
自然语言词性序列的分类
2014-12-13 03:18:38徐芃,熊健
华南师范大学学报(自然科学版) 2014年4期
徐 芃,熊 健
(1.广州大学心理咨询中心,广州510006;2.广州大学经济与统计学院,广州510006)
1 问题背景
语言表征是心理表征的符号现实,个体的心理差异具有外显的行为学倾向[1]. 已有的语言与心理相关性的大量研究支持语言影响思维,语言是思维的现实表征的理论. 语言表征与心理表征具有一致性,例如,语言可以引起相应的表情,情绪词的情绪信息对新异刺激喜好度变化具有自下而上的自动化联想学习过程的调节机制[2],语言结构对心理活动产生影响,不同的说话方式展示不同的人际关系、个性,甚至自我认识[3]. 词性内隐着认知机制,例如,名词动用在词性上发生变化,其转喻的特点和表现不同[4];种类量词中倾向于“种”的词,其思维也越倾向于抽象的上位概念[5].认知机制影响相应的词汇、语义识别,例如,汉英语句的形态不同,语义表征具有共同的认知机制[6];高频词较之低频词容易被认知[7];使用第一人称代词会诱导出现更多的描述个人认知机制的词[8];知觉模拟中词序频率在语义关联判断中的效果远远优于空间意象[9]. 有关语言与思维的相关研究足以表明,客观外显的语言符号是观察主观内隐的思维认知的途径,语言影响思维,语言是思维的现实表征.
认知科学强调外显的语言是思维的工具,语言表达强迫人们以不同的方式组织信息,语言表征的差异可能影响到概念的表征[10];不仅语言的词性是心理的表征标识,即使是语言的速度也对心理发展产生影响:快速的语言是潜意识的映射;而慢速语言的干预能改变意识的过程[11].
使用的语言包含词汇、词序和语法等要素.自然语言逻辑的研究表明,人们会使用由词项构成的句子来表达思维的内容,词项是人们通过词语意义的中介来表达对事物认识的语言指号形式. 自然语言传递心理信息的相关研究发现,不同词的词性,特别是名词、动词、代词、形容词等实词,传递的心理信息也不相同[12],并且在任意句子结构序列中出现;研究还发现,由这4 种词性构成的不同的自然语言结构序列,其语言使用者的阅读理解水平也存在高水平和低水平差异显著的2个类别[13].
认知语言学从语言分析的视角来观察语言与心理的关系,在定性分析的基础上进行语言定量分析逐渐成为语言分析的重要方法. 数学模型是结合定性与定量分析,同时必须以定量的方式呈现对事物系统的特征或数量依存关系的描述与推断的方法,其特征比较适合描述对语言的定性与定量分析. 另一方面,文本分类也是自然语言处理中数据挖掘的重要方法.数学模型所特有的对自然语言结构序列这种客观现象的描述与分类功能,可以帮助人们更好地理解和认识通过外显的语言表征传递出来的内隐的思维形式.鉴于问题提出中已有的语言与心理相关性的定性与定量分析基础,本项研究首先对语料数据进行数学建模的粗粒化处理,突出语言信息中名词、动词、形容词和代词的主效应特征,然后利用中国科学院计算机技术研究所的中文自然语言处理平台(ICTCLAS)将4个主效应信号表示成适当的数学对象,建构由名词、动词、形容词和代词这4 种实词构成的自然语言结构词性序列的描述与分类的数学模型,对自然语言表征传递不同心理信息的分类规律进行科学的观察.
2 模型假设与问题陈述
2.1 模型的条件与假设
2.1.1 数据预处理 在1 项142 人(来源于某大学通识类选修课的大二至大四的学生,专业覆盖理工科、文科和艺术类)参加的5个主题句作业报告中,随机选择60 份作业报告,确定抽取每份作业报告的第5个句子作为自然语言序列研究样本. 采集到的语料数据符合本项的研究要求. 由于本项研究关注的是语言表征的词项序列问题,142 份数据样本中,第5个句子均为完整句子,因此确定每份作业报告的第5个句子作为自然语言序列的研究样本.
随机选择的60 份语料数据通过中文自然语言处理平台(ICTCLAS)处理,得到一级标注词性切分的60个自然语言词性表达序列,如“nanvrnnv”、“rvvvvvrnvn”等,其中,n 为名词标识码,a 为形容词标识码,v 为动词标识码,r 为代词标识码.
基于问题提出中对语言与心理关系的理解,我们对语言序列进行主信号的粗粒化处理,在每一个语言序列中只留下可能表达更多概念表征的名词(n)、动词(v)、形容词(a)和代词(r)的标志符号,研究样本的数据处理为如下形式的序列:(1)nrvavvnv;(2)nanvrnn. 由于名词是描述对实体或抽象事物认识结果的摹状词,在语言表征思维的命名与必然性的语言指号中具有十分重要的作用,因此在60份语言表征序列中,以名词(n)的含量比例作为判断依据,区分名词n 含量排列靠前的10个序列为A类,名词n 含量排列靠后的10个序列为B 类,这20个序列为学习样本;在剩下的40个序列中,随机挑出20个序列作为测试样本.
2.1.2 正态分布假设 在词性构成的自然语言词性序列中,假设具有随机性的名词、动词、形容词、代词的含量服从正态分布.
2.1.3 符号说明
nn:任一给定序列中词性n(名词)在这一序列总词量中的比例含量;
nv:任一给定序列中词性v(动词)在这一序列总词量中的比例含量;
na:任一给定序列中词性a(形容词)在这一序列总词量中的比例含量;
nr:任一给定序列中词性r(代词)在这一序列总词量中的比例含量;
Gi:由某些具有相同属性的个体组成的类.
2.2 问题陈述
有20个已知类的经过中文自然语言处理平台(ICTCLAS)一级标注词语切分的样本序列,其中序列标号A1~A10为A 类,A11~A20为B 类.要求从中提取特征,构造分类方法,并对另外未标明类别的20个中文自然语言处理平台制造的自然语言序列(A21~A40)进行分类. 任何一个随机的自然语言词性序列中包含的词性含量和词性所处的位置,反映该语言序列在数量和序位上的特征:第一,语言序列中的不同词性的总量,表明该语言序列反映心理信息的内容;第二,语言序列中的不同词性的先后位置的序位形式,表明该语言序列反映心理信息的形式.
3 不同词性含量的词性序列分类
3.1 分类模型的基本原理
对于反映心理信息内容的不同词性含量的自然语言词性序列,可以采用序列中n,v,a,r 在序列总词量中的比例含量作为该序列的特征,这样抽取特征的方法具有其认知心理学的意义.例如,在人们的语言表述中,有的时候在使用自然语言传递心理信息时会较多使用名词n 和动词v 来表达对客观事件的认知信息,当情绪信息强烈时人们又会较多使用形容词a 和代词r 来表达个人的心理感受,虽然语境不同,人们使用的具体词语可能也不相同,但是个体在相似刺激条件下的心理反应形式却是相同的.因此,相比于语境中的具体词语,词性本身包含了不同类别的心理信息,更适合成为观察语言词性序列的结构符号.将序列中n,v,a,r 的含量分别记为nn,nv,na,nr,得到一组表征该序列特征的思维向量(nn,nv,na,nr),其线性相关为:nn+nv+na+nr=1.
由于语言词性序列中nn,nv,na,nr四维向量的计算过于繁琐,而任意语言词性序列中的向量特征Xi(i 为标号)和其他向量的关系都可演变成一个三维向量空间的对映点,例如,nr=1- nn- nv- na,相比较四维向量更方便线性代数的计算.
设不同词性含量词性序列分类的判别问题是:在k个类别词性序列(N1,N2,…,Nk)中,任何一个Ni类样品x,都可以得到它的词性序列向量特征值X.已知所属类别的某些样品x1,x2,…,xn组成学习样本,对来自这个类别的某个样本x,依据其特征向量X 的值做出是否归属此类别的判断.
在本项目的已知词性序列分类中,已知k =2,G1=A,G2=B,特征向量X 是三维向量.学习样本n=20个样本,其中A1~A10为A 类,A11~A20为B 类.采用欧式距离(Euclid)分类模型对序列样本进行分类:
(1)分别计算已知的A 类和B 类中各自包含的10个样本点的集合的几何中心:
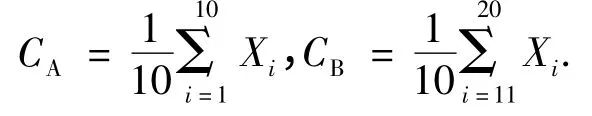
(2)对于给定样本点Xi,计算该点到CA的欧氏距离计算该点到CB的欧氏距离DB
(3)判别标准为:①如果DA<DB,则将Xi点判别为A 类;②如果DA>DB,则将Xi点判别为B 类;③如果DA=DB,则将Xi点判别为不可判类.
3.2 分类模型的应用
运用MATLAB7 编程上述算法并运行,对已知学习样本A1~A20进行分类:
结果A6被错误地分到了B 类,A19被错误地分到A 类,其余18个样本全部正确,分类准确率达到了90%.
用上述欧氏距离分类模型对未知的词性序列A21~A40进行分类,得到结果为:
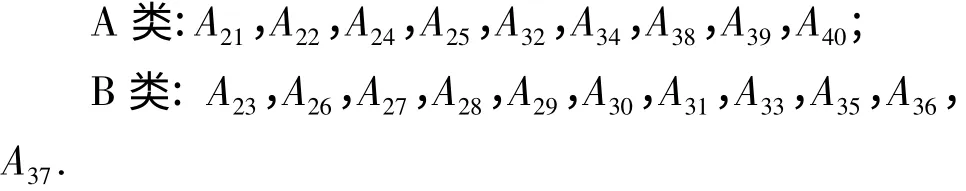
可见,即使单纯从自然语言表征而言,人们使用的自然语言表征也存在不同的类别,这与人们使用自然语言传递心理信息时会有不同类型的思维模式相似.从学习样本原始数据所包含的具体习性来看,A 类多含名词和动词,语言使用者的思维指向多集中在对名词和动词所反映的事物特征的认识上;B类多含形容词和代词,语言使用者的思维指向集中在对自我及心理体验的关注上. 测试样本中的任一词性序列都能归类到某一类别,证明人们总是在使用自然语言或传递对客观事物的认识(A 类),或传递对自我及心理体验的主观认识(B 类),语言是传递心理信息的工具.
4 不同词性序位的词性序列分类
4.1 分类模型的基本原理
虽然基于词量的分类模型采用不同词性n(名词)、v(动词)、a(形容词)和r(代词)的含量特征值作为词性序列的分类依据,具有一定词性投射心理信息的认知语言学意义,并且在欧氏距离分类模型中获得了准确率达到90%的比较理想的结果. 但是,这种以含量为分类标准的方法在抽取语言特征时,没有充分考虑到人们在使用语言时的语序信息量.人们使用语言传达心理信息时,先说什么后说什么是有一定的考虑的.例如,序列nvran 与序列rannv,在这2个词性序列中n(名词)、v(动词)、a(形容词)和r(代词)的词性含量相同,n、v、a 和r 在词性序列中的向量特征值是相同的,但是这2个句子在词性的位序排列结构上却是不同的,例如:

从语言表述来看,这2个句子在主语位置上的词性完全不同,语言使用者表达的关注点也不同,前者更关注“洪水”,后者更关注“他们的家乡”.因此,如果能够直接从序列自身的词性排序来考察语言序列,可能更能够反映语言表达者想要表达的心理信息.因此,需要在不同词性序列的相关度计算的基础上,设计基于词序位置的序列分类模型.
采用基于位置特征的DNA 序列分类模型原理[14],对词性序列样本进行分类:
(1)对于任意词性x 和y,相关运算“x⊗y”的值定义为:
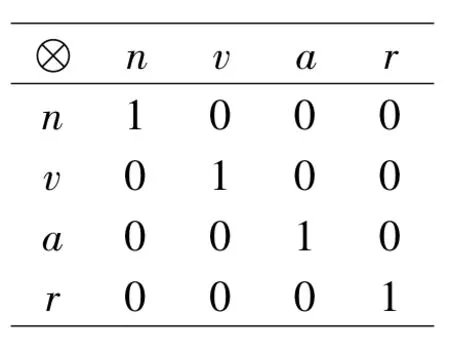
(2)定义哑元O,规定任意词性与哑元的相关运算结果均为0.
(3)对于任意一个长度为N 的序列A ={A0,A1,…,An},它的延拓为一个无限序列::当0≤j <N时;当-∞<j <0 及N≤j <∞时,=0.
(4)对于任意2个序列AX,BY,定义序列A 和序列B 的相关序列Si为:
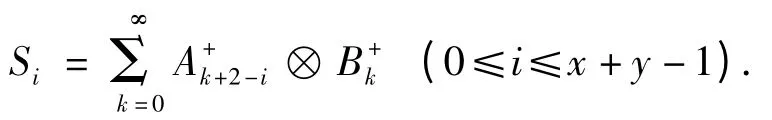
定义序列B 对序列A 的相关度为:
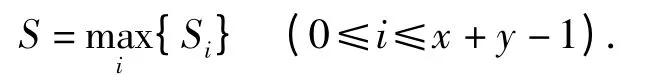
例如,对于序列A ={a,r,a}和序列B ={n,v,a,r,a,r},计算其相关序列度为:

(5)定理1[14]:任意给定3个序列S,A,B,如果A 与S 的相关度大于B 与S 的相关度且B 与A 等长,则A 与S 属于同一类的可能性大于B 与S 属于同一类的可能性.
(6)基于计算原理,序列相关度的分类判别标准为:
①在序列A21~A40中,随机选择任何某个词性序列,分别计算与序列A1~A20中20个词性序列的相关度,计算结果为SS1,SS2,SS3,…,SS20;
②求出前10个相关度的平均值SA=(SS1+SS2+…+SS10)/10,定义SA 为与A 类序列的相关度;
③求出后10个相关度的平均值SB =(SS11+SS12+…+SS20)/10,定义SB 为与B 类序列的相关度;
④记W =SA/SB,根据定理1,如果W >1,将X点判别为A 类;如果W <1,将X 点判别为B 类;如果W=1,将X 点判别为不可判类.
4.2 分类模型的应用
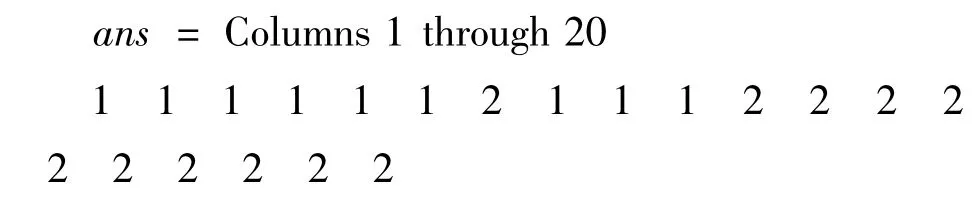
运用MATLAB7 编程上述算法并运行,对已知学习样本A1~A20进行分类:结果A7被错误地分到了B 类,分类的准确率达到了95%,比较基于词量的词性序列分类,分类准确率提高了5个百分点.
用上述基于词性的分类模型对未知的词性序列A21~A40进行分类,得到结果为:

依据定理1 的判别原则:
如果W >1,判别为A 类:A25,A30,A38,A39,A40;
如果W <1,判别为B 类:A21,A22,A23,A24,A26,A27,A28,A29,A31,A32,A33,A34,A35,A36.
在反映词项先后顺序的基于词序位置的自然语言表征分类模型中,序列A21,A22,A24,A32,A34被判别到了B 类,而在只考虑词量的分类模型中,这4个序列是判别在A 类的. 可见,人们使用语言表达心理信息时,即使是要表达的心理信息似乎都表达完整了(词量一样),但是先说什么,后说什么,词性的排列序位不同,语言表征的表达形式不同,仍然有可能传递着不同的心理信息.
5 讨论与结论
5.1 2 种分类模型的比较
对于序列A21、A22、A24、A32和A34,不同词性含量的分类模型和不同词性序位的分类模型有不同的分类结果,可见,在进行词性序列分类时,考虑到词性序列中的词性含量和词性序位等不同的要素,模型分类的方法不同,分类的结果也可能存在差异.基于词序的分类结果准确率为95%,基于词量的分类结果准确率为90%,虽然在20个测试样本中有5个序列的分类结果不同,但是2 种模式的一致分类结果也达到了75%.人们使用客观的语言指号传达主观的心理信息,二者并不一定呈一一对应的关系,形式逻辑的研究表明,相同的语言指号可能传达不同的心理信息,相同的心理信息也可以用不同的语言指号来传达.鉴于自然语言词性序列的特征,我们采用一个联合判定原则:对于任何词性序列,如果2 种分类模型的结果一致时,认为序列判别有效;如果不一致时,认为该序列为不可判类,不影响2 类分类法的算法.使用语言的语序可能传递更多的信息,基于词序的分类结果准确率也高于基于词量的准确率,因此在分类模型的实际应用时,我们设置一个使用条件:如果研究对象的总词量大,趋向于应用基于词量的分类模型;如果研究对象的总词量少,趋向于应用基于词序的分类模型.
5.2 分类模型的应用价值
就语言词性序列分类模型在认知心理学的应用价值而言,不仅揭示和证实了客观的语言符号与主观的心理信息之间存在的相关关系,而且通过外显的语言表征可以对内隐的心理信息做出科学的评估.自然语言词性序列的分类模型应用到教育领域,可以为实践中具体问题的解决提供语言干预的策略和技能.例如,我们在心理咨询的实践中观察到,社会适应困难的当事人,其语言表征就具有自然语言词序分类中B 类的特征,即名词和动词含量少,而形容词和代词的含量多;社会适应无困难的非当事人,其语言表征则呈现A 类的特征,以A 类自然语言表征为干预目标,也能达到心理治疗的目的.自然语言词性序列的分类模型还可以应用到机器学习领域,解决自然语言处理中的歧义问题,成为机器学习方法训练分类器模型源中的目标域,从而提高机器的“思维”水平.
5.3 结论
外显的自然语言序列可以分类.本项研究表明反映自然语言表征序列内容的基于词量的自然语言分类模型准确率为90%;反映自然语言表征序列形式的基于词序位置的自然语言分类模型准确率为95%,不仅揭示了语言与心理信息之间存在的相关关系,而且也证实了通过客观存在的语言符号可以对内隐的心理信息做出科学的评估.
[1]陈少华,郑雪. 论个体心理差异的行为学遗传取向[J].华南师范大学学报:自然科学版,2001(2):31-35.Chen S H,Zheng X. On the behavioral genetics orientation individual differences[J]. Journal of South China Normal University:Natural Science Edition,2001(2):31-35.
[2]郭晶晶,杜彦鹏,陈玉霞,等. 情绪词对新异刺激喜好度变化的调节机制[J]. 心理学报,2011,43(4):364-372.Guo J J,Du Y P,Chen Y X,et al. The modulation mechanism of emotional words on neutral stimuli's preference[J].Acta Psychologica Sinica,2011,43(4):364-372.
[3]Pennebaker J W,Mehl M R,Niederhoffer K G. Psychological aspects of natural language use:Our words,our selves[J]. Annual Review of Psychology,2003,54(1):547.
[4]王薇.名词动用的认知修辞研究[D].上海:上海外国语大学,2008.Wang W. A cognitive and rhetoric study of denominal verbs[D]. Shanghai:Shanghai International Studies University,2008.
[5]冯冬梅.种类量词的认知研究[D]. 桂林:广西师范大学,2010.Feng D M. The cognitive study on the sort of measure words[D]. Guiling:Guangxi Normal University,2010.
[6]李荣宝,彭聃龄,郭桃梅.汉英语义通达过程的事件相关电位研究[J].心理学报,2003,35(3):309-316.Li R B,Peng D L,Guo T M. A study on Chinese and English semantic access with erp technology[J]. Acta Psychologica Sinica,2003,35(3):309-316.
[7]Azarbehi R,Piercey C D,Joordens S. The effects of word variability on the lexical decision task[J].North American Journal of Psychology,2011,13(3):427-434.
[8]Seih Y T,Chung C K,Pennebaker J W. Experimental manipulations of perspective taking and perspective switching in expressive writing[J]. Cognition & Emotion,2011,25(5):926-938.
[9]Tse C S,Kurby C A,Du F. Perceptual simulations and linguistic representations have differential effects on speeded relatedness judgements and recognition memory[J].Quarterly Journal of Experimental Psychology,2010,63(5):928-941.
[10]刘丽虹,张积家. 语言如何影响人们的思维[J]. 自然辩证法通讯,2009,31(5):22-27.Liu L H,Zhang J J. Language how to affect the thinking?[J]. Journal of Dialectics of Nature,2009,31(5):22-27.
[11]Love T,Walenski M,Swinney D. Slowed speech input has a differential impact on on-line and off-line processing in children's comprehension of pronouns[J].Journal of Psycholinguistic Research,2009,38(3):285-304.
[12]徐芃.科学思维类组的语言结构形式探讨[J].广州大学学报:社会科学版,2005,l4(7):79-82.Xu P. An analysis of language structure of science thinking classification[J]. Journal of Guangzhou University:Social Science Edition,2005,l4(7):79-82.
[13]徐芃.语言结构干预对阅读理解影响的实证研究[J].当代教育理论与实践,2011,3(6):20-123.Xu P. An empirical study of language structure intervention effects on reading comprehension[J]. Theory and Practice of Contemporary Education. 2011,3(6):20-123.
[14]韩轶平,余杭,刘威,等.DNA 序列的分类[J]. 数学的实践与认识,2001,31(1):38-45.Han Y P,Yu H,Liu W,et al. Classification of DNA sequences[J].Mathematics in Practice and Theory,2001,31(1):38-45.
猜你喜欢
光明少年(2024年5期)2024-05-31 10:25:59
当代陕西(2022年4期)2022-04-19 12:08:54
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
娃娃画报(2019年11期)2019-12-20 08:39:45
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
数学学习与研究(2017年3期)2017-03-09 18:12:42
