
基于PBIL算法的物流中心选址问题研究
2014-10-11 03:16:50王晓波付珊珊张海霞
微处理机 2014年2期
王晓波,付珊珊,吉 玲,杨 亚,张海霞
(河海大学物联网工程学院,常州213022)
基于PBIL算法的物流中心选址问题研究
王晓波,付珊珊,吉 玲,杨 亚,张海霞
(河海大学物联网工程学院,常州213022)
介绍了基于种群竞争式学习的PBIL算法的基本原理和实现方法。比较了PBIL算法和遗传算法求解过程的异同点。分析了PBIL算法在物流中心选址问题中的应用,并且通过实例验证了算法的可行性和有效性,证明了PBIL算法比遗传算法具有更高的搜索效率。
PBIL算法;进化计算;遗传算法;物流中心选址
1 引 言
随着世界经济的快速发展和现代科学技术的进步,物流行业作为国民经济的一个新兴部门,正在全球范围内迅速发展。物流业的发展给社会生产、人们生活甚至政府职能等带来了巨大影响,因此物流业被喻为经济发展的“加速器”。
在物流系统的运作中,配送中心的选址方式往往决定着物流的配送距离和配送模式,进而影响着物流系统的运作效率。因此,研究物流中心选址具有重要的理论意义和现实应用意义。一般来说,物流中心选址模型是非凸和非光滑的带有复杂约束的非线性规划模型,属于NP-hard问题。
2 PBIL算法简述
PBIL算法是美国卡内基梅龙大学Baluja.S.提出的进化学习算法[1],是遗传算法和增强式学习算法的结合,它将进化视为学习过程,用学习所获得的知识-概率模型来指导后代的产生。这种概率是整个进化过程的信息累积,同遗传算法相比,用它来指导产生的后代将更优生,因而在许多问题中能获得更快的收敛速度和理想的计算结果[2]。目前PBIL算法已应用到许多实际问题中,如TSP问题、最小码覆盖问题[3]、合同匹配问题[4]。
2.1 PBIL算法基本原理
PBIL算法的特点是用概率向量来约束染色体中每一个基因位的取值,因此它适合用于二进制编码求解问题。若一个染色体的编码有n个基因位,则概率向量为P{p1,p2,...,pn},0≤pi≤1,i=1,2,...,n,当pi=0.5时,第i个基因位取0或1的机会相等。
基于二进制编码的PBIL算法处理流程如下:
(1)初始化操作。确定种群的规模N、学习因子r、变异因子rm、变异概率pm、最大迭代次数MG、概率向量P={0.5,0.5,...,0.5}。
(2)k=0;k为迭代次数。
(3)while(k<MG)
{根据概率向量P随机产生N个个体;
检验并计算每个个体的适应度值;
选出当前种群的最优个体Vmax;
根据最优个体Vmax更新概率向量P;
根据变异概率pm对向量P进行变异操作;
k++;}
(4)输出MG中适应度值最优的个体。
(5)PBIL算法主要经过个体生成、概率向量更新和概率变异三个操作,反复执行逐渐朝全局最优解逼近,达到最大迭代次数时,各基因位上的学习概率值大小分别接近1或0。
2.2 PBIL算法与遗传算法
在传统的遗传算法中,用种群表示优化问题的一组候选解,种群中的每个个体都有相应的适应值,然后进行选择、交叉和变异等操作,反复进行,对问题进行求解。而在PBIL算法中,没有交叉、变异等操作,取而代之的是概率模型的学习和采样。PBIL算法采用统计学习手段从群体宏观的角度建立一个描述解分布的概率模型,然后对概率模型随机采样产生新的种群,如此反复进行,实现种群进化,直到满足终止条件。
从两个算法的进化原理可看出:遗传算法的交叉、变异操作能产生更好的个体,也能产生更坏的个体,进化较为缓慢;PBIL算法通过修改概率模型参数使新的个体更优,能快速准确地收敛到最优解。
3 PBIL算法求解物流中心选址问题
3.1 物流中心选址问题数学模型
物流中心选址问题描述:某城市有n个需求点,需建立一个物流中心,物流中心到每个需求点的单位距离运输成本分别为c1、c2...cn,到每个需求点的距离为d1、d2...dn,每天需向每个需求点配送一次货物。现要选择一个物流中心,使得配送成本最低。本模型将城市简化成L乘W的长方形区域块,物流中心和需求点的坐标均为正整数。
数学模型表示如下:
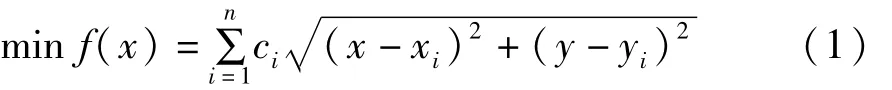
约束条件0≤x≤w,0≤y≤l
其中:x、y为物流中心的横坐标和纵坐标,xi、yi为需求点的坐标。
3.2 算法具体实现
这里给出一个物流中心选址问题的实例,城市规模为100乘50,6个需求点的坐标和单位距离运输成本见表1。
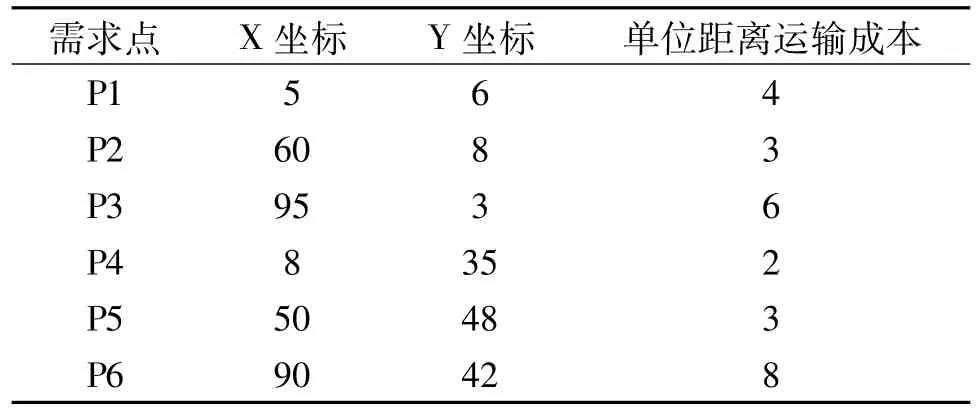
表1 需求点坐标和运输成本
(1)确定物流中心选址问题的编码方案。
100表示成二进制为1100100,50表示成二进制为110010,则共需要13个基因位。将染色体表示成一个基因序列G=(g1,g2,...,g13)。
(2)初始化操作,设定参数值:种群规模N= 20,最大迭代次数MG=100,学习因子r=0.1,变异概率pm=0.2,概率向量P={0.5,0.5,...,0.5}。
(3)根据P随机产生N个个体,判断每一个个体是否满足公式(2)的约束条件,若不满足,则将此个体丢弃,再随机产生一个新的个体。
(4)计算适应度值。根据公式(1)计算出每一个个体的适应度值,并从中选择一个最优个体。
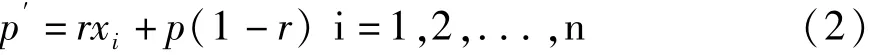
(5)选出的最优个体按照以下公式更新概率向量P:其中:xi为最优个体中第i个基因位上的值,r为学习因子。
(6)生成一个0到1之间的随机数,如果该数小于变异概率pm,对概率向量进行变异操作,公式如下:
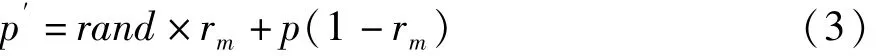
其中:rm为变异因子,通常取rm=0.1,rand是一个0到-1之间均匀分布的随机数。
(7)按照更新后的概率向量P重复上述操作,直到达到最优值或最大迭代次数为止。
3.3 实验结果分析
针对上面给出的物流中心选址问题的实例,使用matlab编写遗传算法和PBIL算法程序。两个程序分别运行5次,比较它们的结果,具体数据如表2和表3所示。

表2 遗传算法程序运行结果
遗传算法参数设定如下:种群规模为20,最大迭代次数为200,交叉概率为0.6,变异概率为0.1,选择操作采用“轮盘赌法”。
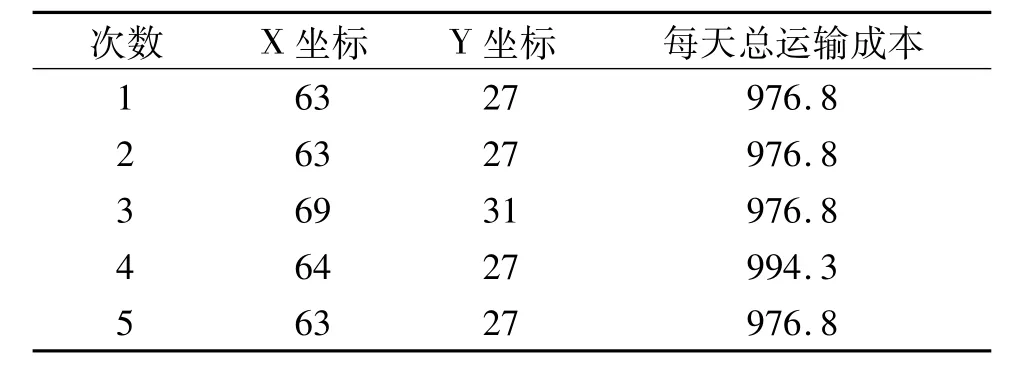
表3 PBIL算法程序运行结果
从5次运行结果来看,遗传算法找到最优解的次数为2次,PBIL算法找到最优解的次数为4次。而且PBIL算法得到的解均小于1000。从数据上来看,PBIL算法迭代100次所找到的解明显优于遗传算法迭代200次的结果。
4 结束语
对于同一个问题,PBIL算法在迭代100次后能找到一个比较令人满意的结果,而用遗传算法则需要迭代200次以上才能找到这样的解。所以在收敛速度上PBIL算法优于遗传算法。另外,由实验结果可以看出,PBIL算法得到的最优解比遗传算法要好,说明其搜索效果更好。以上证明了用PBIL算法求解物流中心选址问题比用遗传算法求解该问题更为快速和有效,算法应用是成功的。
[1] SBaluja.Population-based Incremental Learning[R].Technical Report,CMU-CS-94-163,CarnegieMellon University,1994.
[2] 金炳尧,蔚承建,何振亚.一个用于优化搜索的学习算法[J].软件学报,2001,12(3):448-453.
[3] 林大瀛,郝志峰,舒蕾.应用基因概率学习算法求解最小码覆盖问题[J].华南理工大学学报(自然科学版),2003,31(6):67-70.
[4] 胡琨元,朱云龙,汪定伟.自适应PBIL算法求解合同优化匹配问题[J].系统工程,2004,22(12):87-91.
Study on the Logistics Center Location Problem Based on PBIL Algorithm
WANG Xiao-bo,FU Shan-shan,JILing,YANG Ya,ZHANG Hai-xia
(College of Internet of Things Engineering,Hohai University,Changzhou 213022,China)
The principle and realization of PBIL(Population-based Increased Learning)algorithm are introduced in this paper.The differences between PBIL algorithm and genetic algorithm are compared in their process.The application of logistics center location problem based on PBIL algorithm is analyzed.The feasibility and validity of improved algorithm is proved.The experiments result shown that the searching efficiency and accuracy of PBIL algorithm are higher than that of genetic algorithm.
PBIL algorithm;Evolutionary computing;Genetic algorithm;Logistics Center Location
10.3969/j.issn.1002-2279.2014.02.018
TP301.6
A
1002-2279(2014)02-0058-02
王晓波(1989-),男,江苏徐州人,硕士研究生,主方向:智能算法。
2014-01-09
·微机应用·
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
趣味(数学)(2020年4期)2020-07-27 01:44:16
支部建设(2020年15期)2020-07-08 12:34:32
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
智能系统学报(2015年4期)2015-12-27 09:38:39
新高考·高二数学(2015年11期)2015-12-23 18:17:44
