
基于抽样分组长度分布的加密流量应用识别
2015-01-01 02:56:32高长喜吴亚飚王枞
通信学报 2015年9期
高长喜,吴亚飚,王枞
(1.北京邮电大学 博士后流动站,北京 100876;2. 北京天融信公司 企业博士后工作站,北京 100085)
1 引言
网络流量应用协议识别是内容过滤、QoS、流量分析、安全通信及互联网监管和运维的基础。在网络安全领域,网络流量主要可分为明文流量、加密流量、匿名通信流量、入侵/攻击/渗透流量、病毒/木马/蠕虫/僵尸网络异常流量等。下一代网络中流量组成的复杂性及流量行为的多样性,特别是流量加密、伪装、隧道透传和分片等流量特征隐藏技术使网络流量应用协议识别面临着严峻的挑战。
根据所采用的协议特征的不同,应用协议识别方法可分为:基于端口、深度分组检测(DPI,deep packet inspection)和动态流检测(DFI, dynamic flow inspection)[1]等。基于端口的应用协议识别方法将知名端口作为协议特征,例如 P2P应用的固定服务端口、DNS的 53号端口等,然而动态端口、端口复用等机制使该方法已不能对应用流量进行精确分类。DPI将数据分组载荷内部位置固定或变动的静态字节序列作为协议特征,或者通过深入可识别的信令通道提取协商数据通道的 IP地址和端口而间接识别无特征数据流的应用协议类型(例如SIP),支持数据流中的单个数据分组或多个数据分组协议特征,并可实现细粒度应用协议区分;然而随着网络应用(如BitTorrent、eMule、Skype、Thunder 和 Tor 等)采用消息流加密或协议混淆来实现保密通信,除了极少数应用可通过逆向算法实时解密获取明文关键字特征之外,DPI已无法有效识别加密类应用协议。DFI将传输层连接模式、流统计特性[2]等流量行为作为协议特征,并使用启发式算法或机器学习方法进行流量分类,既能进行粗粒度应用分类(例如P2P类、交互类等),又能进行细粒度协议识别并且不依赖数据分组载荷内容(例如SSH、HTTPS),因此该方法非常适用于加密流量应用协议识别。
本文基于DPI和DFI混合方法,提出了一种基于假设检验的加密流量应用识别统计决策模型,并给出相应的加密流量应用识别算法。该方法首次将确定性抽样数据分组序列的位置、方向、分组长度和连续性、有序性等流统计特征作为协议特征,给出了典型的分组长度统计签名,并通过单数据分组的位置、方向约束及半流关联动作提升了传统DPI方法。基于加密应用BitTorrent和eMule评估数据集的实验验证了该加密流量应用识别算法的有效性。
2 相关工作
当前加密流量应用识别的研究主要采用流统计特征的DFI方法。文献[3]基于流的指定方向上的前若干个数据分组的分组长度以及数据分组载荷前若干字节内容的概率分布定义了 34种用于度量加密应用协议行为的统计属性指纹,提出了基于K-L散度(kullback-leibler divergence)的协议识别模型和算法,并通过实验评估了该算法识别混淆/加密协议的有效性;然而,该方法依赖载荷内容并且未充分利用流之间的相关性。文献[4]将流的支撑数据分组集合的分组长度分布作为协议特征,并根据端口局部性启发将流分组为会话,进而提出了一种基于距离相似性测度的会话级流分类方法,评估结果表明该方法对于流和会话都可以实现高准确率的分类;不过,该方法没有考虑到数据分组在流中的方向性。文献[5]基于流的前若干个数据分组在指定方向上的分组个数、分组长度及其均值、方差等给出了17种流量统计特征参数,提出了k-means和k-nearest neighbors机器学习算法相结合的加密流量混合分类算法,并在嵌入式实时环境中验证了该算法实时分类加密流量的可行性;但是,该方法未能将 DPI与统计方法有效结合起来实现多重识别。文献[6]将流在指定方向上的分组长度与交互到达时间的最大值、最小值、均值、标准差和分组个数等作为流特征,并基于采集自不同网络的数据集评估了 AdaBoost、支持向量机(SVM)、Naïve Bayesian、RIPPER和C4.5等5种机器学习算法用于分类SSH和Skype加密流量的顽健性,实验结果表明 C4.5算法具有最优的分类性能。文献[7]将流的前若干个数据分组的带有方向标记的分组长度(经过缩放预处理)作为协议特征,基于Gaussian mixture model和SVM分类器对SSH隧道承载的应用协议进行识别,并通过对经过SSH加密的POP3、POP3S、HTTP和eMule的实验验证了该方法的有效性。文献[8]对近年运用机器学习方法进行 IP流量分类的研究进展进行了综述和评论,将分类方法分为聚类、有监督的学习和混合方法等3类,并总结和比较了相关研究工作采用的具体机器学习算法、统计特征、评估数据集、待分类流量类型、分类粒度等策略以及准确率、实时性、计算复杂度和流方向依赖性等分类性能。
3 加密流量应用识别模型
基于假设检验的加密流量应用识别统计决策模型HTSDM (hypothesis testing-based statistical decision model) 定义如下。
定义1流方向
流方向定义为由五元组(源IP地址、源端口、目的IP地址、目的端口和传输协议号)标识的流的数据分组发送方向,记为DF={du,dd,db}。其中,du表示客户端向服务器发送分组的上行流方向,dd表示服务器向客户端发送分组的下行流方向,db表示不区分上下行的双向流方向。
定义2分组序列位置
分组序列位置定义为某个流方向上的带有有效负载的抽样数据分组序列的位置编号,并且位置编号在指定的流方向意义上针对全部带有有效负载的数据分组独立进行,记为X={xi,…,xj|1≤xk≤N,1≤i≤k≤j≤N}。其中,xk表示单个数据分组的位置编号,称作分组位置;N表示所在流方向上可取的最大位置编号。
根据所取的抽样位置序列{xi,…,xj}的不同,分组序列位置可分为单个固定位置、离散序列位置和连续区间位置。所谓的离散序列位置是指具有不等长间隔的抽样位置序列,而连续区间位置是指步长固定为1的均匀位置序列。
定义3分组序列方向特征
分组序列方向特征定义为带有有效负载的抽样数据分组序列在流中出现时所位于的流方向,记为DP={di,…,dj|dk∈DF,1≤i≤k≤j≤N}。其中,dk表示分组位置为k的数据分组位于的流方向,称作分组方向;N表示可取的最大分组位置。
定义4分组序列分组长度特征
分组序列分组长度特征定义为带有有效负载的抽样数据分组序列在流中指定的分组位置上的分组长度(即分组载荷长度)、分组长度序列、分组长度集合或分组长度统计量所应满足的特定阈值约束,记为L={li,…,lj|lk=[infk,supk],i≤k≤j}。其中,infk和supk分别表示分组长度特征分量lk的阈值下限和阈值上限,当infk与supk相等时,lk取固定值,否则取范围值。
特别地,L可取位置分组长度变量,所谓的位置分组长度变量是指某个分组位置处的数据分组长度,该数据分组长度事先未知,而只能进行动态提取和确定。
定义5分组序列连续性
在流中指定的流方向DF上的数据分组序列在连续区间位置X上不间断的一一出现并且满足相应的分组序列方向特征DP和分组序列分组长度特征L,则称为分组序列满足连续关系。分组序列连续关系记为Rc(DF,X,DP,L)={rcc,rcv},其中rcc表示分组序列连续,rcv表示分组序列不必连续。
定义6分组序列有序性
在流中指定的流方向DF上的数据分组序列在指定的分组序列位置(离散序列位置或连续区间位置)X上按照指定的先后顺序依次出现并且满足相应的分组序列方向特征DP和分组序列分组长度特征L,则称为分组序列满足有序关系。分组序列有序关系记为Rs(DF,X,DP,L)={rss,rsv},其中rss表示分组序列有序,rsv表示分组序列不必有序。
定义7分组长度分布特征
分组长度分布特征定义为带有效负载的抽样数据分组序列在流中指定的流方向DF、指定的分组序列位置X上应存在一个长度为N的数据分组子序列并满足分组序列方向特征DP、分组序列分组长度特征L、分组序列连续性Rc和分组序列有序性Rs约束,记为F(DF,X,DP,L,Rc,Rs,N) =DFXDPLRc Rs。
定义8分组长度统计签名
分组长度统计签名定义为应用协议类型C已知的加密流量的分组长度分布特征F、统计量T以及统计量T的期望值Te,记为P(F,T,Te,C)。其中,Te=[tinf,tsup]。典型的分组长度统计签名如表1所示,对于不同的统计签名,Te表示数据分组子序列的长度或单个分组长度。

表1 典型的分组长度统计签名
定义9分组长度统计签名变量分组位置
分组长度统计签名可以引用其他的分组长度统计签名定义其分组序列位置。相对于当前分组长度统计签名所引用的分组长度统计签名的命中位置、在某个流方向上的带有有效负载的抽样数据分组序列的偏移位置编号,称为分组长度统计签名变量分组位置,记为j≤N}。其中,表示单个数据分组的偏移位置编号;N表示所在流方向上可取的最大偏移位置编号。
分组长度统计签名决策模型
零假设H0:加密流量应用协议类型为C。
备择假设H1:加密流量应用协议类型不为C。
检验值z:分组长度统计签名P的统计量T。
显著性水平:α

定义10DFI特征
满足一定的逻辑关系Rl的多个分组长度统计签名P的集合,称为DFI特征,记为FF({Pi};Rl)。其中,逻辑关系Rl支持AND、OR和逻辑表达式,缺省为 AND;逻辑表达式由 AND、OR和分组长度统计签名P的编号组成。
定义11半流关联特征
已识别应用协议类型C的流的源(或目的)IP、源(或目的)端口port和指定的传输协议tp组成的二元组或三元组称为半流关联特征,记为RF(IP,port,tp,C)。其中,由IP、端口和传输协议组成的三元组称为强关联特征,而IP和传输协议组成的二元组称为弱关联特征;半流关联特征RF中缓存有关联的应用协议类型C。
已识别应用协议类型的流的半流关联特征RF通过散列运算生成关联半流表(RT, relational table),后续可通过提取的强关联特征直接进行关联查表确定流的应用协议类型,或通过提取的弱关联特征进行预过滤以筛选出需根据指定了该弱关联特征的规则进行后续识别的流。
定义12单数据分组特征
单数据分组特征定义为在流中指定的流方向DF、指定的分组位置X和指定的分组方向DP上的单个数据分组应满足的关键字特征、分组长度特征、端口特征、IP地址特征或半流关联特征等特征签名sig,并且多个特征签名之间满足一定的逻辑关系Rl,记为PF((DF,X,DP, {sig});Rl)。其中,逻辑关系Rl支持AND、OR和逻辑表达式,缺省为AND;逻辑表达式由AND、OR和特征签名sig的编号组成。
定义13提升型DPI规则
由规则头HD、单数据分组特征PF和可选的关联动作ACT组成的应用识别规则,称为提升型bDPI(boosting DPI)规则,并记为DR(HD,PF,ACT)。其中,规则头HD包括规则编号、应用协议类型C、传输协议tp、优先级prio等;关联动作ACT指定在规则命中时应提取并添加到关联半流表RT中的半流关联特征RF。
定义14DFI规则
由规则头HD、单数据分组特征PF和DFI特征FF组成的应用识别规则,称为DFI规则,并记为SR(HD,PF,FF)。其中,规则头HD包括规则编号、应用协议类型C、传输协议tp、优先级prio等;单数据分组特征PF为在验证DFI特征FF之前应首先满足的预过滤条件。
DFI决策模型
预过滤条件H(PF):

决策规则H(DFI) =H(PF) ∧H(FF)
4 加密流量应用识别算法
4.1 PLSSI匹配算法
分组长度统计签名匹配算法 PLSSI(packet length statistical signature identification)基于分组长度统计签名决策模型实现,其伪代码如下文所示。
算法输入:分组长度l,分组方向d,分组长度统计签名P、分组长度统计签名P的匹配状态SP和流在各方向上的当前分组位置cp[]。其中,匹配状态SP包括当前分组位置x、统计量T的当前分组长度统计量l'、统计量T的当前分组计数n、位置分组长度变量的当前值l"、连续性状态rc、有序性状态rs、当前识别状态QP(PENDING、HIT、FAILED)。
算法输出:带更新状态的分组长度统计签名P。
算法描述:

4.2 HMETI识别算法
HMETI(hybrid method for encrypted traffic identification)加密流量应用识别算法基于 DFI决策模型实现,分为预处理和识别2个阶段。其中,预处理阶段根据bDPI规则和DFI规则的单数据分组特征生成包括多模式匹配状态机和散列表的DPI引擎,而识别阶段则首先利用DPI引擎筛选出命中了预过滤条件的DFI规则集,然后基于HTSDM模型对初步命中的DFI规则进行DFI特征的验证。通常情况下,需要对目标流进行多次识别,并且最多只处理流的前N(通常取N=60)个带有效负载的数据分组。HMETI算法的伪代码如下所示。
算法输入:规则集合 SET,分组上下文pkt,流节点fn,关联半流表RT。其中,规则集合 SET包括bDPI规则DR和DFI规则SR;分组上下文pkt包括当前数据分组的分组长度l、分组方向d、载荷payload和五元组tuple等;流节点fn为会话流表节点,包括流统计子节点链表fsnlist、流在各方向上的当前分组位置cp[]、流识别状态QF、流应用协议类型cid等;流统计子节点fsn与DFI规则SR相对应,包括DFI规则SR的各个分组长度统计签名P的匹配状态SP和规则识别状态QR。
算法输出:带有更新状态的流节点fn。
算法描述:


5 实验与结果分析
为了对前文所述的加密流量应用识别方法的有效性进行评估,本文在 Linux平台上实现了HMETI应用识别引擎库,并基于Libpcap和readline库实现了相应的驱动测试平台 TrafficBench,支持规则集配置、报文回放、识别结果统计报表、基于识别结果的报文过滤及导出等功能。
5.1 评价指标
网络流量应用识别方法准确性的评价指标主要有误报率、精确率、召回率、总体准确率和总体误报率等几种。此处讨论的网络流量应用识别方法包括应用协议识别算法和对应的规则集合。
误报(FP, false positive)是指将本不属于某类应用的流量识别为该类应用;漏报(FN, false negative)是指将本属于某类应用的流量识别为其他类型应用;真报(TP, true positive)是指将属于某类应用的流量识别为该类应用。

表2 识别方法评价指标的符号约定
假定测试样本集由N类应用的流量构成,使用网络流量应用识别方法对该测试集进行识别,按照表2给出的符号约定,第i类应用协议识别的准确性评价指标定义如下。

总体误报率(overall FPR)

如果上述定义采用不同的统计粒度(例如流、分组个数、字节数等),则可得到网络流量应用识别方法在不同维度的应用协议识别准确性评价指标。
5.2 数据集
本文选取了支持协议加密/混淆的 P2P应用BitTorrent(简称BT)和eMule评估前文所述加密流量应用识别方法的有效性,其中,BitTorrent客户端选用 BitTorrent V7.6.1和 uTorrent V3.3,eMule客户端选用eMule V0.50a和easyMule V1.2.0,并且开启了协议加密/混淆功能。
评估所用的数据集分别单独按照不同应用捕获自实验室环境,如表3~表5所示。表3中的BitTorrent和eMule数据集1由19个Trace文件组成,每个Trace为BitTorrent或eMule产生的全部TCP和UDP混合流量,包括Web流量、明文数据流量和加密流量,并且滤除了 DNS、ARP等无关流量。表 4中的BitTorrent和eMule数据集2分为训练集和测试集2部分,其中,训练集为人工分类和标注的TCP加密数据流,而测试集为从数据集1中过滤出的无法通过DPI识别的全部BitTorrent或eMule TCP数据流,具体的bDPI规则如下文表6所示。表5中的背景流量数据集3共计286个Trace文件,分别对应各种常见的加密应用和普通应用(或协议),其中加密应用占据了绝大部分流量。

表3 BitTorrent和eMule数据集1

表4 BitTorrent和eMule TCP数据集2

表5 背景流量数据集3
为了模拟真实网络环境出口捕获流量的特性,例如本地主机IP分布和不同应用在本地主机上的分布,数据集的全部Trace统一进行了单个本地主机IP的重新映射处理。本地主机IP的映射方法如下:1)预设私有IP地址池1和2,其中,IP地址池1容量设置为30,IP地址池2容量设置为200,并且IP地址池1为IP地址池2的子集;2)将每个BitTorrent或eMule Trace中的本地主机IP随机映射为IP地址池1中的某个私有IP,将背景流量的每个Trace中的本地主机IP随机映射为IP地址池2中的某个私有IP,并保证不同应用类型Trace之间的本地主机IP、非知名端口和传输协议三元组无冲突。经过重映射处理之后,数据集的Trace包含多个本地主机,并且每个本地主机IP对应一种或多种应用,与实际网络流量分布模型相一致。
5.3 规则集
实验采用的规则集包括 BitTorrent、eMule和Web的相应bDPI规则和DFI规则。
由于BitTorrent、eMule和Web HTTP都属于开源协议,其单数据分组特征较易于分析和提取,具体的bDPI规则如表6所示。为方便计算,bDPI规则的单数据分组特征的关键字特征采用正则表达式语法描述,在实际解析和预处理时,应分离出正则表达式的所有因子字符串并保留其在数据分组内的位置信息和字符串之间的逻辑关系。作为典型的P2P应用,BitTorrent和eMule使用UDP和单个端口与大量的节点进行 DHT/Kad网络通信以执行查找资源、维护节点联通性等功能或进而进行基于UDP的数据传输,因此,通过将相应的bDPI规则关联动作设定为源强关联以直接识别该类 UDP流量。由于BitTorrent在进行TCP加密数据传输时必然伴随着与 Tracker进行通信,因此,通过将相应的 bDPI规则关联动作设定为源弱关联可输出运行BitTorrent应用并可能进行加密数据传输的候选主机,该弱关联特征可作为进行BitTorrent加密流量识别的先决条件。
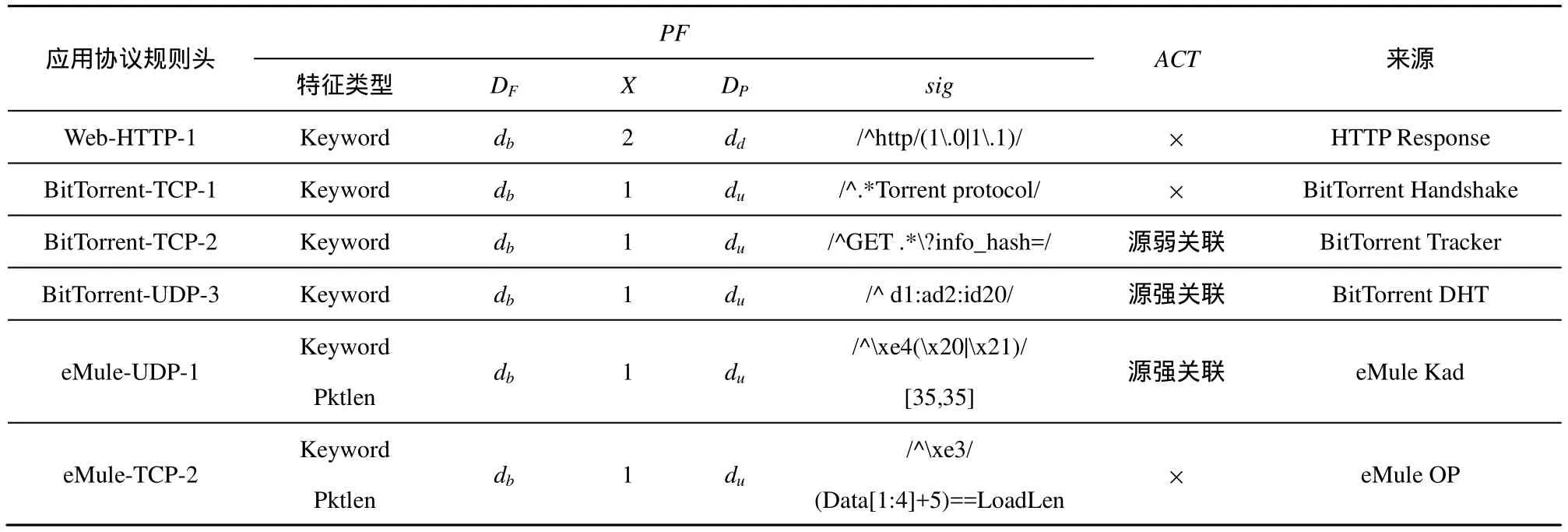
表6 BitTorrent、eMule和Web应用协议的bDPI规则
为了选择和提取BitTorrent和eMule的DFI特征,基于数据集2中的训练集样本和典型的分组长度统计签名,考察BitTorrent和eMule在双向流方向、上行流方向上的分组长度分布以及 BitTorrent的同向连续分组长度和,统计结果如图1~图4所示。
图1为分别从BitTorrent和eMule的36条加密数据流中抽取的双向流方向上的前30个数据分组的分组长度分布散点图,其中,X轴表示双向流方向上的分组位置,Y轴表示数据分组长度,正值表示分组方向为上行,而负值则表示分组方向为下行(坐标轴正负值含义下同)。由图 1可知,BitTorrent加密数据流的首分组分组长度介于70~300,eMule首分组分组长度介于12~270,第2个分组的分组方向总为下行且分组长度介于6~261,第3个分组的分组方向总为上行且分组长度介于95~200,第4个分组的分组方向总为下行且分组长度介于86~358。
图2为BitTorrent的36条加密数据流上行流方向上的第4~20分组位置上分组长度小于200的数据分组的分组长度分布散点图,其中,X轴表示流编号,Y轴表示在对数坐标下的数据分组长度。由图2可知,分组长度17和34为频繁项并构成所有流的集合覆盖,这表明在BitTorrent加密数据流上行流方向的第4~20分组位置上至少存在1个分组长度等于17或34的数据分组。
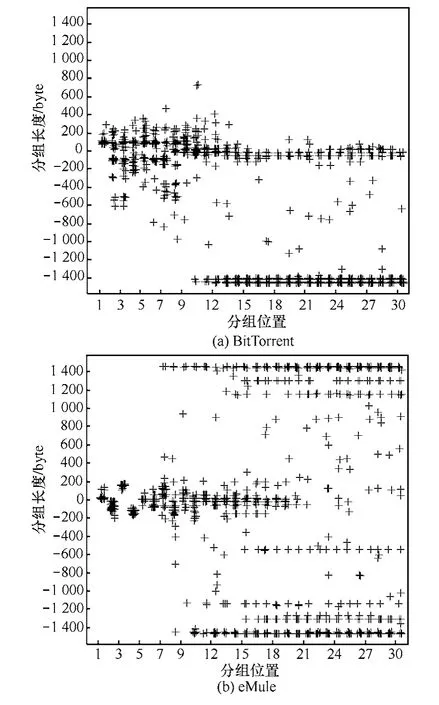
图1 BitTorrent和eMule加密流双向前30个数据分组长度分布

图2 BitTorrent加密流上行数据分组分组长度分布
图3为eMule的36条加密数据流上行流方向上的第3~10分组位置上分组长度小于300的数据分组的分组长度分布散点图,其中,X轴表示流编号,Y轴表示在对数坐标下的数据分组分组长度。由图3可知,分组长度6、11和22为频繁项并构成所有流的集合覆盖,这表明在eMule加密数据流的上行流方向的第3~10分组位置上至少存在1个分组长度等于6、11或22的数据分组。
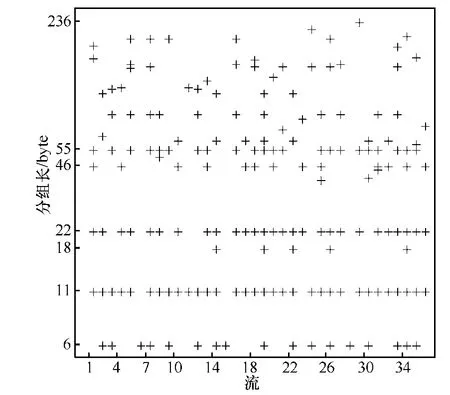
图3 eMule加密流上行数据分组分组长度分布
图4为从BitTorrent的36条加密数据流中抽取的上行和下行流方向上同向连续数据分组分组长度和的散点图,其中,X轴表示上/下行连续交替位置,Y轴表示同向连续分组长度和。由图4可知,在BitTorrent加密数据流的上行流方向的第1~2轮同向连续数据分组的分组长度和分别介于 95~610和5~640,下行流方向的第1轮同向连续数据分组的分组长度和介于80~610。
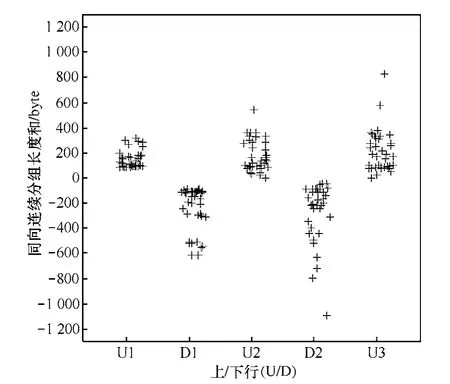
图4 BitTorrent同向连续数据分组的分组长度和
基于上述分析,可以得到 BitTorrent和 eMule的TCP加密协议DFI规则,如表7和表8所示。
5.4 实验结果
以数据集3作为背景流量,基于上述BitTorrent和eMule TCP加密协议DFI规则,取显著性水平α=0.01,运用 HMETI算法对数据集 2的测试集样本进行加密流量识别,得到的识别结果如表9所示。由表9可知,BitTorrent加密流量识别的字节精确率和召回率可达98%以上,而eMule加密流量识别的字节精确率和召回率则分别为 100%和 99.9%;eMule误报率为0%,而BitTorrent误报率则相对较高,其字节误报率接近2%。

表7 BitTorrent TCP加密协议DFI规则

表8 eMule TCP加密协议DFI规则
为了降低BitTorrent加密流量误报率,考虑结合 bDPI方法进一步加强预过滤条件进行优化,只对由bDPI判定为具有BitTorrent行为的主机进行后续加密流量识别,为此,在表7中的DFI规则的单数据分组特征 PF中引入源弱关联特征并且联合表6中的 bDPI规则 BT-TCP-2,利用数据集 1中的BitTorrent Trace重复上述BitTorrent加密流量识别过程,得到的BitTorrent加密流量优化识别结果如表10所示。与表9所示的优化之前的识别结果相比,字节误报率显著降低,仅有0.364%,字节精确率提高到99.6%以上,而召回率保持不变。
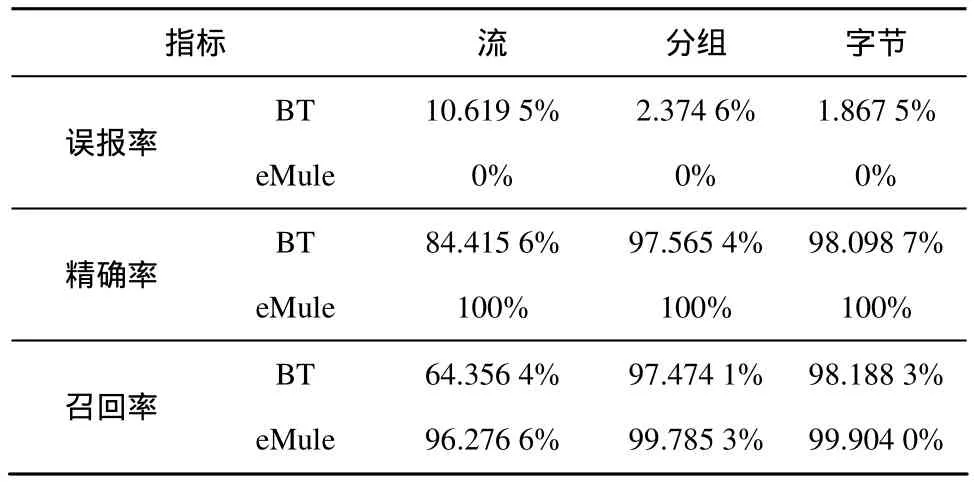
表9 BitTorrent和eMule加密流量识别结果

表10 BitTorrent加密流量优化识别结果
本文将HMETI算法与其他典型的加密流量应用识别方法进行了对比,结果如图5所示。其中,SPID、SLFC和K-K算法分别由文献[3~5]提出。由图可知,无论是对于加密应用BiTorrent还是eMule,本文提出的HMETI算法都具有比其他加密流量应用识别方法更高的识别准确率,这是由于 HMETI算法引入了确定性抽样数据分组序列的位置、方向、分组长度和连续性、有序性等流统计特征,从而使该方法能够成功捕获加密应用在流坐标空间中独特的统计流量行为。
最后,考察BitTorrent和eMule产生的全部应用流量识别的总体准确性。利用HMETI算法和包括所有bDPI规则和DFI规则在内的规则集,取显著性水平.α= 0.01,以数据集3作为背景流量,按照4种方法分别对数据集1进行完全流量识别,得到的总体准确率和总体误报率如图 6所示。其中,X轴表示识别方法,方法1使用传统DPI规则(无关联动作),方法2使用bDPI规则(带关联动作),方法3使用bDPI规则和未优化的DFI规则(不含源弱关联预过滤特征),方法4使用bDPI规则和优化的DFI规则(含源弱关联预过滤特征);Y轴表示在对数坐标下的总体准确率和总体误报率。
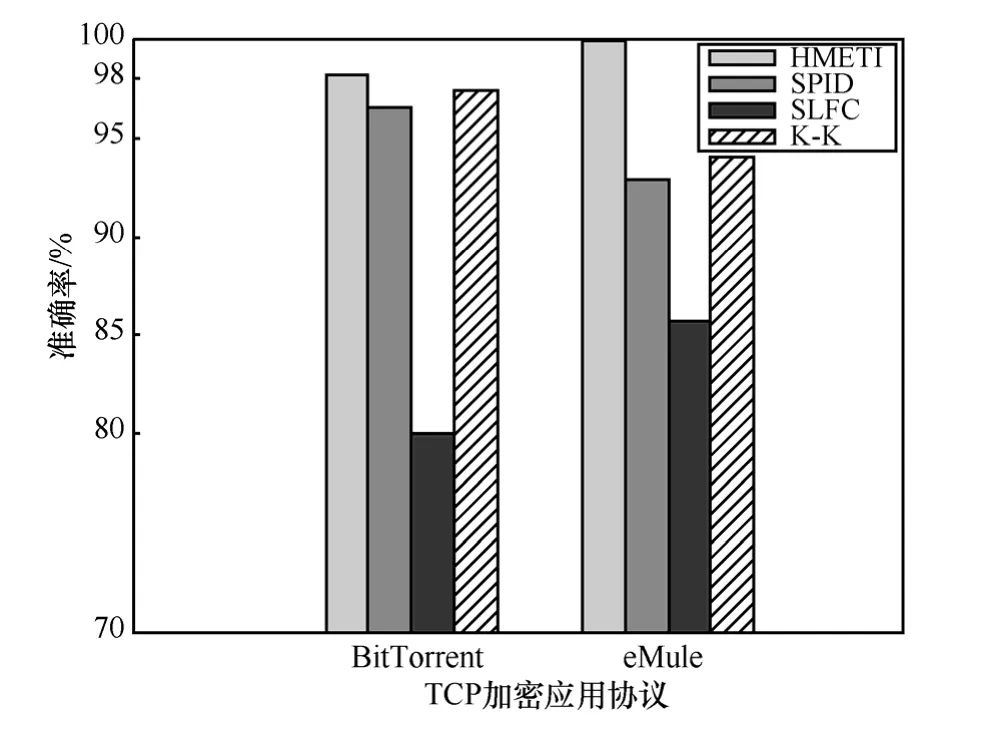
图5 各算法的加密应用识别准确率对比
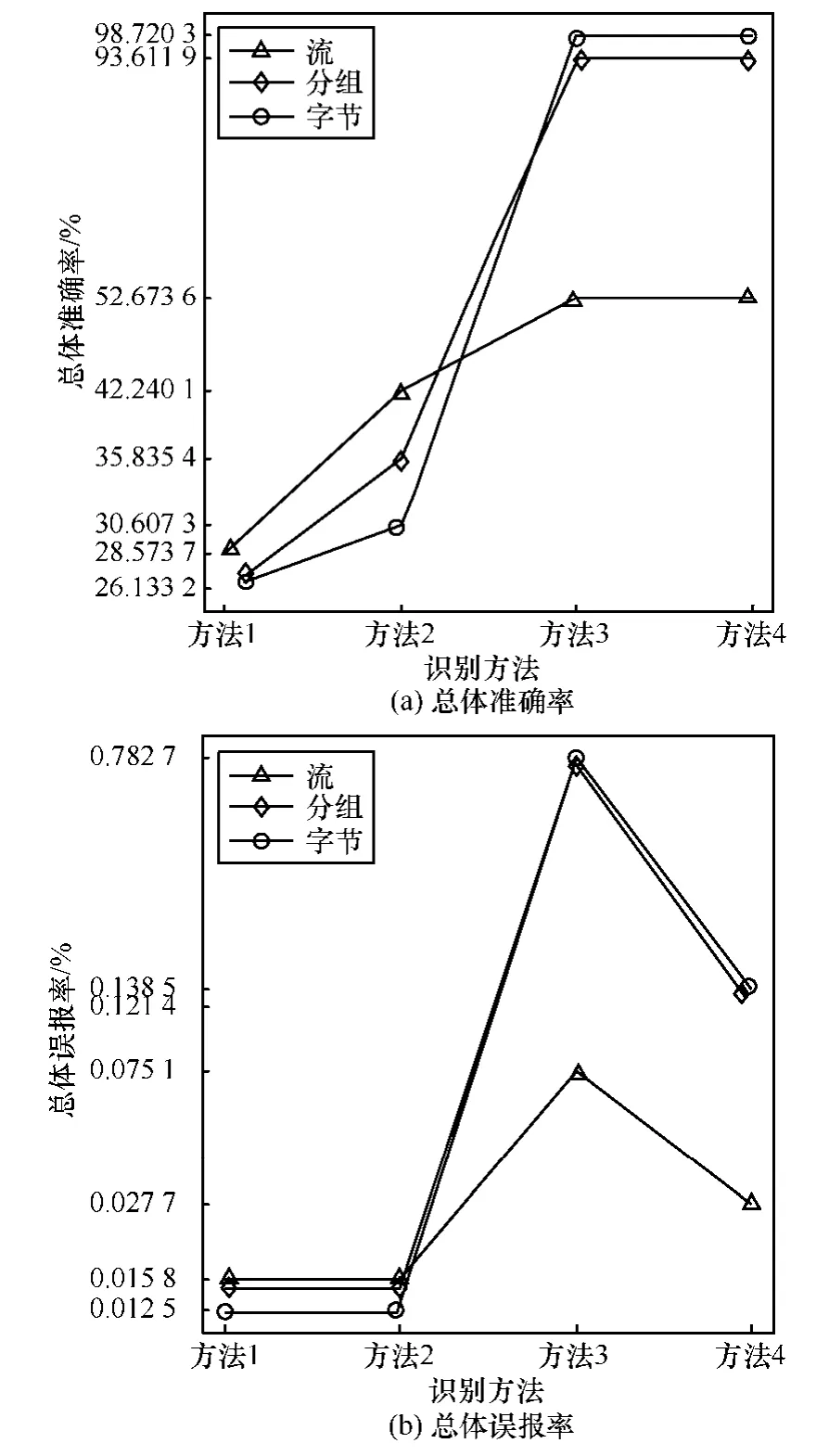
图6 全部应用协议识别的总体准确率和总体误报率
由图6可知,传统DPI方法的字节总体准确率仅有26.133 2%,这表明协议加密/混淆使传统DPI方法已经部分失效,而引入半流关联方法和DFI方法之后的字节总体准确率则逐步升高,在方法4时达到峰值,其字节总体准确率为98.720 3%,这表明占据大部分比例且无DPI特征的TCP加密流量和UDP数据流量已被准确识别。另外,不同统计粒度(字节、分组与流)的总体准确率差别较大,这主要是由于在 P2P类应用产生的大量会话中真正进行业务数据传输的流数量非常少,大部分为短会话或无效流,并且有部分加密数据流无法被识别。
同时,如图6所示,BitTorrent和eMule流量识别的总体误报率非常低,对于识别方法 4,其在达到最高字节总体准确率的同时,字节总体误报率仅为0.138 5%,具有最优的识别性能。从方法2到方法4时总体误报率抖动较大,原因是方法3引入了未优化的DFI方法导致了较高的加密流量识别误报,而方法4则使用了优化的DFI方法使加密流量识别的误报数量迅速下降。
6 结束语
本文基于加密应用在流坐标空间中的分组序列统计特征和典型的分组长度统计签名,提出了一种基于假设检验的加密流量应用识别统计决策模型 HTSDM,并给出了相应的基于 DPI和 DFI混合方法的加密流量应用识别算法 HMETI。最后,通过加密应用BitTorrent和eMule数据集评估了 HMETI算法的有效性。实验结果表明,本文提出的加密流量应用识别方法可以达到接近99%的字节总体准确率,并且仅有约0.1%的字节总体误报率。
HMETI算法依赖于数据分组在流中的位置和到达顺序等,因此需要对待识别流进行数据分组的去重传、分片重组、乱序重排等预处理,并且通常只应用于可靠有序的 TCP加密流。同时,HMETI算法对非对称路由[9]具有顽健性,对于无法获取完整流的应用场景,可使用单向流的分组序列统计特征。另外,由于采用了预过滤方法并且只需抽样识别流的少量数据分组,因此HMETI算法具有较低的计算复杂度并可应用到实时环境。
选取恰当的加密流量分组序列统计特征和分组长度统计签名是保证HMETI算法应用识别准确性的关键。目前,加密应用的流量统计特征和分组长度统计签名的提取主要是通过人工对捕获的大量流量Trace的分类、标注和分析进行,提取效率、特征的显著性和完整性都比较低。因此,下一步的研究工作将是利用数据挖掘算法进行加密流量统计特征和分组长度统计签名的自动提取和验证。
[1] GOMES J V, INÁCIO P R M, PEREIRA M,et al. Detection and classification of peer-to-peer traffic: a survey[J]. ACM Computing Surveys, 2013, 45(3):1-40.
[2] MOORE A, ZUEV D, CROGAN M. Discriminators for use in flow-based classification[R]. Technical Report RR-05-13, ISSN 1470-5559, University of London, 2005.
[3] HJELMVIK E, JOHN W. Breaking and improving protocol obfuscation[R]. Technical Report No.2010-05, ISSN 1652-926X, Chalmers University of Technology, 2010.
[4] LU C N, HUANG C Y, LIN Y D,et al. Session level flow classification by packet size distribution and session grouping[J]. Computer Networks, 2012, 56(1):260-272.
[5] BAR-YANAI R, LANGBERG M, PELEG D, RODITTY L. Realtime classification for encrypted traffic[A]. Proceedings of 9th International Symposium on Experimental Algorithms (SEA 2010)[C]. Naples,2010.373-385.
[6] ALSHAMMARI R, ZINCIR-HEYWOOD A N. Machine learning based encrypted traffic classification: identifying SSH and skype[A].Proceedings of the 2009 IEEE Symposium on Computation Intelligence in Security and Defense Applications (CISDA 2009)[C]. Ottawa,2009.1-8.
[7] DUSI M, ESTE A, GRINGOLI F, SALGARELLI L. Using GMM and SVM-based techniques for the classification of SSH-encrypted traffic[A]. Proceedings of the 44th IEEE International Conference on Communication(ICC’ 09)[C]. Dresden, 2009.1-6.
[8] NGUYEN T, ARMITAGE G. A survey of techniques for internet traffic classification using machine learning[J]. IEEE Communications Surveys & Tutorials, 2008, 10(4):56-76.
[9] CROTTI M, GRINGOLI F, SALGARELLI L. Impact of asymmetric routing on statistical traffic classification[A]. Proceedings of the 7th IEEE Global Communications Conference (GLOBECOMM 2009)[C].Honolulu, 2009.1-8.
猜你喜欢
数学小灵通(1-2年级)(2020年9期)2020-10-27 03:24:46
太原科技大学学报(2019年3期)2019-08-05 01:18:18
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
作文大王·低年级(2017年11期)2017-12-05 00:08:45
小学生学习指导(低年级)(2017年12期)2017-11-22 06:22:39
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
信息安全研究(2016年10期)2016-02-28 20:18:19
读写算(上)(2015年6期)2015-11-07 07:17:55
电子设计工程(2015年17期)2015-02-27 12:08:03
