
AVS熵解码在OMAP3530上的实现及优化
2014-09-17 10:27:18牛丽君
电视技术 2014年3期
宋 娜,牛丽君,张 刚
(太原理工大学信息工程学院,山西太原 030024)
AVS熵解码在OMAP3530上的实现及优化
宋 娜,牛丽君,张 刚
(太原理工大学信息工程学院,山西太原 030024)
结合DSP硬件结构,首先对指数哥伦布码算法的实现进行结构上的调整,其次对熵解码部分的手工汇编实现高效的流水编排,最后结合熵解码数据的存储访问对cache进行优化。仿真结果与传统的C语言相比,程序运行周期降低了约21.49%,码率也显著提高。
AVS;熵解码;OMAP3530;优化
AVS标准(Audio Video Coding Standard)是我国拥有自主知识产权的标准,具有计算复杂程度低、专利费用低、应用前景广阔等特点。OMAP3530是由TI公司推出的一款基于DSP TMS320C64X内核的视频处理器平台,由于功耗低、高性能、高并行等优点,已经成为实现智能手机首选的理想平台,为其增添实时图像编解码功能具有明显的应用价值。其中DSP内核有8个独立的功能单元,每个时钟周期内最多可并行处理8条32位指令[1]。体系结构上采用了超长指令结构,具有双16 bit扩充功能,可以在一个周期内完成双16 bit的加、乘、比较或移位等操作。本文结合AVS熵解码算法的特点,首先调整了k阶指数哥伦布码算法的结构,然后通过比较、跳转指令实现了ce(v)语法元素解析的码表切换,进而采用流水技术优化手工汇编,最后对cache进行优化,解码速度显著提高[2]。
1 AVS熵解码的主要模块
AVS熵解码包括对语法元素的解析和残差数据的解码。解码过程中,两者均以指数哥伦布码的形式映射成二进制比特流。AVS标准中采用ce(v)映射方式描述残差数据,采用0到3阶指数哥伦布码进行解析,再通过查表得到run和level值。最后通过level值比较判断,更新码表解析下一个残差系数。
1.1 k阶指数哥伦布码
指数哥伦布码比特流由前缀、后缀及分隔符“1”三部分组成。前缀是n个连续的0,后缀为n+k(其中k为指数哥伦布码的阶数)个比特,分隔符“1”介于前缀与后缀之间[3]。解码时,首先从比特流的当前位置开始查找以0开头的比特位,直到找到第一个非0位置,并把0的个数记为n,根据下式计算出codenum值。
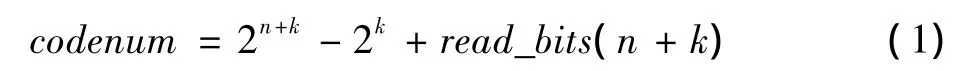
其中,read_bits(n+k)返回(n+k)比特码流对应的实际值。
1.2 ce(v)语法元素解析
如果trans_coeff<59,则trans_coeff=codenum;否则,解析下一个ce(v)语法元素,得到一个新的codenum。在AVS标准中熵解码部分规定了19个码表,其中亮度块部分帧内帧间各7个,色度块部分5个,不同的码表中ce(v)语法元素解析采用不同阶数(0、1、2、3阶)的指数哥伦布码[4]。k规定如下:
1)trans_coeff<59时:
(1)以abslevel为索引按照以下方法查找得到码表的tabnum:

(2)以tabnum为索引查找最终得到k值:

2)trans_coeff≥59时:
需要解析下一个ce(v)语法元素,此时需要根据不同的k值来解析得到一个新的codenum(<59)和escape_level_diff,其中escape_level_diff与k值有关

最终结合1)查找码表。
1.3 解码流程
解码过程中以k阶指数哥伦布码返回值codenum作为索引查找码表,最终生成run和level数组。解码流程如图1所示。

图1 解码流程图
如果trans_coeff<59,则以该值作为索引在当前码表中查找run、level值;如果trans_coeff≥59,解析下一个ce(v)语法元素,得到新的codenum值和escape_level_diff值,由此可以根据以下式子计算出run、level值

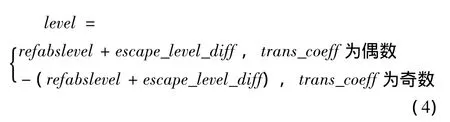
其中,refabslevel值由run值确定,如果run>Maxrun,refabslevel=1;否则,以run为索引查找当前码表得到;escape_level_diff由ce(v)语法元素解析得到。
最后,保存run、level值,更新当前码表及指数哥伦布码阶数,解析下一个残差系数,直到trans_coeff=EOB跳出循环,最终返回生成的run、level数组。
2 AVS熵解码在DSP平台的实现及优化
2.1 指数哥伦布码的实现及优化
式(1)是实现AVS指数哥伦布码的算法。由于指数哥伦布码的码长由码字内容决定,而在AVS码流中一次读取码流位数不超过32 bit,因此在读取码字时需要逐位读出,会导致过多的函数调用,容易打断处理器的流水操作,不利于编译器对程序的优化。本文结合指数哥伦布码的结构特点,并充分利用DSP资源,提出了以下实现方案:
由式(1)可知:2n+k即为分隔符“1”所在比特位置的实际值,因此可以将式(1)变形为
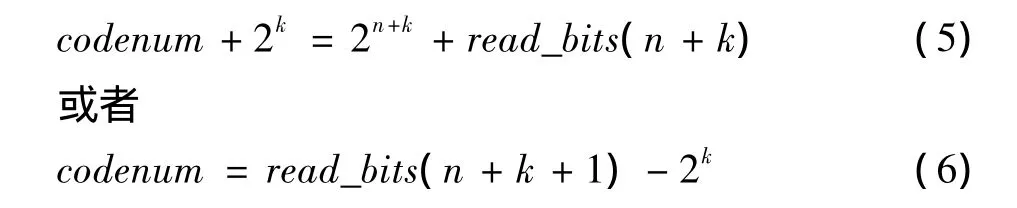
其中,read_bits(n+k+1)返回n+k+1比特码流的实际值,称其为哥伦布码字值。即最终的码字值codenum为哥伦布码字值与2k之差。由式(6)可得指数哥伦布码实现方法:
1)确定阶数k和需要解码的二进制码流;
2)求出分隔符“1”与后缀部分比特流的实际值,即哥伦布码字值,然后计算出2k;
3)将2)中两个值作差,求得码字值codenum。
结合DSP的硬件结构,本文的算法可一次性读取多个比特码流,拼接并返回待处理的32位码,放入缓存区。然后利用式(5)进行计算。与传统AVS算法相比,减小了算法复杂程度,指令占用的CPU周期也大幅度减少,且便于调试。
2.2 AVS熵解码算法端的实现及优化
在OMAP3530上实现AVS熵解码采用的是TI公司提供的用C/C++和汇编语言开发的CCS软件平台,其中算法的实现部分主要是评估测试代码,进而优化得到实时解码的要求[5]。结合AVS熵解码的原理与TMS320C64x+硬件结构特点,算法实现模块主要从手工汇编和cache性能入手。首先采用手工汇编优化,最后结合cache性能进行优化,提高命中率。
2.2.1 手工汇编优化
手工汇编代码的实现主要是利用软件流水技术对指令进行调度安排,使其能够在不同部件内交迭处理。结合C64x+DSP的结构,本文主要做了以下优化:
1)减小寄存器相关性
只有不相关的指令才可以并行执行,即在同一个指令周期内寄存器调用不能过于频繁。手工汇编中寄存器不是随机分配的,而是在程序执行前人为地将寄存器分配到各个变量中,因此减小寄存器相关性可以提高手工汇编的并行效率,降低程序执行周期。
2)减少多周期指令
在C64x+DSP指令集中,乘法指令延迟为1个周期,读取与转移指令分别为4、5个延迟周期。本文中用左移指令SHL代替乘法指令,成对使用传送指令MVKL、MVKH代替读取指令,将码表中的码字值用传送指令赋值给已分配好的寄存器。这样可以大大减少所占用的周期,而且方便了寄存器间各变量的调用。
3)并行指令
CPU运行时,在一个指令周期内可以独立运行8条指令。在根据codenum作为索引查找run、level值过程中,由于二者的值无任何关联性,可以分别分配到A组、B组寄存器中,由此在同一个周期中便可以采用不同的功能单元并行执行含有run、level变量的指令。
4)使用打包、解包指令
查找出run、level值后,分别将其保存到2个不同的寄存器数组中,增加了寄存器存储时间的消耗。可以先将二者打包后放在一个32位的寄存器中,逆扫描模块再进行解包处理,节省了寄存器存储所用的时间,而后续读取所需时间基本没变。
5)使用具有函数功能的指令
在C64x+DSP指令集中,使用汇编指令LMBD就可以很容易获得当前的寄存器在第一个非0系数前含有0的个数,可以迅速查找出前缀0的个数,快速确定n值,简化了程序,提高了执行效率。
6)填充NOP延迟间隙
使用多周期指令会出现延迟间隙,在数值上等于指令原操作数读取到执行的结果可以被访问所需的周期数。本文涉及到码表的选择与切换,有大量的条件转移指令含有5个周期的指令延迟间隙,系统自动安排NOP指令,造成浪费。所以使用转移指令后,尽量填充有用指令确保这5个周期的间隙不被浪费。
2.2.2 cache 优化
cache是介于主内存与CPU之间的高速缓存器,优化cache可以发挥CPU的高速度,提高内存访问与外部存储器访问的速度。本文采用OMAP3530 EVM主板存储,内部存储包括分别用于数据处理和程序处理的一级数据存储器L1D、一级程序存储器L1P,大小分别为80 kbyte、32 kbyte,且二者都可以配置成普通存储器SRAM和高速缓存 cache或者二者的结合;二级缓存 L2,大小为96 kbyte,作为程序和数据的共享空间[6]。工作原理是:CPU处理数据是从cache里查找数据,若cache命中,直接把数据从cache中取出,否则为cache miss,从下一级存储器中取出需要的数据,CPU处于等待状态时几乎不进行任何操作,为cache缺失停顿时间,等待CPU恢复工作后将后续相关数据装入cache中。本文主要采用的方法是合理分配数据和程序的内存,调整代码的存放,改变CPU的访问顺序,从而提高cache命中率。
1)数据cache优化主要是从调整算法结构的数据存储入手,避免数据的重复使用。优化时,将亮度和色度数据分开解码,且将两者的原始数据分别单独传输,待数据传出并存放在DDR中,最后集中处理。此外,对cache字节重新定义,确保解码阶段数据需求保持在32 kbyte内。最后利用TMS320C64X提供的编译指令#pragma DATA_SECTION,对解码数据进行合理分配存储。
2)程序cache优化与数据优化是一样的,亮度和色度解码的数据分开独立进行,将熵解码循环体所在宏块层改为帧层,帧内、帧间解码程序分开,尽量把程序分段,使每段能够控制在32 kbyte内。最终,每个循环体的指令数不超过cache容量,所以只有刚进入循环体初次执行时才会使主存装载指令到cache中,从而大幅度减少cache缺失和cache指令执行的次数,在优化的基础上也使开支降到最低。
在CCS3.3中用Profile Setup工具设置cache选项,然后用Cache Tune显示cache效率问题出现的区间,使之可视化,得到图2、图3仿真图。
用Profile性能分析工具可测出:一级缓存中数据cache命中率为97.28%,程序cache命中率为99.41%。
3 实验结论
在OMAP3530上正确实现熵解码的条件下,本文在XD560 Emulator上进行了仿真,并利用CCS3.3提供的Profile性能分析工具对选用的1~15 Mbit/s不同码率的标清尺寸AVS码流进行测试。解码测试条件有:帧率为25 Hz,解码50帧。考虑到图像大小不影响指数哥伦布解码的效率,本文选择CIF大小的系列进行测试,其中包括
图2 L1Dcache命中仿真图(截图)

图3 L1Pcache命中仿真图(截图)
ice,soccer,football,highway,news,flower六个 YUV 系列。经过比较计算得出表1结果。
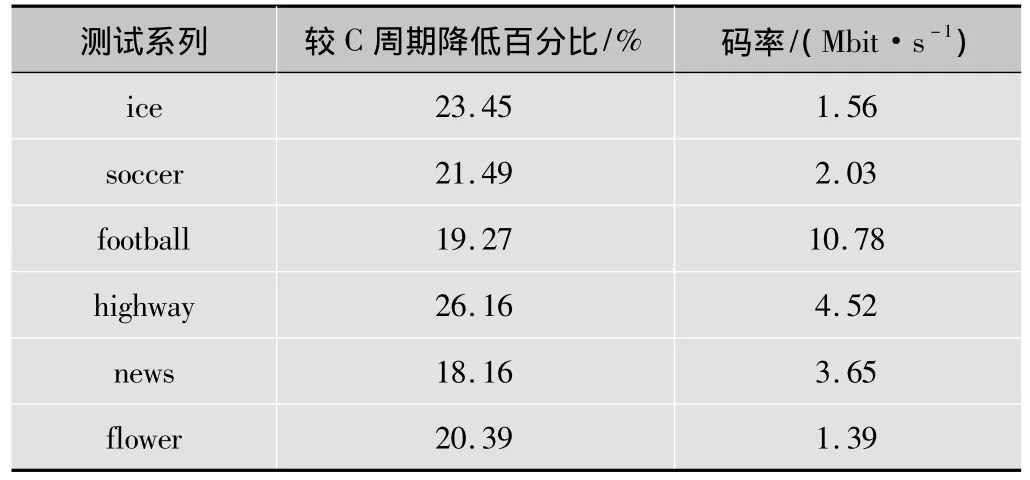
表1 不同码率序列测试结果
由表1可知,用汇编实现的熵解码程序周期较C语言平均降低约21.49%,码率也显著提高,进而提高了熵解码的解码效率。
4 结束语
本文在研究指数哥伦布码数学特性的基础上提出了一种新的指数哥伦布解码算法,又高效利用手工汇编的优化方法及提高cache命中率,最终实现了对AVS熵解码的优化。在保证正确解码的前提下进行解码效率的测试,结果表明,本文针对AVS熵解码的优化方法不仅缩短了解码周期,且显著提高了解码速度。
:
[1]宋建斌,詹舒波,马丽.基于通用DSP的视频解码器的优化实现[J].电信科学,2011,27(8):84-88.
[2]雷涛,周进,吴钦章.DSP实时图像处理软件优化方法研究[J].计算机工程,2012,38(14):177-180.
[3]刘小成,曹默.H.264解码器设计与算法优化[J].微计算机信息,2011(5):90-92.
[4]李辑,陈颖琪,王慈.基于PC的AVS视频解码器软件优化[J].电视技术,2010,34(11):40-42.
[5]魏晓君.AVS解码器环路滤波的优化及实现[J].电视技术,2013,37(5):23-25.
[6]李方慧,王飞,何佩琨.TMS320C600系列DSPs原理与应用[M].2版.北京:电子工业出版,2003.
张 刚(1953— ),博士生导师,主研音视频编解码和计算机通信等。
Implementation and Optimization of AVS Entropy Decoding on OMAP3530
SONG Na,NIU Lijun,ZHANG Gang
(College of Information Engineering,Taiyuan University of Technology,Taiyuan 030024,China)
In this paper,combining DSP hardware architecture,the implementation of Exp-Golomb code algorithm is firstly adjusted in structure.Then highly efficient pipeline arrangement is achieved on the hand assembly of entropy decoding part.Finally the cache is optimized combining the storage and access of entropy decoding data.The results demonstrate that the program operation cycle reduces by about 21.49%compared with traditional C code,and the code rate also improves significantly.
AVS;entropy decoding;OMAP3530;optimization
TN919.8
A
【本文献信息】宋娜,牛丽君,张刚.AVS熵解码在OMAP3530上的实现及优化[J].电视技术,2014,38(3).
国家自然科学基金项目(60772101)
宋 娜(1989— ),女,硕士生,主研视频解码;
牛丽君(1987— ),女,硕士生,主研视频图像编解码;
责任编辑:魏雨博
2013-05-30
猜你喜欢
少儿美术(快乐历史地理)(2020年3期)2020-07-24 09:02:26
扬子江诗刊(2018年1期)2018-11-13 12:23:04
中国自行车(2018年9期)2018-10-13 06:17:04
舰船电子对抗(2018年3期)2018-08-28 02:02:56
扬子江(2018年1期)2018-01-26 02:04:06
优雅(2017年8期)2017-08-08 06:01:53
中国自行车(2017年1期)2017-04-16 02:54:07
英美文学研究论丛(2017年2期)2017-03-01 07:33:59
小学时代(2016年31期)2016-02-24 08:00:01
中国自行车·骑行风尚(2014年6期)2015-01-06 00:58:23
