
中文专利信息资源深加工方案设计与实证研究*
2014-10-12 02:55张兆锋桂婕李颖杜永萍
数字图书馆论坛 2014年7期
张兆锋,桂婕,李颖,杜永萍
(1. 南京大学信息管理学院,南京 210093;2. 中国科学技术信息研究所,北京 100038;3. 北京工业大学计算机学院,北京 100022)
中文专利信息资源深加工方案设计与实证研究*
张兆锋1,2,桂婕2,李颖2,杜永萍3
(1. 南京大学信息管理学院,南京 210093;2. 中国科学技术信息研究所,北京 100038;3. 北京工业大学计算机学院,北京 100022)
基于专利分析的视角,调研了国内外专利信息资源的现状和特点,明确了用于专利分析的资源及其加工深度的不足,设计了预处理和深加工的方案,重点为专利清洗和专利中四类信息的内容标引:发明类型、技术主题、发明改进和应用领域。并以新能源汽车领域为例,对中文专利进行了深加工实证研究。结果显示,利用清洗和深度标引后的专利资源能有效提高分析的准确度和专利资源揭示深度。
专利资源;专利清洗;专利标引;专利抽取
引言
专利作为技术创新的载体,包含大量的技术、经济和法律信息,且数量巨大、覆盖学科范围广,技术描述详细规范,是一种重要的科技信息资源。基于专利进行分析,可以了解领域发展现状,进行国家或企业竞争情报分析,及时把握技术发展热点和趋势,以便更好地发现技术机会和进行战略布局,从而有效地提高企业的竞争能力。
选取合适的专利信息源是进行专利分析的基础,专利信息资源的质量是获得准确可靠竞争情报的保证。目前,专利信息来源众多,质量参差不齐,给选择和利用造成诸多不便。同时,大家获取到的专利信息资源多数只能进行题录信息的分析,不能深入专利文本内部[1,2]。某些商业专利分析平台[3,4]和研究人员[5]在开发的系统中提供了人工标注的接口,但随着技术的快速发展和专利数量的迅速增多,人工标注成本大、速度慢的问题暴露出来。有数据库开发商和研究人员研究了专利数据自动加工的方法,但加工工具的精确度、扩展性和深度不足。
本文在长期跟踪、深入调研分析国内外专利资源及深加工现状的基础之上,主要研究基于词表和模板对专利进行自动深加工的方法,设计一套通用的专利深加工方案,深入到专利内容层面细粒度的标引加工,为专利的有效和深度利用提供基础支撑。
1 专利信息资源现状
1.1 专利信息资源概述
专利信息资源指各国及区域知识产权组织发布的专利文献及基于其加工的二次文献的总称。按照不同的分类标准,可以有多种分类:
(1)根据专利资源的来源不同,专利可以分为官方专利和服务商专利数据库。官方专利一般提供免费检索服务,及时性、权威性较好,但数据质量不够;数据库服务商提供的专利是经过整合后的多国专利数据,可支持跨库检索,但更新周期长。
(2)根据加工程度不同,专利信息可分为原始专利、粗加工专利和深加工专利专题库。原始专利没有经过加工整理,存在格式、录入不规范等错误信息;粗加工专利进行了一般性的规范处理,比如规范字母大小写、日期格式等;深加工专利专题库中的专利数据经过严格的筛选、规范、加工和标引等,数据质量较好。
(3)根据提供服务的方式不同,有简单检索、检索结果分面统计、检索结果指标分析等不同程度的服务。官方专利局一般只提供简单检索和列表查看功能;部分免费的开放平台会提供专利的复杂检索和检索结果分面统计功能;比较专业的专利服务商和平台会提供专利检索和对检索结果的指标分析一体化服务,实现专利资源与分析服务的整合。
(4)按是否收费可分为免费数据库和收费数据库。免费数据库数据质量不高,访问速度慢,不能批量下载数据。收费数据库提供的专利质量、服务和稳定性都较好,如德温特专利数据库[6]收录的专利都经过题目和摘要的改写,同一专利家族的专利归并。
1.2 专利信息资源利用现状
随着人们专利意识的快速提升,利用专利信息进行技术分析、领域分析和竞争情报分析的企业和研究人员也快速增多,如姚颉靖等人基于专利分析抗肿瘤药物发展状况[7],韩雪冰等利用专利信息分析我国固体激光器发展状况[8],并提出对策,翟东升等进行了基于专利的页岩气技术国际研究态势研究[9]。由于专利信息的公开性,获取专利信息比较容易,但在专利信息检索、分析等利用过程中还存在着较多问题和不足,主要如下:
(1)免费系统只提供有限的检索结果展示或分析。现在多数公开免费的网络专利信息资源提供检索结果显示和导出时,都限制最高数量,如国家知识产权局官方网站限制每日浏览和下载专利说明书不超过300页[10],佰腾网每次只能导出1000条记录[2]。由于对一个领域进行领域分析时,所需的专利数一般都超过最高数量限制,不能满足准确的分析需求,需要购买商用专利数据库。
(2)获取的专利信息没有进行足够的清洗就进行分析。网上免费的专利数据资源,质量存在较多问题,若分析前不进行充分的专利清洗、规范加工,就不能得出可信的分析结论。即所谓的“Garbage in, garbage out”。如果需要较高质量的分析情报,需要对获取到的初始数据进行清洗加工,且要对可能出现的问题考虑全面。清洗专利数据是一项费时费力的工作,也可以直接购买所需领域的专利专题数据库,但专题数据库多是比较热门的领域,不能找到完全符合自己分析需求的数据。
(3)多数的专利分析只限于题录信息的组合分析。由于专利信息登记时,题录信息单独存放,所以提供服务较为容易。大多数专利信息资源提供商大多只提供题录信息的分析,不能提供深入专利文本内容的微观分析。需要进行基于专利文本内容分析时,需要用人工标引的方法对专利“技术”、“功效”、“创新性”进行标引,由于人工成本较大,这只适合于较少专利数量的分析。
1.3 专利信息资源深加工研究现状
为了提高专利信息资源利用的准确性和效率,有不少研究人员和公司对专利资源的深加工进行了相关的研究。例如,德温特依靠雄厚的数据加工能力对专利题目和摘要进行了改写和深加工,将摘要分成了三部分:NOVELTY、USE和ADVANTAGE,但粒度还不够细,属于句群级别,没有具体到词或短语的级别,只能满足人工阅读的需要,不能为自动化处理提供小粒度的标引结果[6];东方灵盾公司制作了世界传统药物深加工数据库,针对药物专利的特点进行成分、属性等相关信息的提取,取得了较好的应用效果,然而此方法通用性不够,不便于扩展到其他领域,且需要较多的人工参与,成本较高[11];北京工业大学的翟东升、李倩等人利用SQL Server BI对德温特专利信息进行了清洗和字段拆分工作,但仅限于对复合字段的拆分存储,便于对题录信息的统计,并没有深入到专利文本内容层面[12]。
近年来,随着本体技术的发展和逐渐成熟,对题录信息的深度加工逐渐向面向文本的深加工转移,利用本体技术对专利摘要进行信息抽取、标引和加工、构建专利知识库,更利于专利信息的组织、检索和分析。例如,姜彩虹等人利用知识工程的方法,提出了一个基于本体的专利摘要抽取模型,通过构建的本体、收集的词表和撰写的规则对专利摘要进行知识抽取,构建专利知识库实现对专利的深度加工[13]。翟东升等人从提升专利研究领域中信息处理效能的角度出发,基于Derwent专利数据库中的专利信息和其中所包涵的语义关系设计Derwent专利本体、实现OWL语言描述的本体模型、研究本体实例的组织方式,将专利信息合理地存储在基于本体模型的逻辑介质中[14]。
通过对专利深加工研究现状的多角度综合分析,发现现有的专利信息深加工技术对专利加工的精确度不够、加工标引粒度过大、专利工具多领域应用的扩展性不足。而由于中文文本分词、抽取等技术的不够成熟,所以基于本体技术的专利抽取、标引和组织方面的研究还处于初级阶段,有待进一步加强研究力度,为未来面向专利文本的挖掘提供基础支撑。
2 专利信息资源深加工方案设计
专利信息清洗加工的程度决定专利分析结果的准确度和深度。本研究根据实际工作中的经验和发现的问题,并针对在“1.2 专利信息资源利用现状与不足”中提到的问题进行了深入全面的研究,为专利深加工设计了专利清洗和专利标引两步加工的方案,如图1所示。
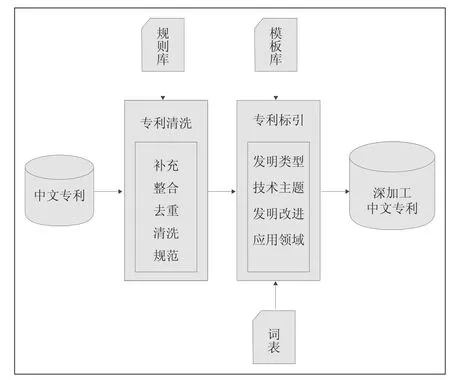
图1 深加工方案设计图
在专利清洗阶段,利用专利数据的常见问题和规范标准制定一系列的规则,形成规则库,基于规则库并结合使用SQL批处理语句等对专利数据进行补充、整合、去重、清洗和规范等;在专利标引阶段,基于中信所自主研发的“领域汉语科技词系统”提供的词表,结合半人工机器学习积累的模板库对专利中包含的“发明类型”、“技术主题”、“发明改进”和“应用领域”等知识进行了标引。该方案有效地解决了专利清洗不全面和专利标引依赖手工而不能处理大批量数据及内容标引深度不足的问题。
2.1 专利清洗
专利清洗针是指对专利信息中不完整、不规范、不正确的信息进行补充、纠错、统一、规范的过程。主要清洗的对象是分析常用的字段,如专利权人、发明人、日期等。专利清洗过程中常见的问题可参考表1。
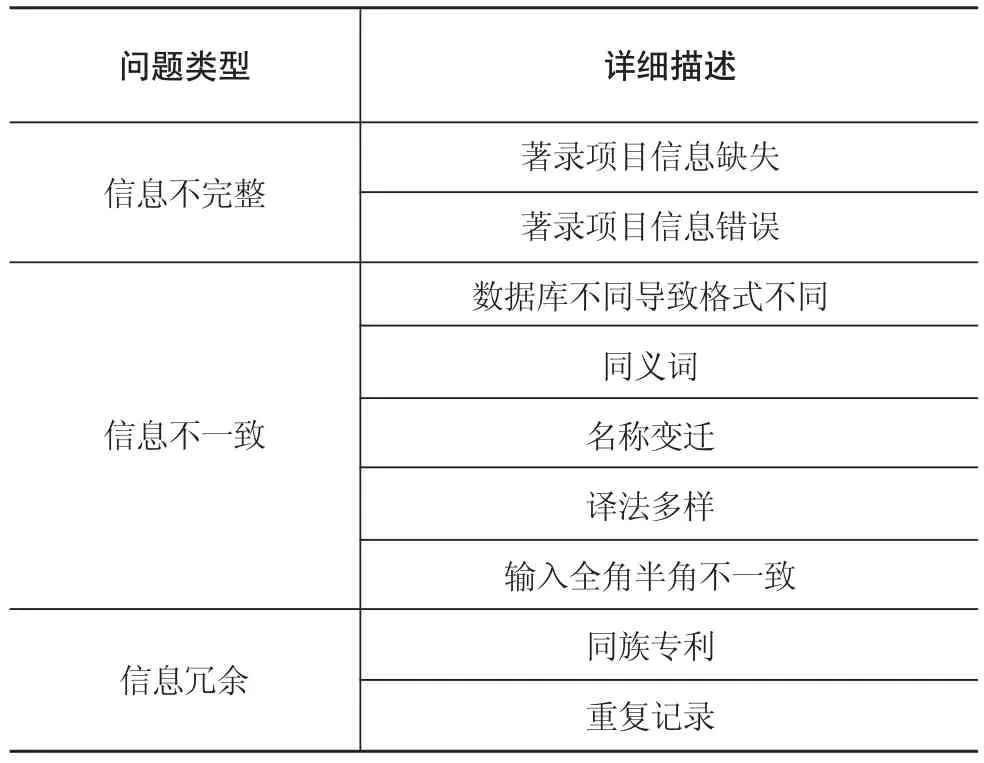
表1 专利清洗常见问题列表
对“信息不完整”的问题,根据需要主要是对排名靠前的专利权人或该领域重要的公司信息的准确性进行核实,不完整的进行补充;对“信息不一致”的问题,通过建立标准术语与变异术语的对应关系,批量化地规范为标准规范的表述;对“信息冗余”问题,要根据实际分析的需要进行重复记录去重工作,以保证分析结果的可靠性。
2.2 专利标引
专利标引主要是对专利文本内容的深度揭示,为进行基于专利文本的挖掘提供数据基础。本研究根据专利文本的特点,利用半自动化的模板构建方法抽取专利文本摘要中的指定信息,实现指定领域的专利术语识别,利用识别出的术语进行标引。因此需要首先建立模板库,模板是对句子中被抽取部分、特征词以及它们之间次序的抽象。通过选取特征词和适当泛化等策略,采用人机交互方式,人工标注与机器学习相结合,构建抽取模板。针对专利摘要中的各种不同类型的目标信息建立相应的模板,完成知识抽取任务。专利标引的流程图如图2所示。
本研究共设计了四种类型信息的标引,如图3所示:
(1)发明类型:在名词短语识别基础上,实现领域概念的获取,获取专利的发明类型信息。如,判断发明是否属于产品、方法、设备、流程、工艺、材料等。
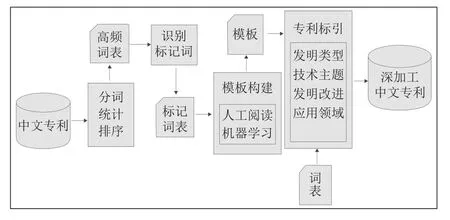
图2 专利标引流程图
(2)技术主题:技术主题指一个专利描述的主要技术是什么,即专利全文描述的主要对象,通过建立核心关键词表等方式,触发技术主题相应的模板,实现技术主题知识的抽取。
(3)发明改进:也即功效,指该发明实现了什么功能的改变和效果的提升。在已有的专利数据中,采用统计的方法实现不同专利用语及专利术语的词频计算,包括名词核心词表、动词核心词表、表示倾向性特点的词表等,从不同的角度获取其改进特征,最后对功效相似的描述进行合并。通过功效的标引,可以为技术研发人员提供从功效检索的入口,更好地发现可替代技术。
(4)应用领域:专利摘要中可能会包含该专利的应用领域信息,通过建立相应的模板实现相关知识的抽取。

图3 专利标引内容说明
对发明类型的判断,主要是定位在专利名称和摘要中的第一句话,通过匹配“方法”、“技术”、“材料”、“装置”、“系统”等关键词来确定专利相应的类型;对发明改进的判断,主要依赖建立的功效动词库,如“提高”、“加快”、“节省”等,并结合常用功效表述词表进行定位,如“方法简单”、“成本低”、“功率大”等,根据不同领域的特点,功效描述词会有部分差异。
针对“技术主题”和“应用领域”两类专利,知识抽取适合以模板的形式抽取,分别建立相应的模板,抽取模板示例如表2所示。
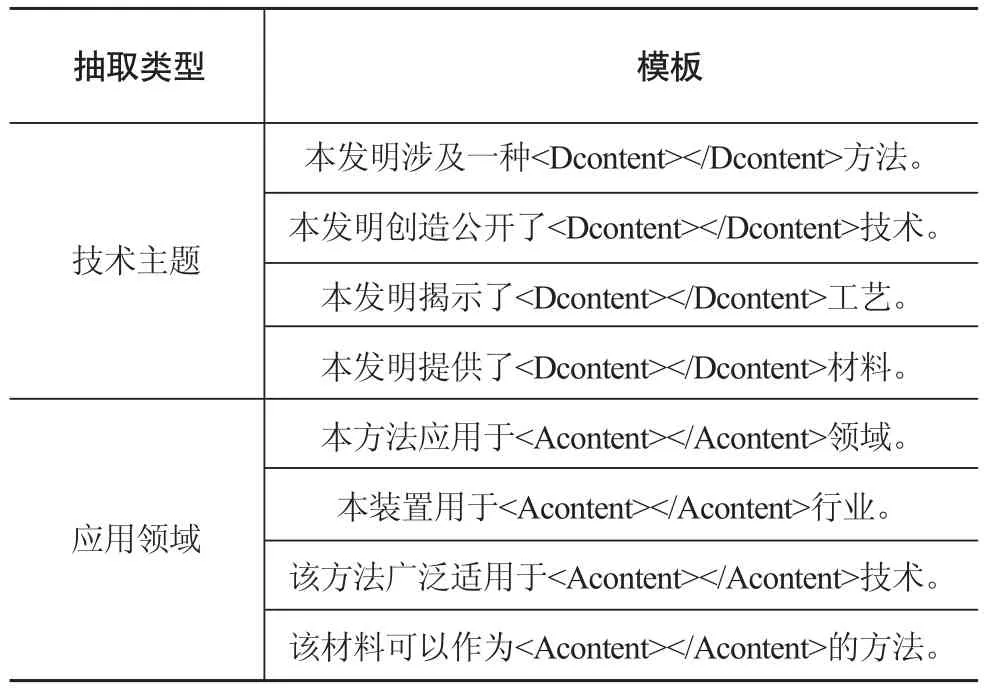
表2 抽取模板示例
3 深加工实证研究
本研究以1985-2013年中文专利数据库为数据源,以“新能源汽车”、“电动汽车”、“混合动力汽车”等汽车类型及其关键零部件名称为检索词,结合IPC分类号如“ B60L11”、“G01L3”、“ H01M2”进行检索。对检索结果进行浏览过滤,删除明显不属于该领域的专利,最后获得新能源汽车领域中文专利8005条专利,根据第2节设计的深加工方案,进行专利清洗和专利标引的实证研究,实现基于规则和模板的专利清洗和深加工。
3.1 专利清洗
根据设计方案中常见问题列表,分析容易出现错误的字段和内容,进行了如下的清洗操作:
(1)对不完整信息进行补充。通过检索语句查找专利库中本应该有而信息缺失的字段,例如,分类号、专利权人或发明人这些字段是必填字段,却有缺失情况,则利用专利号去官方网站查找信息,进行专利数据库信息补充,提高了专利信息库的完整性。
(2)对机构名称进行合并。对排名靠前的大公司因申请人不同导致的机构名称不统一,进行合并。如申请人为“中国科学技术信息研究所”、“中国科技信息研究所”、“中国科技情报研究所”,由于历史名称变更和申请时不规范书写造成的同一个单位,多种描述,要统一合并为规范描述“中国科学技术信息研究所”。同时,对录入错误、合资公司申请、名称变化、重组兼并等情况而导致的机构名称不一致问题,进行相应的修正。由于专利权人机构众多,对所有的机构进行排查会耗费较大人力,也无必要,本研究采取对排名在前500名的专利权人机构名称进行了清洗合并。如,对专利权人中的“中国科学院长春光机所”修改为“中国科学院长春光学精密机械研究所”。
(3)对人名进行合并。对人名中存在的全称与缩写、输错、姓名次序颠倒、翻译问题、称呼变化、多个称呼等问题,进行人名合并。如“奥斯兰姆”与“奥斯兰母”,通过观察其他字段信息,如国家、城市、地址等,发现这些信息一样,可以判断这两个专利权人是由于输入错误导致的人名不一致,实际操作中,针对发明数在3个以上的发明人进行了清洗。
(4)统一英文字母、数字、标点、各种符号的大小写及全角半角格式。对专利信息录入时没有区分全角半角问题进行处理。如,针对大小写问题的错误修正,将“ASK工业s•p•a•”、“ASK工业S•P•A•”、“ASK工业S•P•A•”,统一修改为“ASK工业S•P•A•”;因为符号问题需要修正的数据,如,“GN瑞声达A/S”、“GN瑞声达A/S”、“GN瑞声达A/S”,统一修改为“GN瑞声达A/S”。其他容易出现类似问题的标点符号还有“()”和“()”、“〃”和“"”、 “~”和“~”、“+”和“+”、“〈〈”和“《”等。
3.2 专利标引
通过对数百篇比较典型的专利文本的考察,我们发现专利摘要文本的描述语言较规范,一段专利摘要文本,一般先描述技术主题,然后再用较长的一段话描述发明原理,最后是对发明改进和应用领域的描述。因此,我们构建模板的方法如下:首先将一个完整对象内的部分信息进行泛化(如:专利属于NP组块),作为模板的变量,保留触发词,包括前缀特征词、后缀特征词、关键动词等信息,作为模板的常量;其次,通过人机交互方式,人工与机器学习相结合,并通过统计方法对大量专利文档的分词以及词频进行统计,得到高频词表,人工对该词表进行整理得到用于识别模式的标记词,如“一种”、“其特征”、“涉及”等。然后,进行人工标记,用10人对专利摘要500条进行标记,包括4种对象。最后,利用人工优化后的模板,结合专利摘要中各目标信息出现的位置、长度等特征来抽取目标信息,利用抽取结果对专利进行标引。
通过不断的反复优化,利用建立的模板对8005条数据进行实际抽取,对抽取结果随机选择800条分为10组进行人工评价。发现其中技术主题和发明类型抽取的准确率较高,在专利文本中表现规范,一般位于句首,特征较明显。发明改进和应用领域部分的抽取主要依据模板中的特征词以及在专利文本中的位置等信息。以技术主题模板抽取结果为例,统计数据如表3所示,有较高的准确率,实验证明该方法有较高的可靠性。
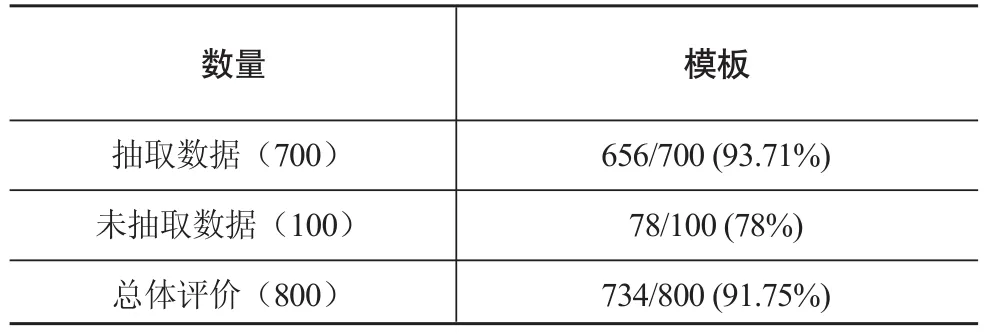
表3 技术主题抽取结果统计
为了方便结果的展示,对抽取的技术、模板、动词词表和标引后的示例专利进行了统一整合,以平台的形式集中体现标注效果。

图4 单条专利标引结果
其中一条抽取结果的详细信息,如图4所示,列出了专利号为“CN100998948”的专利抽取出的专利主题、专利提高、专利应用和发明类型等信息,抽取出的各类信息可用于对该条专利进行标引。
3.3 结果讨论与应用场景
本研究通过对8005条专利数据的观察总结,发现了原始数据中存在的较多问题,并根据实际出现的问题逐项依据需求进行了补充、清理和完善,有效地提高了数据的准确度和可用性。通过对设计的抽取四种专利信息“技术主题”、“发明类型”、“发明改进”和“应用领域”方案进行研究和实证实验,并利用抽取结果对相应专利进行标引,有效地实现了对专利信息资源的深度揭示,为下一步专利文本的深度挖掘和分析奠定了基础。
基于抽取标引的深加工专利数据可进行多种形式的应用。例如,把上述从文本内容抽取的四种信息与著录项信息如“时间”、“专利权人”、“区域”等进行组合分析,可以从多个角度进行技术趋势分析和企业的专利布局分析,也可以提供更多的检索入口和分面统计类型,还可以进行技术功效矩阵分析,如图5所示,发现技术密集区(气泡大的部分)、雷区(高侵权风险)和空白区(交叉点没有专利申请),为技术研发创新提供思路指导。
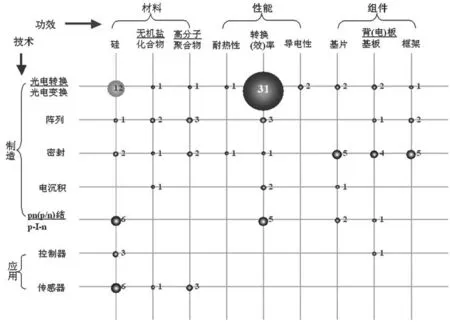
图5 技术功效矩阵
结语
本文通过研究国内外专利信息资源的现状,发现在使用专利资源过程中遇到的问题,结合问题和专利分析的需求,设计了通过专利清洗和专利标引两种方案提高数据质量的方法,并通过实证研究验证了方案的有效性和优点,为提高专利分析的准确性提供了保障。通过对专利文本的抽取标引,实现了专利内容层面的深度揭示,为专利浏览、检索、分析、挖掘等工作打下了基础。由于实验数据数量有限,模板覆盖度还不够高,下一步工作有待进一步积累模板的数量,优化模板质量,提高在不同领域应用的能力,并对专利抽取的结果进行进一步的精简,实现词组或短语的形式描述四类专利信息,更加便于统计和分类工作。
[1] 国家知识产权局.专利检索与服务系统[EB/OL]. [2014-03-20].http://www.pss-system.gov.cn.
[2] 佰腾网.佰腾专利检索[EB/OL]. [2014-03-20]. http://so.baiten.cn/.
[3] 智慧芽.Patsnap [EB/OL]. [2014-03-20]. http://cn.patsnap.com/.
[4] 德高行.TechGlory专利风险管控及竞争情报分析系统[EB/OL].[2014-03-20]. http://www.tek-glory.cn/.
[5] 汪雪锋,王有国,刘玉琴.多数据源协同下的专利分析系统构建[J].图书情报工作,2013(14):92-96.
[6] 郑伟.Derwent Innovations Index数据库的主要特点及检索方法[J].中国索引,2009(1):56-60.
[7] 姚颉靖,彭辉.基于专利分析的我国抗肿瘤药物发展现状研究[J].现代情报,2014(2):107-114.
[8] 韩雪冰,吴学彦,戴磊.基于专利分析的我国固体激光器领域现状与发展对策研究[J].现代情报,2014(1):132-136.
[9] 翟东升,蔡万江,张杰,等.基于专利的页岩气技术国际研究态势分析[J].情报杂志,2013(11):12-21.
[10] 国家知识产权局.专利检索[EB/OL]. [2014-03-20]. http://www.sipo.gov.cn/zljs/.
[11] 东方灵盾.世界传统药物数据库[EB/OL]. [2014-3-20]. http://www.eastlinden.com/list.aspx?id=208.
[12] 翟东升,李倩,等.德温特专利信息清洗与标注模型研究[J].情报杂志,2013(8):150-153.
[13] 姜彩红,乔晓东,朱礼军.基于本体的专利摘要知识抽取[J].现代图书情报技术,2009(2):23-28.
[14] 翟东升,张欣琦,张杰.Derwent专利本体设计与构建[J].情报科学,2013,31(12):95-100.
Solution Design for Deep Processing of Chinese Patent Resources and Its Empirical Study
ZHANG ZhaoFeng1,2, GUI Jie2, LI Ying2, DU YongPing3
(1. Nanjing University, Nanjing 210093, China; 2. Institute of Scientific and Technical Information of China, Beijing 100038, China;3. Beijing University of Technology, Beijing 100022, China)
From patent analysis perspective, this paper surveys the present situation of patent resources and characteristics, and summarizes the shortcomings of patent resources used in analysis. Then it proposes a solution to process patent resource deeply. The emphases are cleaning and indexing of four type information: invention type,technology topic, improvement and application area. At last, it presents an empirical study, which proves that the cleaned and extracted patent resources are more accurate and revealed for analysis.
Patent resources; Patent cleaning; Patent indexing; Patent extracting
2014-03-25)
G250.7
10.3772/j.issn.1673—2286.2014.07.008
*本研究得到“十二五”国家科技支撑计划项目“面向科技创新的专利信息加工与服务关键技术研究与应用示范”子课题“专利信息资源挖掘与发现关键技术研究”(编号:2013BAH21B02)资助。
张兆锋,男,1979年生,在读博士,研究方向:专利分析、数据挖掘、信息可视化,E-mail:zhangzf@istic.ac.cn。
桂婕,女,1976年生,博士,副研究员,研究方向:专利分析和科技创新管理。
李颖,女,博士,副研究员,研究方向:知识工程,知识服务系统。
杜永萍,女,1977年生,博士,研究方向:信息检索,智能问答,自然语言处理。
