
基于超算平台和Hadoop的并行转码方案设计
2014-11-20 08:19:14刘炳均戴云松
电视技术 2014年7期
刘炳均,戴云松
(1.中山大学软件学院,广东广州510006;2.广州耘趣网络科技有限公司,广东广州510000)
在当今时代,电视网、电信网和互联网的融合要求视频数据可以同时在电视、手机和网络进行播放。但是,由于不同平台的网络带宽状况、终端播放设备、用户需求千差万别,视频的编码格式、分辨率、帧率也各不相同。因此,需要对视频进行转换编码。但是,当前的视频转码存在两个问题,一是计算量巨大,视频数据存在着海量化的趋势;二是实时性难以保证,用户不能在可容忍的时间内得到转码结果。
当前,对于大规模的视频转码,主流的解决方案有单机服务器转码和分布式服务器转码。然而,单机服务器转码计算能力有限,分布式视频转码实现复杂,都不容易实现。笔者提出利用Hadoop搭建一个分布式转码系统,结合超算平台的强计算能力和多核多线程的特点以及MIC架构的并行处理优势进行大规模的转码任务,有效解决了上述问题。
1 技术基础
1.1 超算平台
广州超级计算中心的业务主机为天河二号,是当前世界最快的超级计算机。超算平台主要有3个特点:一是计算能力强,天河二号由16 000个节点组成,单个节点有3.431 Tflops运算能力,16 000 个节点总计可达54.9 Pflops性能;二是多核多线程,每个节点有2个CPU处理器和3个MIC协处理器,并支持多线程编程;三是存储容量大,每个运算节点有64 Gbyte主存,而每个MIC协处理器板载8 Gbyte内存,因此每个节点共有88 Gbyte内存,总计16 000个节点一共有1.404 Pbyte内存,而外部存储器容量方面更是高达12.4 Pbyte。
天河二号使用的MIC协处理器是Intel公司推出的基于集成众核(Many Integrated Core,MIC)架构的至强融核系列的一个产品。该产品双精度性能达到每秒一万亿次以上,并且支持并行编程模型。对于采用传统CPU平台很难实现性能进一步提升的部分应用,例如并行视频转码,使用MIC协处理器是一个很好的选择[1]。
1.2 Hadoop
Hadoop是一个实现了MapReduce模式的开源分布式计算框架。通过Hadoop,程序员可以方便快捷地开发分布式程序,利用计算机群的强处理能力和高存储空间对海量数据进行分布式处理。Hadoop的核心设计还包括一个分布式文件系统(HDFS)及分布式数据库(HBase)[2]。图1是Hadoop的组成示意图。
MapReduce是Google提出的一种软件编程模型,其作用是帮助用户开发处理大规模数据集的应用程序。MapReduce的主要思想是将海量数据处理问题划分为Map(映射)阶段和Reduce(化简)阶段。当发起一个作业时,MapReduce模型会把输入的大数据集分割成若干个数据块,在Map阶段分发到多个Map任务中并行处理,得到处理后的数据块,然后进入Reduce阶段,Reduce任务将所有结果合并成最终结果,并存储在文件系统上[2],如图2所示。

图1 Hadoop的组成示意图
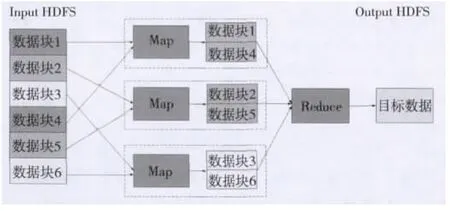
图2 MapReduce模型作业流程图
HDFS是一个分布式文件系统。HDFS集群采用master-slave结构,由一个NameNode节点和多个DataNode节点组成。NameNode节点是主服务器,负责管理文件命名空间和调节客户端访问文件系统。DataNode负责提供实际的存储服务。当一个文件提交到HDFS中时,HDFS会将该文件分割成一个或者多个块,并存储在若干个Data-Node节点中,每个块都有多个副本,分别存储在不同的DataNode上。同时,NameNode节点记录块与DataNode之间的映射关系。当需要对文件进行读写时,客户端从NameNode获取文件的元数据(Metadata),得到所有文件块的存储位置,再从相应的DataNode直接进行读写操作。具体如图3所示。
HBase建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统,适合用来存储非结构化和半结构化的松散数据,例如视频数据。它可以横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
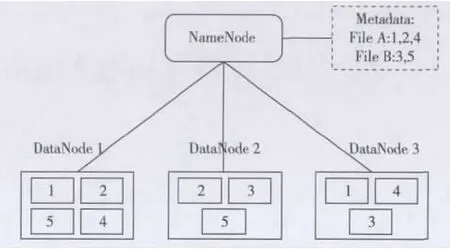
图3 HDFS体系架构图
1.3 FFmpeg
FFmpeg是开源免费跨平台的视频和音频流方案,它的主要功能有视频采集功能、视频格式转换、视频抓图、给视频加水印等。FFmpeg包含了3个重要组件,分别是libavcodec,libavformat和 ffmpeg命令行工具。其中,ffmpeg命令行工具是一个可执行的文件,输入需要的参数,就能完成相应的媒体处理操作。例如将.mpg转成.avi:
ffmpeg - i video_origine.mpg video_finale.avi
2 整体架构设计
由于超算平台由众多的节点组成,每个节点均可独立工作,多个节点可协同工作,相当于传统分布式系统中的集群。本解决方案是以节点为单位搭建基于超算平台的视频转码系统。
本系统主要由任务控制节点、视频分割节点、Hadoop节点组构成,其中Hadoop节点组的核心部分是HDFS模块和MapReduce模块。任务控制节点负责接收客户端的任务请求,配置任务信息,监控任务进度,控制其他节点处理任务和返回任务结果。视频分割节点负责将一个视频分割成若干个视频块。Hadoop节点组的HDFS模块负责视频块的存储,MapReduce模块完成视频转码工作和视频块合并工作。系统整体架构如图4所示。

图4 系统整体架构图
各流程详细说明如下:
1)客户端发起一个转码请求,任务控制节点接受用户上传的视频,处理用户输入的任务配置信息,分析视频数据并生成任务对象,开始转码作业。
2)任务控制节点将视频传输给视频分割节点,并通知该节点将视频分割成若干个视频块。
3)视频分割节点将分割结果存储在Hadoop节点组的HDFS中。
4)视频分割节点通知任务控制节点分割作业完成,并返回分割后各个视频块的信息,例如大小和存储位置等。
5)任务控制节点根据任务对象的信息(任务要求时间、视频大小、转码要求等)构建合适的MapReduce作业框架,
6)MapReduce模块完成对视频块的转码任务和合并任务,并把目标视频存储在HDFS中。
7)MapReduce模块返回任务完成信息和目标视频的存储信息。
8)任务控制节点返回任务完成信息到客户端,并提供目标视频的存储位置。
9)用户从HDFS模块下载目标视频,转码请求完成。
2 技术实现
2.1 任务控制节点
当客户端发起一个转码请求时,任务控制节点分析上传的源视频和用户配置的任务需求,对当前转码任务进行建模,生成一个n维的任务特征向量T,其中T=[t0,t1,t2,…,tn-1],每一维都描述了转码任务的某一属性,例如任务状态、视频名称、视频时长、视频大小、视频源与目的编码方式、视频源与目的比特率、任务限时、目标视频大小限制、视频块与HDFS的映射表等,并将其加入队列TaskQueue中。
任务控制节点每次取出位于TaskQueue队头的向量对象T,并根据T中的信息,生成相应的指令信号I,例如进入下一执行阶段或者重做当前阶段等,最后将T和I传输到下一节点,如此循环,直到TaskQueue为空。
2.2 视频分割节点
在Hadoop系统中,存储在HDFS的文件是由一个或者多个数据块组成,而且由于MapReduce框架的Map任务通常是并发执行,所以需要对视频数据进行分割。但是,视频数据是非结构化数据,视频中帧与帧存在着关联性,简单的物理划分会导致视频数据信息受损。
所以在该节点中,需要使用专门的媒体处理工具来实现视频分割的功能,例如FFmpeg,mencoder等。在实现时,可以在视频分割节点集成多种视频分割工具。
视频分割节点接受任务控制节点传递过来的任务对象T和指令信号I,从T中提取视频信息并分析,动态选取最合适的工具,最后生成一个个互相独立的视频块并存储在HDFS的各个DataNode中等待转码处理,同时更新任务对象T,并传输回任务控制节点,加入队列TaskQueue中等待下一步处理。
2.3 MapReduce模块
MapReduce模块接受任务控制节点传递来的任务对象T和指令信号I,然后根据T中信息,获取视频块的存储位置,即DataNode编号,开始转码作业。
作业分为两个阶段:Map阶段和Reduce阶段。Map阶段负责视频块的转码,在这个阶段,多个Map任务并行执行。每个Map任务都运行在存储其要处理的视频块的DataNode上,这样避免了节点间的文件传输。Map任务结束后,转码结果不上传到HDFS中,而是保留在本地节点。所有的Map任务完成后,开启Reduce阶段,在这个阶段,Reduce任务只有一个,它会访问所有执行Map任务的节点,取得各个视频块的转码结果,然后按顺序合并成目标视频,最后上传至HDFS中,同时,更新并传输对象T到任务控制节点。
2.3.1 移植FFmpeg到MIC(Map阶段)
视频转码工作是发生在MapReduce框架的Map阶段。
由于Hadoop是基于Java,在Map任务中使用FFmpeg需要Java提供的Runtime类,运行该类中的 exec(String cmdArray[])方法就可以调用FFmpeg命令行工具这个可执行文件。只需将可执行文件放置在Hadoop框架可以访问到的位置。
在本方案中,执行转码任务的是FFmpeg,FFmpeg是开源的,这意味着可以修改其源代码,重新编译出一个适合运行在MIC卡上的FFmpeg可执行文件。MIC并没有单独的编程语言,MIC编程是对C/C++/Fortran语言进行扩展,加入编译指令或指导指令,使用最简单的方法让现有的程序在尽量不做改动的情况下,能够利用MIC的计算资源,其中最基本的关键字是offload。其作用是:在offload作用范围内(即最靠近offload语句下面的第一个代码段)的程序代码,是要在MIC卡上运行[3]。一个最简单的例子如下:


该代码中的for循环将在MIC卡上运行。
MIC芯片通常有数十个精简的x86核心,提供高度并行的计算能力。所以,在移植FFmpeg时,可以对其进行并行化,进一步加速其转码速度。本方案使用的手段是OpenMP。OpenMP是一种API,用于编写可移植的多线程应用程序,它能够为编写多线程应用程序提供一种简单的方法,而无需程序员进行复杂的线程创建、同步、负载均衡和销毁工作。OpenMP采用引语的方式对程序进行并行化,其中最常用的方法是对循环进行并行化[4]。上面例子使用OpenMP并行化后如下:

通过使用MIC编程与OpenMP,将原来运行在CPU上的FFmpeg程序移植到MIC卡,充分发挥MIC架构的浮点运算能力和高度并行能力,从而加速视频转码的效率。
2.3.2 任务并行化(Reduce阶段)
视频合并工作是发生在MapReduce框架的Reduce阶段。在这个阶段,Reduce任务在所有Map任务完成后启动,读取所有转码后的视频块,并按照其编号的顺序,合并视频。传统的解决方案一般会以串行的方式完成这个工作,而且由于受运行节点的主存容量限制,合并过程中产生的中间结果需要存放在硬盘上,I/O开销较大。
针对这种情况,本方案利用超算节点多核多线程的特性,将视频合并工作以并行的方式进行,同时合并多个视频块。而且,利用超算节点高主存的特性,对主存利用率设置一个阈值,低于该阈值时,保留中间结果在主存,当主存不足时,才将中间结果写入硬盘,最大限度地减少I/O操作的开销。
2.4 HDFS 模块
在本系统中,使用HDFS模块的情况分为两种:一是上传本地文件到HDFS,例如保存视频分割后的视频块和转码合并后的目标视频;二是从HDFS下载文件到本地系统,例如Map任务下载视频块和客户端下载目标视频。
这两种情况的实现需要使用Hadoop抽象文件系统的 copyToLocalFile()和 copyFromLocalFile()。copyTo-LocalFile()的功能是从分布式文件系统拷贝文件到本地,copyFromLocalFile()的功能是从本地拷贝数据到分布式文件系统。
3 总结与展望
当前视频数据存在着海量化、多平台化、多编码标准化的趋势,传统的视频转码方案已经满足不了日益增长的用户需求。所以,本文提出一种基于超算平台和Hadoop的视频并行转码方案。总的来说,方案有两个重点:一是基于Hadoop框架优秀的并行任务处理能力,高扩展性和高容错性,使用MapReduce思想搭建一个并行转码系统,完成对视频的分割、转码和合并。二是结合超算平台的优势,采用特殊的技术实现方法来提高系统并行转码的能力,例如移植FFmpeg到MIC卡。
当然,本方案还有许多需要改进之处。例如,需要进一步研究,提出更多可行的方法来提高转码系统的性能。FFmpeg能够处理大多数视频格式,但不是所有,需要添加对特定格式的支持。在MIC卡上并行处理视频数据时要考虑视频数据的关联性,HDFS中视频块大小设置对并行度的影响等。
总之,本文希望通过提出一种基于超算平台的海量视频转码解决方案来满足目前的转码需求。同时,通过本文在方案中对超算平台的分析和应用,为其他大规模数据处理应用提供新的思路、新的选择。
[1]英特尔至强融核协处理器开发人员快速入门指南[EB/OL].[2013-12-22].http://software.intel.com/zh-cn/articles/intel-xeon- phicoprocessor-developers-quick-start-guide#admin.
[2]杨帆,沈奇威.分布式系统Hadoop平台的视频转码[J].计算机系统应用,2011,20(11):80-85.
[3] DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM-50th anniversary issue,2008,51(1):107-113.
[4]王恩东,张清,沈铂,等.MIC高性能计算编程指南[M].北京:中国水利水电出版社,2012.
猜你喜欢
广东通信技术(2023年11期)2023-12-10 12:28:38
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
科学与社会(2022年1期)2022-04-19 11:38:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
缔客世界(2020年1期)2020-12-12 18:18:28
莫愁(2019年36期)2019-11-13 20:26:16
传播力研究(2018年7期)2018-05-10 09:42:47
计算机工程(2015年8期)2015-12-02 01:12:50
中国卫生(2015年12期)2015-11-10 05:13:34
