
FP-Tree算法在饰品设计中的应用
2014-09-21 11:57黄玮
重庆科技学院学报(自然科学版) 2014年4期
黄 玮
(闽江学院软件学院,福州 350011)
在企业产品设计管理过程中,需要找到设计与市场、生产等不同维度指标之间的规律,然后根据这些规律,有针对性的设计指标。为此提出在饰品开发部门使用FP-Tree算法进行数据挖掘,以找到隐藏于数据之下的规律,并使用这些规律进行饰品的设计和指导设计部门的日常管理。
数据挖掘技术在产品设计领域应用越来越广泛,相关研究也不断深入。针对创新设计过程中的知识获取和挖掘需求,文献[1]采用向量空间模型的夹角余弦算法对知识进行挖掘处理,实现对网络创新知识的获取。文献[2]中,进行外观创新设计时按照产品形式美学、使用方式及文化时尚分类建立创新案例库,实现以用户为中心的产品开发。文献[3]研究了概念设计过程中所需的知识构建了该过程中基于知识工程理念的知识获取系统框架。文献[4]则认为在未发现潜在市场需求之前,产品应先行进化,为此构建了进化驱动型产品创新设计方法。
数据挖掘应用于饰品开发领域时具有以下特点:(1)客户订单产品类别分布离散,无特别明显的市场关注产品,不易收集市场评价;(2)饰品开发有很大的主观性,无法精确判断产品的外观特性;(3)除产品外观外,种类、材质、工艺、地域、季节等也对产品的生产订购有较大影响。上述特点与之前文献中所列举的环境有所区别。为了便于分析挖掘规律,此处使用FP-Tree的改进算法实现对数据的挖掘。
1 FP-Tree算法
FP-Tree算法是Jiawei Han教授提出的一种不需要生成候选频繁项集的关联规则挖掘算法。在该算法中其采用分治的策略,使用频繁模式树存储频繁项信息,然后利用该树生成频繁项目集。由于该方法不生成候选项目集,且仅需扫描2次数据库,极大提升了挖掘效率。
FP-Tree算法有 Build_FP-Tree、Insert_FPTree及FP_growth等行为。Build_FP-Tree根据事务数据库DB与最小支持度Minsup生成频繁项表。Insert_FP-Tree,则根据已生成的频繁项集创建树的分支。在该过程中对数据库中的每一个事务创建一个分支,在后续事务分支的创建过程中可与前事务共享前缀。FP_growth则在Insert_FP-Tree创建树的基础上进行挖掘。设挖掘的目标为p,只需要树中求得以p为结尾的分支即可得到挖掘的结果。
2 数据挖掘过程
2.1 数据预处理
用于挖掘的数据主要有两个方面的来源,一是业务售部门提供的历史销售数据,二是质检查部门提供的历史抽检情况。在数据挖掘前,对原始数据需要进行预处理,使之能被应用于挖掘。
(1)数据合并处理。两种数据存在较大的不同,先行对其进行合并。合并以订单编号与产品编号为关键字。合并后的原始数据库DB具有以下结构:(产品编号、产品名称、订单编号、订购时间、客户ID、数量,…,质检员ID,返工数,…)。由于产品编号、产品名称并不能反映产品的属性,因此需要对其进行扩展。
(2)设计属性处理:产品属性根据目的可分为设计属性与工艺属性。对于产品的设计属性,由开发部门提供。开发部门根据对产品进行总结,从文化、情感、美观等多个角度总结产品的设计属性。由于开发部门之前没有做过这一类似的工作,出于工作量的考虑,只取销售数据中销售额最大的前10%产品进行分析。将这些产品样品提供给开发部门的领域专家,由领域专家用多个简短的形容词来总结其产品的属性,例如“简约”、“华贵”等。统计每个属性出现频率后取前20%的属性放入属性库中。
属性库中存放的是用于描述所有产品可能出现的设计属性,针对具体的产品需要为其设计属性进行度量。度量公式为:
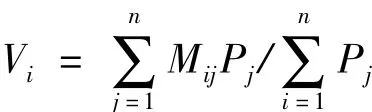
式中:Vi为产品在第i个设计属性上的值;Mij表示第j个人在对产品的i属性给出的评价值;Pj为该评价人的权重。由于Vi的取连续数值,后续需要进行离散化的处理。
(3)工艺属性处理:工艺属性反映产品工艺上的物理特征,例如:材质、大小、光面,特殊工序等,与设计属性相比,这一部分的属性较为客观,由生产部门提供。
(4)离散化处理。例如光面大小的取值是个连续的范围,根据加工工艺可对其分为L、M、S等三个类别。对于时间的分,只以淡季、旺季、正常三种离散的值进行划分。对于一种产品的市场价值,则以每年度所有订单中该产品的总金额进行划分,按金额的大小由财务部门将其划分为极重要、重要、中等、一般、不重要5个类别。而对于(2)中的产品设计属性Vi,则设计一个阀值λ,当Vi<λ时,取Vi=0;当 Vi≥ λ 时,取 Vi=1。
(5)数据扩充与消减处理:为了反映产品与销售之间的关联,需要在挖掘前增加客户的相关信息(区域、规模……)。同时消去与挖掘目的没有明显关联的属性或重复的属性。如当对研究市场情况时,消除与质检的相关信息。
2.2 数据挖掘
(1)设 min_sup=10%,min_conf=40%
(2)第一次扫描数据库时,导出频繁项集L=(银材 a、时尚 b、永恒 c、…..、光面大 n、……),其中a,b,c,n表示支持度。根据频繁项集中每个元素的支持数排序后去除不频繁的项,达到化简数据库的目的。表1中给出了部分原始数据库与排序后的部分数据示例。

表1 原始数据库/排序后的数据库(部分示例)
表中的示例使用中文进行说明,在实际挖掘的过程中则根据数据字典的编号进行处理。
(3)第二次扫描数据库,对每一个事务创建分支。例如,读取1001事务时,创建构造树的第一个分支<银材1→时尚1→永恒1→一般1>。对于第二个事务,由于其排序后的频繁项表<银材1→时尚1→尖晶1→中等1>与已有分支共享前缀<银材、时尚>因此对前缀的每个结点数加1,形成新的分支<银材2→时尚2→尖晶1→中等1>。扫描完数据库DB中的所有事务后,即可得到FP-Tree树,图1给出了该树的部分结构。
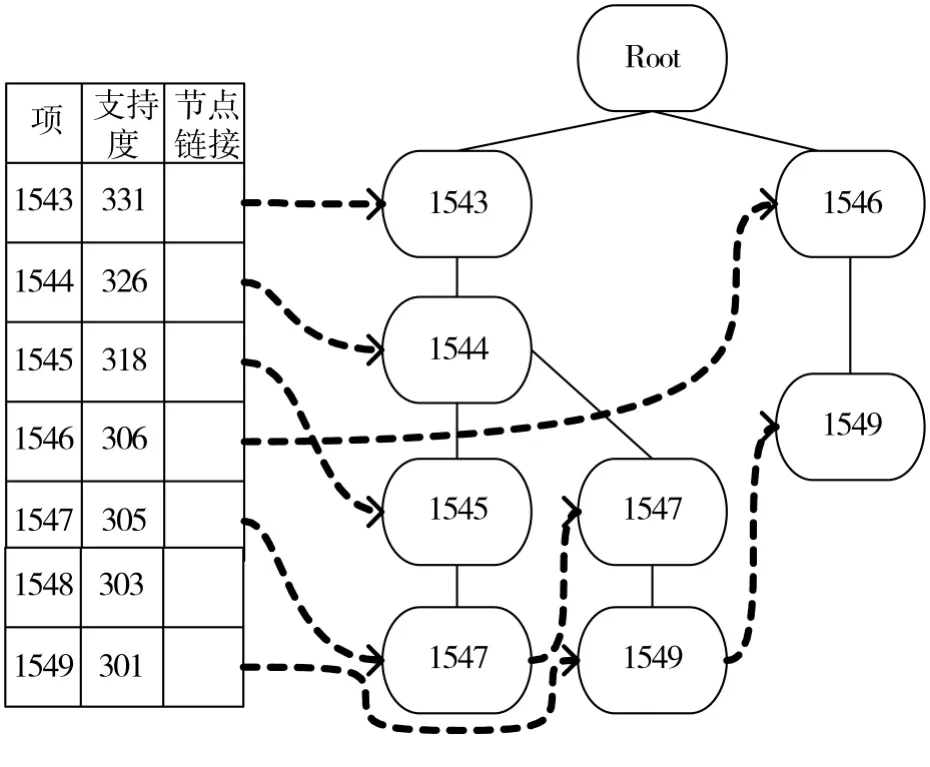
图1 FP-Tree树部分示例
2.3 结果分析解释
对数据进行挖掘后可获得饰品与设计、市场、工艺等相关的信息,除去一些明显的已为企业所知的规律,以下提供部分的示例用以说明。
银材饰品在所有被订购的产品中的份额最大,黄金材质饰品则有稳定的销量和周期。具有较大光面的饰品和嵌有大号水钻的饰品往往具有“时尚”属性,磨砂工艺的产品多具有“华贵”属性,超过之前所认为的电镀。使用皮绳部件的饰品多具有“新潮”这一设计属性,与手链产品关联大,多用“古银”工艺。在工艺上震桶、修边的返修率低,而抛光则有最高的次品率和返修率,在现有的工艺下需要减少产品的光面。
3 挖掘结果在管理中的应用
在明确了解产品的设计属性所对应的市场价值及工艺成本后,开发部门可以以此为依据进行开发人员绩效的考核;由于可知饰品材质、外型、颜色、零配件等多种物理属性与设计属性之间的对应关系,在设计时可避开工艺上不易于生产的部分,减少生产的成本;将客户属性也纳入挖掘体系后,得知地域与产品属性的关联情况。以上这些均可在开发部门对新员工的培训时进行有针对性的训练,减少其自行摸索的时间成本。
可见在对饰品的相关数据进行挖掘后的信息有利于开发部门的管理规范化,减少了之前粗放式管理的管理成本,提高了企业的开发效率,也增加了企业对市场的把握能力。
4 结语
饰品开发中的主观性强,对新产品的在市场、生产等维度上的优劣难以判断。这给开发部门的绩效管理、成本管理、知识管理等均造成很大的困挠。在使用FP-Tree算法对历史销售数据与生产数据进行挖掘后得到了部分的未知知识,这些知识对于企业的管理起到了有效的指导作用。
[1]周翼,张晓冬,郭波.面向产品创新设计的网络知识获取及挖掘[J].现代制造工程,2010(6):28-31.
[2]刘征,孙守迁,吴剑锋,等.基于用户认知的产品外观创新设计知识模型[J].计算机集成制造系统,2009(2):59-64.
[3]姜娉娉,黄克正,黄宝香,等.产品概念创新设计中的知识获取[J].制造技术与机床,2005(8):41-43.
[4]麻广林,李彦,黄振勇,等.进化驱动型产品创新设计方法研究[J].计算机集成制造系统,2009(5):19-27.
[5]Han Jiawei,Pei Jian,Yin Yiwen.Mining Frequent Patterns without Candidate Eneration:a Frequent-pattern Tree Approach[J].Data Mining and Knowledge Discovery,2004,8(1):53-87.
猜你喜欢
现代装饰(2021年5期)2021-12-02
大众投资指南(2021年35期)2021-02-16
延河(2018年6期)2018-06-11
电力与能源(2017年6期)2017-05-14
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
信息通信技术(2015年6期)2015-12-26
Coco薇(2015年11期)2015-11-09
