
基于站点结构和浏览时间的路径补全算法
2014-12-23 01:22崔晓靖陈兴蜀曾雪梅
计算机工程与设计 2014年3期
崔晓靖,陈兴蜀,曾雪梅
(四川大学 计算机学院,四川 成都610065)
0 引 言
Web使用挖掘[1-3]是Web挖掘的一个分支,是通过挖掘用户的访问日志,从中发现用户的访问模式的过程。只有使用准确描述用户浏览行为的数据进行挖掘才能发现正确的模式和规则。因此,作为知识提取的输入数据,数据预处理后的数据必须具有较高的准确性。用户访问记录的缺失影响了Web使用挖掘的准确性。例如,文献[4]中对Web日志挖掘中路径补充的影响进行评估,说明了路径补充提升了规则抽取的数量以及抽取规则的支持度和置信度。所以,在Web日志挖掘中路径补全是很有必要的。
为了提高数据与处理后数据的质量,学者们提出了多种路径补充方案[5-7]。文献[5]使用典型的“后退”方式对缺失路径进行补充。文献[6]提出一种新的基于“多窗口”方式的路径补充算法,解决了用户使用多个窗口进行浏览时的路径补充问题,是对 “后退”方式的补充。文献[7]提出一种个性化推荐模式下的路径补充机制,利用网站的静态结构和动态信息结合不同的页面类型进行有效地路径补充。这些方法大多是将两个页面间的最近访问路径或最短路径补充到原始路径中。在网页结构复杂的情况下,两个网页之间的链接相对复杂,多数情况下用户并不是沿着最短路或最近访问过的路径进行浏览,而且用户可能是在同一窗口打开一系列页面,也可能是在不同窗口打开多个页面。这种情况下,仅仅基于 “后退”或者“多窗口”的路径补全算法并不能完整地还原用户的行为趋势。本文在现有的路径补全算法的基础上提出一种基于站点结构和用户浏览时间的路径补充算法来解决这些问题。实验证明,在上述的几种访问模式下,本文的路径补全算法都能够有效地补充丢失的路径。
1 Web日志预处理简介
本文的数据预处理模型如图1所示。数据预处理过程主要包括数据清洗、用户识别、会话识别和路径补全4个过程。图中网站结构通过爬虫获取。

图1 数据预处理过程
1.1 数据清理
数据清理是数据预处理的第一阶段。Web日志中存在大量的干扰性数据,这些数据与用户访问行为无关,严重影响了Web日志挖掘结果的准确性。数据清理阶段主要清理一些无关数据。其规则如下参见文献[8]。
1.2 用户识别
用户识别就是识别每个访问网站的用户的过程。本文用户识别采用以下策略:
(1)IP不同,表示不同用户;
(2)IP相同,使用不同的代理服务器表示不同的用户;
(3)IP和代理服务器相同,不同的浏览其代表不同的用户[11];
(4)IP、代理服务器以及浏览其都相同,引用页面不在前面的记录中表示不同的用户[12]。
否则,就表示相同的用户。
1.3 会话识别
会话是指用户进入网站到离开网站的一系列页面请求。一个用户可能多次访问同一网站,这就需要对用户进行会话识别以区分用户的每次访问过程。本文采用文献[8]中时间窗口模型的会话识别算法进行用户会话识别。
1.4 路径补全
由于本地代理和缓存服务器的存在,用户访问缓存中已经访问过的页面时,日志中并不再记录该次访问,这样就会遗漏很多页面。本文提出一种基于网站拓扑结构和访问时间相结合的路径补全算法。该算法主要是利用日志的动态结构和访问时间对缺失页面进行补全。算法基本思想是利用会话中的日志记录构建动态站点结构,并根据动态结构找到可能补充的多条路径选择合适的路径补充到日志记录中。具体补充算法将在后文中做详细介绍。
2 路径补全算法
2.1 概念描述
定义1 用户访问记录(R)。R=<id,time,url,refer>。其中id 表示当前会话中记录R 的序号,time表示请求时间,url表示请求页面的链接地址,refer表示用户浏览的上一页面,即引用站点URL。
定义2 用户会话集合Session。Session=<Session_ID,(R(1),R(2),…,R(n))>,其中Session_ID 表示会话的序号,R(i)表示会话中的第i个用户访问记录,且i,j如果i<j,则有R(i).id<R(j).id 且R(i).time≤R(j).time。
根据第2节中的用户识别策略可知,对于同一个会话集合中的Session,他们拥有相同的IP。
定义3 用户集合(U)。U =<UID,<Session(1),Session(2),…,Session(n)>>。其中UID 表示用户标识,Session(i)表示会话集合。
定义4 用户相邻日志记录时间间隔(ΔT)。表示同一会话中两条相邻日志记录之间的时间间隔值。

定义5 页面浏览时间(vis_time)。页面浏览时间表示用户浏览某一页面所花费的时间,也就是说,在会话中用户浏览R(i).url花费的时间

对于连续的两条日志记录R(i)和R(i+1),即R(i+1).refer=R(i),R(i).url页面浏览时间为相邻日志记录时间间隔ΔT;当R(i+1).refer≠R(i)时,说明两条日志记录不连续或者日志记录为该会话的最后一条日志记录,此时的ΔT(i)并不能准确反映页面的浏览时间,此时记R(i).url的页面浏览时间为∞。
定义6 页面平均浏览时间(avg_time)。页面平均浏览时间表示用户集合中某一页面的平均浏览时间

式中:num(url)——用户集合U 中有效url(vis_time(R(i).url)≠∞)个数。
页面平均浏览时间是对用户浏览某一页面浏览时间的一个估计。由于不同用户的访问习惯、阅读速度等具有个性化特征,因此定义6中的页面平均浏览时间是针对不同用户的,即不同用户对同一个页面的平均浏览时间可能不相等。由于vis_time(R(i).url)=∞时,vis_time(R(i).url)不能有效反映用户浏览该url的时间因而在估计url 的平均浏览时间时应被舍弃。
定义7 用户浏览路径时长(Tpath)。设path=<url1,url2,…,urlk>其中url1,url2,...,urlk为访问路径的url序列,且path-urli表示从path 的url序列中去掉urli页面则
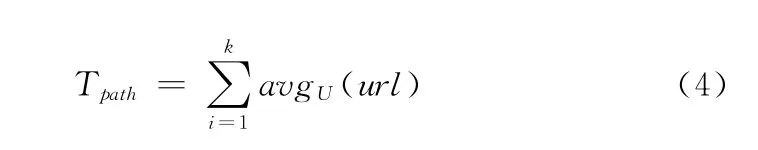
定义8 网页动态结构。网页动态结构也是用图结构存储,动态站点结构图G=(V,E),V 表示会话中的页面url,即图G 中的顶点,顶点顺序依次为url1,url2,…,urln,E 为当前记录前已经遍历的站点页面间的链接,即图G 中的顶点间的有向链接,G 的邻接矩阵B 是n 阶方阵,如果R(i).url=urli且R(j).url=urlj则有
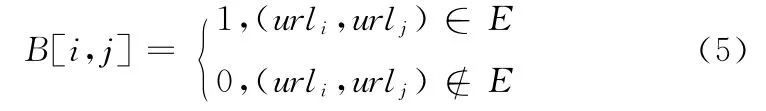
定义9 待补充路径和实际路径的偏离程度σ。σ用于选取待补充路径中最接近真实路径的路径。
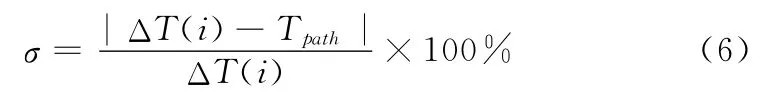
为了选择最合适的路径,定义相邻url的路径时间间隔,它是为了衡量路径补全算法中产生多个路径的一个参数,而定义5中的页面浏览时间是为了估算页面平均浏览时间。
2.2 路径补全基本流程
文献[8]进行会话识别后R(i+1).refer为空或者属于站点URl集合。遍历会话中的记录,路径补充按照以下流程进行:
(1)如果会话中,R(1).refer为本站点的网页,则补充R(1).refer到会话中,并继续遍历会话中的日志记录,转到(2)。
(2)如果会话中,R(i+1).refer≠R(i).url且会话未结束,补充规则如下:①令待选路径集合Path_Set=<path-1,path0>其中path0=<R(i).url,R(i+1).refer>,path-1=<R(i).url>。②根据用户访问站点动态结构图求出R(i+1).refer和R(i).url之间的所有路径path1,path2,…,pathn,并将这些路径添加到Path_Set里。
(3)计算Path_Set中路径集合时长偏离ΔT(i)的程度σ-1,σ0,…,σn。
(4)找出min{σ-1,σ0,…,σn}所对应的路径pathk并将pathk-R(i).url中的url 页面转换成记录的形式补充到<R(i).url,R(i+1).url>中。若存在p,q 满足min{σ-1,σ0,…,σn}=σp=σq使得,则取pathp和pathq中里当前记录最近的一条路径补充<R(i).url,R(i+1).url>之间。
其中,path-1和path0表示不需要补充的情况和只需要补充R(i+1).refer的情况。
2.3 路径补全算法实现
(1)两点间有向路径集合Path_Set求解算法PS[9,10]。
站点动态结构则在路径补充过程中产生,程序每处理一条记录G 就可能增加一条两个节点间的链接。算法实现中,用G 的逆邻接表来实现。其结构如图2所示。
adjvex为邻接点域,存放与R(i)节点相邻的节点R(j)的序号j;nextarc指向下一表结点;data表示存放顶点R(i)信息;firstarc表示R(i)邻接表的头指针。所有的头结点顺序存放在向量R_SET 中。
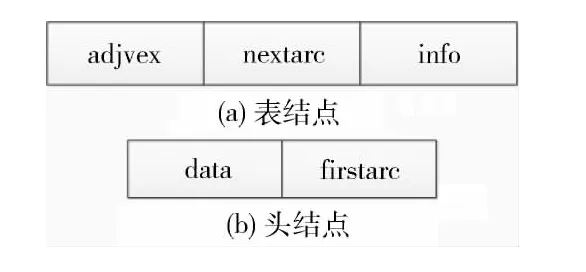
图2 逆邻接表的结构
求解R_SET 的算法如下:
由G 的邻接矩阵B求解各顶点的逆邻接表。
由逆邻接表求解urli到urlj之间的所有有向路径集合。
初始化urli到urlj的路径集合Path_Set=NULL,以及临时路径集合Temp_Path=NULL
初始化路径向量Path=<urli>

(2)路径补全算法流程。


3 实验与结果分析
本文以四川大学网站2012年6月的日志数据为实验数据,设计4种不同的浏览路径,同一种路径包含5条路径,共20条路径。这4种路径分别是:①Path1(记P1),基于“后退”方式的用户访问路径;②Path2(记P2)。基于 “多窗口 “的用户访问路径;③Path3(记P3),基于个性化模式的用户访问路径;④综合访问模式的访问路径。在4种访问模式下,分别使用已有的PRM 路径补全算法[9,10]、基于多窗口的路径补充算法[6]、基于个性化推荐的路径补充算法[7]以及本文提出的算法来实现路径补充。统计路径补充的正确补充访问记录个数,错误补充访问记录个数,分别计算各种访问模式下路径补充的正确率P及其平均正确率。其中,正确率P=T/(T+F)。统计4种算法在四中访问模式下的正确率见表1。
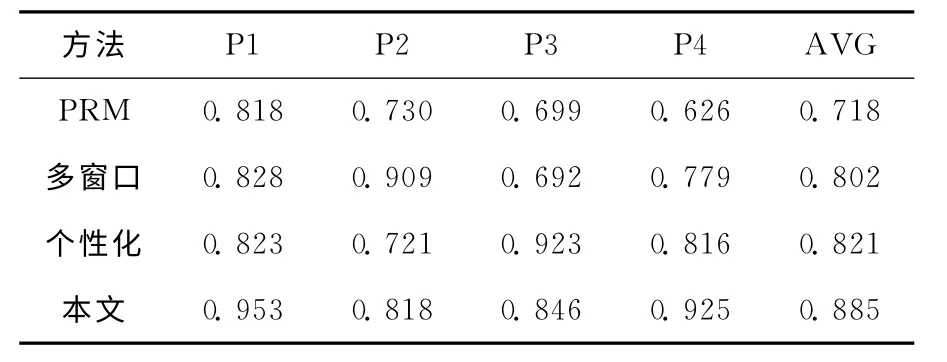
表1 实验结果
由图3可知:
(1)传统的基于 “后退”方式的路径补充算法在多窗口访问模式和个性化访问模式下路径补充的准确率较低;
(2)基于 “多窗口”的路径补充算法和基于个性化的路径补充算法在其适用的访问模式下准确率较高;
(3)本文的基于网站结构和浏览时间的路径补充算法在多种访问模式下进行的路径补充均有较高的准确率。
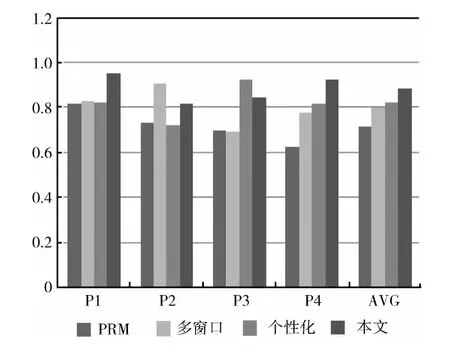
图3 各种路径补全方法准确率比较
4 结束语
本文对各种路径补全算法进行了深入研究,探究了用户访问路径的几种方式,分析了路径补全的影响因素。并针对现有的路径补全方法的缺点,提出了基于站点结构和页面浏览时间的路径补全算法。实验表明,与其它方法相比,此方法在各种访问模式下均有较高的准确率。
由于实验目标网站为中小型网站,访问量和日志量不会过大,运算时,因而本文使用矩阵进行存储和计算效率也比较高。对于大型网站而言,日志量比较大,每个用户会话内的日志记录比较多的情况,则需要对算法进行优化以提高程序运行的效率,及时地为日志数据挖掘提供数据基础。
[1]Nithya P,Sumathi.Novel pre-processing technique for web log mining by removing global noise and web robots [C]//NCCCS,IEEE,2012.
[2]Li Yan,Feng Boqin.The construction of transactions for web usage mining [C]//International Conference on Computational Intelligence and Natural Computing,2009:121-124.
[3]Reddy S K,Reddy K.An effective data preprocessing method for Web Usage Mining [C]//ICICES,IEEE,2013.
[4]CAI Weixin,FENG Zhenyu,YANG Jian.Evaluation of impact of path completion in web log mining [J].Computer Systems & Applications,2011,20 (3):226-229 (in Chinese).[蔡卫欣,冯振宇,杨剑.web日志挖掘中路径补充的影响评估 [J].计算机系统应用,2011,20 (3):226-229.]
[5]WANG Lan,ZHAI Zhengjun.The research on data preprocess and path supplement in web data mining [J].Microelectronics&Computer,2006,23 (8):113-116 (in Chinese). [王岚,翟正军.web日志挖掘的预处理及路径补全算法的研究 [J].微电子学与计算机,2006,23 (8):113-116.]
[6]HUANG Jinjing,ZHAO Lei,YANG Jiwen.Path supplement in session reconstruction based on multi window [J].Computer Applications and Software,2009,26 (7):46-51 (in Chinese).[黄金晶,赵雷,杨季文.web会话构造中基于多窗口的路径补充 [J].计算机应用与软件,2009,26 (7):46-51.]
[7]XIA Xiufeng,WANG Yu.A user access path complementing algorithm based on personalized recommendation [J].Computer Applications and Software,2011,28 (2):179-183 (in Chinese).[夏秀峰,王宇.一种基于个性化推荐的用户访问路径补全算法 [J].计算机应用与软件,2011,28 (2):179-183.]
[8]CAI Hao,JIAN Yubo,HUANG Chengwei,et al.Improved method for session identification in Web log mining [J].Computer Engineering and Design,2009,30 (6):1321-1323 (in Chinese).[蔡浩,贾宇波,黄成伟,等.Web日志挖掘中的会话识别算法 [J].计算机工程与设计,2009,30 (6):1321-1323.]
[9]LI Y,FENG B,MAO Q.Research on path completion technique in web usage mining [C]//International Symposium on Computer Science and Computational Technology,IEEE,2008:554-559.
[10]MAO Hongmei,GAN Shengke.An algorithm for finding all paths bet ween source node and other nodes in a digraph [J].Microelectronics & Computer,2009,26 (3):128-130 (in Chinese).[毛红梅,甘晟科.求有向图中源点到各结点所有路径的一种实用算法 [J].微电子学与计算机,2009,26(3):128-130.]
[11]Varnagar Chintan R,Madhak Nirali N,Kodinariya,et al.Web usage mining:A review on process,methods and techniques[C]//International Conference on Information Communication and Embedded Systems,2013:40-46.
[12]XIAO Hui,WANG Lihua.User identification algorithm in web log mining [J].Computer Systems & Applications,2011,20 (5):223-226 (in Chinese).[肖慧,王立华.Web日志挖掘中的用户识别算法 [J].计算机系统应用,2011,20 (5):223-226.]
猜你喜欢
保健医苑(2022年1期)2022-08-30
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
电子制作(2019年14期)2019-08-20
思维与智慧·上半月(2018年9期)2018-09-22
小学生(看图说画)(2017年6期)2017-11-06
党的生活·党员电教与远程教育(2017年9期)2017-10-17
中国自行车(2017年1期)2017-04-16
故事会(2016年21期)2016-11-10
工业设计(2016年1期)2016-05-04
