
基于关键词语义与作用域扩展的事件检测
2014-09-29 10:32褚衍杰李云照
计算机工程 2014年8期
褚衍杰,魏 强,李云照
(盲信号处理重点实验室,成都 610041)
1 概述
事件检测与描述由自动文本抽取(Automatcic Content Extraction,ACE)会议提出,主要研究从新闻语料中自动检测事件及其描述信息,是ACE会议除实体识别和实体关系识别的又一研究热点。在微博、论坛、短信等应用中,除了本身内容外文本一般还具有浏览与被浏览、转发与被转发、发送与接收等关联要素,本文研究从具有关联要素的中文文本中检测目标事件的问题,以实现从此类文本中挖掘目标事件信息的目的。
事件检测主要使用聚类、分类等机器学习方法,如文献[1]提出利用MegaM和Timbl这2种机器学习方法分别实现事件类别检测和元素识别;文献[2]提出基于触发词指导的自相似度聚类方法,利用触发词及命名实体信息解决了对事件类别模板的依赖性问题;文献[3]提出基于情感计算的微博突发事件检测方法,利用突发情感特征及谱聚类方法实现微博突发事件检测及抽取;还有很多学者致力于研究如何提升事件检测的性能[4]。
本文在ACE事件检测与描述框架的基础上结合文本的关联要素分析和内容分析,提出基于关键词语义和作用域扩展的事件检测方法。
2 ACE的事件检测框架
自由文本中出现的事件,都有明确的当事者或者实施者,有构成事件的基本要素:时间,地点,人物等。ACE2005的思想是如果能够把事件的特征要素识别出来,填入事件列表,那么维护此列表即可实现对事件的检测和跟踪。ACE2005对事件检测技术进行分割,划分为事件类别识别和事件元素提取2个主要步骤:
(1)事件类别识别:ACE2005定义了8种事件类别以及33种子类别。每种事件类别/子类别(简称为事件类别)对应唯一的事件模板,事件类别和模板如表1和表2所示(事件模版内容较多,仅列出部分,详细内容可参见 ACE2005[5]相关章节)。
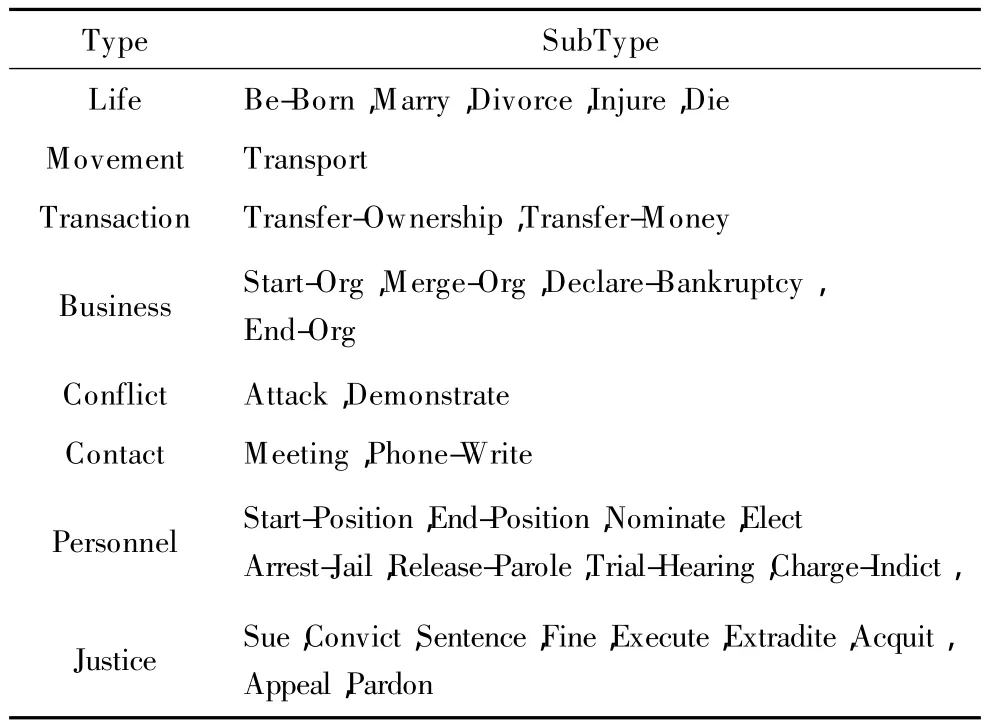
表1 ACE定义的事件类别

表2 ACE定义的事件模版
(2)事件元素提取:根据所属的事件模板,提取相应的元素,并为其标上正确的元素标签。
在事件类别识别中[6-8],一般分 2 步进行:确定候选事件集合和候选事件识别。其中,确定候选事件集合是根据语句中出现的触发词决定事件类别,如“小明出生在2000年”,其中触发词是“出生”,决定了该事件属于“Life/Born”类。触发词-事件的对应关系由训练得到。利用该方法可以对一段文本分析形成一个候选事件集合。候选事件识别是判断该候选事件是否属于该事件类别,一般根据词法、上下文等特征进行判断。
3 基于关键词语义与作用域扩展的事件检测
3.1 问题分析及改进方法
具有关联要素的中文文本事件检测问题,可以描述为从具有关联要素的N个文本T={t1,t2,…,tN}中,发现与目标事件相关的所有文本ti,并提取出每个文本的简要信息。每个文本由关联要素和字符文本组成,即:ti={fromer,toer,time,c1c2…cMi},其中,fromer和toer分别表示文本关联关系的双方,比如评论人和被评论人、发送人和接收人等;time表示文本产生的时间,c1c2…cMi表示文本的内容;目标事件通常用一组关键词向量 W={w1,w2,…,wK}表示,其中,wi(1≤i≤K)可能是事件涉及的人、物、时间、地点、动作等。
本文提出的事件检测模型的基本思想是利用关联关系分析扩展关键词的作用域,利用基于文本库的训练扩展关键词的语义,从而提高事件的检测率,具体介绍如下:
(1)关联关系分析:对于同一事件的不同发展阶段,可能会涉及到不同的话题,例如一宗商业交易的事件中,一般会涉及合同签订、货物运输、货物验收、汇款交付等不同话题,其中涉及的关键词可能相差甚远。在没有关联要素的事件检测中只能够利用事件跟踪技术跟踪事件的发展变化,而在有关联要素[9]的情况下,问题可以得到简化,即利用关联关系就可以将事件的不同阶段组合起来,形成完整的事件流。但是从另一个角度来讲,若文本集T中含有事件参与者参与非目标事件的文本时,使用关联关系进行文本关联会将其他事件也纳入检测结果。为了解决该问题,本文利用剪枝处理的方法滤除噪声文本,即通过历史经验剪掉一条关联链路,从而滤除该关联链路涉及的大量文本,如图1所示,假设A,B,C,D这4个文本是某事件的所有文本,但是由于B和E之间有一次关联,导致了引入E,F,G,H的噪声文本,由于本文讨论的文本一般较短,目标文本量也较少,单纯从文本内容相似度的角度很难区分噪声,因此利用历史经验剪掉B,E间的链路,滤除E,F,G,H。
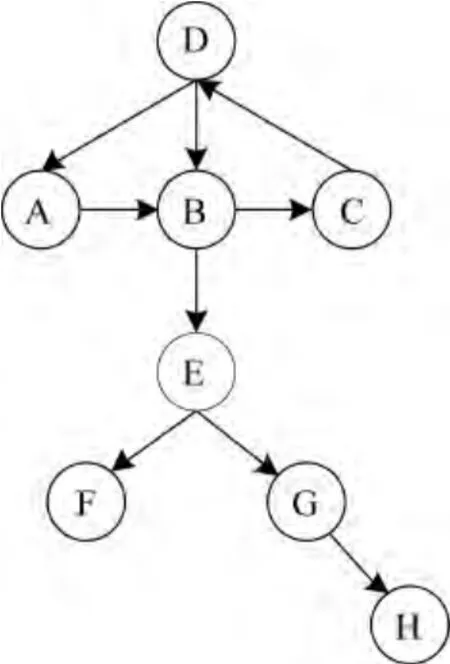
图1 剪枝方法示意图
(2)关键词语义扩展:由于表达方式的多样性,关键词向量W={w1,w2,…,wK}并不能完全描述目标事件,以该向量为关键词,极有可能无法检测到事件的相关文本,因此使用关键词语义扩展[10-12]的方法,即在文本资料库中检索每个关键词,统计在关键词周围一定范围内出现的名词、动词、时间词,然后根据出现位置、出现频次选取与关键词语义关系最近的L个词,依此形成扩展词向量:W′={w1,w11,w12,…,w1L,w2,w21,w22,…,w2L,…,wK,wK1,wK2,…,wKL}。其中,L表示扩展词的数量。在模式匹配模块,同一关键词及其扩展词之间是“或”关系,而不同关键词之间是“与”关系。分析显示,扩展词的数量越多,匹配的结果越多,但会引入很多噪声文本,本文一般选取4个~6个扩展词,以历史数据和北大CCL语料库作为训练文本资料库。
(3)关键词作用域扩展:当关键词数量较多时,由于事件描述过于精确,容易造成漏检问题,例如同一商业事件的2个文本中分别出现了“采购”和“合同”2个关键词,若使用“采购&合同”作为关键词进行搜索,就会造成这2个文本的漏检。为了避免上述问题,本文通过采用关键词分组并进行2次关键词匹配和关联要素分析的方法来扩展关键词的作用域。文中将 W={w1,w2,…,wK}分为2个组,W1={w1,w2,…,wθ}和 W2={wθ+1,wθ+2,…,wK}。其中,θ为关键词分组的边界。本文方法利用W1进行松散匹配,并通过关联要素分析得到有关系的文本群,然后利用W2在文本群中进行匹配和关联要素分析。在这种方法下如果W1出现在某个文本中,而W2出现在与该文本有关联的另一个文本中,也不会出现漏检现象,相当于将W1和W2的“与”关系的作用域扩展到具有关联关系的文本群。分析显示,关键词分组数越多,作用域扩展效果越好,但关联分析带来的运算量越大。
3.2 算法框架介绍
本文提出的基于关键词语义和作用域扩展的事件检测流程如图2所示。
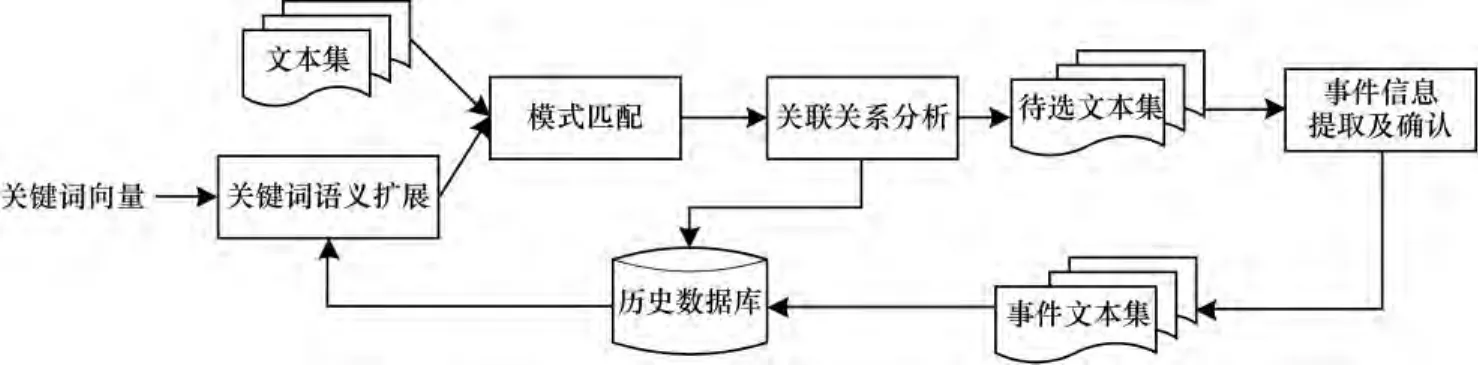
图2 基于通信关系和内容分析的事件检测流程
历史数据库中包含按照政治、经济、军事、体育等主题划分的历史文本和新闻类文本,以及在过往处理中已经确认的事件参与者的关联关系网。
关键词语义扩展模块通过历史数据库中的历史文本以及新闻类文本,训练得到关键词向量的扩展词向量,对每个关键词wi(1≤i≤K)扩展的具体步骤如下:
(1)以关键词wi作为条件,对所有训练文本进行搜索。
(2)在匹配的文本中找到wi出现的位置P,对以P为中心,长度为2D的文本进行分词处理。
(3)以P为中心,向前、向后分别搜索长度D,记录出现的名词、动词、时间词,并记录出现的次数和到位置P的距离。
(4)完成对所有匹配文本的处理,计算每个词的得分:
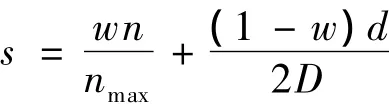
其中,w为词频和距离的权重比例;n为该扩展词出现的次数;nmax为所有词出现的最大次数;d为该词与wi的平均距离。
(5)选取排名前L位的词,与wi一起组成扩展词向量={wi,wi1,wi2,…,wiL}。模式匹配模块按照扩展词向量对文档执行匹配操作,选取所有匹配文本,供关联关系分析模块使用,本文采用正则表达式完成模式匹配。
关联关系分析模块对扩展词向量的匹配文本进行处理,分析关联关系,形成关联关系网,并进行剪枝处理,形成该事件的待选文档集合,具体步骤如下:
(1)提取每篇匹配文档的fromer和toer。
(2)以fromer和toer为关键词,对原始文档集中所有文档的进行匹配,选取所有匹配文本,并提取其 fromer和 toer。
(3)重复步骤(2)若干次,一般不超过5次。
(4)以获取的所有fromer和toer信息为基础,构造关联关系网,利用历史数据库中的同类事件关系网,判断每个fromer/toer是否可能涉及目标事件,并以此为标准进行剪枝操作。
(5)剪枝操作后,剩余的所有文档形成事件的待选文档集。
事件信息提取及确认模块提取每个待选文本的事件元素信息,并按事件顺序组织文本,形成对事件的整体描述,然后人工根据事件的描述信息判决是否是目标事件。由于本文涉及的文本一般较短,因此适合使用ACE的事件类别识别、事件元素提取方法。
3.3 算法步骤
算法具体步骤如下:
(1)将关键词 W={w1,w2,…,wK}分成 2组:W1={w1,w2,…,wθ}和 W2={wθ+1,wθ+2,…,wK}。
(2)分别对W1和W2进行关键词语义扩展,形成扩展词向量 W′1和 W′2。
(3)利用扩展词向量W′1对原始文本集进行模式匹配,得到匹配文本,然后在匹配文本的基础上进行关联关系分析,得到中间文本集。
(4)利用扩展词向量W′2对中间文本集进行模式匹配,得到匹配文本,然后在匹配文本的基础上进行关联关系分析,得到待选文本集。
(5)在待选文本集的基础上按照ACE框架判断事件类别,提取事件信息,确认目标事件,将目标事件的文本、关联关系存储到历史数据库。
4 实验及分析
本文在以下实验环境中对算法进行了测试。实验平台为Windows XP操作系统,系统配置为Intel(R)Core(TM)i7 -2600 CPU@3.4 GHz,内存4 GB,算法在Microsoft Visual Studio 2010环境下实现。测试目标事件是一个商业上关于物资发送-索赔的事件样本,共包含12个具有关联要素的文本;测试噪声数据为4988个具有关联要素的其他文本。关键词语义扩展的训练数据为北大CCL语料库。在下面的测试结果中,事件群是指具有关联关系的文本组成集合,例如12个目标文本就是一个事件群;事件群数量是指事件检测结果中包含事件群的数量。
为了验证算法效果,表3~表5分别给出了在单关键词条件下,使用不同关键词和不同扩展词数量时的实验结果,从实验数据可以看出,由于算法使用了关键词语义扩展,因此利用目标文本中未出现的词作为关键词时依然能够发现目标事件,而且扩展词数量越多,发现目标事件的概率越大;但是扩展词越多会使运算量增大,且检测结果中非目标事件群越多,本文推荐使用4个~6个扩展词。
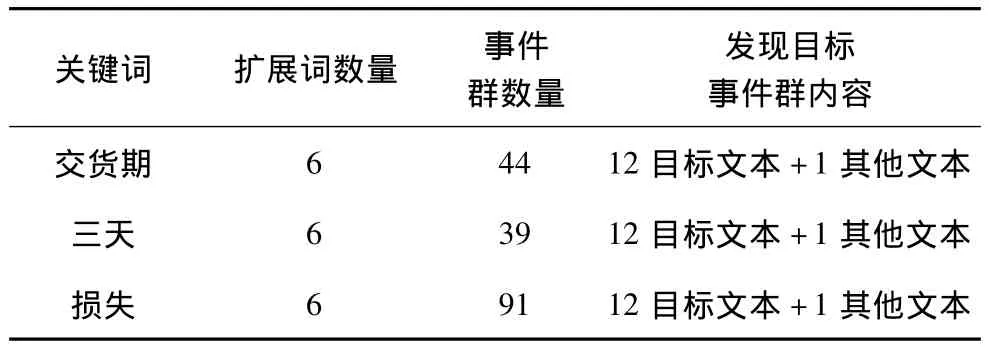
表3 目标文本中的词作为关键词的检索结果
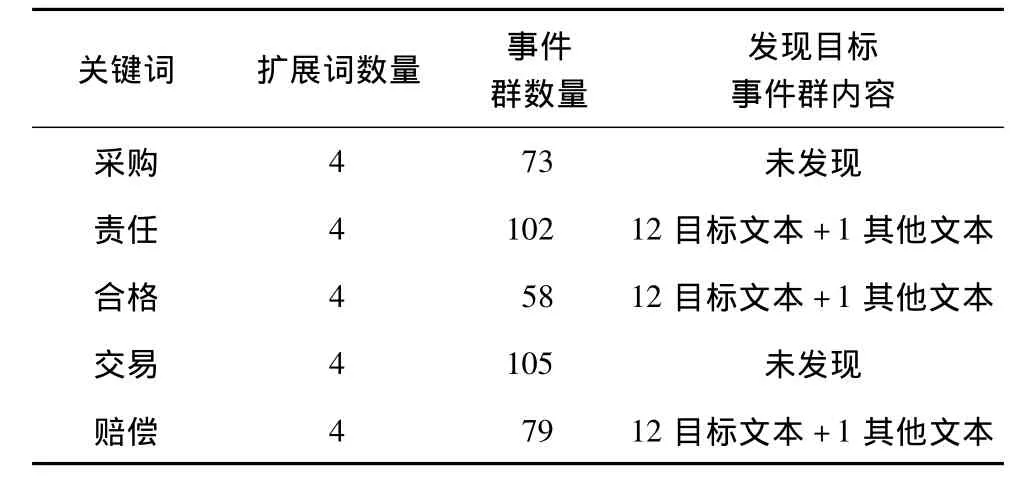
表4 目标文本外的词作为关键词的检索结果(4个扩展词)
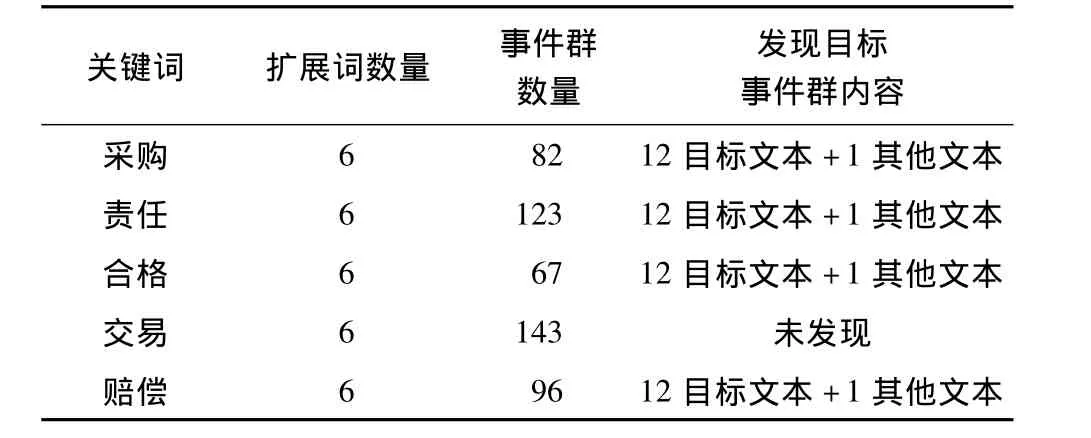
表5 目标文本外的词作为关键词的检索结果(6个扩展词)
表6给出了使用含有2个词的关键词向量作为检索条件时的实验结果,而且在目标文本中不会同时出现关键词向量中的词或其扩展词。如果按照正常的关键词匹配,无法检测到目标事件;由于本文算法采用了关键词分组及2次匹配的方法扩展了关键词作用域,相当于将事件群中的所有文本作为一个整体进行“与”关系的匹配,因而能够检测到目标事件,而且检测结果中非目标事件群数量比单关键词的结果显著减少。

表6 关键词向量检索结果
5 结束语
本文研究具有关联要素的中文文本事件检测问题,通过关键词语义扩展提高关键词匹配的概率;通过关键词分组、关联关系分析和二次匹配实现了关键词逻辑关系作用域的扩展,从而降低关键词向量匹配的漏检率;综合上述方法提出的事件检测算法能够有效地从有关联要素的中文文本中检测到目标事件。实验结果显示,该算法能够有效减少漏检率,提高检测率。
下一步将针对算法性能的定性分析、运算复杂度的简化等问题开展研究,以提高其在实际应用中的使用效果。
[1]Ahn D.The Stages of Event Extraction[C]//Proc.of Workshop on Annotations and Reasoning About Time and Events.[S.l.]:ACM Press,2006:1-8.
[2]张先飞,郭志刚.基于触发词指导的自相似度聚类事件检测[J].计算机科学,2010,37(3):212-220.
[3]张鲁民,贾 焰,周 斌.基于情感计算的微博突发事件检测方法研究[C]//第27次全国计算机安全学术交流会论文集.九寨沟,四川:[出版者不详],2012:143-145.
[4]王颖颖,张 赟,胡乃静.在线新事件检测系统中的性能提升策略[J].计算机工程,2008,34(15):72-74.
[5]Linguistic Data Consortium.ACE(Automatic Content Extraction)Chinese Annotation Guidelines for Events[EB/OL].(2005-05-09).https://www.ldc.upenn.edu/Projects/ACE.
[6]付剑锋,刘宗田,刘 炜,等.基于特征加权的事件要素识别[J].计算机科学,2010,37(3):239-241.
[7]将德良.基于规则匹配的突发事件结果信息抽取研究[J].计算机工程与设计,2010,31(14):3294-3297.
[8]姜吉发.一种跨语句汉语事件信息抽取方法[J].计算机工程,2005,31(2):27-29.
[9]李 潇,罗军勇,尹美娟.基于邮件通联关系的邮箱用户权威别名评估[J].计算机应用与软件,2011,28(4):271-273.
[10]王昭龙,李 霞,许瑞芳.多关键词查询中LCA剪枝概念数的查询扩展技术[J].计算机科学,2010,37(4):132-162.
[11]汪 洋,帅建梅.基于语义扩展模型的中文网页关键词抽取[J].计算机工程,2012,38(22):163-166.
[12]杜金洋,易 河,杨 春.基于关键词语义扩展的检索策略[J].计算机应用,2009,35(6):1575-1577.
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
开放教育研究(2020年2期)2020-03-31
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
现代语文(2016年21期)2016-05-25
新校长(2016年8期)2016-01-10
大连民族大学学报(2015年2期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
