
一种基于变邻域搜索的启发式聚类算法
2015-01-01 03:10陈家俊徐华丽
皖西学院学报 2015年5期
金 萍,陈家俊,徐华丽
(皖西学院信息工程学院,安徽 六安237012)
0 引言
聚类分析是数据挖掘的重要任务,是一种典型的无监督学习方法,成为对数据进行合理归类的重要手段[1-2]。聚类是根据数据的某些属性,按照预先定义的相似度将数据划分成若干类,并最大化类内数据对象的相似性,而最小化类间数据对象的相似性,以发现数据中隐藏的有用信息。直到目前为止还没有相关文献给出聚类的统一定义。基于不同的应用目的,研究者们采用不同的模型定义聚类问题。本文研究以组合优化模型定义的聚类问题,它是求解数值型数据聚类的重要方法,有着广泛的应用背景。

所有可能的M集合就构成了该类聚类问题的搜索空间CX,穷举CX中的每个结果就能获得最优聚类结果。文献[3]已经证明,即使在K=2的情况下,该聚类问题也是NP-难解的,即不存在多项式时间的精确算法能求得聚类问题的全局最优解。研究者们往往采用能在较短时间内获得可接受解的启发式搜索(heuristic search)方法来求解该类聚类问题,并设计了经典启发式聚类算法,如K-means[1]、K-mediods[2]、PAM[4]及CLARANS[5]等。图1给出了启发式聚类算法的搜索示意图。从图1中可以看出,初始解A和初始解B引导算法收敛于不同质量的聚类结果。这说明启发式聚类算法对初始解十分敏感。
变邻域搜索在搜索过程中,通过系统地改变邻域结构来拓展搜索范围,获得局部最优解,再基于已获得局部最优解重新系统地改变邻域结构扩展搜索范围,以寻求另一个局部最优解。由于变邻域在搜索过程中不断地重构搜索邻域,有效地避免了局部最优解的困扰,能很好地提高搜索算法的质量。
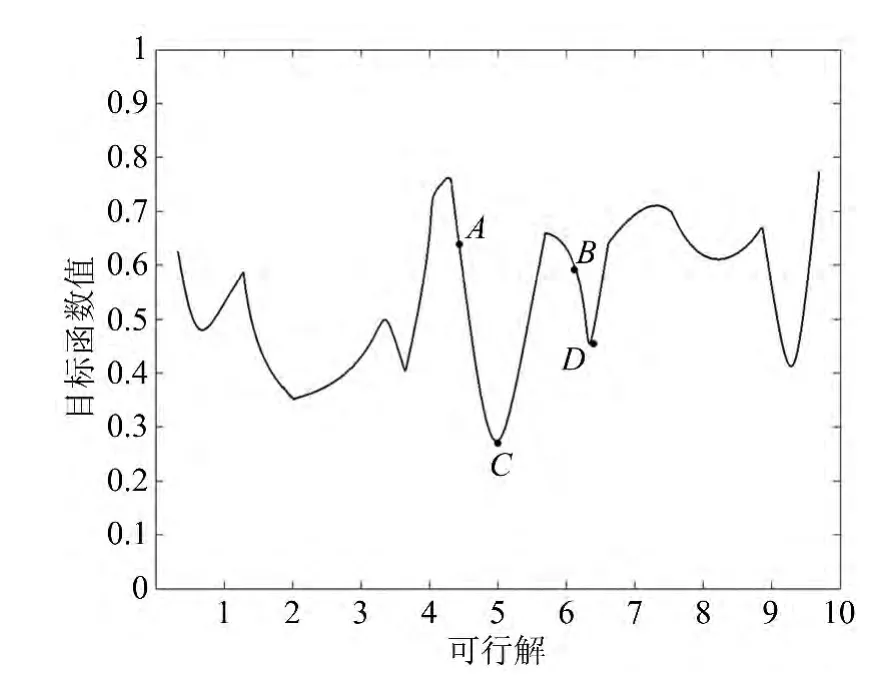
图1 启发式聚类算法搜索空间示意图
本文引入变邻域搜索技术改进现有启发式聚类算法初始解敏感问题,给出了一种基于变邻域搜索的启发式聚类算法HC_VNS(Heuristic Clustering Algorithm based on Variable Neighborhood Search)。该算法:(1)从给定数据D中选取K 个数据对象构成初始解Morg;(2)对于初始解Morg中的每个中心点,从数据集D-Morg中选择其KN个最近邻居,构造与其对应的可变搜索邻域VNS;(3)以初始解Morg为搜索起点,引导启发式聚类算法在VNS中搜索新的聚类中心Mlocal;(4)如果Mlocal优于Morg,则用Mlocal替换Morg,并迭代执行(2)~(3)直到达到预定目标,否则,继续在VNS中搜索聚类结果Mlocal;(5)依据产生的中心点集合,将D中剩余数据对象分配到与其最近中心点所表示的簇中,产生最终聚类结果C。实验结果表明,变邻域搜索对提高启发式聚类算法质量非常有效。
本文的组织结构如下:第1节介绍本文背景知识;第2节介绍基于变邻域搜索的启发式聚类算法框架;第3节给出了实验及实验结果分析;最后总结全文。
1 背景知识
给定包含N个数据对象的数据集D={x1,…,xi,…,xN}和任意聚类中心点集合M,其最近邻居和可变邻域的构造方法描述如下。
定义1 给定数据集D和聚类中心点集合M={m1,…,mk,…,mK},则mk∈M 的KN 个最近邻居定义为:
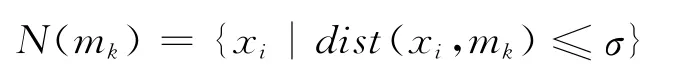
其中xi∈D-M,σ为阀值参数,用于选择KN个最近邻居,“-”为集合减运算。
定义2 给定数据集D和聚类中心点集合M,M的可变搜索邻域VNS定义为:
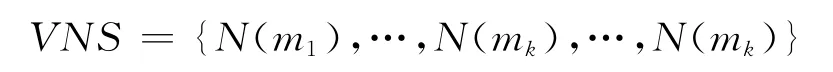
定义3 给定数据集D,初始解(即K个聚类中心点)Morg及其对应的可变搜索邻域VNS,启发式聚类算法HC_VNS的聚类结果定义为:
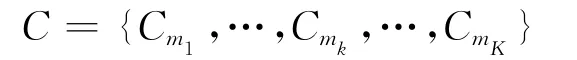
其中C(mk)是以mk为中心的聚类。
2 基于变邻域搜索的启发式聚类算法框架
本节介绍基于变邻域搜索的启发式聚类算法HC_VNS算法框架及时间复杂度分析。
2.1 HC_VNS算法框架
算法1 HC_VNS
输入:数据集D,聚类个数K
输出:聚类结果C
(1)从数据集D中任选K 个数据对象构成初始中心点Morg;
(2)for(p=1;p<=P;p++)
(a)根据定义1~2,构造 Morg的可变搜索邻域VNSorg;
(b)以Morg为搜索起点,调用现有启发式聚类算法在VNSorg中搜索新的聚类中心Mlocal;
(c)如果Mlocal优于Morg,则 Morg←Mlocal;
否则继续在VNSorg中搜索新的Mlocal;
(3)以步骤(2)产生的Morg聚类中心,将数据集D数据对象分配给与其最近的聚类中心,产生聚类结果C={Cm1,…,Cmk,…,CmK};
(4)返回聚类结果C。
算法1给出了HC_VNS算法框架。该算法主要包含3个步骤:选择初始解、迭代构造可变搜索邻域和启发式聚类。HC_VNS算法的具体步骤:(1)从给定数据D中选取K个数据对象构成初始解Morg(聚类中心点);(2)对于初始解Morg中的每个中心点mk∈M org,k=1,…,K,从数据集D-Morg中选择mk的KN 个最近邻N(mk)={xi},构造可变搜索邻域VNSogr={N(m1),…,N(mk),…,N(mK)};(3)以初始解Morg为搜索起点,引导启发式聚类算法在VNSorg中搜索聚类中心Mlocal;(4)如果 Mlocal优于Morg,则Morg←Mlocal,并迭代执行(2)~(3)直到达到预定目标,否则,继续在VNSorg中搜索聚类结果Mlocal。最后将D中剩余数据对象分配给与其最近的聚类中心,产生聚类结果C。
2.2 时间复杂度分析
算法HC_VNS的时间消耗主要集中在可变邻域构造与启发式搜索2个部分。对于任意给定的数据集D,dist()函数采用欧几里德距离,算法可先计算每个数据对象的相似度,耗时O(N2),其后可直接依据该相似度构建可变邻域。步骤(a)对Morg中的每个数据对象,选择与其最近的KN个邻居,构造可变搜索邻域VNSorg,需耗时O(K*KN)。步骤(b)以Morg为搜索起点,调用现有启发式聚类算法在VNSorg中搜索新的聚类中心,其耗时与调用算法及VNSorg的规模有关。现有的启发式聚类算法中K-means算法时间消耗与VNSorg的规模呈线性关系,而其它算法如PAM、K-medoids和CLARANS算法的时间消耗与VNSorg规模呈平方关系,即步骤(b)的时间消耗最多为O(K*KN2)。步骤(2)通过P次迭代执行可变邻域构建与启发式搜索,以完成搜索更优聚类中心的目的,其时间复杂度为O(P*K*KN2)。步骤(3)将数据集D的N 个数据对象分配给与其最近的聚类中心,产生聚类结果C,其时间消耗最多为O(K*N)。
综上所述,算法HC_VNS的总消耗为:O(N2+P*((K+1)*KN+P*K*KN)2),其中相似度计算步骤通常可以在预处理阶段完成,因此本文提出的算法时间消耗为O(P*((K+1)*KN+P*K*KN2))。
3 实验结果及性能分析
3.3 性能评价标准
本文使用文献[6]给出了一种兼顾簇内相似性与簇间相异性的内部质量衡量方式来评价HC_VNS算法性能。
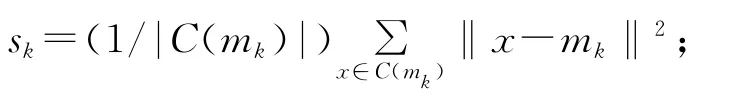

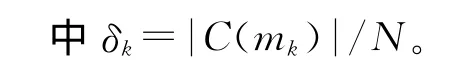
3.2 实验结果
根据上述算法实现步骤,进行实验仿真:实验平台采用Intel Core I5 3.3GHz CPU\4G 内存计算机,在Windows XP环境下用Matlab7.5实现算法HC_VNS以 及 对 比 算 法 K-means、NHCA[7]、CIGC[8]、ABRAC[9]。算法NHCA采用噪声法重构搜索空间,降低局部最优解对启发式聚类算法的影响。算法CIGC采用共有信息构建初始解,引导启发式聚类算法在解空间进行搜索。而ABRAC算法则引入近似骨架概念设计新的启发式聚类算法,提高聚类质量。这3个改进的启发式聚类算法被成功地应用于标注挖掘[10-11],不确定数据挖掘[12],推荐系统[13]等领域。
本文分别在1个人工实验数据集和5个经典的真实数据集上进行了实验。
(1)人工实验数据集
因为通过比较输入数据与输出数据,可以更精确地评价聚类结果,本文首先在人工实验数据集上进行实验。表1给出了人工数据集Dataset1的基本情况。

表1 Dataset1
图2给出了算法HC_VNS及其对比算法K-means、NHCA、CIGC和ABRA在Dataset1上的实验对比结果。从图中可以看出,经典启发式聚类算法K-means获得的Q(C)值明显高于其它对比算法,这说明K-means算法受到局部最优解的影响很大。算法NHCA采用噪声平滑技术“填平”搜索空间中的局部最优解“陷阱”,降低启发式聚类算法过早收敛概率,提高聚类质量,因此该算法的质量要明显优于K-means算法质量。CIGC算法利用多个局部最优解的共同信息,产生优化的初始解,并以此初始解来引导启发式聚类算法收敛于更优结果。ABRA算法则利用局部最优解和全局最优解分布的“大坑”特征,引入骨架概念设计启发式聚类算法。NHCA、CIGC、ABRA和HC_VNS都采用了不同的优化技术来避免局部最优解对算法的影响,从而达到提高聚类质量的目的。
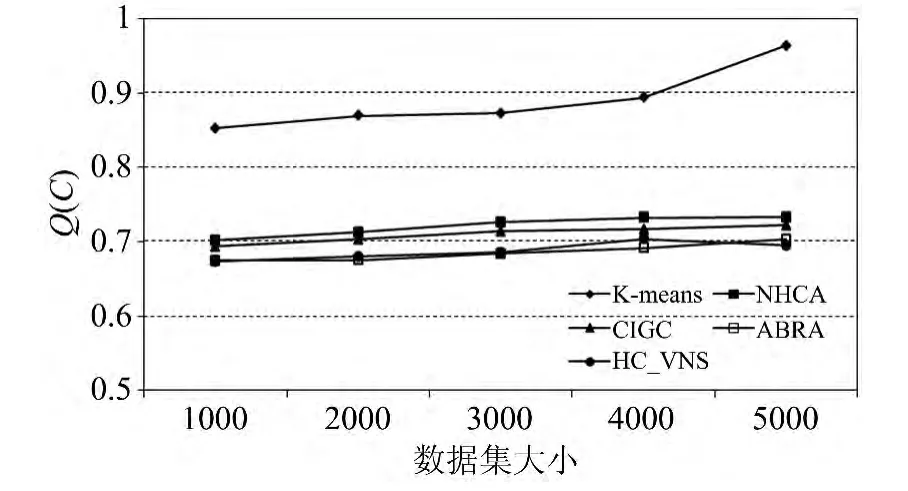
图2 5种对比算法在Dataset1上的实验结果
为了比较5种算法的效率,本文在数据集Dataset1上运行对比算法,获得的时间消耗如图3所示。从图中可以看出K-means算法基本与数据集的规模呈线性增长关系,而其它优化算法NHCA、CIGC和ABRA则几乎呈平方量级增加。造成这个现象的原因是:优化算法NHCA、CIGC和ABRA需要在数据集D上多次运行启发式聚类算法获得局部最优解,然后采用不同的优化策略进行算法质量改进,因此耗时较大。HC_NVS的时间消耗比K-means算法还要低一些,这是因为HC_NVS每次进行变邻域重构和启发式搜索都是在数据对象的KN个邻居中进行,因此大大减少了时间消耗。

图3 5种对比算法在Dataset1上的时间消耗对比
(2)实际数据集
为了验证算法HC_VNS处理实际数据集的能力,本文从http://archive.ics.uci.edu/ml/datasets.html网站上下载了5个真实数据集进行实验,数据集描述如表2所示。表2所示数据集包含规模、属性和簇3个属性,分别表示该数据集包含数据对象个数,数据对象的属性个数以及该数据集包含的聚类个数。每个数据集属性取值都是实数或整数。

表2 真实数据集
图4给出了5种对比算法在5个实际数据集上的实验结果。本文提出的HC_VNS和改进的启发式聚类算法NHCA、CIGC、ABRA都能较好地处理真实数据,获得较高质量的聚类结果,明显优于传统聚类算法K-means的聚类结果。但是在数据集BC、PRHD、CBD以及QM上的聚类结果不是太好,造成这个现象的原因是随着数据维度的不断增加,相似度的误差越来越大,影响了启发式聚类算法的效果。
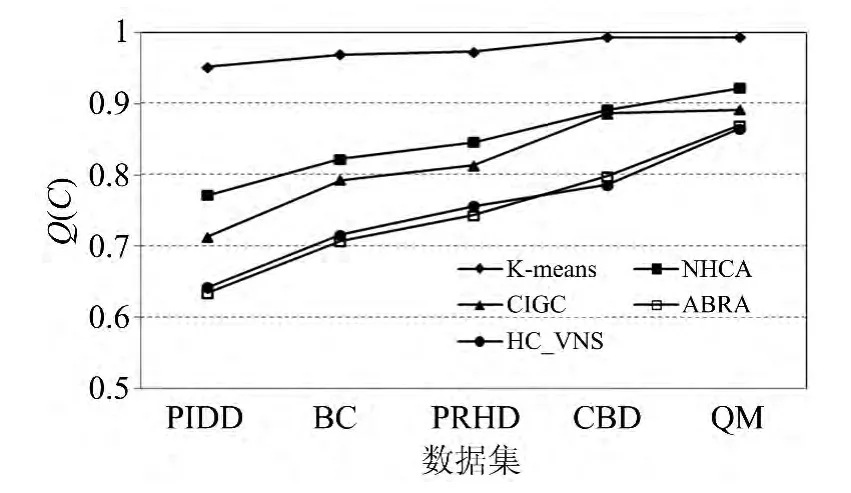
图4 5种对比算法在真实数据集上的实验结果
4 结语
本文利用可变邻域搜索的优点,设计了一种基于可变邻域搜索的启发式聚类算法,给出了算法框架,并分别在人工数据集和实际数据集上验证了算法的效率和效果。实验结果表明,可变邻域搜索对提高启发式聚类算法质量十分有效。
[1]Maimon O.,Rokach L.Data Mining and Knowledge Discovery Handbood[M].Spring,2010.
[2]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[3]Drinesa P.,Frieze A.,Kannan R.Clustering Large Graphs Via the Singular Value Decomposition[J].Machine Learning,2004,56(1-3):9-33.
[4]Kaufman L.,Rousseeuw P.J.Finding Groups in Data:an Introduction to Cluster Analysis[M].John Wiley &Sons,1990.
[5]Ng R.,Han J.CLARANS:A Method for Clustering Objects for Spatial Data Mining.IEEE Trans on Knowledge and Data Engineering[J],2002,14(5):1003-1016.
[6]宗瑜,江贺,张宪超,等.空间平滑搜索CLARANS算法.小型微型计算机系统[J].2008,29(4):667-671.
[7]金萍,宗瑜,李明楚.一种噪声启发式聚类算法[J].合肥工业大学学报,2009,32(6):786-790.
[8]金萍,宗瑜,李明楚.共有信息导向的启发式聚类算法[J].计算机工程与应用,2010,46(31):50-53.
[9]宗瑜,江贺,李明楚.近似骨架导向的归约聚类算法[J].电子与信息学报,2009,31(12):2953-2957.(EI检索)
[10]Xu G.D.,Zong Y.,Jin P.,et al.KIPTC:a Kernel Information Propagation Tag Clustering Algorithm[J].Journal of Intelligent Information System,2015,45(1):95-112.
[11]Rong P.,Xu G.D.,Peter D.,et al.Group Division for Recommendation in Tag-Based Systems[C].CGC 2012:399-404.
[12]金萍,宗瑜,曲世超,等.面向不确定数据的近似骨架启发式搜索算法[J].南京大学学报:自然科学版,2015,1(51):197-205.
[13]Li X.,Xu G.D.,Chen E.H.,Zong Y.Learning Recency Based Comparative Choice towards Point-of-interest Recommendation[J].Expert System and Application,2015,42(9):4274-4283.
猜你喜欢
昆钢科技(2022年4期)2022-12-30
农业工程学报(2022年7期)2022-07-09
昆钢科技(2022年1期)2022-04-19
昆钢科技(2021年6期)2021-03-09
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
吉林大学学报(理学版)(2020年3期)2020-05-29
电脑报(2019年4期)2019-09-10
小学科学(学生版)(2019年4期)2019-05-11
自动化学报(2018年7期)2018-08-20
