
基于动态权值的多策略领域本体概念自动抽取
2014-09-12 11:17张华楠刘胜全刘艳刘华鹏李鹏
计算机工程与应用 2014年21期
张华楠,刘胜全,刘艳,刘华鹏,李鹏
1.新疆大学信息科学与工程学院,乌鲁木齐 830046
2.新疆大学现代教育技术中心,乌鲁木齐 830046
基于动态权值的多策略领域本体概念自动抽取
张华楠1,刘胜全2,刘艳1,刘华鹏1,李鹏1
1.新疆大学信息科学与工程学院,乌鲁木齐 830046
2.新疆大学现代教育技术中心,乌鲁木齐 830046
为了提高中文领域本体概念抽取的自动化程度及准确率,提出了一种基于动态权值的多策略中文领域本体概念自动抽取方法。针对中文领域本体概念的特点,采用自动学习的规则学习模式,筛选出候选概念,将改进的DR&DC、TF-IDF和NC-Value三种策略融合,对候选概念进行领域归属度排序,将最终权重超过阈值的概念存入最终概念集合。实验证明了该方法抽取领域概念的可行性和有效性。
动态权值;本体学习;多策略;概念抽取
本体(ontology)是概念模型的明确的规范说明[1]。目前,本体已经被广泛应用于语义Web、智能信息检索、信息集成、数字图书馆等领域[2]。本体中的知识总在不断地发展和更新,这种动态性就决定了本体不能以手工方式构造,需要自动或半自动方式来构建本体。因此,本体学习(ontology learning)[3]技术应运而生,它可以实现本体的自动或半自动构建。本体概念获取是本体构建的基础问题,影响着本体后续步骤的构建和应用。
纯文本缺乏一定的结构,要使机器能够自动地理解纯文本并从中抽取出所需要的知识,则必须利用自然语言处理(NLP)技术对其预处理,然后利用统计、机器学习等手段从中获取知识。与国外相比,中文领域本体概念获取的研究工作相对较少。文献[4]提出利用Bootstrapping的机器学习技术,从大规模无标注真实语料中自动获取领域词汇。但并未对抽取的概念进行领域量化导致学习到的领域词数目偏少。文献[5]提出采用非线性函数与“成对比较法”相结合的方法,进行关键词的自动抽取。但只考虑了位置与词频两个因素,实验结果的准确率并不很高。文献[6]提出一种将统计方法与规则方法相结合的专业领域术语抽取算法。但概念的过滤算法很不完善导致结果中出现大量噪声词语。文献[7]提出一种主题概念抽取的多文档文摘方法,但该方法是以句子为单位进行抽取,并不适用于文本。文献[8]提出一种利用词语之间量化关系来提取文本主题的方法。但只考虑了词语间的量化关系,使得该方法只适合主题概念突出的领域文本。
目前,多特征融合进行概念抽取的趋势越来越明显。文献[9]采用互信息与log-likelihood相结合的策略对候选双字词汇进行左右扩充,过滤后得到领域概念。文献[10]使用子串归并、搭配检验和领域相关度计算技术来分别解决短语结构完整度判断、搭配合理性检查、领域信息量三个问题。以上方法自动化程度不高,且各策略融合时所取的权值为静态,不能真实反应概念的领域归属度。
本文尝试将改进的DR&DC、TF-IDF和NC-Value三种策略融合,提出一种基于动态权值的多策略融合中文领域本体概念自动抽取方法,旨在提高中文领域本体概念抽取的自动化程度及正确率。
1 基于动态权值的多策略融合概念抽取框架
基于动态权值的多策略融合的中文领域本体概念自动抽取的框架如图1所示,系统的输入是领域文本,输出是领域本体概念集合。领域文本经过预处理以后进行分词和词性标注。概念抽取过程中,首先使用自动学习到的规则过滤出可能成为领域概念的候选概念,而在对候选概念进行排序时,本文采用多策略融合排序算法,这种算法融合了各策略的优点且能动态分配权值,从而能更加真实地反应概念的领域归属度。最后将权重超过给定阈值的概念存入最终本体概念集合。

图1 基于动态权值的多策略融合概念自动抽取框架
2 策略分析与融合
2.1 预处理与分词
在面向文本进行概念抽取之前,首先要进行文本预处理。预处理是指对文本中的无用信息进行处理,以便减少误差。尤其对于领域中的论文和专著,需要删除其中的作者、数学公式、图片等无关信息。然后进行分词、词性标注等工作。
在本研究采用的分词工具是中国科学院计算技术研究所开发的ICTCLAS(一种基于隐马尔可夫模型的汉语词法分析系统[11])。经过分词处理之后,文本被切分成具有词性标注的中文组词及符号。
2.2 规则自动学习
在规则的学习阶段,以往的方法都是凭借经验总结领域概念的词性组合规则,但中文名词性短语的词性构成方式多种多样,无法一一列举出这些组成方式,且规则模板的精确度与灵活性不可兼得。
科技文献中关键词严谨科学,是一种半结构化的数据,因此,根据关键词的组合模式本文提出一种基于关键词的规则自动学习方法,流程如图2所示。

图2 规则自动学习流程
基于关键词的规则自动学习步骤如下:首先提取科技文献的关键词部分,然后对每组关键词进行分词及词性标注,记录其组合模式及频次,检查组合模式的合法性,最后将符合Rule的规则按其频次放入规则库中。
在规则检查阶段使用的规则如下:
Rule1:概念中不得包含如下性质的词语:标点符号、代词、语素、习用语、状态词、非语素词、处所词、拟声词、叹词、语气词和成语。
Rule2:概念不得以连词、助词和后接成分作为词首。
Rule3:概念不得以连词、方位词和前接成分性质的词语结尾。
Rule4:概念中至少有一个词属于名词、动词、量词、习用语、简称略语或后接成分。
同时满足这四条规则的概念在候选概念集合中占到了96.33%[10]。系统使用上述规则进行规则的自动评价,符合规则且在系统规则库中未出现的规则加入到规则库中。在后继步骤中,使用规则库中的规则来抽取候选概念。
2.3 多策略融合排序
候选排序方法涉及到两个问题:策略的选择和策略的加权算法。
本文采用改进的DR&DC、TF-IDF和NC-Value三种策略融合进行候选概念的领域归属度排序。
2.3.1 改进的DR&DC
传统的DR&DC[12]只考虑了词频、领域文本与参照文本数量这两个特征,因此其结果受普通文本集质量的影响很大,从而影响了该方法的实际可行性。本文借鉴并改进DR&DC,采用领域相关性和领域一致性对候选概念进行领域归属度计算。
本文综合考虑如下几点:(1)复合短语的长度,越长的概念表示的语义信息越丰富,越有可能成为领域概念;(2)领域文本的数量与参照文本的数量;(3)词的位置信息,不同位置的短语反映了该词在领域中的相对重要性。
改进后的领域相关性DR定义如下:
定义1
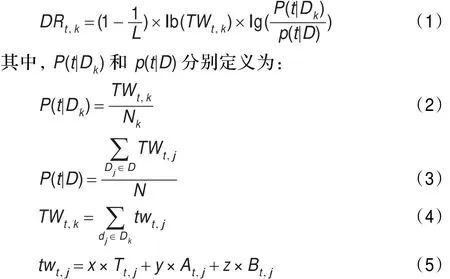
其中,dj指领域Dk中的第j个文本;twt,j是复合短语t在文本j中的词重;Nk是领域Dk中的文本数量;N是所有文本的数量;L是复合短语t的长度,即中文词语数与英文单词数之和,Tt,j是复合短语t在文本j题目中出现的次数,At,j是复合短语t在文本摘要中出现的次数,Bt,j是复合短语t在文本j正文中出现的次数,x,y,z分别为概念出现在标题、摘要、正文的权重。
领域一致性是指概念在特定领域的分布程度,也就是说对于领域相关度相同的语义串,在领域文本中分布越均匀的概念越有可能是领域的概念。领域一致性DC的定义如下:

其中,ft,j是指词t在领域Dk中的文本dj中的频率。此公式可解释为若某复合短语在领域文本中均匀分布,那么相对于在单个文本中出现多次的复合短语,前者更可能是领域的概念。
复合短语的权重TW可以表达为:

改进后的DR&DC额外考虑了概念长度、领域文本域参照文本的数量比、概念位置信息等影响概念领域归属度的因素,因此能得到更加准确的权值,切实反应概念的领域归属度。
2.3.2 TF-IDF
TF统计候选概念在文档中出现的频率;IDF计算候选概念在领域的聚合程度;但传统的TF-IDF[13]只能计算概念在单一文本内的权重,本文对其进行了改进,使其适应大语料场景,改进后的公式如下:

某一特定文件内的高词语频率,以及该概念在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
2.3.3 NC-Value
NC-Value是Frantzi[14]提出的,通过当前词在较长候选概念中的出现频率来确定。NC-Value参数将概念的上下文信息作为重要的特征引入到了考虑范围,避免了只抽取到长概念中的前部分就按照规则停止的情况。
其定义如下:

其中C-Value(a)表示概念a的C-Value值,fa(b)表示a的上下文b的词频,weight(w)表示a的上下文b的权重。
2.3.4 多策略融合算法
改进的DR&DC考虑了概念长度、概念位置、领域文本与参照文本的数量等特征;TF-IDF考虑单篇文档中的概念频率以及在文档集合中概念的分布特征;NC-Value不仅考察了词汇的频率,还引入了具有包含关系的词串的频率对比,同时考虑了上下文信息以及概念内部的结合强度。由于各方法所采用的特征类型重叠不多,将三种方法进行融合能够覆盖中文概念抽取领域考虑的大多数特征类型[15],避免了只由个别特征类型决定最终排序情况的发生。融合三种方法,发挥各个方法的优势,根据方法特性动态赋予相应的权值,使结果更能真实地体现概念的领域归属度。综合考虑影响抽取结果的所有特征类型,旨在提高概念抽取的准确率。
基于动态权值的多策略融合的概念筛选模型如图3所示。

图3 基于动态权值的多策略加权融合模型
改进的DR&DC、TF-IDF、NC-Value分别计算某个概念的权重,然后根据方法本身考虑的特征综合决定各策略的权值,各方法加权后得到概念的最终权重。基于动态权值的多策略加权融合模型可以动态设置各策略的权值,模型包含了静态权值的策略融合,如将某两种策略的权值设为零则表示余下一种策略的单一结果。
概念t的最终权重W(t)定义如下:
定义5

其中wk(t)是概念在某一策略的初级权重,wk是各策略的权值,其定义如下:


最终权重W(t)超过阈值θ的候选概念存入最终概念集合。
3 实验结果与分析
规则自动学习所用的语料是计算机领域的267篇科技文献,共自动学习到了89条规则,其中长度3以下的64条,长度4~6的25条。其中排名前十的规则如表1所示。
为了验证本文所提出方法的准确性,选取了100篇计算机网络的相关语料,同时用172篇政治、人文等领域的语料作为参考文本。实验用Java语言编程,经过多次实验同时参考文献[5]、文献[12],最终设定的参数如表2所示。

表1 词法构成模式

表2 参数设定
表3是自动抽取到的前15个概念及最终权重。

表3 概念与最终权重
从表3中可以看出,计算机网络领域的重要概念都被正确抽取出来了。
为了比较,人工抽取了领域文本的224个概念,表4是动态权值多策略融合方法在设定不同权值时的抽取结果比对。

表4 各方法比较
其中前三种方法分别是其他两种策略权值为零时的结果,第四种方法则表示静态权值(各策略均赋予1/3)的结果,第五种为本文的动态权值多策略抽取结果,从实验结果可以看出,无论是在准确率还是召回率方面,本文所提出的多策略融合方法均比其他方法有所提高。某些概念(如“电路”)在各策略初级权重排在较前的位置,但策略融合后的最终权重的排名却后退了,更加符合现实情况,这验证了基于动态权值的多策略融合抽取方法的合理性。动态权值的多策略融合抽取方法能将发挥各策略的优势,使结果更加真实地体现概念实际的领域归属度,但相应地会增加抽取模型的复杂度。
分析可知,本文方法在概念抽取的准确率和召回率提高的原因是采用了自动的规则学习,由此能得到尽可能多的候选概念,而后把多特征进行综合考虑,进行动态权值的多策略融合,筛选出能够真实代表领域的领域概念。因此该方法对中文领域本体概念的自动抽取有一定的积极意义。
4 结束语
本文在前人工作的基础上进行了扩展和改进,尝试将改进的DR&DC、TF-IDF和NC-Value三种策略融合,提出了一种基于动态权值的多策略融合的领域本体概念自动抽取方法,实验证明该方法对领域概念抽取的准确率有一定的提高,亦提高了概念抽取的自动化程度。下一步的工作是用更大的语料进行规则的自动学习,提高规则库的完整度及准确性,并在此基础上扩展抽取模型,提高模型的包含度,后期进行领域本体概念关系的抽取,以探索自动构建本体的新方法。
[1]Guber T R.A translation approach to portable ontology specifications,Technical Report,KSL 92-71[R].Knowledge System Laboratory,1993.
[2]Deng Z H,Tang S W,Zhang M,et al.Overview of ontology[J]. Acta Scientiarum Naturalium Universitatis Pekinensis,2002, 38(5):730-738.
[3]杜小勇,李曼,王珊.本体学习研究综述[J].软件学报,2006,17(9):1837-1847.
[4]Chen W L,Zhu J B,Yao T S.Automatic learning field words by bootstrapping[C]//Proc of the JSCL.Beijing:Tsinghua University Press,2003:67-72.
[5]Zheng J H,Lu J L.Study of an improved keywords distillation method[J].Computer Engineering,2005,31(18):194-196.
[6]Du B,Tian H F,Wang L,et al.Design of domain-specific term extractor based on multi-strategy[J].Computer Engineering,2005,31(14):159-160.
[7]宋宜辰,刘贵全.基于主题概念抽取的多文档文摘方法[J].计算机工程,2010,36(4):190-192.
[8]蒋建惠,陈玉泉.基于词语量化关系的主题概念抽取算法研究[J].计算机仿真,2009,26(12):122-125.
[9]田怀凤.基于多策略的专业术语抽取处理技术的研究[J].计算机与现代化,2008(12):94-96.
[10]周浪,史树敏,冯冲黄,等.基于多策略融合的中文术语抽取方法[J].情报学报,2010,29(3):460-467.
[11]Qun L,Hua Ping Z,Hong-Kui Y,et a1.Chinese lexical analysis using cascaded hidden Mazkov model[J].Computer Research and Development,2004,41(8):1421-1429.
[12]Navigli R,Velardi P.Learning domain ontologies from document warehouse and dedicated web sites[J].Computational Linguistics,2004,30(2):151-179.
[13]Salton G,McGill M J.Introduction to modern information retrieval[M].[S.l.]:McGraw-Hill,1983.
[14]Frantzi K,Anaiadou S,Mima H.Automatic recognition of multi-word terms:the C-value/NC-value method[J]. International Journal on Digital Libraries,2000,3.
[15]游宏梁,张巍沈,钧毅,等.一种基于加权投票的术语自动识别方法[J].中文信息学报,2011,25(3):9-16.
ZHANG Huanan1,LIU Shengquan2,LIU Yan1,LIU Huapeng1,LI Peng1
1.School of Information Science and Engineering,Xinjiang University,Urumqi 830046,China
2.Modern Educational Technology Center,Xinjiang University,Urumqi 830046,China
To improve the automation degree and accuracy of Chinese domain ontology concept extraction,a method of concepts automatic extraction based on dynamic weighted multi-strategy integration is proposed.This paper filters out the candidate concepts according to the rule templates using automatic learning;and then improved DR&DC,TF-IDF and NC-Value are integrated;it sequences the degree of domain membership of the candidate concept sets,and puts concepts whose weight exceeds the threshold value into final concept sets.After lots of experiments,the feasibility and validity of this method are proved.
dynamic weight;ontology learning;multi-strategy;concept extraction
A
TP182
10.3778/j.issn.1002-8331.1212-0040
ZHANG Huanan,LIU Shengquan,LIU Yan,et al.Automatic extraction method of domain ontology concepts based on dynamic weight multi-strategy.Computer Engineering and Applications,2014,50(21):152-156.
新疆维吾尔自治区科技攻关项目(No.200931103);新疆大学自然科学基金(No.XY110121)。
张华楠(1986—),男,硕士研究生,研究方向:本体学习;刘胜全,教授,硕士生导师,研究方向:网络应用、语义Web;刘艳,讲师,研究方向:电子商务;刘华鹏,硕士研究生,研究方向:语义Web;李鹏,硕士研究生,研究方向:本体构建。E-mail:zhangchris@163.com
2012-12-04
2013-02-06
1002-8331(2014)21-0152-05
CNKI出版日期:2013-03-13,http://www.cnki.net/kcms/detail/11.2127.TP.20130313.0950.013.html
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
Coco薇(2017年11期)2018-01-03
自动化学报(2017年7期)2017-04-18
制造业自动化(2017年2期)2017-03-20
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
现代电子技术(2016年15期)2016-12-01
文学教育(2016年27期)2016-02-28
