
基于几何统计差异性的伪造印鉴识别方法
2014-12-23 01:16:34胡建颖郎海涛
计算机工程与设计 2014年9期
胡建颖,赵 荻,周 玲,郎海涛+
(1.北京化工大学 理学院,北京100029;2.中国专利技术开发公司,北京100080)
0 引 言
自动的伪造印鉴识别方法研究需要解决几个主要的技术难点问题:①从印鉴文件中提取待分析的有效印文是印鉴识别的一个关键环节,有效印文提取的质量直接关系着最终的真伪识别结果[1,2]。由于印鉴文件的多样性,如图1所示,有效印文背景中可能包含图表、文字、嘈杂纹理等复杂情况,这些都为有效印文的高质量提取制造了很大的麻烦。②伪造印鉴与真实印鉴十分相似,尤其是高仿印鉴,在结构、细节等方面都会仿造的极其相近,因此印鉴的识别方法必须同时从全局 (结构)和局部 (细节)两方面入手,才能达到目的。③由于盖印条件的差异性而引起的印鉴差异性为印鉴的识别带来了实际的困难。例如,即便是同一个印章,如图1 中b和g,由于着 (印)泥的多少不同,或者盖印的力度不同,会导致印鉴出现很大的差异,甚至会导致盖印不全等情况的发生。印鉴识别系统必须要能够处理由于上述各种差异性而带来的挑战。
国内外的研究人员针对上述不同问题,提出了多种解决方案[3-7]。针对有效印文的提取问题,张学东等[3]将印鉴图像从RGB彩色空间转换到HSI彩色空间,通过分别对H的余弦值,S,I设定阈值,提取到了印文区域;Pan等[6]将印鉴图像分为印文区域和非印文区域,利用这个2个区域像素在HSV 空间的颜色分量作为训练向量,训练SVM。最后将待检测印鉴的每个像素的颜色分量放入SVM 中判断像素是否属于印文区域,对于印文区域进行保留,非印文区域置0。

图1 印鉴数据库中的部分印鉴
当有效印文从印鉴背景中被分割出之后,现有的方法通常采用将该印文与已有标准真实印鉴的印文比较的方法进行真伪识别,因此需要首先将待分析印文与真实印文进行对齐 (alignment),这要通过一个平移+旋转的变换实现。梁吉胜等[8]计算印鉴图像几何中心,并将印鉴图像由直角坐标系变换到极坐标系,利用设计的8种不同频率的辐射状模板分别与预留印鉴和待检验印鉴做卷积运算,运算时模板中心必须与印鉴的几何中心重合。依据卷积结果设计目标函数,通过对目标函数求极小值寻找到最佳对齐旋转角度。
在图像对齐之后,需要对对齐后图像进行鉴别,判断其是否属于真实印鉴。文献 [9]对于对齐后的图像计算不重合的对应边缘之间的距离和它们的长度,根据这2个参数是否超过阈值来鉴别印鉴的真伪。
本文提出了一种同时攻克上述3个难点问题的自动的伪造印鉴识别方法。该方法将有效印文的提取以及真伪印鉴的识别2个核心任务建立在有监督分类框架下。大量的统计结果表明,伪造印鉴不能在全局结构与局部细节上同时做到与真实印鉴的一致性,基于这一事实,本文采用由局部特征匹配点生成的结构线的几何一致性作为真伪印鉴的评价判据,为了提高算法的鲁棒性以及使其更适应实际应用情况,方法利用待验印印鉴与真实印鉴多次盖印的一致性程度生成分类向量。本文所提出算法的流程如图2所示,具体方法将在接下来的各章中详细介绍。
1 数据库
本文所提出的有效印文的提取方法,以及基于几何一致性的印鉴识别方法都建立在有监督分类的框架体系下。这种方法需要预先构建包含正负样本的数据库,出于研究目的,本文构建了 “印鉴印文数据库”和 “有效印文提取数据库”。
1.1 印鉴印文数据库

图2 方法流程及示例
数据库中包含真实印鉴1000 个,伪造印鉴2000 个,总计3000个印鉴图像。每个真实印鉴印文都有相对应的不同数量的伪造印鉴印文图像。考虑到实际应用中,盖印文件类型多样 (如表格,图文,颜色等的差异),盖印条件千差万别 (如盖印力度,印章着泥多少等),甚至图像采集系统的光照差异等情况导致的印鉴印文图像的变化。该数据库包含印章在各种不同盖印条件下生成的印鉴图像。数据库的部分示例如图1所示,其中左侧三列为真实印章盖印得到的印鉴,右侧两列为伪造印章盖印得到的印鉴。
1.2 有效印文提取数据库
有效印文的提取属于图像分割范畴,本文的方法不同于之前的工作,将印文的提取建立在分类框架下,通过对有效印文和印文背景的联合学习,构建分类器,从而完成有效印文提取工作。基于如1.1节所述的印鉴印文数据库,将印文和背景分离开,构建有效印文提取数据库,构建过程中重点考虑了存在同色印泥差异的印文,存在图像采集系统光照差异的印文,以及复杂文件背景等情况。图3给出了该数据库的一部分例子,其中第一行为图1中第一行各印鉴的背景,第二行为对应的有效印文。
图3 有效印文提取训练数据库
2 有效印文提取
有效印文的提取是印鉴真伪识别任务的第一步,也是尤为关键的一步,有效印文提取质量的高低直接决定着真伪评价的成败。由于印文颜色的特殊性,基于颜色的方法是当前印文分割的常用方法,已有方法通常通过将图像某像素在某个颜色空间的值与预先给定的局部阈值或者全局阈值进行比较,从而判断其是否属于有效印文。分割阈值的选取通常采用经验值,或者根据颜色理论计算得到。本文提出的方法基于分类框架,对于图像I中某个像素xi=x(hi,si,vi),xi∈I,其中x(hi,si,vi)表示xi在HSV 颜色空间中对应分量hi,si,vi所构成的向量,本文用该向量描述像素。颜色提取问题转化为分类问题

当yi=1则xi为有效印文,yi=-1,则xi为背景,其中f_ext(.)表示有效印文分类器,它通过有效印文提取训练数据库学习得到。为了得到f_ext(.)本文从如图3所示的正样本数据库中提取了100 000个训练样本,采用如上所述的HSV 颜色空间向量表达,并赋予这些样本类标+1。同理,从负样本数据提取了100 000个背景训练样本,赋以类标-1。采用libSVM[10]实现了SVM 分类器,2个参数c,g采用5-fold交叉验证 (5-fold cross validation)的方法优化得到。图6给出了对几个印鉴的有效印文提取的结果图(未经任何其它图像处理的原始提取图),从中可以看出,该方法能够在复杂背景条件下,准确提取出有效印文。
3 基于几何一致度统计有监督分类的伪造印鉴识别方法
3.1 基于局部匹配特征生成线的几何一致度统计
如图2所示流程,当待验印鉴的有效印文从盖印文件中提取出来之后,首先提取待验印鉴和数据库中与待验印鉴具有相同印文的在不同盖印条件下获得的真实印鉴 (已提取出有效印文,本文采用9个)的局部特征点。本文采用SIFT 特征点提取及描述方法,SIFT (scale invariant feature transform)[11]特征具有尺度、光照、旋转等不变性,是当前获得成功应用的一种典型局部特征描述符。由于印鉴图像在采集过程中不存在尺度变化,因此本文主要利用了SIFT 特征的光照和旋转不变性,前者赋予了实际应用中图像采集部分一定的光照变化富裕度,后者则使本文方法回避了复杂的印鉴对准过程。
当待验印鉴与数据库中真实印鉴的特征提取完成后,将待验印鉴的特征与每个真实印鉴分别进行匹配,得到匹配特征点对,如图2所示。待验印鉴中的特征点与第一个真实印鉴中的匹配,获得所有的匹配点后 (例如,Pi_1与Pr_1匹配,Pi_2与Pr_2匹配),随机生成10条匹配特征线,如Li12=d(Pi_1,Pi_2),其中函数d(.)表示计算点Pi_1,Pi_2之间的像素长度。当待验印鉴与真实印鉴1的对应匹配生成线计算完成后,比较各对应生成线几何特征的一致性,采用规则为,当式 (2)成立时,认为这2条线具有几何一致性
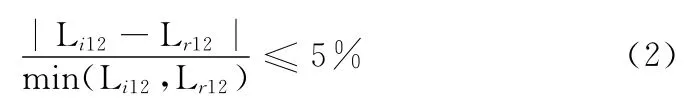
最后计算几何一致的生成线数与所有生成线的比例,得到待验印鉴与真实印鉴1之间的几何一致度,如图2所示,待验印鉴与真实印鉴1之间的几何一致度为0.75,也就是说2个印鉴间有75%的匹配生成线被认为是几何一致的。同理计算待验印鉴与其它真实印鉴的几何一致度,将各几何一致度数值生成向量得到基于几何一致度统计的印鉴表达。
式 (2)中选择的5%为经验值,出于如下考虑:印鉴长与宽的平均大小均为15mm,所对应的采集图像大小为700×700像素,印文区域处于图像中心大小为500×500像素。最长的匹配线不会超过400像素,两条匹配线所允许的最大差异为5%×400=20 像素,大约是 (15/500)×20=0.6mm,即我们要求真假印鉴的字符间距布局不能有0.6mm 的区别。这样的精度范围即使是高仿印鉴也很难达到。
另外需要说明的是,由于盖印条件的不同,各印鉴中所能提取的SIFT 特征点的数量是不等的,比如某些印鉴由于盖印原因明显缺失了一部分,就仅能提取出少量特征点,而匹配的特征点数会进一步减小。本文方法的一大优势体现在,即使在这种情况下,本文方法也可以通过少量匹配的特征点 (大于等于5个匹配点,即可随机生成10条匹配线)生成线的一致性做出真伪判断。而且多特征线比较结果与多印鉴统计结果的联合使用进一步增强了本文方法的鲁棒性。如图4所示,图中为部分正确识别的有缺失的印鉴图像。

图4 正确识别的有缺失的印鉴图像
3.2 方法的可行性依据
本文所提出的方法建立在大量统计分析结果之上,这里给出本工作预研阶段所进行的一些统计分析结果,说明方法的可行性。本文方法的理论依据建立在伪造印鉴不能在全局结构与局部细节上同时做到与真实印鉴保持一致,为此本文进行了大量的统计分析,评价该依据的可靠性。以图1中三组 (a vs.m,d vs.n,g vs.l)真伪印鉴对为例,图5给出了它们分别与对应的真实印章的9次不同盖印印文的几何一致度曲线,从中可以看出,真实印鉴 (a,d,g)与各真实印鉴之间的几何一致度 (黑色曲线)普遍高于伪造印鉴 (m,n,l)与各真实印鉴的几何一致度 (灰色曲线),尽管存在个别差异 (如a和m 在第8个盖印上的结果,g和l在第5个盖印上的结果),但是在统计上这种差异性是显著的。本文的方法就是建立在这样的统计事实基础上的。
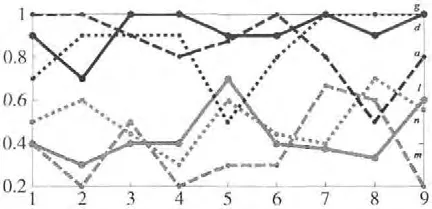
图5 方法可行性分析示例
3.3 真伪印鉴识别分类器
本文采用了简单的K最近邻(K-nearest neighbor,KNN)分类器作为真伪印鉴识别分类器。KNN 是一个理论上较为成熟的方法,它的思想简单直观:在样本空间里寻找与测试样本最近邻的K 个数据,这些数据的大多数属于哪一类别,就判断测试样本属于哪一类别。如下公式计算
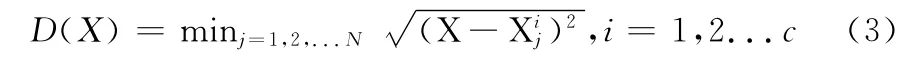
式中:X——测试样本,Xj——样本空间内的样本,共N个,上标i表示类别。K 个最近数据中,i的哪个值最多,测试样本就属于哪一类别。真伪印鉴的识别是个两类问题(c=2),我们将数据库中所有真实印鉴与对应的真实印章的9次不同盖印印文的一致度构成一个正样本的一致度表达,并赋予类标+1 (如图5中黑色线所示),同理将伪造印鉴与对应的真实印章9次盖印印文的一致度构成负样本的一致度表达,并赋予类标-1 (如图5 中灰色线所示)。采用上述公式计算待验印鉴的一致度表达与数据库中各印鉴一致度表达的欧式距离,根据最近邻的K 个样本的类标的多数类评价待验印鉴的真伪。
4 实验验证
4.1 有效印文的提取
本实验验证了本文所提出的有效印文提取方法的准确性,实验从数据库中随机选择两组印文,每组各包含10个印鉴,第一组印鉴均盖印在白色背景文件中,第二组印鉴均盖印在具有复杂背景的文件中。采用本文方法提取的有效印文准确率通过如下公式计算
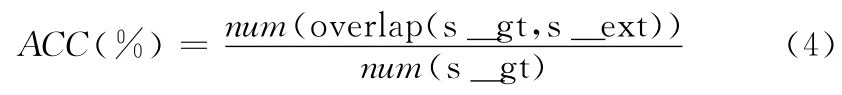
式中:s_gt、s_ext——groundtruth有效印文、提取的有效印文,函数overlap (.)计算2个印文的重叠区域,函数num (.)计算像素数目。提取的实例如图6所示,第一行为从白色背景文件中提取的印文,第二行为从复杂背景文件中提取的印文。

图6 有效印文提取实例
表1给出了具体的提取准确率数据,从中可以看出,对于白色背景,本文算法可以非常准确的提取有效印文。对于复杂的背景,算法也给出了非常高的提取精度。最坏的情况出现在图6第二行中间图所示的结果,提取的准确率为89.02%,主要原因在于该文件的背景颜色与印泥的颜色非常接近。但是由于大量的错误发生在背景区域,即将不属于有效印文的部分当作有效印文被提取,如3.1和3.2节所述,这些错误提取的印文很少 (或者基本不会)与真实印鉴的有效印文形成匹配的特征,因此对于真伪识别的影响不大,这一结果可以通过4.2节得到的结果看出。

表1 提取精度
4.2 伪造印鉴的识别
本文采用了与文献 [2]相似的评价方法进行了评价。文献 [2]采用了①正确检测率 (CR);②错误接受率(FAR);③错误排除率 (FRR);④模糊概率 “ambiguity rate”(AR)等4个标准进行了评价。由于本文采用两类分类器,不会做出无法判断的结论,因此未采用④标准。CR,FAR,FRR 按如下公式计算
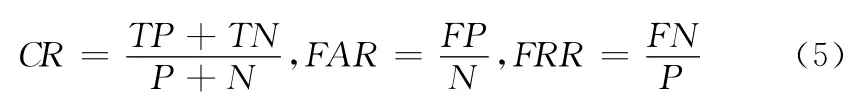
式中:P,N——真实印鉴与伪造印鉴的个数,TP,TN——正确识别的真实印鉴与伪造印鉴的个数,FP,FN——错误识别的真实印鉴与伪造印鉴的个数。
实验结果见表2,从中可以看出本文提出的方法的错误接受率为0%,即所有的伪造印鉴均被识别出。错误排除率为5.50%,36个真实印鉴有2个被误判为伪造印鉴。主要是由于背景与印鉴颜色太过相近,在提取过程中印鉴的部分信息被破坏导致的。并且正确识别的印鉴包含图4中有缺失印文的图像。可以得出,本文方法对于部分缺失印文的图像就有很好的鲁棒性。
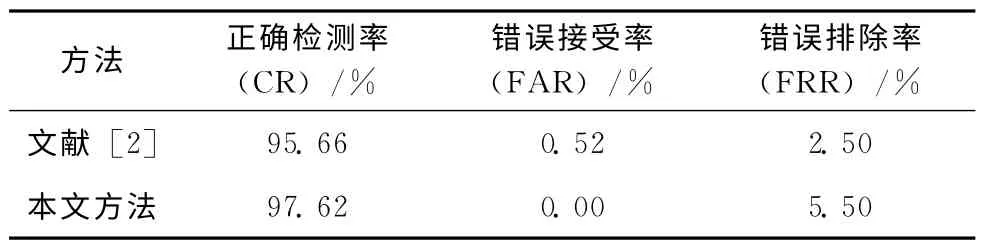
表2 检测精度
5 结束语
本文提出了一种建立在真伪印鉴几何一致性统计差异上的伪造印鉴识别方法,系统研究了有效印文的提取方法以及真伪印鉴的识别方法,通过将这2个难点问题建立在有监督学习框架下,同时提高了有效印文提取的精度,以及对伪造印鉴识别的精度。本文的主要贡献体现在3个方面:
(1)本文出于研究的目的,建立了印鉴识别数据库,这是目前已知的规模最大的,盖印情况最丰富的数据库。如图1所示,通过增加盖印文件背景的复杂性,以及盖印的差异性,我们有意识的增加了印章印文提取,以及相关的印鉴识别问题的研究难度,使所提出的研究方法更能适用于实际情况。
(2)本文所提出的方法,通过匹配的局部特征点(SIFT)直接生成待检验的线,因此不需要图像对齐这一过程,在减少了算法复杂度的同时,也避免了由于对齐不准而引起的误判等情况。另一方面,该方法通过计算特征点的匹配获得了印鉴的局部信息,通过匹配特征点生成的线获得了印鉴的结构信息,因此同时做到了从细节和结构两方面对印鉴进行分析,从而提高了伪造印鉴识别的精度。
(3)与现有方法经常采用的将待验印鉴与一个标准印鉴进行比较的方法不同,本文方法将待验印鉴与多个真实印鉴多次盖印的印文进行一致性比较,以一致度的统计结果评价待验印鉴的真伪。这一做法允许待验印鉴发生盖印的差异,增强了算法的鲁棒性。
从本文的工作以及现有的一些论文的情况看,如图1g,以及图6中第二行中间的图所示的提取结果,以及实验中所反映的由此导致的两个错误排除情况,当印鉴被盖印在颜色与印泥颜色非常接近的文件上时,基于颜色空间的提取方法将受到很大的影响,因此在今后的工作中,我们将从新的角度对该问题进行进一步的研究。目前系统框架不包含表单的表格线颜色恰好与印泥颜色相似的情况,该种情况复杂且极具挑战性,我们会进一步研究试图解决此问题。
通过引入专家决策机制,对一次鉴别结论 (如本文方法)进行二次分析,进一步减少错误排除以及错误接受情况的发生,也是我们下一步工作的重点。
[1]ZHU Junchao.Research on recognition method for verification of circle seal stamped on finance note [D].Tianjin:Tianjin University,2007 (in Chinese).[朱均超.金融票据圆形印鉴真伪识别方法研究 [D].天津:天津大学,2007.]
[2]Lang H T,Xie C R,Qi X,et al.Seal forgery detection by geometric consistency [C]//Proceedings of Information:An International Interdisciplinary of Journal.Japan:International Information Institute,2012:3695-3699.
[3]ZHANG Xuedong,PAN Xiaohong.Least square method based repairing method for broken seal imprint contour[J].Computer Engineering and Design,2009,30 (20):4693-4696 (in Chinese).[张学冬,潘晓红.基于最小二乘法的印鉴缺损轮廓 修补法 [J].计算机工程与设计,2009,30 (20):4693-4696.]
[4]DAI Xinliang,SUN Weizhen.Image pre-processing study for seal verification [J].Microcomputer Information,2007,24(27):305-306 (in Chinese).[戴新亮,孙卫真.印鉴识别中图像预处理问题的研究 [J].微计算机信息,2007,24 (27):305-306.]
[5]CHU Changqing.An authenticity verification technology of bank seal[J].Computer CD Software and Applications,2012(5):132-132 (in Chinese).[储常青.银行业印章真实性验证技术研究 [J].计算机光盘软件与应用,2012 (5):132-132.]
[6]Pan W,Hu J.Seal imprint segmentation based on color feature classifier[C]//International Conference on Proceedings of Audio,Language and Image Processing.Shanghai,China:IEEE,2012:837-840.
[7]Wang X,Chen Y.A novel seal imprint verification method based on analysis of difference images and symbolic representation [G].LNCS 6540:Computational Forensics,2011:56-67.
[8]LIANG Jisheng,WU Yajuan.Registration method based on the radial template[J].Journal of Daqing Petroleum Institute,2011,35 (4):87-90 (in Chinese). [梁吉胜,吴亚娟.基于辐射状模板的圆形印章配准方法 [J].大庆石油学院学报,2011,35 (4):87-90.]
[9]HE Jin,LIU Tiegen.Automatic seal identification using edge difference [J].Chinese Journal of Scientific Instrument,2010,31 (1):85-91 (in Chinese).[何瑾,刘铁根.基于边缘差异的印鉴自动鉴别 [J].仪器仪表学报,2010,31 (1):85-91.]
[10]Lin Chih-Jen.LIBSVM [EB/OL]. [2011-12-01].http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
[11]Lowe DG.Distinctive image features from scale-invariant keypoints[J].Int’l Journal of Computer Vision,2004,60(2):91-110.
猜你喜欢
皮革科学与工程(2023年6期)2023-06-03 05:20:21
法制博览(2020年19期)2020-07-01 12:12:04
职工法律天地·上半月(2018年22期)2018-11-21 09:20:30
计算机与数字工程(2018年2期)2018-03-20 07:07:23
中国司法鉴定(2017年6期)2017-12-06 07:58:59
大陆桥视野·下(2016年10期)2016-12-16 08:54:54
决策与信息(2016年32期)2016-11-26 11:04:26
法制博览(2015年30期)2015-02-06 20:25:56
档案管理(2014年6期)2014-10-30 21:33:25
自动化与信息工程(2012年5期)2012-09-29 03:19:16
