
基于纠删码的动态副本冗余存储研究
2014-12-23 01:18:54郑志蕴孟慧平王振飞
计算机工程与设计 2014年9期
郑志蕴,孟慧平,李 钝,王振飞
(郑州大学 信息工程学院,河南 郑州450001)
0 引 言
目前,云存储中数据冗余存储技术主要包括副本冗余和纠删码冗余两种技术。副本冗余存储设计简单,支持高并发访问,但消耗空间大;纠删码机制虽然能够节省存储开销,但造成了读数据性能的下降[1]。本文在分析现有冗余存储方案的基础上,从存储开销和访问质量等方面考虑,提出一种基于纠删码的动态副本冗余存储方案DRBEC(dynamic replication based on erasure codes),将纠删码策略和副本策略合理结合,在尽量减小空间消耗的同时,提高系统的访问效率。
1 相关技术和研究
副本冗余和纠删码冗余采用完全不同的方式对文件数据进行冗余存储。副本冗余策略是对文件进行简单的复制后,将各个副本文件分别存储在不同的集群节点服务器上,进行多副本静态保存,提高系统的容错能力、提升数据资源的使用效率和数据的访问性能。纠删码冗余策略则是将文件分割后进行编码冗余保存。基于纠删码的容错技术可以简单记为 (n,k,t,Q),其编码使用过程为:
(1)将待存文件数据分为k个分片;
(2)将k个分片进行冗余编码,生成n (n>k)个冗余分片,并且将它们分别存储在不同的服务器节点上;
(3)当用户访问或者修复数据时,从n个分片中选取t(k≤t<n)个有效分片,从每个分片上下载Q 比例的存储量来进行译码,恢复原文件数据。
云存储中最常用的纠删码为 RS (reed-solomon codes)[2]纠删码,它是一种线性编码,可记为 (n,k,k,1),即译码时需要下载k个完全分片。考虑到修复网络带宽问题,Dimakis等人在Infocomm 会议中提出的一种基于网络的新型纠删码——再生码 (regenerating codes,RC)[3]。RC码的参数表示为 {[n,k,d], (α,β,B)},将大小为B的文件编码存储在n个节点上,每个节点存储α数据量,修复节点时连接任意存活的d (k≤d≤n-1,系统节点k为修复节点的最小连接个数)个节点,每个节点的下载量为β(β≤α),节点的修复带宽为γ=d·β。
相同冗余度情况下,纠删码消耗的空间比纯副本方案更小,容错能力较强,空间利用率高[4]。卡内基梅隆大学的PDL (parallel data lab)实验室提出了DiskReduce[5]的系统方案,采用异步编码方式,先将文件进行3倍副本的存储,之后在后台进行编码,利用多副本的高效访问来提高系统的I/O 吞吐量和计算并行性。DiskReduce考虑到系统的访问效率和存储消耗,但仅以时间关系来判断编码的时机,没有提出更好地编码机制。文献 [6]提出了一种改进方案Noah,该方案基于编码策略和动态副本策略的结合,将编码后的分片进行冗余存储,实时监控文件的访问频度,并根据需求动态改变分片副本的数量和位置,有效减少空间的浪费、改善了系统的负载均衡能力,但用户的访问仍然需要译码开销。现有研究结果表明,由于网络问题而致使用户无法接入集中式服务的时间达1.5%~2%[7],这种实时监控下进行的动态调整没有考虑网络延迟给用户访问性能造成的影响。
文献 [1]中,作者经过实验结果表明副本数量的增加会显著提高读数据的吞吐量。根据一些行业报告,云存储中有70%以上的数据是被静态存储的,很少甚至可能不会再被访问,对于静态存储的数据若用副本方案存储会浪费大量的存储空间。
综上所述,本文结合纠删码和副本策略的优缺点,提出一种基于纠删码的动态副本冗余存储方案DRBEC,在纠删码策略的基础上使用副本策略,并动态调整副本的数量。
2 DRBEC方案
本文提出的基于纠删码的动态副本冗余存储方案DRBEC,其基本设计思想如下:
(1)首先,在未知文件使用热度的情况下,通过对RS码和RC码的比较,创新地使用RC码对文件进行编码,实现文件的编码冗余存储;
(2)其次,根据文件的访问记录,预测其访问热度,再结合系统当前的状态,在纠删码的基础上增加原文件的副本存在形式,并动态调整原文件的副本数量。
对于静态文件,系统将它们以纠删码的方式冗余存储,用较小的空间消耗保证了数据的可靠性;对于访问频繁的热点文件,系统根据其访问热度将文件还原后,适时调整原文件副本的数量,从而提高用户的访问质量。
2.1 基于RC再生码的编码冗余存储
云存储中,使用纠删码冗余策略来存储数据,可以高效的利用存储空间保证系统的可靠性,但编码和译码过程将带来不容忽视的带宽消耗问题。云计算环境下,带宽消耗应作为纠删码设计主要关注的指标[8]。
2.1.1 RC码的带宽优势
RC码是一种基于网络的编码。最小存储量的RC 编码称为MSR (minimum storage regenerating)编码,对于大小为B的文件,节点存储量αMSR=B/k,修复带宽γMSR=B*d/ (k*d-k2+k)。相比RS编码,RC 编码拥有更小的恢复带宽。MSR 编码与RS编码的比较结果见表1。
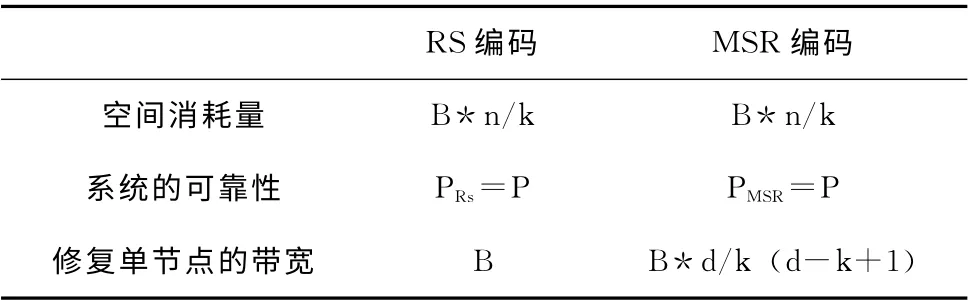
表1 MSR 编码与RS编码的对比
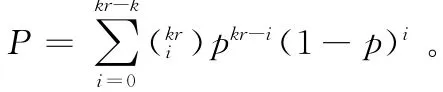
从表1中可以看出,RS编码与MSR 编码的空间消耗和系统可靠性是相同的。当d=k时,MSR 编码的修复带宽与RC码的修复带宽相同,即γMSR=γRC=B;但当d>k时,修复带宽γMSR<γRC=B。MSR 编码的修复带宽与连接节点个数d的关系如图1所示,当d-k>0时,MSR 编码的修复带宽远远小于RS编码,并且随着连接节点d-k值的增大,节点的修复带宽减小。
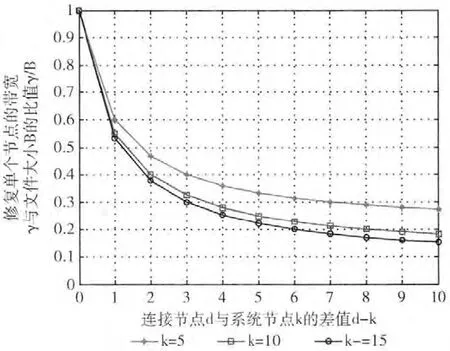
图1 MSR 编码的修复带宽消耗与d-k值的关系
2.1.2 基于RC码的分组编码存储
在使用纠删码进行文件冗余存储时,通常是将整个文件分片后直接进行编码存储,导致文件更新时需要将整个文件还原更新后重新编码。为了降低用户更新数据引起的重新编码开销,本文中对文件进行RC 码编码时提出先分组后编码的思想:将文件分片后分为两组,最后一个分片作为单独一组进行多副本保存,其它分片作为另一组进行纠删码编码冗余保存。文件更新时,只需追加到最后一个分片上,对最后一个分片的各个副本进行更新,而无需对整个文件进行重新编码。
Rashmi等人在文献 [9]中给出RC码的最小存储量编码方案PM_MSR:令β=t,取d=2k-2,则B=k* (k-1)*t,α= (k-1)*t。基于PM_MSR 方案的RC 码分组编码算法如下:
(1)将原文件分为k* (k-1)+1 个分片:b1,b2,…,bk(k-1),bk(k-1)+1,将前k* (k-1)个分片划分为组B1,最后一个分片bk(k-1)+1划分为组B2;
(2)将B1组中各个分片进行条带化,用向量珚B= [b1,b2,…,bk(k-1)]表示。取珚B 的前 (k-1)*k/2个分片构成的 (α×α)矩阵X 的上三角部分,且XT=X。B1组剩余的分片构成 (α×α)矩阵Y 的上三角,且YT=Y。定义 (d×α)的数据矩阵为

(3)定义基于有限域Fq上运算的范德蒙德修复矩阵R= [ф Λф],ф是 (n×α)维矩阵,Λ为 (n×n)的对角矩阵,其对角线元素互不相同,且矩阵R 的任意2α行线性无关、Λ的任意α行线性无关;
(4)RC码编码矩阵为C(b),且有

第i行的编码向量Ci=Ri·D(b),由节点i存储。
如图2所示,当还原文件时,先还原组B1数据。由任意k个节点得到C(b)的k行向量,组成 (k×d)矩阵。由式 (1)和式 (2)可知Rk·D(b)=Wk·X+Zk·Y。由于矩阵R 的任意2α行线性无关,且矩阵X 和Y 为对称矩阵,可以解出矩阵X 和Y,从而得到D(b)并还原出珚B= [b1,b2,…,bk(k-1)]。得到B1组数据后,将恢复出的B1数据与B2组数据的副本结合,从而还原出整个原文件。而修复失效节点时,则从剩余有效节点中任选d个节点获取γ=d·β的有效数据来精确恢复失效节点。

图2 基于PM_MSR 分组编码的数据重构过程
2.2 动态调整文件副本
文件上传后,如果单纯以纠删码方式存储文件,其提供访问的能力有限,并且用户访问延迟过大。因此当文件访问热度增加到一定程度后,本文通过调整原文件的副本数量来保证用户的访问质量。对于云存储这种特殊服务,在网络传输带宽和磁盘I/O 带宽有限的情况下,通过预测来寻找合适的副本创建时机,可以提高系统的整体性能。
2.2.1 文件热度预测
将文件的周期访问量按时间排列后呈现时间序列,一份文件相近周期的访问量具有相似性,随着文件创建时间的推移,文件的访问热度呈现先上升后下降的趋势[10]。因此本文采用基于多项式的非线性曲线拟合预测方法来预测文件的访问热度,根据历史记录对时间序列值进行多项式拟合,得到被测对象的发展趋势,从而预测下个序列值。多项式曲线拟合模型为

将访问量按观察周期T 的先后列为时间序列,得到自变量和因变量的n个观察值为:x11,x22,x33,…,xTn和y(T1),y(T2),y(T3),…,y(Tn),则输入矩阵X 和Y如下

系数矩阵β= [β0β1… βn],由式 (3)知Y=X·βT,从而求出β,得到时间序列的拟合曲线。
不同时间段,用户对于数据的访问热度呈现波动现象。对文件周期访问量的时间序列,将Tn+1前的n个周期T1,T2,T3,T4,T5,…,Tn的周期访问量进行t次曲线拟合,次数为t(t=2,3,4)的拟合曲线的拟合误差为
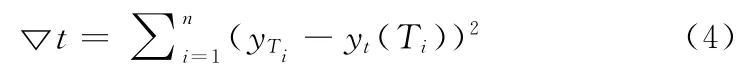
式中:yTi——周期Ti的实际访问量,yt(Ti)为Ti的拟合访问值。通过比较t,得到拟合误差最小的ts,其对应的拟合曲线为yts。则预测得到周期Tn+1的访问量为
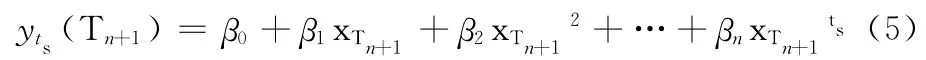
鉴于用户对文件访问的随机性,访问量在短期内随着时间呈现波动,如果仅仅通过n个观察周期拟合得到的整体趋势来进行预测,预测结果误差较大。本文对基于n个周期进行的简单曲线拟合预测方法进行改进,将预测周期Tn+1前的3个周期作为短周期进行小趋势预测,而后把该结果与基于n个周期的整体趋势得到的预测值进行加权平均,用近期小趋势预测值调整n个周期的大趋势预测结果,从而减小预测误差。
近期小趋势预测采用二次曲线的预测,其模型为
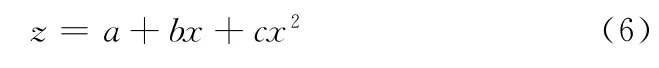
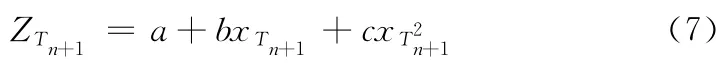
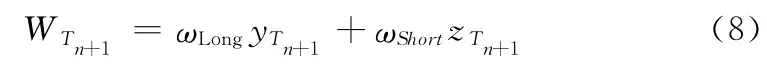
2.2.2 副本的动态生成和删除
对于云中的文件资源R,当实际访问量超过了云系统中R 所能提供的访问上限时,增加资源R 的副本数量,则可以增加R 提供访问的能力;若文件访问量减少,减少副本以减少存储开销。为此,本文结合2.2.1 小节给出的文件访问热度预测结果,动态管理副本的生成和删除。
用户在周期Tz中对资源R 访问总数WR(Tz)和文件当前的副本数量r(Tz)由主节点nameNode记录保存。R在服务器i上的副本或编码分片Ri的访问队列被记录在一张表中,由数据节点dataNode服务器i动态维护。将服务器i上Ri的周期访问量,即队列个数记为Ri(Tz)。在本文中,为了更加清晰的说明副本生成和删除时机的计算模型,特给出以下几个定义:
定义1 令η为存储资源R 编码分片的服务器节点集合,ε为拥有资源R 副本的服务器节点集合,δk(Tz)为服务器k在周期Tz内可响应的访问次数。资源R 以纠删码形式提供访问的上限为ζ(Tz),并且对任意i都有ζ(Tz)≤ζi∈η(Tz)。则资源R 的总访问上限为
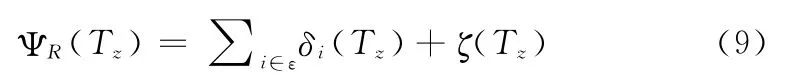
定义2 当文件基于 [n,k,d]MSR 编码时,周期Tz中文件冗余度MR定义为:MR(Tz)=n/k+r(Tz),其中r(Tz)为当前周期中文件R 的副本数量。则定义资源R 的副本价值系数为
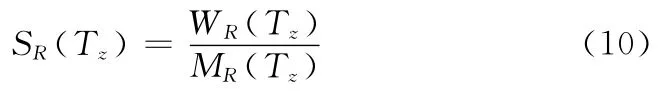
定义3 周期Tz中资源R 的访问权重函数定义为

式中:n——最近n个周期。则服务器i上资源R 的副本Ri的访问权重为
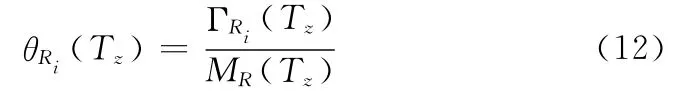
在判断副本的生成时机时,在周期Tz中根据式 (8)预测得到资源R 在周期Tz+1的访问总量WR(Tz+1),再由定义1中式 (9)计算出资源R 当前的访问上限ΨR(Tz),如果有WR(Tz+1)≥ΨR(Tz)时,表示在Tz的下个周期Tz+1中,对资源R 的访问量将大于系统当前所能提供的访问上限,则应该为资源R 创建副本。用户可以选择访问新增副本服务器上的资源R。
在定义删除副本的时机时,在周期Tz中,当由定义2中式 (10)计算出副本价值系数SR(Tz)≤1,即文件的访问量小于文件的冗余度,或者当系统检测到没有足够的存储空间时,需要选取适当的副本进行删除操作。由定义3中式 (11)和式 (12)计算各个副本资源的访问权重,按照最近最久不用 (least recently used,LRU)置换算法进行资源选取,选择权重θRi(Tz)最小的服务器上的副本资源对其进行懒惰删除,即仅将空间状态为标为可用,但仍保留其数据信息。当系统需要该空间时,才将磁盘信息进行彻底删除并用新数据覆盖。
3 仿真实验
为了验证本文提出的基于纠删码的动态副本冗余方案(DRBEC)的有效性,实验分为两部分,首先从网络上捕获数据,对改进的曲线拟合预测效果进行验证。其次,搭建集群实验环境,验证该方案在数据存储空间消耗和用户访问质量方面的效果。
3.1 改进后曲线拟合的预测准确度
实验数据基于对100个网络热点视频和热点文献 (每天访问量大于1000)的跟踪记录,设定周期为10min,记录这些文件的各个周期访问量。依据2.2.1 小节改进前和改进后的曲线拟合方法,对这些文件的周期访问量进行预测。图3展示了预测准确度大于80%的概率。
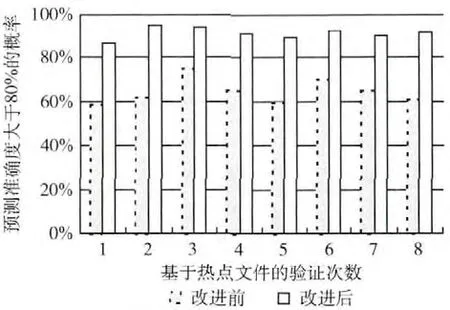
图3 2种曲线拟合预测准确度大于80%的概率
由图3可以看出改进前简单的曲线拟合预测的准确度达到80%以上的概率只有60%左右,而改进后利用大趋势和小趋势的结合来减小波动给预测结果造成的误差,使改进后的曲线拟合的预测准确度在80%以上的概率达到90%左右,远远大于改进前的简单曲线拟合。
3.2 集群环境下DRBEC方案的验证实验
基于Xen虚拟机搭建hadoop集群存储平台,1个name-Node和6个dataNode节点服务器使用内存为2G,硬盘为50G,系统为Red hat Enterprise Linux 5。使用Hadoop集群的基准测试系统SWIM (statistical workload injector for mapreduce)[11],根据Yahoo的2000个Hadoop集群节点1个月的历史信息,产生新的模拟数据访问程序,来访问系统中50GB的存储文件。在不考虑删除文件的情况下,图4展示了SWIM 进行基准测试时系统的空间消耗情况。
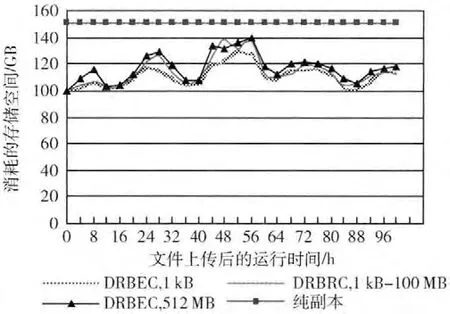
图4 系统存储空间消耗
对于冗余度r=3的纯副本方案,消耗的存储空间始终是原文件的3倍,大于150GB。而DRBEC 方案中,采用[n=5,k=3,d=4]的RC 码进行编码,由于采用分组编码,文件上传后最初消耗的存储空间100G。随后系统中一些文件的访问热度增加,文件的副本数量也随之改变,空间消耗呈现波动。当文件访问热度下降并趋于平稳时,空间消耗也下降趋于平稳,并且DRBEC方案整体空间消耗量远远小于纯副本方案。
在使用Apache组织开发的压力测试工具jmeter模拟用户对于热点文件的访问时,用户对不同大小的文件访问的平均延迟时间如图5所示。

图5 对不同大小文件访问的平均延迟
当热点文件的并发访问量很高时,Noah方案中动态副本策略采用实时监控方式,副本生成时的网络延迟影响用户的访问质量,而DRBEC方案预测文件的访问热度,针对预测结果提前更改文件的副本数量,有效减少了实时检测方式下网络和磁盘I/O 带来的延迟,提高了用户的访问成功率。
图6展示2种方式下对不同大小的文件访问成功率对比。随着文件的增大,访问延迟时间就越长,文件请求超过一定时间时,访问就失败,因此实时监控下文件创建的延迟造成不能及时响应用户的访问,降低了文件的访问成功率。而DRBEC方案下,由于预测而提前增加的副本服务器减小了文件创建延迟的影响,使用户的访问能够得到及时地响应,提高了用户访问的成功率。
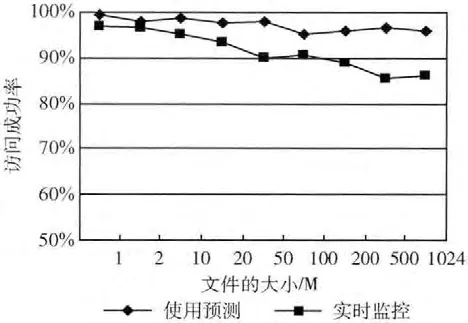
图6 对不同大小文件的访问成功率
4 结束语
本文针对单一冗余策略的不足,提出DRBEC方案,基于恢复带宽更小的RC 码冗余存储的基础上使用动态副本策略,采用预测得到文件的访问热度实时改变文件的副本数量。通过搭建原型系统的实验和分析结果表明,DRBEC方案能有效降低网络延迟和磁盘I/O 性能给用户带来的访问延迟,提高用户的访问质量,解决了冗余存储带来的空间消耗和用户数据的高可靠性、高效访问之间的矛盾。
在未来的工作中,将对DRBEC方案中数据存放的安全性做进一步研究,并且考虑系统的负载均衡问题,使存储系统更加可靠,为用户提供更加高效的访问,并在实际场景下对其效果进行测试。
[1]CHENG Zhendong,LUAN Zhongzhi,MENG You,et al.Research and practice on erasure codes in cloud [J].Computer Science and Exploration,2013,7 (4):315-325 (in Chinese).[程振东,栾钟治,孟由,等.云文件系统中纠删码技术的研究与实现 [J].计算机科学与探索,2013,7 (4):315-325.]
[2]DU Junchao,LIU Hui,LI Xiaojun,et al.The performance evaluation of the wireless sensor network information distribution protocol based on RS code[J].Computer Science,2011,38 (B10):315-318 (in Chinese). [杜军朝,刘惠,李晓军,等.基于RS纠删码的无线传感器网络信息分发协议性能评价[J].计算机科学,2011,38 (B10):315-318.]
[3]Dimakis A G,Godfrey P B,Wu Y,et al.Network coding for distributed storage systems [J].IEEE Transactions on Information Theory,2010,56 (9):4539-4551.
[4]Dimakis A G,Ramchandran K,Wu Y,et al.A survey on network codes for distributed storage [J].Proceedings of the IEEE,2011,99 (3):476-489.
[5]Fan B,Tantisiriroj W,Xiao L,et al.DiskReduce:RAID for data-intensive scalable computing [C]//Proceedings of the 4th Annual Workshop on Petascale Data Storage.ACM,2009:6-10.
[6]LI Xiaokai,DAI Xiang,LI Wenjie,et al.HDFS improvement system based on dynamic replication redundancy and erasure code strategy [J].Computer Application,2012,32 (8):2150-2153 (in Chinese).[李晓恺,代翔,李文杰,等.基于纠删码和动态副本策略的HDFS 改进系统 [J].计算机应用,2012,32 (8):2150-2153.]
[7]Bonvin N,Papaioannou T G,Aberer K.The costs and limits of availability for replicated services[C]∥ACDC,2009.
[8]Khan O,Burns R,Plank J,et al.Rethinking erasure codes for cloud file systems:Minimizing I/O for recovery and degraded reads[C]//Proc of USENIX FAST,2012.
[9]Rashmi K V,Shah N B,Kumar P V.Optimal exact-regenerating codes for distributed storage at the MSR and MBR points via a product-matrix construction [J].IEEE Transactions on Information Theory,2011,57 (8):5227-5239.
[10]DONG Jiguang,CHEN Weiwei,WU Haijia,et al.The research on load balance based on dynamic copy in cloud storage[J].Computer Application and Rearch,2012,29 (9):3422-3424 (in Chinese).[董继光,陈卫卫,吴海佳,等.基于动态副本技术的云存储负载均衡研究 [J].计算机应用研究,2012,29 (9):3422-3424.]
[11]Chen Y,Ganapathi A,Griffith R,et al.The case for evaluating MapReduce performance using workload suites[C]//IEEE 19th International Symposium on Modeling,Analysis & Simulation of Computer and Telecommunication Systems,2011:390-399.
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
计算机系统应用(2019年2期)2019-04-10 05:08:46
火控雷达技术(2018年4期)2019-01-15 05:07:22
卷宗(2016年12期)2017-04-19 20:57:30
计算机与生活(2016年11期)2016-11-22 02:07:32
活力(2016年9期)2016-08-01 22:41:45
健康管理(2016年7期)2016-05-14 11:38:41
计算机工程与科学(2015年3期)2015-03-27 07:46:15
