
自适应学习的混合高斯模型运动目标检测算法
2014-12-23 01:20任克强张盼华
计算机工程与设计 2014年3期
任克强,张盼华,谢 斌
(江西理工大学 信息工程学院,江西 赣州341000)
0 引 言
在计算机视觉和图像处理领域中,智能视频监控技术是一个重要的研究课题,已被广泛的应用在智能交通、智能安防以及智能建筑等领域。如何从一组连续的视频序列中提取出运动目标是其首要解决的问题之一。常见的运动目标检测方法有:光流法[1]、帧间差分法[2]和背景差分法[3]。光流法是通过计算光流场而得到运动目标,不需要预先知道有关场景信息,但计算量较大,目前没有较好通用的硬件支持。帧间差分法是将相邻的两帧图像对应像素点进行相减而得到运动目标,能够适应光照突变,具有较小的计算量,但抗噪声性能较差、易出现空洞现象。背景差分法是将当前视频图像帧和建立的背景模型进行相减而得到运动目标,该算法复杂度不高、实用性较好,能够满足实时性要求。
混合高斯模型 (Gaussian mixture model,GMM)是背景差分法中一种常见背景建模方法[4],其关键是建立符合场景的背景模型与模型的有效自适应维护更新。文献 [5]将混合高斯模型应用于场景的背景建模与前景分割中,由于其良好的背景拟合能力和较强的适应性而得到广泛关注。文献 [6]提出了一种融合背景减除法的改进混合高斯算法能够快速检测出运动目标,有效地抑制反光物体带来的频繁闪动。文献 [7]采用自适应高斯模型数目的方法同像素点的空间位置相结合改进了混合高斯模型,但是该方法并没有自适应学习率。文献 [8]根据背景演变过程进行划分的自适应学习率方法,但其学习速率仍是设定有限的几种固定的学习速率,没能实现真正的自适应非跳变的学习。文献 [9]通过统计像素点到t时刻匹配的总次数的倒数作为学习速率,在较短的有限时间内是可行的,但背景模型经过较长时间后学习速率进行了一定的恶性积累,学习速率会衰减为一个很小的值,若背景像素被前景像素长期覆盖,则需要更长的时间才能学习到真实的新背景。
针对上述的不足,提出了一种改进的混合高斯模型。将背景模型学习过程划分两个大的阶段:背景初始形成阶段和背景维护更新阶段,针对不同的阶段采用不同的更新策略,自适应实现对背景模型的更新,实现自适应拟合真实背景分布。
1 混合高斯模型
1.1 背景建模
混合高斯模型是一种无监督学习的参数化模型,是单高斯概率密度函数的延伸,能够平滑近似任意形状的概率密度分布。由于其良好的对真实场景背景分布拟合逼近能力,被广泛应用在运动目标检测中。
在时间轴上,将视频序列中同一位置像素点的xt值变化视为一种随机过程并且认为服从高斯分布,像素点在t时间的状态可以用K 个高斯模型表示,由这多个高斯分布构造出来的背景模型实现对真实背景分布逼近,其概率函数模型为

式中:Xt——t 时刻样本像素观察值;K——模态总数;i——模态序号;ui,t——模态的均值;wi,t——模态的权重;∑i,t——协方差矩阵;η(Xt,ui,t,∑i,t)——概率密度函数;P(Xt)——Xt的概率函数。
1.2 匹配与更新
模型匹配准则是将当前观测到的像素点I(x,y)与已有的K 个高斯分布进行比较,若满足式 (3),则认为当前像素点I(x,y)与高斯分布模型匹配,否则认为不匹配
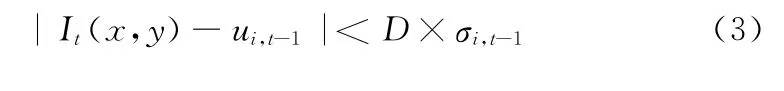
式中:D 为置信参数,一般取2.5;ui,t-1和σi,t-1分别为第i个高斯分布在t-1时刻的均值和标准差。
(1)若匹配,则将匹配的高斯分布参数按如下规则进行更新
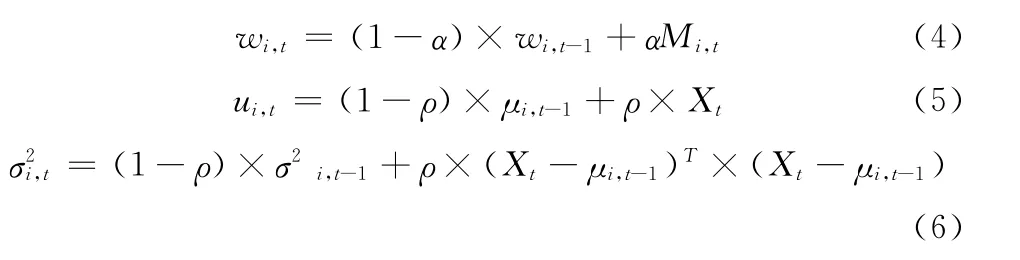
式中:α为学习速率,一般取0.005;Mi,t为偏置,匹配时取1,不匹配时取0;ρ=α×η(Xt,ui,t,∑i,t)为期望与方差的学习速率。
(2)若不匹配,则用当前帧的均值,初始化一个较大方差、较小权重的高斯模型,并将新的高斯模型取代排序最后一个背景模型;权重更新只需将式 (4)中的Mi,t值取0;对于其他高斯模型,其均值和方差取值不变。
1.3 背景估计与前景分割
背景估计与前景分割的本质属于分类器的设计,首先将高斯分布优先级按wi,t/σi,t的值从大到小排列,然后从排列在最前的第一个模型开始,取B 个高斯分布作为混合高斯分布的背景模型
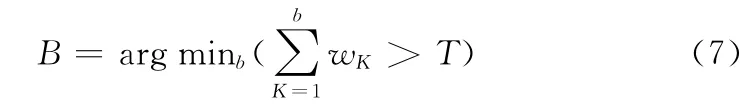
式中:T 为阈值,一般取0.7-0.8。
进行前景检测时,选取B 个高斯模型作为背景模型后,将当前帧的像素值I(x,y)与B 个高斯背景模型分别进行比较,若I(x,y)与背景模型中任何一个模态匹配,则该像素点为背景点,否则为前景点。
2 图像序列像素变化特性
图像中像素点I(x,y)处的像素变化可视为一种随机过程,在t时刻的观察值可以用Xt来表示,其中Xt=[xRxGxB]T为像素点的RGB 彩色向量。图像场景中内容的变化对于彩色监控摄像机而言,表现为RGB彩色分量的变化,即同一坐标位置像素点的RGB 值由新的值代替。如图1所示,本文以Campus_1和highway监控视频序列作为分析样本。如表1所示,分别选取4种不同的观测样本点,分析了场景中无目标 (A 点,静止路面)、少量运动目标 (B点,缓慢行人;D 点,摇摆树枝)、多运动目标(C点,行驶车辆)等像素点变化情况,其像素点RGB分量变化图、灰度分布图、RGB 三维分布图如图2、图3和图4所示。从图中可以看出,像素变化主要有以下特性:
(1)无任何目标出现的情况
当场景像素点无任何目标出现时,如图2 (a)所示,像素RGB彩色分量变化较为平稳;如图3 (a)所示,模型呈现较为集中单峰模态;如图4 (a)所示,像素RGB三维空间分布呈现密集的椭球形。此时对于模型而言应当采用较小的学习速率,保持模型的相对稳定。

图1 测试样本图像序列
(2)少量目标与多目标出现的情况
当场景中出现运动目标时,如图2 (b)、图2 (c)所示,运动目标经过的地方像素RGB 彩色分量值产生突变。背景像素RGB彩色分量值变化可能是短时的突变,即经过有限帧数变化图像像素RGB彩色分量值又恢复到原来的背景RGB彩色分量值中心周围。若短时突变,如图3 (b)所示,模态呈现集中的单峰情况;如图3 (c)所示,目标像素点分布远离模型分布中心像素;如图4 (b)所示,RGB三维空间分布仍呈现密集的椭球形。此时对于模型而言应采用较小的学习速率,减小对场景的误学习,保持背景模型的相对稳定。
(3)场景中目标由静止到运动或者由运动到静止的情况
背景像素RGB彩色分量值变化也有可能是长时间的突变,如运动目标停止将原始背景遮盖或静止目标运动使得原始背景的裸露。这种变化表现为原始背景像素消退,形成新特性背景,如图2 (d)所示,背景像素变化表现为RGB彩色分量值的整体搬移;如图3 (d)所示,模态呈现单峰与多峰并存;如图4 (d)所示,新特性像素点分布远离模态分布中心,形成一个新的模态中心。此时应加大权重的学习速率,加速模型收敛速度。
由此可见,混合高斯模型中的学习速率α值大小显得非常重要,α取值过小,则模型更新速度减慢,模型对真实场景的学习产生滞后,这样会把某些已经不是前景的物体误判为运动目标,造成目标的误检;α取值过大,则模型的更新速度过快,这样容易使目标溶入背景,造成目标的漏检。因此,混合高斯模型在对真实场景学习时,学习速率选取不当,则模型的有效更新会产生滞后,容易造成模型中存在 “模态残留”和 “有效模态丢失”情况,使得模型的有效估计滞后于真实背景的变化,在前景检测与目标分割时出现 “拖影”现象。
(4)像素变化 (目标,背景)均值、方差和标准差之间的特性分析,相关统计见表1。
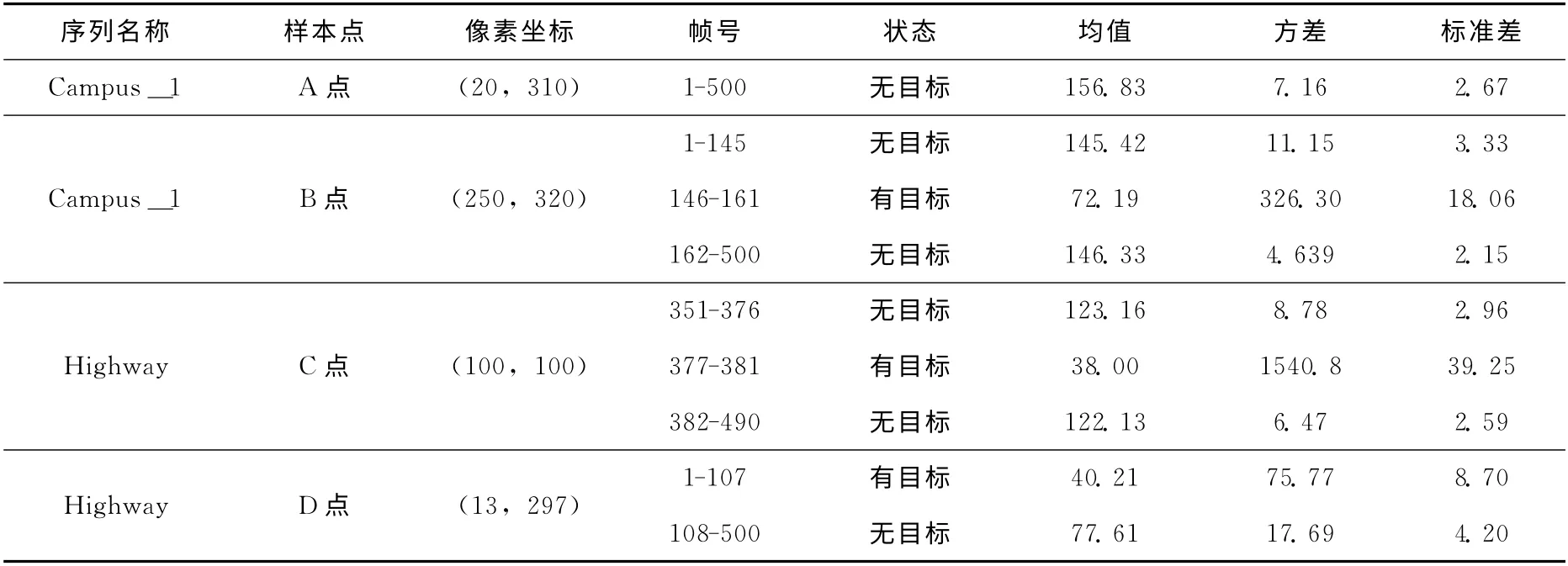
表1 像素样本点的均值、方差和标准差
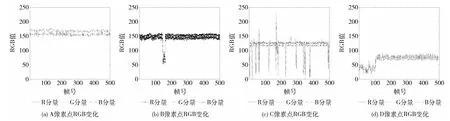
图2 Campus_1与Highway的像素RGB变化

图3 Campus_1与Highway的像素灰度分布
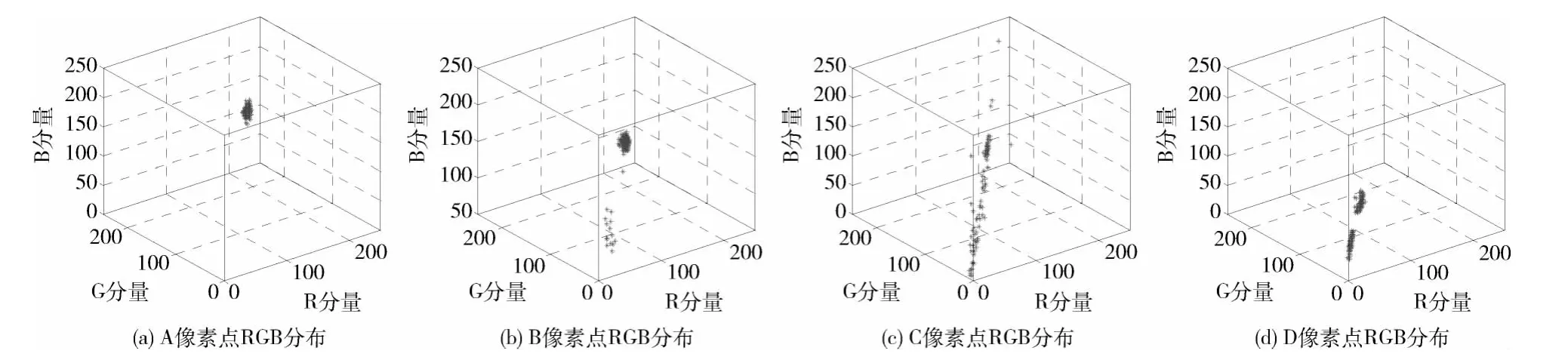
图4 Campus_1与Highway的像素RGB分布
由表1可以看出,目标出现位置像素点的方差和标准差值较大;无目标出现的位置像素点的方差与标准差都是很小的值。传统混合高斯模型方差学习速率ρ=α×η(Xt,ui,t,∑i,t),可以看出ρ远小于α,要使多个高斯分量的协方差矩阵∑i,t能够得到准确估计,则相对应的样本观察时间近似长度要求ρ >α。正由于方差学习速率的观察时间偏小,导致方差收敛速率较慢,不符合真实场景的方差变化情况。因此,在背景模型稳定后,应当加速其方差的收敛。
3 算法改进
3.1 模型参数分析
从上述分析的像素点变化特性可以看出,场景的变化是复杂和多变的,对于混合高斯模型而言,背景模型建立与有效维护更新伴随着运动目标检测的整个过程,而背景模型建立与维护更新又依赖于模型的控制参数。
(1)模态权重反映出某一模态出现的可能性,而学习速率又是模态权重的重要控制参数。从第2节分析可以看出,时域中RGB 彩色分量变化呈现:渐进变化、瞬时变化、周期变化、非周期随机变化等特征,当对新的场景采样值进行学习时,由于传统混合高斯模型权重学习速率是一个固定值,不能较好的适应场景中不同情况的变化,导致对模态参数的估计值严重滞后于采样样本的变化,算法正确有效更新速度较慢,不能及时适应场景的变化。因此随着采样时间的增大,权重学习速率应当为某种动态的值,才能够适应这种变化,即对不同的像素点采用不同的学习速率来进行学习。
(2)混合高斯模型的本质是在线聚类,模型中的协方差矩阵体现了各高斯分量对应的聚类形态,模态方差决定聚类的可塑性。较大的方差则使得聚类的可塑性减弱,导致模型不能及时从新的观测样本中学习到背景模型变化成分,从而造成背景模型的严重污染;较小的方差则使得聚类的可塑性过强,导致背景模型的结构不稳定,易出现聚类波动情况。方差的估计过大或者过小,都会导致前景分割的失败,因此当运动目标学习成背景之后,应当加速模型方差的收敛,加强其可塑性。
(3)模态期望决定聚类中最具有代表性的值,反映出属于哪一类的特征,代表着从历史像素值中学习到的背景模型结构,故模态要保持相对稳定。
由此可见,混合高斯模型在对场景的学习过程中,其学习速率的选取、期望和方差有效估计影响着模型学习、模态排序和模态匹配,模型参数的正确估计最终影响模型结构稳定、适应能力和目标分割效果。
3.2 学习速率改进
根据上述对视频序列像素点变化特性以及模型控制参数的分析,本文将模型的学习过程分为两个阶段,分别对模型的权重学习速率和期望方差的学习速率提出了改进。
(1)背景的初始形成阶段 (n<N),学习速率的更新策略如式 (8)所示。
由于模型初始化的第一帧常常是非清空场景,模态中非背景像素模态权重较大,应采用较大的学习速率来加快淘汰那些伪背景像素模型,加速真实背景模型的收敛。但此时背景尚未完全形成,方差和期望不易收敛过快,随着背景的逐步形成,学习速率逐渐递减,保证有效背景模型的稳定
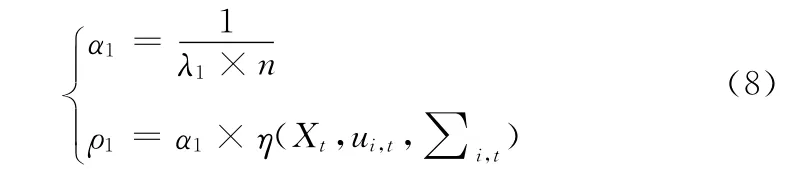
式中:λ1为衰减系数,取1.5;n为当前流过的帧数;N 为阶段阈值帧数;
(2)背景的维护更新阶段 (n≥N),学习速率的更新策略如式 (9)所示。
经初始阶段的学习,背景模型已基本形成,但场景信息常常是复杂多变的,因此需要对背景进行实时维护更新。背景的维护更新阶段根据模态像素变化的匹配次数与不匹配次数作为反馈量来修正模型的学习速率。当不匹配时,反馈量为正值,来增大学习速率,加大对场景的学习;当匹配时,反馈量为一个负值,来减小学习速率,减弱对场景的误学习,保证模型的稳定。模型的两种反馈在起始时反馈量都是一个很小的值,随着迭代次数的增加,反馈量则会逐渐增大。改进后的学习速率,给了模型对场景观测学习迭代时间长度,一个动态的学习空间,减小了对噪声、快速运动目标和较慢运动目标的误学习,又很好的根据场景情况,实现学习速率的自适应调节,实现模型的有效收敛
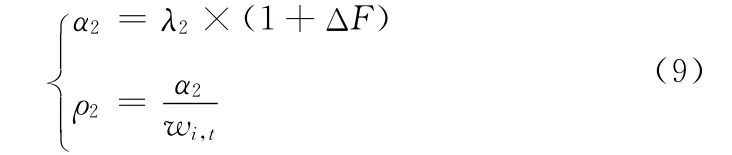
式中:λ2为学习率基准系数,取0.004;ΔF =(2f-t)×10-2为反馈量,f 为不匹配次数、t为匹配次数。为了避免在模型维护更新过程中,学习速率出现恶性增长或减小,对改进学习速率的学习准则做如下约定:防止学习后期中学习步长过大或者过小,设置学习速率空间α2∈(d1,d2),当学习速率动态调整超出学习速率空间的左右端点时,则将学习速率用d1,d2代替。防止出现数据溢出,当f、t大于τ时,则将其置零,重新计数;防止对前一目标、背景的学习误积累,若计数出现一次中断,则将f 和t置零。
4 实验结果与分析
为了测试本文方法的有效性,对GMM 方法和本文方法进行比较实验,实验平台为VC++6.0和OpenCV,测试序列为Highway(500帧,320×240)、Cityway(222帧,320×240)、Campus_1 (1179帧,352×288)、Campus_2(2687帧,384×288)。实验参数为:K=3,N=200,T=0.75,τ=20,λ1=1.5,λ2=0.004,d1=0.0028,d2=0.0168。实验结果如图5~图8所示。

图5 Highway序列的检测结果

图6 Cityway序列的检测结果

图7 Campus_1 序列的检测结果

图8 Campus_2 序列的检测结果
图5 为检测序列Highway的第15 帧检测结果,图6为检测序列Cityway第20帧的检测结果,主要是比较两种方法在初始阶段检测的效果。GMM 方法采用固定的学习速率,在起始阶段由某些运动目标构成的背景元素权重过大,导致背景的更新滞后当前的真实情况,出现孤立点和“鬼影”现象。改进后的算法在初始阶段采用较大的学习速率,通过流过的采样序列帧数的情况作为当前帧的学习速率控制参数,较快的实现初始化中非背景模型的权重衰退,较好的解决了模态残留,检测出的目标结构较为完整。
图7为检测序列Campus_1的第390帧检测结果,图8为检测序列Campus_2的第990帧的检测结果,主要是验证两种方法在维护更新阶段的检测效果,其中包括:对目标由运动到静止成为背景和缓慢运动目标 (行人、车辆)等情况检测。图7中的道闸已是合上,经过一定时间学习后,GMM 方法检测分割出来的仍为前景目标,而改进后的算法则已经将其学习为背景,检测结果更符合真实的情况。图8中的车辆已经停靠到车位中,GMM 方法检测出来的仍为前景目标,而改进后的算法已经将其学习为背景,主要原因在于改进算法通过统计模态匹配次数与不匹配次数作为反馈控制量,加速模态的收敛,检测的结果更为理想。并且从图中可以看出,对于缓慢运动目标 (如行人、缓慢行驶车辆)检测效果较好,并没有过快的将其学习为背景,其原因就是,模型学习在起始一段时间内,反馈量是一个较小的值并随着变化持续时间而逐渐增长,从而避免了对缓慢运动目标的误学习。
算法有效性评估是算法改进效果的重要体现,目前运动目标检测算法评估标准包括:基于目标界别评估、基于像素级别评估、以及基于目标和像素综合评估。为了检测本文方法的性能,将本文方法与传统的方法进行比较,针对上述实验检测结果,本文采用基于像素级别的估计,使用检出率 (DR)和误检率 (FAR)两个指标进行客观评价[10],DR 和FAR 的计算公式如式 (10)和式 (11)所示

式中:FP——错误检测出来的虚假像素数,TP——正确检测出来的目标像素数,FN 为未被检测出来的目标像素。本文对上述相关实验数据见表2。
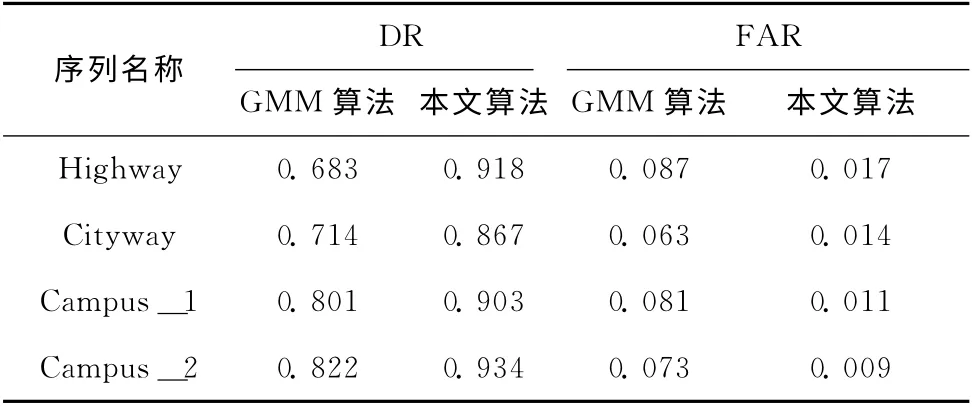
表2 GMM 算法与改进算法比较
从表2可以看出,改进后的算法检测效果优于GMM算法。主要原因在于,初始阶段采用较大的学习速率,那些非真正背景模型得到快速衰退,加快了背景模型的快速建立;维护更新阶段,根据像素点的匹配与不匹配次数情况作反馈量,加速或者减缓自适应的对场景的学习,使得检测结果更加符合真实的场景。
5 结束语
本文分别对像素变化特性、混合高斯模型控制参数进行了分析,将背景学习分为两个大的阶段,引入反馈控制机制进行背景建模,提出了一种自适应学习速率的混合高斯模型算法。改进的高斯混合模型算法,对真实场景背景的拟合能力更佳,能够实现自适应拟合真实背景分布,并且合理的解决了场景中模型收敛速度慢而产生的模态残留和拖影问题,有效地检测出运动目标,改进后的算法优于传统混合高斯模型算法。
[1]ZHANG Shuifa,ZHANG Wensheng,DING Huan,et al.Background modeling and object detecting based on optical flow velocity field[J].Journal of Image and Graphics,2011,16(2):236-243(in Chinese).[张水发,张文生,丁欢,等.融合光流速度与背景建模的目标检测方法 [J].中国图象图形学报学,2011,16 (2):236-243.]
[2]XU Jing,ZHANG He,ZHANG Xiangjin.IR motive detection using image subtraction and optical flow[J].Computer Simulation,2012,29 (6):248-252(in Chinese). [许敬,张合,张祥金.基于帧间差分和光流法的红外图像运动检测 [J].计算机仿真,2012,29 (6):248-252.]
[3]SI Hongwei,QUAN Lei,ZHANG Jie.Motion detection algorithm based on background estimated[J].Computer Engineering and Design,2011,21 (1):262-265(in Chinese). [司红伟,全蕾,张杰.基于背景估计的运动检测算法 [J].计算机工程与设计,2011,21 (1):262-265.]
[4]XUE Ru,SONG Huansheng,ZHANG Huan.Overview of background modeling method based on pixel[J].Video Engineering,2012,36 (13):39-43(in Chinese). [薛茹,宋焕生,张环.基于像素的背景建模方法综述 [J].电视技术,2012,36 (13):39-43.]
[5]Stauffer C,Grimson W E L.Adaptive background mixture models for real-time tracking [C]//Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition,1999:246-252.
[6]HUANG Wenli,FAN Yong,LI Huizhuo,et al.Improved mixture Gaussian algorithm [J].Computer Engineering and Design,2011,32 (2):592-595 (in Chinese).[黄文丽,范勇,李绘卓,等.改进的高斯混合算法 [J].计算机工程与设计,2011,32 (2):592-595.]
[7]WANG Yongzhong,LIANG Yan,PAN Quan,et al.Spatiotemporal background modeling based on adaptive mixture of Gaussians[J].Acta Automatica Sinica,2009,35 (4):371-378(in Chinese).[王永中,梁颜,潘泉,等.基于自适应混合高斯模型的时空背景建模[J].自动化学报,2009,35 (4):371-378.]
[8]ZHU Qidan,LI Ke,ZHANG Zhi,et al.An improved gaussian mixture model for an adaptive background model[J].Journal of Harbin Engineering University,2010,31 (1):1348-1353(in Chinese).[朱齐丹,李科,张智,等.改进的混合高斯自适应背景模型 [J].哈尔滨工程大学学报,2010,31 (1):1348-1353.]
[9]LI Wei,CHEN Linqiang,YIN Weiliang.Background modeling approach based on self-adaptive learning rate[J].Computer Engineering,2011,37 (15):187-189(in Chinese).[李伟,陈临强,殷伟良.基于自适应学习率的背景建模方法 [J].计算机工程,2011,37 (15):187-189.]
[10]LI Pengfei,CHEN Chaowu,LI Xiaofeng.An overview for performance evaluation of intelligent video algorithms [J].Journal of Computer-Aided Design & Computer Graphics,2010,22 (2):354-360(in Chinese).[李鹏飞,陈朝武,李晓峰.智能视频算法评估综述 [J].计算机辅助设计与图形学学报,2010,22 (2):354-360.]
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
现代电子技术(2021年1期)2021-01-17
小天使·二年级语数英综合(2019年4期)2019-10-06
红领巾·萌芽(2019年8期)2019-08-27
小学生学习指导(低年级)(2019年6期)2019-07-22
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
中国与非洲(法文版)(2017年10期)2017-11-23
自动化学报(2017年11期)2017-04-04
CHIP新电脑(2016年3期)2016-03-10
