
基于人工神经网络的人口预测
2014-12-24 06:54杨茂江
科技视界 2014年21期
杨茂江
(茂名市高级技工学校,广东 茂名525000)
0 引言
中国是一个人口大国, 人口问题始终是制约我国发展的关键因素之一, 但是要确定人口发展战略, 必须既着眼于人口本身的问题, 又处理好人口与经济社会资源环境之间的相互关系, 构建社会主义和谐社会, 统筹解决人口数量、素质、结构、分布等问题。已有的文献采用微分方程、灰色系统和曲线拟合等方法研究了我国人口问题[1-2]。 本文根据近年来中国的人口发展所出现一些新的特点, 以及近几年中国人口抽样数据及现有全国人口普查数据, 运用人工神经网络算法[3-4]对中国人口做出了分析和预测。人工神经网络(ANN)可以通过学习来抽取和逼近输入输出之间存在的非线性关系。 因此,基于人工神经网络的预测方法成为近几年研究的热点。目前,主要采用BP 神经网络、局部反馈性神经网络等。 BP 神经网络是人工神经网络中应用最广泛的算法。
1 BP 神经网络模型
BP 神经网络的输入与输出之间是一种高度非线性映射关系,如果输入节点数是N,输出节点数是M,则网络是从N 维欧式空间到M维欧式空间的映射。 通过调整BP 神经网络的连接权值和网络的规模(包括N,M 和隐层节点数),可以以任意精度逼近任何非线性函数。
BP 算法的训练过程包括输入信号的正向传播和输出误差的反向传播两个过程。BP 算法首先进行输入信号的正向传播。输入的样本首先进入网络的输入层,经中间隐含层的分析计算处理后,进入输出层得到样本训练输出结果。 如果网络最终输出与网络期望输出值(导师信号)存在误差,那么就进行误差的反向传播。 误差的反向传播首先将误差按照一定的学习算法整理成相应的形式, 由隐含层传播至输入层,并将误差分配给各层的所有神经元上,从而获得各层神经元的误差信号,此误差信号即作为修正各神经元权值的依据。 这种权值修正的过程,也就是网络的学习训练过程。这种过程不断迭代,最后使得误差信号达到允许的范围内。
在BP 神经网络预测前,首先要训练网络,通过训练使网络有联想记忆和预测的能力。 具体的步骤如下:
第一步:设置好已知参数,包括目标输出、预期平均误差、隐含层的数量与神经元个数、输出层的神经元个数、各层的权值与阀值等。
第二步:数据归一化。在设定好各种参数之后,确定每一样本的参数。 每一样本的每个数据作为输入层神经元,所有样本计算做为一个学习周期,为了使网络能更快地收敛,应该将输入层神经元归一化,即将其按照式(1)转换为(0,1)之间的值,其中x 是样本数据。

第三步:确定样本数据之后,通过每一个样本数据对网络进行的计算。 计算时首先将输入层神经元按照式(2)计算出隐含层输入,其中h 表示隐含层,k 表示第k 个样本,wih表示第i 个输入层神经元与第h个隐含层神经元之间连接的权值,bh表示隐含层第h 个神经元的阀值。 计算隐含层输入之后通过可导函数(一般选择sigmond 函数,如式(3)所示,其中x 表示隐含层输入)处理得出隐含层输出;将第一层隐含层的输出作为下一隐含层的神经元进行下一隐含层输入计算,在通过可导函数处理得出下一层隐含层的输出如此反复计算,直至隐含层全部计算完;

第四步:误差计算,更新权值和阀值。
第五步:判断误差是否符合预定要求,若符合,则停止迭代;否则转第二步。
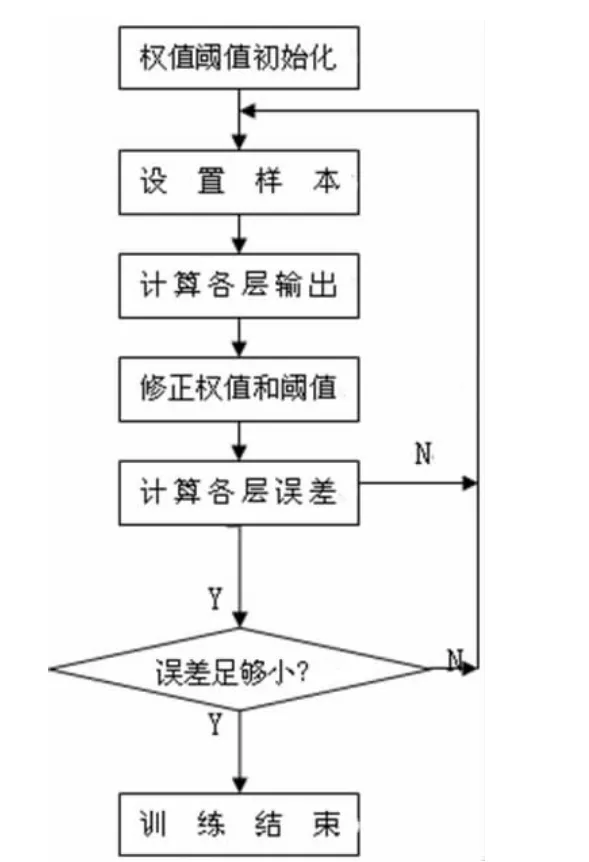
图1 BP 神经网络流程图
2 人口预测
2.1 数据来源
为了验证神经网络模型在人口预测中的效果,本文采用的我国人口数据均来自1995 -2012 年的《中国统计年鉴》,具体数值如表1 所示。 我们将数据分为两部分,1995-2008 年作为训练样本,2009-2012年作为测试样本。
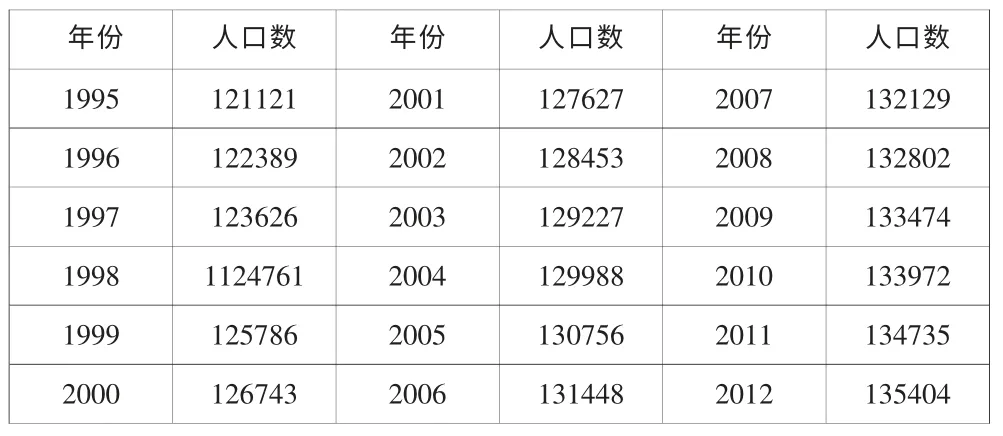
表1 1995-2012 年我国人口数据统计(年/万人)
2.2 BP 神经网络拓扑结构的确定
如果隐含层神经元数目过少,网络很难识别样本,难以完成训练,并且网络的容错性也会降低;如果数目过多,则会增加网络的迭代次数,从而延长网络的训练时间,同时也会降低网络的泛化能力,导致预测能力下降。在选择隐含层层数时要从网络精度和培训时间上综合考虑。在具体设计时,首先根据经验公式初步确定隐含层神经元个数,然后通过对不同神经元数的网络进行训练对比, 再最终确定神经元数。通用的隐含层神经元数的确定经验公式有:

其中i 为隐含层神经元的个数,n 为输入层神经元的个数,m 为输出层神经元的个数, a 为常数且1<a<10 。 则在本文中,经过不断的模拟实验,以出错率、偏差值、训练次数、时间作为成功与否的3 个判断条件,当3 个条件都符合的时候即为符合条件的神经网络。 从符合条件的多个神经网络中挑选出最佳的一组,最终将隐含层节点数确定为3 个(即网络结构为1-3-1),输入层转移函数确定为tansig,输出层函数确定为tansig。学习次数为1000 次,学习函数为默认函数,训练函数为trainlm 函数,训练次数为500 次。

图2 BP 神经网络数据训练图
2.3 人口预测结果
由图2 可知,神经网络很快就训练收敛了。 经过多次训练和学习,得到BP 网络的预测值。 预测结果是2009-2012 年人口预测数量分别为:133487,133985,135139,135431.(单位:万人)。
2.4 结束语
将BP 预测值与实际值做比较, 2009-2012 年的相对误差为0.01%、0. 01%、0.3%、0. 009%.
BP 网络预测结果表明, 比其他数学方法预测值更接近实际值.这是因为我国的人口数量受多种因素的影响,人口的增长呈非线性局势, 而BP 网络的优点就在于它的非线性趋近性和泛化能力。 本文采用自适应学习速率和附加动量法相结合的方法, 比应用单一的方法效果要好很多。 BP 网络具有它的局限性, 隐含层的设计是人为设定的,这样很容易造成误差。 因此, 如何更好的将BP 网络与其他神经网络结合起来应用于人口预测系统, 是我们以后努力的方向。
[1]王晓龙,杨广,张保华.灰色及其改进模型在人口预测中的应用[J].世界科技研究与发展,2009,31(4):757-758.
[2]蒋超,杨琳,付敏.中国人口预测的数学模型[J].内江师范学院学报,2008,3(12):33-35.
[3]邢立远,黄东伟,曹宇.BP 神经网络在中国人口预测中的应用[J].纺织高校基础科学学报,2010,23(3):386-388.
[4]陈虹,田八林.径向基函数网络在陕西省人口预测中的应用[J].现代电子技术,2005,28(23):91-92.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
自然杂志(2021年6期)2021-12-23
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
空间科学学报(2020年4期)2020-04-22
电子制作(2019年10期)2019-06-17
现代装饰(2018年5期)2018-05-26
自动化学报(2017年7期)2017-04-18
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
建筑材料学报(2014年4期)2014-03-11
