
自适应的分布式文件系统元数据管理模型
2014-12-23 01:24程付超
计算机工程与设计 2014年3期
程付超,苗 放,2,陈 垦
(1.成都理工大学 地球探测与信息技术教育部重点实验室,四川 成都610059;2.成都理工大学地质灾害防治与地质环境保护国家重点实验室,四川 成都610059)
0 引 言
分布式文件系统的元数据管理直接影响到系统的性能、扩展性、稳定性和可靠性。目前,分布式文件系统大多将元数据全部缓存到服务器内存中进行管理[1],按照其部署方式可分为集中式元数据管理模型、分布式元数据管理模型和无元数据模型三类[2],见表1。多数分布式文件系统采用了集中式的元数据管理模型[3-7],如GFS[3]、HDFS[4]、Lustre[5]等;GlusterFS[8]中采用了无元数据模型。但随着当前各类应用系统中数据量的爆发性增长,元数据的数据量已经逐渐超过单台服务器的内存上限,采用分布式元数据管理模型是未来的发展趋势[9,10]。因此,如何在多台元数据服务器间进行高效低开销的元数据同步,维护元数据的一致性,成为一个需要解决的重要问题。目前主要存在两种解决办法:
(1)使用多个独立命名空间。一些分布式文件系统,比如HDFS Federation[11],让每台元数据服务器单独管理一个命名空间,服务器间不需要互相协调。这种方法从根本上消除了同步元数据的必要性,其性能与使用集中式模型的系统一致;但这种方法没有完全解决单点故障问题,当某个元数据服务器宕机时,其管理的相应文件便不可访问。
(2)使用分布式共享内存技术。一些分布式文件系统采用了硬件级的分布式共享内存技术(如MMP、SMP和cc-NUMA)[2],虽然可以明显提高系统性能,并抵消同步性能开销,却大大增加了系统的构建成本。

表1 元数据管理模型对比
针对分布式文件系统元数据管理模型存在的上述不足,本文借鉴Spark计算框架中RDDs[12]的设计思路,提出了一种分布式的内存抽象——工作-备份数据集(workingbackup dataset,WBD),将内存区域抽象为数据集,并通过数据集操作来实现内存访问,减小了数据同步时内存操作的复杂度,降低了元数据同步造成的额外性能开销。在WBD 的基础上,本文设计了一种分布式文件系统元数据管理模型——自应从模型(self-adaptation master-slave,SAMS),通过数据的放置、更新和同步策略,实现元数据管理的自适应性。实验分析表明,采用SAMS作为分布式文件系统的元数据管理模型,不但能够提供高性能的元数据服务,还能够保证元数据服务的高容错性和高扩展性。
1 工作-备份数据集
工作-备份数据集是一种内存抽象,也是一种面向高效数据访问服务的分布式数据集,它将内存区域抽象为数据集形式,通过数据集操作来访问内存区域,实现基于内存的数据高效查询、更新和同步等功能,同时具备多种工作状态,可以为分布式文件系统的元数据管理提供支持。
1.1 WBD的构成
工作-备份数据集由数据集版本、工作数据集和备份数据集三部分构成。
1.1.1 数据集版本
数据集版本(dataset version,DV)是进行数据一致性校验和数据恢复的重要依据。版本的内容包括WBD 名称、当前版本号和历史版本。WBD 名称是在全局维护的WBD 唯一标识符;当前版本号是与最新的数据集相对应的WBD 版本;历史版本用于查询WBD 的更新历史,进行数据恢复。数据集版本存储在服务器的外部存储器上,同时也被缓存到内存里。
1.1.2 工作数据集
WBD 中的工作数据集(working dataset,WD)用于提供数据的查询、更新和同步等功能,被缓存到服务器内存中。工作数据集由服务数据集和操作数据集组成。
(1)服务数据集(service dataset,SD)
服务数据集是WBD 中的主要数据集,WBD 的绝大部分数据记录都被放置在服务数据集中。SD 主要用于提供数据的查询服务,因此只支持读操作和批量写入操作,而不支持细粒度的写操作,这样就减少了数据的更新频率,从而降低了更新造成的性能开销。
(2)操作数据集(operation dataset,OD)
操作数据集在WBD 中占的比重较小,但却非常重要,数据的查询和更新等操作的完成都在一定程度上依赖于操作数据集。OD 中放置的是对当前数据集的实时操作记录,这些操作记录按照顺序排列,组成一个操作队列。相对于SD,OD 支持完整的读写操作,其数据更新和同步都较为频繁,但由于其数据总量较小,造成的性能开销也就相对较小。
1.1.3 备份数据集
备份数据集(backup dataset,BD)存在于外部存储器上,以文件形式存储,主要用于数据的加载和恢复,由补丁和镜像构成。
(1)补丁(patch):补丁是操作数据集的备份数据,由持久化操作生成。在一个WBD 中一般存在一个或多个补丁,每个补丁与一个数据集版本相对应,通过补丁能够将WBD 恢复到其任意版本。
(2)镜像(image):镜像是WBD 中服务数据集的备份数据,通过持久化操作写入外部存储器。镜像中记录了对应的数据集版本和此版本服务数据集的全部数据记录,可以用于节点重启和宕机之后服务数据集的恢复。每个WBD只有一个镜像文件,老版本的镜像将被替换。
1.2 WBD的操作
WBD 提供了较为丰富的数据集操作,能够满足分布式文件系统元数据管理的需要。按照操作对象的不同,WBD操作可以分为基本操作、工作数据集操作和备份数据集操作三类,见表2。

表2 WBD 提供的操作
1.2.1 数据融合
数据融合是WBD 的核心操作,通过数据融合能够对整个数据集进行更新。其步骤为:①将OD 中的操作记录持久化到外部存储器上,成为新的补丁;②将OD 中的操作记录融合到SD 中,实现对SD 的批量更新,融合算法如图1所示。③清空OD,并生成新的数据集版本,融合完毕。

图1 数据融合算法流程
1.2.2 数据恢复
WBD 的数据恢复主要是对工作数据集进行恢复,而对其中的OD 和SD 采用了不同的恢复方式。OD 的恢复通过与其它节点进行同步来完成。SD 的恢复通过版本、镜像和补丁来完成,能够将SD 恢复到刚刚完成某次融合之后的状态,流程如图2所示。
1.2.3 分裂与合并
WBD 支持在线的分裂和合并操作。
(1)WBD 的分裂:在进行分裂操作时,会首先对原始WBD 进行一次数据融合,然后创建两个新的WBD,将原始WBD 的服务数据集进行划分后,分别存入新的WBD中,并将数据持久化为各自的初始补丁,最后设置好初始版本,完成分裂操作。分裂操作的关键在于服务数据集中数据记录的划分算法,可以采用的算法包括排序算法,随机算法,hash算法,局部匹配算法等,在实际应用中可以根据需要进行选择。

图2 服务数据集恢复流程
(2)WBD 的合并:与分裂操作类似,在进行合并操作时,也会首先对两个WBD 进行一次数据融合,然后创建一个新的WBD,将两个服务数据集合并为一个写入新的WBD 中,并持久化为初始补丁,最后设置初始版本,完成合并操作。
1.3 WBD的状态
工作-备份数据集具有预备和活动两种工作状态,分别对应于不同的功能,通过加载、恢复和释放操作可以实现WBD 状态切换,如图3所示。

图3 WBD 状态切换
(1)预备状态。WBD 部署完成等待载入的状态叫做预备状态,在这种状态下,工作数据集相关的操作都无法执行,WBD 不能提供服务,但并不影响数据恢复、同步和校验等操作的执行。
(2)活动状态。将工作数据集缓存到内存中,并开始提供数据服务的状态,叫做WBD 的活动状态。活动状态是WBD 的工作状态,在这种状态下WBD 提供的所有操作都能够执行,从而提供高效的数据访问服务。
1.4 工作-备份数据集与分布式共享内存的比较
工作-备份数据集与分布式共享内存的对比见表3。

表3 工作-备份数据集与分布式共享内存的对比
2 基于工作-备份数据集的SAMS模型
2.1 SAMS的组成结构
SAMS是一种主-从模式的分布式元数据管理模型,由一个控制节点(controller)和多个工作节点(worker)构成,并通过工作-备份数据集实现元数据的共享和同步。SAMS维护全局唯一的命名空间,沿用了HDFS/HDFS Federation中目录分层的命名空间划分算法,将命名空间分为多个子空间,每个子命名空间的元数据通过一个WBD 进行管理,这样整个命名空间就划分成了多个WBD,这些WBD 会被分配到工作节点,并提供元数据服务。为了保证SAMS的容错性,每个WBD 被分配到至少3 个不同的工作节点。SAMS组成结构如图4所示。
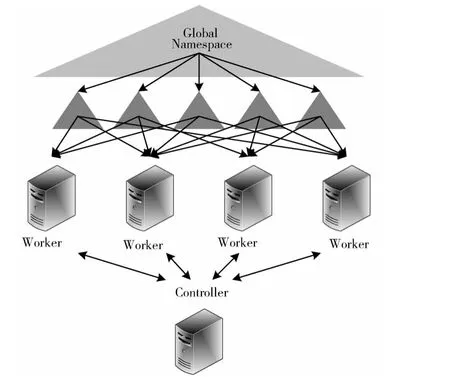
图4 SAMS组成结构
(1)控制节点。控制节点负责整个SAMS集群中各节点的数据同步、数据备份、负载均衡和故障恢复等任务。控制节点会按照命名空间的划分,将各子命名空间对应的WBD 分配给各个工作节点,并对所有工作节点的状态进行监控,维护元数据集群的负载均衡。为了保证元数据的一致性,控制节点上还建立了同步缓存,用于对数据同步进行协调。同步缓存是一个FIFO 队列,其中按序存储了各节点发来的更新记录,每条记录由更新的序号、内容、目标WBD 和目标节点四部分信息构成。
(2)工作节点。工作节点是SAMS中提供元数据服务的节点,负责通过WBD 管理分配到的子命名空间,提供目录查询、数据定位等元数据服务。每个工作节点上可以运行一个或多个WBD,这些WBD 之间相互独立,不需要互相协调,各自管理自己的子命名空间。
2.2 SAMS的运行策略
2.2.1 数据放置策略
在分布式文件系统中,元数据的数据总量相对较小,虽然可能超过单个节点的内存容量,但在节点的外部存储器上进行全冗余备份是可行的。因此,对于构成命名空间的WBD,SAMS按照 “全冗余部署,分布式运行”的策略进行放置:
(1)全冗余部署。在全部节点(包括控制节点)上对WBD 按照全冗余方式进行部署,保证每个节点在数据上的一致性;
(2)分布式运行。工作节点按照分配的子命名空间,加载相应的WBD,使之进入活动状态,开始提供元数据服务。
以这种方式进行数据放置,从局部看,每个工作节点上都部署了全部的WBD,并且大部分都处于预备状态,控制节点可以根据集群负载状况,随时对命名空间的划分进行调整,保证了元数据服务的可用性;从全局看,所有节点(包括控制节点在内)在物理上都是对等的,只是运行的程序和WBD 有所不同,为实现节点的自适应控制提供了条件。
2.2.2 数据更新策略
SAMS的数据更新通过WBD 相关操作实现,具有实时和异步两种不同的更新策略:
(1)实时更新。SAMS通过登记操作对活动状态WBD的OD 进行实时更新,WBD 中其余部分的数据都直接或间接的来自于OD,保证了OD 数据的有效性,也就保证了整个WBD 的数据是有效的。
(2)异步更新。对于WBD 的其余部分,采用异步方式进行数据更新。SAMS会根据OD 的数据量大小,定期执行融合操作,实现对SD、补丁和数据集版本的更新;对于镜像文件,SAMS会根据工作节点负载情况,选择负载较低的时候通过持久化操作对镜像文件进行更新。
通过这样的更新策略,SAMS将数据的更新过程进行了分解,避免一次性更新据造成过大的服务器性能开销。
2.2.3 数据同步策略
为了保证元数据的一致性,提供可靠的元数据服务,SAMS中需要对元数据进行同步,采用了强一致性同步和最终一致性同步两种策略,分别与数据更新策略中实时更新和异步更新相对应。
(1)强一致性同步。在SAMS中元数据服务通过活动状态的WBD 提供,因此需要对活动状态的WBD 维护强一致性。又由于WBD 中OD 是更新较为频繁的部分,且对元数据的查询和更新等操作都在一定程度上依赖于OD,所以SAMS对OD 采用了强一致性的同步策略,具体方法是:当某工作节点需要更新OD 时,会先将更新数据同步到控制节点上,控制节点为这些数据分配一个序号后放入同步缓存中,并将序号返回给该工作节点,工作节点按照序号将更新数据插入OD 中;当同步缓存不为空时,控制节点会按序取出记录,并将其转发给所有目标节点。OD 的强一致性同步,不但保证了元数据服务的一致性,也保证了各节点在进行融合操作时对SD、数据集版本和补丁的更新是一致的(根据FLP 结论),对维护整个WBD 的一致性具有较大的影响。
(2)最终一致性同步。SAMS中最终一致性同步主要使用在对预备状态WBD 的同步上。这些WBD 并不用于提供元数据服务,因此其数据一致性要求相对较低,由节点自行决定在何时同步,其同步方法可以直接采用分布式文件系统数据同步的方法。
2.3 SAMS的自适应特性
SAMS的自适应特性包括控制节点的自适应性、工作节点的自适应性和命名空间的自适应性。
2.3.1 控制节点的自适应性
由于节点都是对等的,当集群需要一个新的控制节点时(比如第一次运行或是原控制节点宕机),SAMS可以通过控制节点选举算法从所有节点中快速选出一个新的控制节点,因此SAMS中的控制节点是具有自适应性的。
从易于实现的角度出发,SAMS采用了一种仿效Paxos的两阶段选举算法SimpleElect,通过节点之间的消息传递,实现控制节点的选举。按照SimpleElect算法,选举过程分为Propose和Accept两个阶段,每个阶段又包括Request和Response两个部分,系统中同一时刻可能存在多个正在进行的选举,但只有一个选举能够完整执行Accept阶段,并完成选举。SimpleElect算法中,同一节点可以同时扮演两种角色Proposer和Acceptor,分别用于发起选举和接受选举。当某工作节点发现控制节点宕机时,开始执行SimpleElect,发起选举,算法流程如下:
(1)Propose request:Proposer向Acceptor广播选举请求消息,内容为选举编号和节点ID。每个Proposer的选举编号都从1开始,按选举次数递增。
(2)Propose response:Acceptor接收到选举请求消息后,判断收到的选举编号是否大于本地缓存的最大选举编号:是,则缓存新编号,并回复接受消息,内容为Acceptor之前缓存的最大选举编号;否,回复拒绝消息;
(3)Accept request:Proposer接收到回复消息后,判断回复消息的内容是否为空:是,进入(4);否,终止当前选举;
(4)Accept request:Proposer接收到全部回复消息后,判断是否超过半数回复为接受:是,Proposer广播选举确认消息,内容与选举请求消息一致;否,随机等待一段时间,提高选举编号,重启Propose过程;
(5)Accept response:Acceptor收到选举确认消息后,将控制节点设置为Proposer的节点ID,清空缓存的选举编号,返回确认消息。
(6)Accept response:Proposer判断接收到的确认消息是否超过半数:是,Proposer改变工作状态,成为新的控制节点,选举结束;否,重启选举过程。
2.3.2 工作节点的自适应性
当工作节点数目发生变化时,控制节点会自动进行处理:
(1)新工作节点上线时,控制节点会计算应分配给新节点的子命名空间,并将分配信息和WBD 备份数据集发送给新节点,新节点通过这些数据重建WBD 工作数据集,并开始提供元数据服务。
(2)某工作节点宕机时,控制节点对当前命名空间的划分情况进行评估,判断是否需要对分布情况进行调整,并根据判断结果进行相应操作。
2.3.3 命名空间的自适应性
控制节点会根据每个子命名空间对应的WBD 的数据量大小,对命名空间的划分进行动态调整。
(1)当WBD 数据量过大,接近节点内存上限时,控制节点会对该WBD 对应的子命名空间进行进一步的划分,并通过WBD 的分裂操作将该WBD 分成两个新的WBD,并重新分配到其它节点上进行管理。
(2)当WBD 数据量过小,导致WBD 个体数量过多时,控制节点会对多余的子命名空间进行合并,并使用WBD 的合并操作将该WBD 合并到同级WBD 中。
2.4 比 较
SAMS与HDFS Federation元数据模型的对比见表4。

表4 SAMS与HDFS Federation元数据模型的对比
3 实验分析
本文首先在Linux环境下通过Java对WBD 进行了实现,并以HDFS Federation(Hadoop 0.23.0)为基础实现了一个SAMS原型系统。实现过程中,最大化的利用了HDFS原有代码,包括命名空间划分算法、备份数据集同步等算法和功能都通过HDFS原有代码进行实现。原型系统部署在4个元数据节点,10个数据节点的实验集群上,各节点通过千兆网卡连接,所采用的服务器硬件指标见表5。实验中使用约800G各类数据存储在HDFS中作为实验数据。

表5 服务器硬件指标
3.1 文件I/O 性能基准实验
本实验对SAMS 的文件I/O 性能进行测试,通过与HDFS Federation和HDFS进行对比,分析SAMS 的I/O性能特征。实验方法:采用LoadRunner模拟100用户进行并发读/写操作,记录平均响应时间。为了不相互干扰,读写实验分开进行,读/写操作每次随机读取/写入大小为100K 的数据块。
图5显示了3种系统对读/写操作的平均响应时间,可以看到,3 种系统的文件读取操作响应时间基本持平,SAMS的写操作响应时间要略低于HDFS Federation 和HDFS约15ms,分析其原因在于:HDFS和HDFS Federation每完成一次元数据操作会将其记录到editlog中,带来一定的磁盘I/O;而在SAMS中,除了持久化,所有元数据操作均在内存中完成,提高了元数据访问效率。
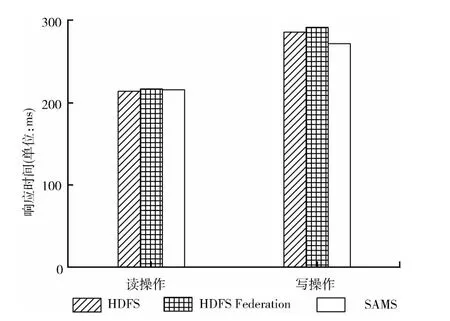
图5 I/O 操作响应时间对比
本实验结果充分说明,WBD 能够有效地降低分布式元数据管理带来的额外性能开销;并且,由于采用了全内存的元数据管理,使整体文件I/O 性能得到了微小的提升。
3.2 容错性实验
3.2.1 元数据可用性实验
本实验测试节点宕机对SAMS 文件访问的影响,以HDFS Federation为对比。实验方法:通过shell脚本让一台元数据服务器在测试中自行断开网络,模拟服务器宕机的情况。在宕机前后,分别采用LoadRunner模拟10000次随机读取操作,记录宕机前后文件读取操作的成功次数。结果见表6,当HDFS Federation元数据节点宕机时,会导致部分文件无法访问,而SAMS由于采用了多重冗余设计,单个元数据节点故障不影响文件的访问。
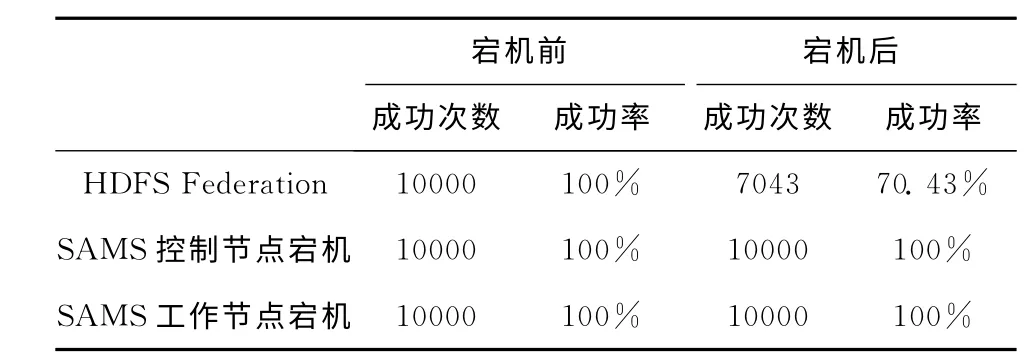
表6 宕机前后读操作成功率对比
3.2.2 宕机性能影响实验
本实验通过对比正常运行、工作节点宕机和3种控制节点宕机情况下元数据的查询效率,测试节点宕机对SAMS元数据服务性能的影响。实验方法:通过LoadRunner模拟100用户并行执行元数据随机查询,并通过shell脚本让指定服务器在测试开始600 秒左右自行断开网络,输出操作执行的TPS曲线,分析丢失节点时SAMS元数据服务的性能变化。结果如图6,在正常运行的状态下,元数据查询操作的TPS曲线快速上升并保持在27000左右;在工作节点宕机的对照组中,可以看到随着控制节点宕机,元数据查询操作TPS迅速下降到约16000,并最终稳定在17000左右,原因在于工作节点的宕机,导致提供元数据服务的节点减少,服务性能下降;在控制节点宕机的对照组中,控制节点宕机后,经过了一小段时间,元数据查询操作TPS才快速下降到约15000,并同样稳定在17000左右,原因是当控制节点刚刚宕机时,对集群性能并无太大影响,但是当某个工作节点被选举为新的控制节点后,服务节点减少,集群状态与工作节点宕机后的集群状态保持一致。
容错性实验表明,丢失节点虽然会造成一定的性能下降,但不会导致元数据服务的失败,SAMS具有较好的容错性,保证了元数据服务的高可用性。
3.3 扩展性实验
本实验通过增加新的元数据节点,测试SAMS的扩展能力。实验方法:通过LoadRunner模拟100用户并行执行元数据随机查询,并从600s开始,每300s增加一个工作节点,总共增加3个,输出操作执行的TPS曲线,分析增加节点时SAMS元数据服务的性能变化。图7展示了元数据随机查询操作的TPS曲线,在3次增加新节点后,SAMS性能都出现阶梯状增长,表明SAMS的性能与节点数量呈现出一定的线性关系,具有良好的横向扩展性。
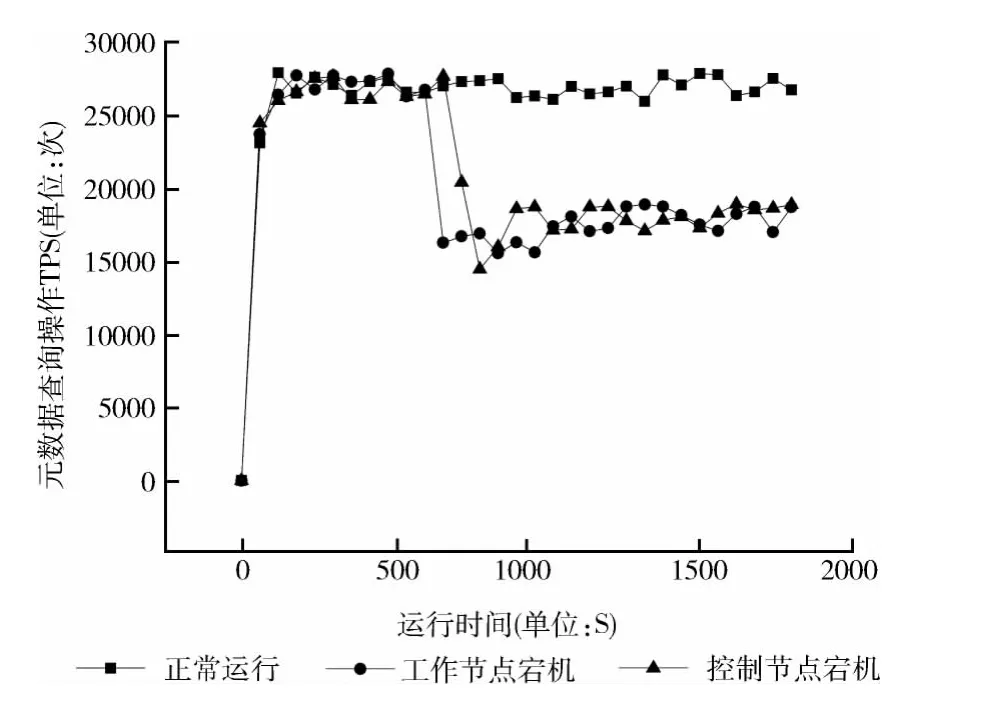
图6 宕机实验元数据查询操作TPS
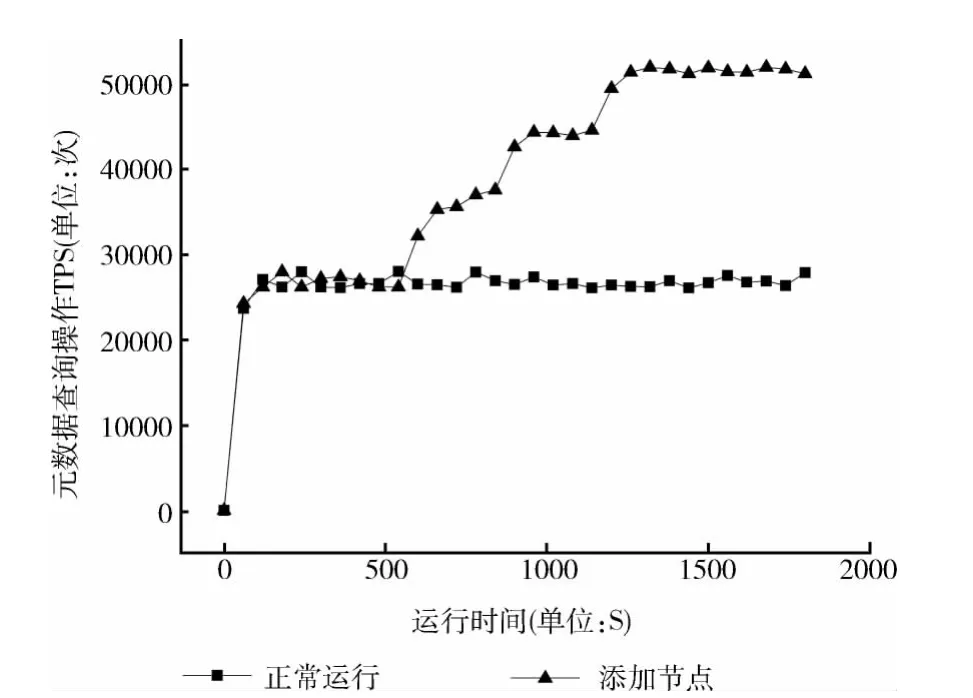
图7 扩展实验元数据查询操作TPS
4 结束语
本文针对分布式文件系统元数据管理模型存在的不足,重点论述了WBD 的构造、状态和操作,设计并实现了一种分布式文件系统元数据管理模型SAMS。实验分析表明,采用SAMS作为分布式文件系统的元数据管理模型,在维持元数据服务性能的基础上,实现了高容错性和高扩展性。下一步的研究重点是在更大规模的集群中测试WBD 和SAMS的性能特点,并对其进行优化。
[1]WU Wei.Research on metadata management in large-scale storage system [D].Wuhan:Huazhong University of Science and Technology,2010 (in Chinese).[吴伟.海量存储系统元数据管理的研究 [D].武汉:华中科技大学,2010.]
[2]LIU Aigui.Metadata service model for distributed file systems[EB/OL].[2011-09-05].http://blog.csdn.net/liuaigui/article/details/6749188.(in Chinese).[刘爱贵.分布式文件系统元数据服务模型[EB/OL].[2011-09-05].http://blog.csdn.net/liuaigui/article/details/6749188.]
[3]Wikipedia.Google file system[EB/OL].[2013-01-30].http://en.wi-kipedia.org/wiki/Google_File_System.
[4]The Apache Software Foundation.HDFS architecture guide[EB/OL].[2011-05-04].http://hadoop.apache.org/common/docs/current/hdfs_design.html.
[5]Oracle.Lustre internals documentation[EB/OL].[2010-04-06].http://wiki.lustre.org/lid/index.html.
[6]ZHAO Yuelong,XIE Xiaoling,CAI Yongcai,et al.A strategy of small file storage access with performance optimization[J].Journal of Computer Research and Development,2012,49 (7):1579-1586 (in Chinese).[赵跃龙,谢晓玲,蔡咏才,等.一种性能优化的小文件存储访问策略的研究 [J].计算机研究与发展,2012,49 (7):1579-1586.]
[7]LIU Lian,ZHENG Biao,GONG Yili.Metadata processing optimization in distributed file systems[J].Journal of Computer Applications,2012,32(12):3271-3273(in Chinese).[刘恋,郑彪,龚奕利.分布式文件系统中元数据操作的优化[J].计算机应用,2012,32(12):3271-3273.]
[8]LIU Aigui.Research of the GlusterFS [EB/OL].[2011-09-05].http://blog.csdn.net/liuaigui/article/details/6284551.(in Chinese).[刘爱贵.GlusterFS集群文件系统研究[EB/OL].[2011-03-28].http://blog.csdn.net/liuaigui/article/details/6284551.]
[9]XUE Wei,ZHU Ming.Dynamic management system of distributed metadata [J].Computer Engineering,2012,38(4):63-66 (in Chinese).[薛伟,朱明.一种分布式元数据的动态管理系统 [J].计算机工程,2012,38 (4):63-66.]
[10]CAI Tao,NIU Dejiao,LIU Yangkuan,et al.NVMMDS:Metadata management method based on non-volatile memory[J].Journal of Computer Research and Development,2013,50 (1):69-79 (in Chinese).[蔡涛,牛德姣,刘扬宽,等.NVMMDS——一种面向非易失存储器的元数据管理方法[J].计算机研究与发展,2013,50 (1):69-79.]
[11]DONG Xicheng.Introduction of HDFS federation[EB/OL].[2011-12-01].http://dongxicheng.org/mapreduce/hdfs-federation-introduction/(in Chinese).[董西成.HDFS Federation设计动机与基本原理[EB/OL].[2011-12-01].http://dongxicheng.org/mapreduce/hdfs-federation-intro-duction/.]
[12]Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets,a fault-tolerant abstraction for in-memory cluster computing [R].San Francisco:University of California at Berkeley,Technical Report No.UCB/EECS-2011-82,2011.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
客联(2021年3期)2021-09-10
现代计算机(2021年16期)2021-08-06
环球时报(2020-11-02)2020-11-02
铁道通信信号(2020年4期)2020-09-21
湖北函授大学学报(2017年6期)2017-06-16
科技视界(2017年2期)2017-04-18
