
基于改进TFIDF算法的文本分类研究
2014-10-14 09:28:18徐德华
计算机与现代化 2014年9期
郑 霖,徐德华
(同济大学经济与管理学院,上海 200092)
0 引言
随着信息技术与互联网的迅速发展,用户通过网络获取的信息量增长迅速,而庞大的网络数据资源中,绝大多数的数据仍是文本数据。如何让用户在海量数据中,快速找到自己所感兴趣的数据,成为了一个亟待解决的问题。文本分类作为信息处理的重要研究方向,是处理大量文本数据的有效途径。通过对文本数据进行分类,将相似文本集中在一起进行管理,可以提高用户检索的效率,快速找到其感兴趣的类别文本。
文本分类(Text Classification)是在给定的分类模型下,根据文本内容判断文本所属类别的过程。通常情况下,文本不仅包括网页、邮件,还包括短信、微博和论坛帖子等。在文本分类的过程中,核心的部分就是将文本表示成向量空间模型[1](VSM:Vector Space Model)。在建立文本空间向量模型的过程中,首先是对文本进行分词,将文本表示成向量形式,但是这样产生的向量维数巨大,产生“维度灾难”。因此,在文本分词结束后,首先进行特征选择和权重的计算,降低文本向量的维数,形成一个低维的空间向量。
在建立空间向量模型的过程中,权重的表示尤为重要,常用的有布尔权重、词频权重和TFIDF权重等,特征项的权重表示在很大程度上会影响文本分类的准确性。在权重的众多表示方法中,TFIDF权重表示因为相对简单,有较高的准确率和召回率,一直是一种使用最广泛的权重表示方法。
为了进一步提升文本分类的效果,本文分析了传统文本分类权重计算方法的优点和不足,并对经典的TFIDF算法做了改进,最后将改进的算法用在实验文本的分类上,取得了分类效果上的提升,证明了改进策略的可行性。
1 文本分类国内外发展现状
文本分类研究始于自动分类研究,20世纪50年代,H.P.Luhn在这一领域进行了开创性研究,他提出词频统计思想主要用于自动分类[2]。1960年,Maron发表了关于自动分类算法的论文,随后,以Kspark、G.Salton以及 K.S.Jones等人为代表的众多学者在这一领域进行了卓有成效的研究工作[3]。国外当前流行的基于统计的分类方法有 Naïve Bayes[4]、KNN[5]和支持向量机[6]等。国外的文本分类研究工作已经从基础实验性研究转入实用阶段。
国内在文本分类方面的研究比国外起步晚,但是也取得了巨大的进步。国内在中文文本分类方面的研究始于上个世纪的80年代,历经了4个主要过程:学习和借鉴国外的研究成果;构建中文语料库;创建开放的中文文本分类实验平台;自主研发具体的应用系统等[7]。随着中文自然语言理解技术特别是中文自动分词和词性标注技术的日渐成熟,中文文本分类技术的研究发展很快,已经逐步从可行性探索向实用化开始转变[8],例如百度等搜索引擎。总体来说,中文文本分类还处于不断的发展之中,正确分类率约为60%~90%,已经向商业化的软件应用靠拢,并且已经尝试开发了一批自动分类系统[9]。
在文本分类的过程中,非常重要的部分就是分词后词条的权重表示。常用的权重表示方法有布尔权重、词频权重和TFIDF权重等。
1)布尔(Boolean)权重:在计算词条权重时,根据词条是否在文本中出现来决定,词条在文档中至少出现过一次,权重为1,否则为0。该方法形式简洁,容易实现,但是不能很好地体现词条在文档中出现的次数。
2)词频(Term Frequency,TF)权重:在计算时将词条在文档中出现的次数作为权重值。该方法实现方便,但是容易受到文本长度的影响,在一定程度上影响了分类的效果。
3)TFIDF权重。
Salton在1973年提出了TFIDF(Term Frequency& Inverse Documentation Frequency)算法[10]。该算法综合考虑了词条的词频TF以及逆文档率IDF,其主要思想是:如果一个词条在特定的文本中出现的频率越高,说明它在区分该文本内容属性方面的能力越强;如果一个词条在文本中出现的范围越广,即每个类别中出现次数相当,说明该词条区分文本内容的能力越弱。其经典计算公式为:
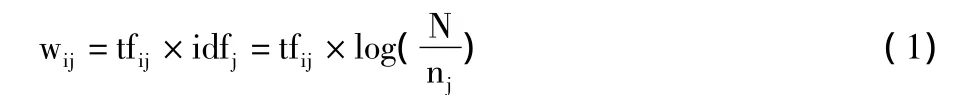
其中,tfij是指词条tj在文档di中出现的次数,idfj是指出现词条tj的反文档数,N表示总文档数,nj是指出现词条tj的文档数。
从TFIDF的经典公式可以看出,tfij越大,即词条tj在特征文本中出现的次数越多,权重wij越大,区分该文本的能力越强;nj越大,即词条tj在语料集中出现的文档数越多,权重wij越小,区分该文本的能力越弱。实际上,如果词条tj在某一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,但是词条tj在某一个类的文档中频繁出现,会使nj增大,从而导致wij减少,这就是传统TFIDF算法的问题所在。它将文档集作为整体来考虑,其中IDF的计算并没有考虑到特征项在类间的分布情况,导致在类别之间分布均匀对类别区分度不大的特征项赋予了很高的权值,而且IDF的计算也没有考虑到特征项在类内的分布情况,导致在一个类别内部只集中在某几个文本的特征项赋予了很高的权值。
2 改进的TFIDF算法
针对传统算法的上述不足,很多研究者都进行了算法的改进。张保富(2011年)等[11]提出了一种结合词条在类间和类内的信息分布熵来调整TFIDF计算的方法,改善了文本分类的效果。张建娥(2012年)[12]通过词语关联度修正了TFIDF算法的误差,使算法的平均召回率有了一定提升。李学明(2012年)等[13]在前人的基础上,提出了一种基于信息增益与信息熵的TFIDF算法(TFIDFIGE),对于文本集合内部的词条分布通过信息熵来对词条的权重进行调整。这2种算法虽然在一定程度上克服了传统算法的缺点,但是大大增加了算法的复杂度。张玉芳(2006年)等[16]将IDF的计算改为IDF=log(×N)(m为类C内包含词条t的文档数,k为除类C外包含词条t的文档数),这样就考虑到了词条t在类间与类内的分布,也在一定程度上克服了传统算法的不足,但是用类C内包含词条t的文档数m和类C外包含词条t的文档数k直接计算,可能会由于类C外的文档数比类C的文档数多,而使k值较大,从而削弱了m的影响。
基于此,本文提出一种新的TFIDF改进算法。新算法的核心思想是用类C内包含词条t的文档占比和类C外包含t的文档占比来衡量词条t在类间和类内的分布,修改了IDF的计算方法:

其中,m为类C内包含词条t的文档数,j为类C内不包含词条t的文档数,k为非类C内包含词条t的文档数,i为非类C内不包含词条t的文档数。
1)验证1:词条t在类C文档集中出现越频繁,即m值越大,则词条t对类C的区分能力越强,因此IDF'的值应该越大。

所以IDF'是关于m的增函数,随m值的增大而增大。
2)验证2:词条在类C文档集中出现越少,即j值越大,则词条t对类C的区分能力越弱,因此IDF'的值应该越小。

所以IDF'是关于j的减函数,随j的增大而减小。
3)验证3:词条t在非类C文档集中出现越频繁,即k值越大,则词条t对类C的区分能力越弱,因此IDF'的值应该越小。
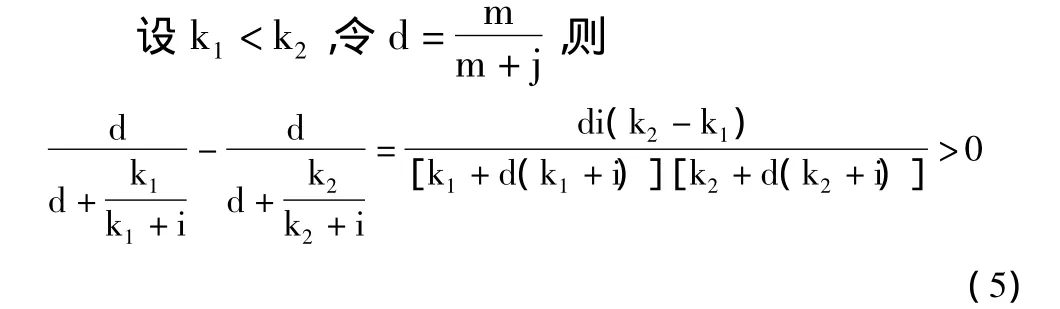
所以IDF'是关于k的减函数,随k的增大而减小。
4)验证4:词条t的非类C文档集中出现越少,即i值越大,则词条对类C的区分能力越强,因此IDF'的值应该越大。
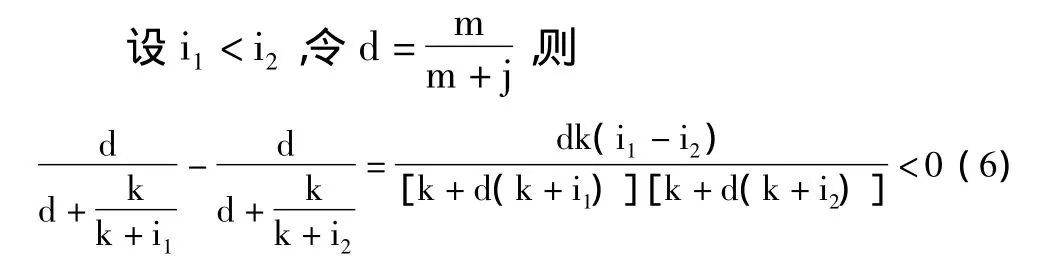
所以IDF'是关于i的增函数,随i的增大而增大。
通过上述4个验证发现,改进后的算法在理论上符合文本分类的实际,可以应用于文本分类时的权重计算。
3 特征选择及分类策略
1)特征选择。
在中文文本分类中,对语料集中的文本进行分词,去停用词后,形成的特征词集合,称之为初始特征集。在初始特征集中,特征词的个数可能是成千上万的。也就是说经过分词,去停用词后所形成的特征空间的维数是非常大的。高维的特征空间给文本分类的效率带来了很大的影响[7]。特征选择就是用于高维特征空间的降维处理。常用特征选择的方法有文档频率(DF:Document Frequency)、信息增益(IG:Information Gain)、互信息(MI:Mutual Information)、χ2统计量(CHI:Chi-square)等[14]。
本文在后续的实验验证过程中,特征采用的是χ2统计量。χ2统计量方法是度量词条t与类C之间的相关性,认为两者的关系近似服从自由度为1的χ2分布,χ2统计值越大,词条t与类C相关性越大。计算公式如下:
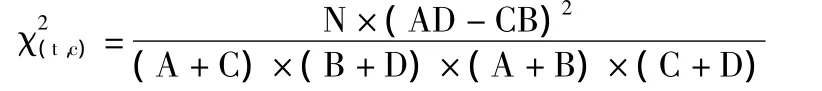
其中,N表示语料中的文档总数,A表示属于类C且包含词条t的文档数,B表示不属于类C但包含词条t的文档数,C表示属于类C但不包含词条t的文档数,D表示不属于类C且不包含词条t的文档数。
2)分类策略—Rocchio方法[15]。
该方法根据算术平均为每类文本集生成一个代表该类的中心向量,然后在新文本到来时,确定新文本向量,计算该向量与每类分类中心的距离(相似度),则判定该文本属于与其距离最近的那个类。相似度的计算公式如下[16]:

其中,Sim(Di,Dj)表示待分类文档与指定类别的相似度,Di为待分类文档,Dj为第j类文档的中心向量,M为特征向量的维数,Wk为向量的第k维(即第k个词条的权重)。本文在后续实验中也采用这种分类计算的方法。
4 实验结果及分析
通过网络爬虫从新浪新闻中抓取了财经、房产、教育、军事和体育5大类的新闻作为本次实验的语料库。每个大类分别抓取了500篇新闻,共2500篇文档作为总语料库,其中每个类取400篇,共2000篇作为训练集,形成分类器,每个类别剩下的100篇,共500篇作为测试集,测试改进后TFIDF算法的效果。表1为实验数据中训练集与测试集的类别分布情况。

表1 实验数据中训练集与测试集的类别分布情况
通常采用召回率和准确率来评价文本分类效果的优劣。对于某一特定的类别,召回率R(Recall,查全率)定义为:被正确分类的文档数和被测试文档总数的比例,即该类样本被分类器正确识别的概率。准确率P(Precision,查对率)定义为:正确分类的文档数与被分类器识别为该类别的文档数比率,即分类器做出正确决策的概率。为了从召回率和查全率2个方面综合考虑,一般用F值进行分类效果评价,其计算公式:F=,F值越大,反映出分类效果越好,说明改进的TFIDF算法越优越。
本文分别用了传统 TFIDF算法、文献[6]的TFIDF算法及笔者改进的TFIDF算法对文本数据进行了分类,分类效果用F值评价,实验的大致流程如图1所示。
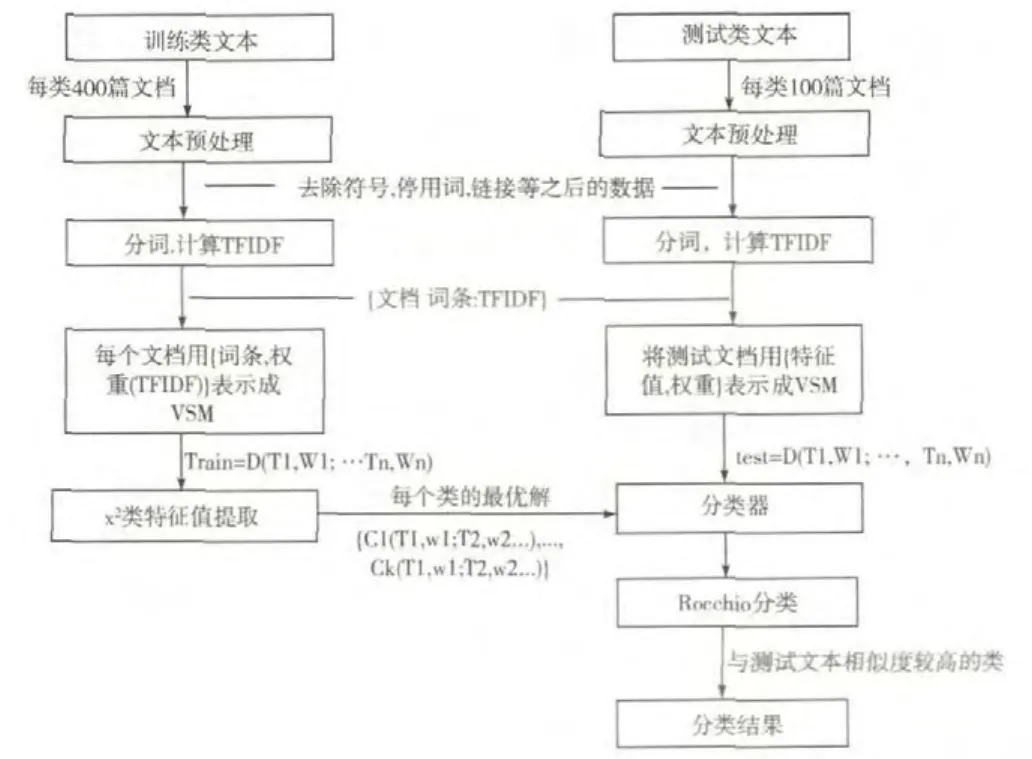
图1 文本分类实验流程图
为了更好地确定卡方选取特征值的个数,本文对3种不同算法分别取每个类别卡方值前60,70,80,90,100等,然后分别进行文本分类,观察文本的总体分类效果,结果如图2所示。

图2 不同卡方取值下文本分类的效果
从图2中可以看出,当取每个类别卡方值的前80个词条作为特征项时,文本分类的效果最佳。于是本文选取80个特征项进行分类,具体结果如表2所示。
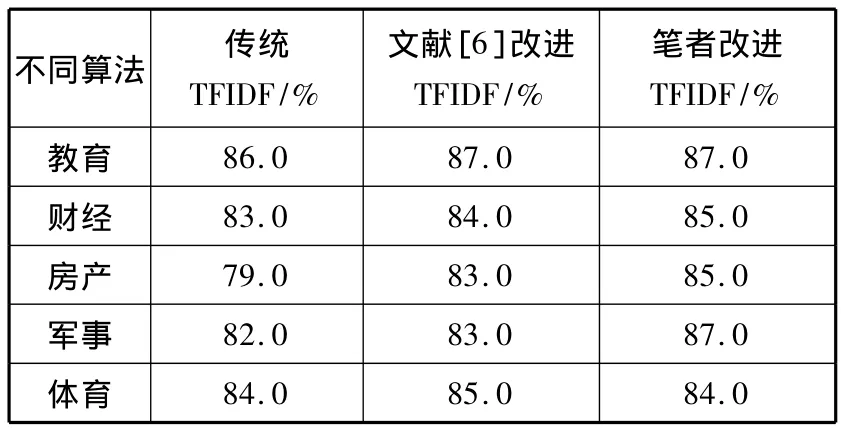
表2 不同TFIDF算法的分类效果评价
从表2的实验数据中可以看出,传统TFIDF算法的F1值较小,而文献[6]改进的TFIDF算法确实对文档分类的效果有了一定改善,但笔者改进的TFIDF算法对文档分类效果则有了较大的提升。实验证明,通过改进IDF算法,充分考虑了词条t在类间与类内的分布,对文档分类的准确率和召回率都有一定提高,有助于改善文档分类的效果。
5 结束语
本文从文本分类的研究现状及意义出发,总结了文本分类常用的几种算法的优缺点,并对其中最常用的TFIDF算法进行改进,通过修改IDF的计算方法,用类C内包含词条t的文档占比和类C外包含t的文档占比来衡量词条t在类间和类内的分布来计算IDF,从而充分考虑了词条t在类间与类内的分布。最后,本文还将改进的TFIDF算法用在实验文本的分类上,通过与传统 TFIDF算法的比较,改进的TFIDF算法确实对文档分类的效果有了一定的提升。
下一步的研究方向可以针对向量空间模型的特征值选取方法做一些改进,更有效率地选取出最具代表性的特征值,同时,在文本的分类策略上,也可以做一些改进,以期达到更好的文本分类效果。
[1]Salton G,McGill M J.Introduction to Modern Information Retrieval[M].McGraw-Hill,1983.
[2]Luhn H P.Auto-encoding of Documents for Information Retrieval Systems[M]//Modern Trends in Documentation.New York:Pergamon Press,1959:68-95.
[3]Salton G,Wong A,Yang C S.A vector space model for automate indexing[J].Communications of ACM,1975,18(11):613-620.
[4]Lewis D D.Naïve Bayes at forty:The independence assumption in information retrieval[C]//Proceedings of the 10th European Conference on Machine Learning.1998:4-15.
[5]李荣陆,胡运发.基于密度的KNN文本分类器训练样本裁剪方法[J].计算机研究与发展,2004,41(4):539-545.
[6]Hsu C,Lin C.A comparison on methods for multi-class support vector machines[J].IEEE Transactions on Neural Networks,2002,13(2):415-425.
[7]宋惟然.中文文本分类中的特征选择和权重计算方法研究[D].北京:北京工业大学,2013.
[8]候敏.计算语言学与汉语自动分析[M].北京:北京广播学院出版社,1999.
[9]苗夺谦,卫志华.中文文本信息处理的原理与应用[M].北京:清华大学出版社,2007.
[10]Salton G.On the construction of effective vocabularies for information retrieval[C]//Proceedings of the 1973 Meeting on Programming Languages and Information Retrieval.1973:48-60.
[11]张保富,施化吉,马素琴.基于TFIDF文本特征加权方法的改进研究[J].计算机应用与软件,2011,28(2):17-20.
[12]张建娥.基于TFIDF和词语关联度的中文关键词提取方法[J].情报科学,2012,30(10):1542-1555.
[13]李学明,李海瑞,薛亮,等.基于信息增益与信息熵的TFIDF算法[J].计算机工程,2012,38(8):37-40.
[14]Cohen W,Singer Y.Context-sensitive learning methods for text categorization[J].ACM Trans.Information Systems,1996,17(2):146-173.
[15]Han E H,Karypis G.Centroid-based document classification:Analysis& experim-ental results[C]//European Conference on Principles of Data Mining and Knowledge Discovery(PKDD).2000:424-431.
[16]张玉芳,彭时名,吕佳.基于文本分类TFIDF方法的改进与应用[J].计算机工程,2006,32(19):76-78.
[17]施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J].计算机应用,2009,29(B6):167-170,180.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
信息安全研究(2016年4期)2016-12-01 06:06:54
知识经济·中国直销(2016年5期)2016-11-07 09:35:07
知识经济·中国直销(2016年4期)2016-11-07 09:34:04
知识经济·中国直销(2016年10期)2016-02-27 16:16:54
新校长(2016年8期)2016-01-10 06:43:59
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
信息安全研究(2015年3期)2015-02-28 20:17:53
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
