大,则置位CPU调度标志,下次中断或者系统调用返回时检测到调度标志置位会调用schedule函数完成调度。
CFS调度器核心操作的主要流程如下:
(1)scheduler_tick函数计算运行任务的虚拟运行时间,根据队列负载信息计算运行任务允许的虚拟运行时间,如果虚拟运行时间超出允许值,则置位CPU调度标志,在时钟中断返回重新调度[9]。如果任务运行队列间负载严重失衡,则进行任务迁移使负载均衡。
(2)schedule函数清理调度标志,计算运行任务的虚拟运行时间,插入红黑树中,再选取红黑树最左侧的任务,切换上下文执行新任务。
假设系统中有M个CPU、N个任务。任务新建、插入、删除和调度时间复杂度为O(lg(N/M)),各类操作效率均较高。但是CFS需要频繁判断执行负载均衡,任务迁移时会进行任务运行队列加解锁, Cache和内存刷新等操作导致性能下降。此外,任务插入CPU对应的任务运行队列后,除非发生负载均衡,否则只能在该CPU上执行,唤醒任务不能转移到其他满足调度条件的CPU上执行,影响了交互任务响应时间。
2.3 BFS任务调度算法
BFS是Android操作系统采用的任务调度算法。BFS为每个任务分配一个时间片和虚拟最后期限,调度器每次选取虚拟最后期限最小的任务进入运行。所有的CPU共享一个全局的双链表式的任务运行队列,如图2所示。
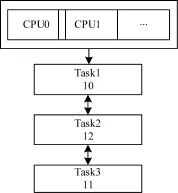
图2 BFS任务运行队列架构
任务的虚拟最后期限计算公式为:
vdeadline=jiffies+prio_ratio×rr_interval
其中,jiffies是当前时钟时间;rr_interval为任务时间片长度,固定为6 ms;prio_ratio是与任务优先级有关的参数,优先级越高对应的prio_ratio值越小。
当新建任务时,根据上述公式计算任务虚拟最后期限;任务唤醒时,保持睡眠前的虚拟最后期限不变。将新任务插入双链表末尾,检查所有CPU,如果存在空闲的CPU,或者存在运行任务虚拟最后期限大于新任务的CPU,则置位该CPU的调度标志并发送处理器间中断引发重新调度。
BFS调度器核心操作的主要流程如下:
(1)scheduler_tick函数计算当前运行任务的运行时间,如果任务用完自己的时间片,则置位调度标志。
(2)schedule函数清理调度标志,将运行任务插入双链表末尾,如果运行任务已经用完时间片,重新装填任务的时间片,根据公式重新计算虚拟最后期限。扫描整个双链表,选取可在CPU上运行并且具有最小虚拟最后期限的任务,切换上下文执行新任务。
假设系统中有M个CPU、N个任务。任务插入和删除时间复杂度为O(1),新建和唤醒时间复杂度为O(M),调度时间复杂度为O(N)。任务唤醒时,如果有满足调度条件的CPU,通知该CPU重新调度,减少了交互任务的响应时间,所有CPU共享任务运行队列因此不需要负载均衡。不足之处是当系统中CPU数目较多时队列竞争访问延时比较大,任务数目较多时调度效率很低。此外,CPU间亲缘关系比较远,例如在不同的NUMA节点上时,任务在CPU间迁移导致Cache或内存刷新的代价可能超过在原CPU上等待调度的代价,影响调度性能。
3 GFS算法设计
为解决BFS随系统CPU和任务数目增多响应时间增加较快的问题,本文提出GFS算法。算法沿用BFS虚拟最后期限和时间片的设计和计算方法,并支持自动配置一组CPU共享一个任务运行队列。通过对任务运行队列的分组配置,综合考虑队列访问竞争、任务迁移和负载均衡代价,更好地适应实际硬件和负载的需求。
GFS依照CPU之间的亲缘关系进行分组配置。一般多核系统CPU之间的亲缘关系由远及近有以下4种:
(1)不同NUMA节点,它们有独立的内存。
(2)同一NUMA节点上的不同处理器,它们共享内存,但是有独立的Cache。
(3)同一处理器上的不同核,它们共享L2 Cache,但是有独立的L1Cache。
(4)同一核上的不同超线程,它们共享L1 Cache。
不同的存储器访问时间不同:内存访存时间为50 ns~100 ns,L2 Cache访存时间为3 ns~10 ns,L1 Cache访存时间约为1ns[10],将亲缘关系近的CPU配置到一个分组,任务在组内CPU间迁移运行导致CPU间存储刷新代价较小。GFS为每个分组分配一棵红黑树作为主任务运行队列,为每个CPU分配一个顺序双链表作为存储可调度唤醒任务的高级任务运行队列,如图3所示。
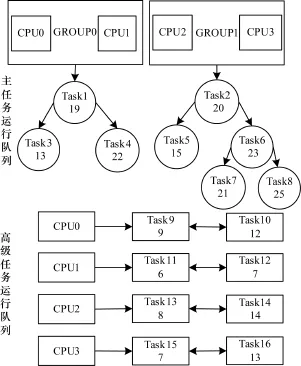
图3 GFS任务运行队列架构
当新建任务时,根据公式计算虚拟最后期限。将新任务插入CPU所在分组的红黑树中,检查本分组内所有CPU,如果存在空闲的CPU,或者运行任务虚拟最后期限大于新任务的CPU,则置位该CPU的调度标志并发送处理器间中断引发重新调度。
任务唤醒时,保持睡眠前虚拟最后期限不变。检查本分组内所有CPU,如果存在空闲的CPU,或者运行任务虚拟最后期限大于新任务的CPU,则将新任务插入该CPU对应的顺序双链表中,置位该CPU的调度标志并发送处理器间中断引发重新调度,否则将新任务插入分组对应的红黑树中。
GFS调度器核心操作的主要流程分析如下:
(1)scheduler_tick函数计算运行任务的运行时间,如果任务用完时间片则置位调度标志。如果各分组队列间负载严重失衡,进行分组间任务迁移。
(2)schedule函数清理调度标志,将运行任务插入CPU所在分组的红黑树中,如果运行任务用完时间片,重新装填时间片和虚拟最后期限。调度时,优先选取CPU对应的顺序双链表中的任务,如果顺序双链表为空,则选取红黑树最左侧的可运行任务,切换上下文执行新任务。
由于调度任务时,选取顺序是先查看顺序双链表,再查看红黑树,唤醒任务如果满足调度条件会放入顺序双链表并且立即通知CPU重新调度,这种机制减少了唤醒任务的响应时间,也使得顺序双链表中任务数不会很多,各项操作效率比较高。
假设系统中有M个CPU、N个任务、K个分组。任务插入及删除时间复杂度为O(lg(N/K)),新建和唤醒时间复杂度为O(M/K+lg(N/K)),调度时间复杂度一般为O(lg(N/K))。GFS优先调度满足调度条件的唤醒任务让交互任务的响应速度较高。每组CPU竞争一个主任务运行队列降低了竞争,分组内部任务迁移代价比较小,同时在一般情况下调度效率较高。
4 GFS算法实现
4.1 CPU分组配置
sched_init是Linux启动内核时进行调度初始化的函数。GFS在函数中为每个CPU初始化一个主任务运行队列指针和一个高级任务运行队列指针。为支持自动分组配置,GFS为每个CPU初始化一个数组cpu_locality,用于表示该CPU与其他CPU间的亲缘关系。定义一组宏:CPU<CORE<PHY<NUMA,对于每个CPU,遍历系统中所有其他的CPU,如果2个CPU在同一核的不同超线程上,则将cpu_locality的相应位设置为CPU;如果在同一处理器的不同核上,则将相应位设置为CORE;如果在同一NUMA节点的不同处理器上,则将相应位设置为PHY;否则将相应位设置为NUMA。GFS记录遍历过程中获得的CPU之间亲缘关系的最大值,依此进行分组自动配置。
migration_init是Linux进行任务迁移初始化的函数。GFS在函数中执行分组配置,如果CPU之间亲缘关系最大值为NUMA或PHY,则以处理器作为分组单位,通过cpu_locality数组找到同一处理器上的所有CPU划分为一个组,否则以核作为分组单位,同一核上的所有CPU划分为一个组。由于同一处理器上的所有CPU共享L2 Cache,这种分组配置下,任务在组内CPU之间迁移的代价比较小,同时组内有比较多的CPU可以选择运行。
自动配置可能不完全符合系统要求,GFS封装了系统调用sys_set_mainq_cpu实现重新指定CPU的主任务运行队列,用户可以通过系统调用实现手动配置CPU分组,更好发挥系统的硬件特性。
4.2 调度函数
4.2.1 scheduler_tick函数
GFS的scheduler_tick函数在BFS的scheduler_ tick函数末尾添加了负载均衡处理。负载均衡可以提高调度的并行性,但是执行时需要执行任务运行队列加解锁、任务迁移等操作,对调度器性能有影响,因此应该减少负载均衡的操作复杂程度和时机。
GFS通过调度域描述系统的CPU拓扑结构[11]。调度域表示具有相同亲缘关系的CPU集合,以层次结构组织,从下到上依次是同一核的不同超线程(CPU调度域)、同一处理器的不同核(CORE调度域)、同一NUMA节点的不同处理器(PHY调度域)、不同NUMA节点(NUMA调度域)。不同层次之间通过指针链接在一起,形成一种的树状的关系,如图4所示。
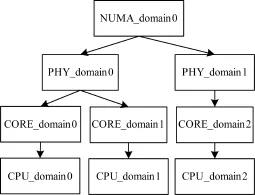
图4 调度域层次结构
算法从CPU所在的最低级别调度域往上遍历进行负载均衡,直到遍历完所有调度域。最低级别调度域与队列分组配置的粒度有关,例如分组时将同一核上的所有CPU放在一个组中,那么最低级别的调度域是CORE调度域,这样需要进行负载均衡的层数少了一层,减少了负载均衡操作的复杂度。
随着调度域级别的提高,CPU间亲缘关系疏远,共享Cache或内存减少,任务迁移刷新存储的代价越大。GFS以间隔时间表示调度域的任务迁移代价,调度域级别越高,任务迁移操作间隔时间越长。
在scheduler_tick函数末尾判断,如果当前时钟时间超过最低级别调度域负载均衡时间或者CPU运行空闲任务,则触发一个软中断进行负载均衡处理。
在软中断中,由rebalance_domains函数进行负载均衡处理,rebalance_domains函数在最低级别调度域执行任务迁移,并往上检查当前时钟时间是否超过各级别调度域的负载均衡时间,如果没有超过,则函数终止,否则进行任务迁移并继续检查。
load_balance函数进行具体的任务迁移处理。函数重设调度域的负载均衡时间,找出调度域下负载最重的子调度域,在子调度域中找到负载最重的队列,如果该队列不同于当前队列,则将该队列下的超重的任务迁移到当前队列上,以达到平衡。迁移过程中,如果发现有满足调度条件的任务,则置位相应的调度标志。
CFS在任务唤醒、任务创建时均需判断是否执行负载均衡,且每次操作都从CPU调度域遍历到NUMA调度域。相对CFS,GFS的负载均衡时机减少,仅需定期进行负载均衡和在CPU没有运行任务时进行负载均衡。另外,GFS的负载均衡操作扫描的调度域层数一般少于CFS,操作复杂度降低,负载均衡性能提高。
4.2.2 schedule函数
schedule函数核心问题为待运行任务的选取,选取顺序是先查看顺序双链表,再查看红黑树。如果顺序双链表中有任务,由于任务已经按照虚拟最后期限顺序由小到大排好,直接选取第一项作为待运行任务。如果高级任务运行队列中没有任务,调度器选取红黑树最左侧的可运行任务。考虑到一些任务可能绑定到指定CPU上执行,因此在红黑树中找到最左侧的任务后,需要判断该任务是否容许在CPU上运行,如果可以,则选取该任务作为待运行任务,否则继续查看该任务的后继,直到所有任务被扫描完。
如果所有的扫描都完成后还没发现待运行任务,则在对应的主任务运行队列中标记CPU为空闲CPU,新任务产生时可以在CPU上得到调度机会。选取的最坏时间复杂度为O(lg(N/K)((N/K)),这发生在系统中很多任务设置绑定到特定CPU时,一般情况下任务不会指定在特定的一组CPU上执行,因而可以在任意CPU上运行,这时选取时间复杂度为O(lg(N/K)),效率比BFS的O(N)高。
4.3 任务唤醒
唤醒任务的关键在于CPU选取。GFS按照CPU亲缘关系由近及远的顺序,优先选择空闲CPU,其次选择当前运行任务虚拟最后期限比自己大的CPU。
当任务唤醒时,首先找到任务所在分组的主任务运行队列,获取该队列分组的空闲可运行CPU信息,借助cpu_locality数组遍历并找到亲缘关系最近的空闲可运行CPU作为调度CPU。如果没有符合调度条件的空闲CPU,则获取该队列分组的非空闲可运行CPU信息,遍历并找到亲缘关系最近且当前运行任务虚拟最后期限大于唤醒任务的CPU作为调度CPU。
如果找到可调度的CPU,则把唤醒任务插入该CPU的高级运行队列,置位CPU的调度标志并发送处理器间中断;否则,将任务插入CPU所在分组的主运行队列。
5 测试结果与分析
5.1 测试环境和方法
为直观反映GFS的性能,本节对CFS、BFS、缓存竞争调度算法及GFS进行性能测试。测试平台环境为:CPU为4核8CPU的Intel(R)Core(TM)i7-3770 CPU@3.40 GHz,内存2 GB;操作系统: CentOS release 6.3,内核版本为Linux3.6.2。GFS自动配置同一核下的所有CPU为一个分组。
本文使用Interbench-0.31工具进行Linux交互性能测试[12]。Interbench模拟背景负载下交互任务的响应延迟数据。本次测试的背景负载为Burn,模拟若干服务CPU任务,CPU占用率为100%。交互任务为X_windows,模拟的是桌面操作任务,任务随机的睡眠及唤醒,CPU占用率与请求次数也不固定。任务唤醒与执行的时间差作为响应延时,分别测试背景负载由轻到重,任务数为8,16,24,32,40,48时交互任务响应延时的平均值、标准偏差及最大值,分析调度算法的交互性能。
5.2 结果分析
不同任务负载下3种调度算法的平均响应延时、响应延时标准方差、最大响应延时如图5~图7所示。
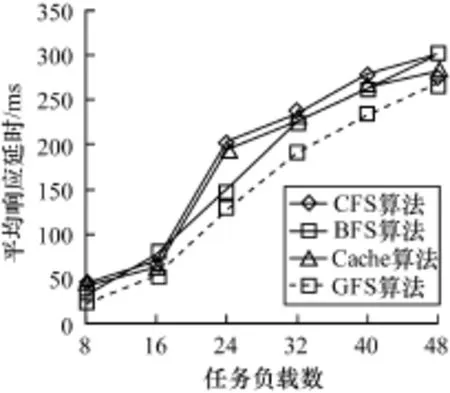
图5 不同任务负载下3种调度算法的平均响应延时
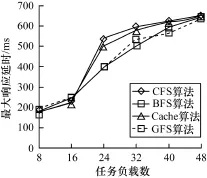
图7 不同任务负载下3种调度算法的最大响应延时
可以看出,在测试平台上,相比其他3种调度算法,GFS在不同计算任务数目的负载下交互任务的平均响应延时和响应延时标准方差上都有明显改进。在最大响应延时上,GFS总体改进不明显,主要是因为X_window类应用的请求比较随机。综合而言,GFS算法明显提高了系统的交互性能。
6 结束语
本文针对Linux调度算法在多核系统中交互性能差的问题,设计并实现了一种改进的任务调度算法GFS。GFS通过CPU分组共享队列、优先调度唤醒任务等设计减少交互任务的响应时间,提高多核系统的交互性能。下一步将在用户态的作业调度系统(如Quartz的调度算法)中引入GFS,从而提升系统调度性能。
[1] Silberschatz A.OperatingSystemConcepts[M]. New York,USA:John Wiley&Sons Ltd.,2004.
[2] 谢伟毅,廖光灯,谢康林.Linux调度算法在桌面应用环境中的改进[J].计算机工程与应用,2006,42(23): 101-103.
[3] Groves T,Knockel J,Schulte E.BFS vs.CFS Scheduler Comparison[Z].2009.
[4] 夏 厦,李 俊.基于缓存竞争优化的Linux进程调度策略[J].计算机工程,2013,39(4):58-61.
[5] Brain Fuck Scheduler[EB/OL].(2011-05-18).http:// en.wikipedia.org/wiki/Brain_Fuck_Scheduler#cite_ note-2.
[6] 朱 旭,杨 斌,刘海涛.完全公平调度算法分析[J].成都信息工程学院学报,2010,25(1):18-21.
[7] Molnar I.Modular Scheduler Core and Completely Fair Scheduler[EB/OL].(2008-05-03).http://lwn.net/ Articles/230501.
[8] 赵 旭,夏靖波.基于RTAI的Linux系统实时性研究与改进[J].计算机工程,2010,36(14):288-290.
[9] 杜慧江,王云光.Linux内核2.6.24的CFS调度器分析[J].计算机应用与软件,2010,27(2):166-168.
[10] Hennessy J L,Patterson D A.计算机系统结构:量化研究方法[M].郑纬民,汤志忠,汪东升,等,译.北京:电子工业出版社,2004.
[11] 邵立松,孔金珠,戴华东.芯片级多线程处理器的操作系统调度研究[J].计算机工程,2009,35(15): 277-279.
[12] Kolivas C.The Homepage of Interbench[EB/OL].(2006-08-11).http://users.on.net/~ckolivas/inter-bench/.
编辑 陆燕菲
A Linux Task Scheduling Algorithm for Multi-core System
CAO Yuea,b,c,GU Naijiea,b,c,REN Kaixina,b,c,ZHANG Xua,b,c,WU Zhiqianga,b,c
(a.School of Computer Science and Technology;b.Anhui Province Key Laboratory of Computing and Communication Software; c.Institute of Advanced Technology,University of Science and Technology of China,Hefei 230027,China)
To improve interactive performance of Linux in multi-core systems,this paper designs and implements an improved task scheduling algorithm named Group Fair Schedule(GFS).According to the hardware characteristics of multi-core system,GFS allows to configure a group of CPUs with close affinity to share one task run queue automatically,so that the cost of competitive access,task migration inside a group and run queue load balance between groups can be weighed,and reduces scheduling delay.GFS gives priority to awakening tasks so that interactive performance of multi-core systems is improved.Test results show that GFS decreases the average response time of interactive tasks under different background loads,and improves interactive performance of multi-core systems effectively.
multi-core system;scheduling algorithm;interactive performance;automotive configuration;awakening task;load balance
曹 越,顾乃杰,任开新,等.一种面向多核系统的Linux任务调度算法[J].计算机工程, 2015,41(2):36-40,46.
英文引用格式:Cao Yue,Gu Naijie,Ren Kaixin,et al.A Linux Task Scheduling Algorithm for Multi-core System[J]. Computer Engineering,41(2):36-40,46.
1000-3428(2015)02-0036-05
:A
:TP311
10.3969/j.issn.1000-3428.2015.02.008
“核高基”重大专项(2009ZX01028-002-003-005);高等学校学科创新引智计划基金资助项目(B07033)。
曹 越(1990-),男,硕士研究生,主研方向:并行计算,流程优化;顾乃杰(通讯作者),教授、博士生导师;任开新,讲师;张 旭,博士研究生;吴志强,硕士研究生。
2014-03-24
:2014-04-16E-mail:caoyue@mail.ustc.edu.cn
猜你喜欢
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
小学生学习指导(低年级)(2019年3期)2019-04-22
制造技术与机床(2019年4期)2019-04-04
军营文化天地(2018年2期)2018-12-15
测控技术(2018年7期)2018-12-09
小学生学习指导(低年级)(2018年9期)2018-09-26
产品可靠性报告(2017年7期)2017-09-05
小学生导刊(低年级)(2017年1期)2017-06-12
信息通信技术(2015年6期)2015-12-26
