
面向众核GPU加速系统的网络编码并行化及优化
2014-09-12 11:17唐绍华
计算机工程与应用 2014年21期
唐绍华
湖南工程职业技术学院信息工程系,长沙 410151
◎网络、通信、安全◎
面向众核GPU加速系统的网络编码并行化及优化
唐绍华
湖南工程职业技术学院信息工程系,长沙 410151
网络编码允许网络节点在数据存储转发的基础上参与数据处理,已成为提高网络吞吐量、均衡网络负载和提高网络带宽利用率的有效方法,但是网络编码的计算复杂性严重影响了系统性能。基于众核GPU加速的系统可以充分利用众核GPU强大的计算能力和有效利用GPU的存储层次结构来优化加速网络编码。基于CUDA架构提出了以片段并行的技术来加速网络编码和基于纹理Cache的并行解码方法。利用提出的方法实现了线性随机编码,同时结合体系结构对其进行优化。实验结果显示,基于众核GPU的网络编码并行化技术是行之有效的,系统性能提升显著。
网络编码;图形处理器(GPU);并行;计算统一设备架构(CUDA);优化
1 引言
网络编码在提高网络吞吐量、改善负载均衡、减小传输延迟、节省节点能耗、增强网络鲁棒性等方面均显示出其优越性[1]。因此,网络编码一经提出便引起了国际学术界的广泛关注,其理论和应用已广泛应用于分布式文件存储[2]、P2P系统[3-4]、无线网络[5]。然而,现实网络环境的非确定性[6]、网络编码的计算复杂性[7]等因素严重影响了系统整体性能,使得网络编码技术的实用性不强。因此,网络编码优化成为推动网络编码技术更具实用性的重要手段[8-9],其中,优化网络编码的计算通信开销更是研究的热点,包括网络编码算法的构造设计以及基于硬件的网络编码加速[7,10-12]。
虽然研究者在利用GPU加速网络编码方面进行了较为深入的研究,也取得了可喜的成绩。但是,他们的工作都倾向于最大化GPU计算资源的利用率,GPU计算资源耗费不少,然而并行网络编码系统的效率并不高;同时,对结合GPU体系结构和存储层次而展开的优化工作也尚有不足。本文的工作将致力于结合众核GPU体系结构设计高效的并行网络编码算法和面向GPU存储层次对并行网络编码进行优化。

图1 CUDA执行模型
2 众核GPU体系结构及CUDA编程模型
CUDA(Computing Unified Device Architecture,CUDA)是NVidia为适应GPU通用计算而推出的一种高性能GPU体系架构,支持CUDA的GPU是一块具有可扩展处理器数量的处理器阵列,与传统GPU最大的区别在于,它拥有片内共享存储空间用以减小片外访存延迟[13]。CUDA执行模型以CUDA硬件架构为基础,如图1所示。
CUDA源程序由运行于host(CPU)上的控制程序和运行于device(GPU)上的计算核心(kernel)两部分组成。每一个kernel由一组相同大小的线程块(thread block)来并行执行,同一线程块里面的线程通过共享存储空间来协作完成计算,线程块之间是相互独立的。运行时,每一个线程块会被分派到一个流多处理器(Streaming Multi-processor,SM)上运行,一个SM包括8个线程处理器(Threaded Processor,TP)和一段大小为16 KB的共享存储空间(Shared Memory),另外,GPU还提供了一定数量的全局的只读的纹理Cache和常量Cache[14]。
3 基于CUDA架构的并行网络编码
网络编码的本质是赋予节点计算能力以提高链路带宽的利用率。图2(b)阐述了网络编码的基本原理,图中s是信源,x和y是信宿,假设各边的带宽均为1 bit/s,现要将2比特数据a和b同时从s传到x和y。s与x和y之间均分别存在两条独立路径,若采用传统路由方法,如图2(a)所示,由于存在共有链路wz,a和b不能同时在wz上传输;若采用网络编码方法,在节点w上对a和b执行异或操作并转发,则节点x可以通过a⊕b⊕a计算解码得到b,同理y也可以解码得到a,从而提高了带宽利用率。

图2 路由分发与网络编码比较
网络编码按照节点输出和输入的关系可划分为线性网络编码和非线性网络编码,根据编码系数生成的随机性可划分为随机网络编码和确定网络编码[1],实用的网络编码系统大多采用随机线性编码[2-3,6-7,9-12]。然而,随机网络编码计算复杂度较高,严重影响了编码系统的性能,为此,本文基于众核GPU加速的系统设计并实现了并行的随机网络编码算法,并且有效利用GPU存储层次对其进行优化,使得随机网络编码系统的性能有了显著性的提升。
3.1 随机线性编码
所谓线性网络编码就是将节点传送信息线性映射到一个有限域内,利用线性关系实现编译码的过程[9]。通信网络G(V,E)中,信源s∈V的输入数据b被分割为n个数据片段b1b2…bn,每个片段含有k个字节。一个网络节点可以在有限域内独立地选择一组随机编码系数c1c2…cn,生成一个k字节的编码片段X,即

由于每个编码片段X是原始数据片段的一个线形组合,因此编码片段可以由线形组合中的参数集唯一确定。当一个节点接收到n个线性无关的编码片段[X1,X2,…,Xn]T,就可以进行解码。
根据每个原始片段的系数构造一个n×n的系数矩阵C,C的每一行对应于一个编码片段的系数,然后利用C解码得出原始片段。

在方程(2)中,可以利用高斯消元法计算矩阵C的逆,再与X相乘,其复杂度为ο(n2·k)。其中,当C是行线性无关时,C的逆存在。
3.2 片段编码并行化
正如文献[7,10-12]中归纳的:线性编码的主要性能瓶颈集中于有限域上的乘法操作和循环计算每个片段中n×k个字节的乘加操作。因此,优化加速有限域上的乘法、循环乘加操作对提高网络编码的性能至关重要。文献[7,10-12]都采用将有限域上的乘法操作转换为基于对数和指数的并行查表,即

将有限域上的对数和指数预先计算好存储起来,将有限域上的一次乘法操作转换为三次查表和一次加法操作。
在计算受限的系统中,上述过程将昂贵的乘法操作转换为相对廉价的查表和加法操作,对系统的性能有一定的提升。但是,在存储受限的GPU结构中,访存查表很可能比乘法计算的延迟更大,并且,将有限域上的对数表和指数表缓存起来对共享存储空间的压力太大并且访存冲突、复用率等因素也值得考虑;即使在计算受限的结构中,可以更加激进地将有限域上的一次乘法操作转换为一次查表完成。
支持CUDA的GPU虽然拥有一定的片内共享存储空间用以减小片外访存延迟,但是共享存储空间受限只有16 KB,并且显式地分派管理数据极易引起访存冲突。但是,支持CUDA的GPU拥有数以百计的计算核,计算比访存更有优势。因此,基于片段的并行编码将采用启动数以千记的线程同时编码的方法来分摊昂贵的乘法开销。
在支持CUDA架构的GPU上,最直接的并行算法就是将每一个数据片段都交付给一个独立的线程去处理,这样只要数据片段足够多,就可以启动大量的线程来同时执行,因此,可以将片段划分得足够小,以获得启动更多的线程。片段的大小为1 bit不合适,数据片段没有实际意义;数据通常以字节为单位,那么以字节为单位似乎更合理。但是片段太小只会浪费计算资源,更重要的是会增加线程之间的通讯开销。由于现有的支持CUDA的GPU计算核的字长为32位,因此,选择片段的大小为2个字节,不够的可以在末尾补0,这样两个大小为2个字节的数据相乘,其结果在有效范围内,并且数据精确度高。
设输入数据b被可以分割为n个大小为2个字节数据片段b1b2…bn,将每一个片段都分派给一个线程来处理,则所需要的线程数目为:

若设置每个线程块包含512个线程,则所需要的线程块的数目为:

并行编码的流组织过程如图3所示。图3中演示了一个线程块中512个线程并行加载数据和进行数据编码的过程。在CUDA架构中同一个线程块内的线程在编译调度时会被分派到同一个流多处理器上,因此它们共享一个大小为16 KB的共享存储空间(Shared Memory)。在并行编码中使用共享存储空间加载原始数据片段,处理完后直接存放在共享存储空间,通过有效使用共享存储空间可以减少数据的存取访问时间。
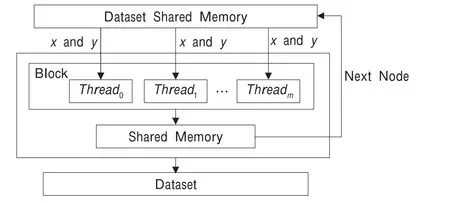
图3 并行编码
3.3 主机协作并行解码
正如文献[7]中归纳的:解码过程与编码相比具有更高的计算复杂度,最为关键的是解码过程内在的并行性更少,后面节点的解码依赖于前面节点的解码结果,因此节点之间还必须同步。文献[10]提出了一种渐进式的高斯-约当消元法来提高解码效率;Shojania等人在文献[7,11]中也是采用高斯-约当消元法来解码,不同的是,他们建议将GPU与CPU协作起来进行解码。基本方法是:由CPU生成随机系数,在GPU上计算矩阵的逆并解码。

表1 支持CUDA的GPU存储结构
CPU与GPU协作进行解码是一个明智的选择,但是,CPU还可以承担系数矩阵求逆的任务,然后将C-1传递给显存,因为矩阵求逆和GPU计算kernel可以异步执行,即,CPU将编码kernel启动后可以执行主机上的矩阵求逆,等待编码结束后可以在最短时间内将CPU计算的逆矩阵传递给显存。考虑到C-1的复用性高,还可以进一步将其缓存起来,在支持CUDA的GPU中,纹理Cache专门为二维空间位置而优化过并且C-1无需更新,所以将C-1直接绑定缓存至纹理存储空间。
考虑到网络解码过程内在并行性的特点,并行网络解码将参考文献[13]中tiled模式的矩阵乘法来解码。
4 面向体系结构的并行编码优化
面向GPU结构的编程需要显式管理分派数据,因此结合GPU体系结构,尤其是有效利用GPU的存储层次进行优化对整个系统的性能提升尤为重要,因此,下面将面向GPU的体系结构对并行网络编码系统进行优化。
4.1 有效利用GPU存储层次
CUDA线程可在执行过程中访问多个存储器空间的数据,如表1所示。
共享存储空间(Shared Memory)的有效使用是CUDA应用优化最常用、最容易想到的存储优化技术,这是因为共享存储器位于流多处理器片上,并且它为一个线程块内的线程共享,为同一线程块内的线程之间的通信提供了便利,同时,与全局存储器相比,其速度要快得多。但是,共享存储器的存储空间大小有限,并且对数据的分派管理不当,会引起存储体冲突,这时访存就必须序列化,降低了有效带宽。因此,并行编译码时,谨慎使用共享存储器很有必要。
并行编码过程中,使用共享存储空间存放中间数据结果,为后面的数据处理做准备,可以避免数据在全局存储空间来回传递,有效减少了访存延迟,并且简化了中间流的管理;并行解码过程中,可以将系数矩阵的逆复制给每一个流多处理的共享存储器,可以避免同一个线程块里面的线程重复访问全局存储器。考虑到共享存储器的空间受限并且作用广泛,解码过程将求助于其他优化方法。
4.2 基于设备运行时组件加速乘法操作
如前面所述,文献[7,10-12]都采用将有限域上的乘法操作转换为基于对数和指数的并行查表来避免乘法操作,本文通过大量线程并行来分摊乘法操作的开销。同时,CUDA运行时库支持的设备运行时组件中包括了几乎所有的数学标准库函数[11]。这些设备运行时组件会被映射到GPU上的一条指令或一个指令系列,这些设备组件内部的数学函数是标准库函数精确度较低但速度更快的版本,但是,加法和乘法是符合IEEE规范的[11],因此精度与标准库函数相同。
因此,设备运行组件支持的数学函数__fmul_(x,y)和__fadd_(x,y)将尝试应用于网络编码计算中以进一步改善系统性能。
4.3 基于纹理Cache并行解码
纹理Cache其实就是全局存储器的一个特定区域。但是,纹理Cache空间是被缓存的,因此纹理获取仅需在缓存内容失效时才读取一次全局存储器,否则只需读取纹理缓存即可。同时,纹理缓存已为二维空间位置而优化过,通过只读的纹理Cache也可以缓存无需更新的系数矩阵的逆,并且纹理Cache专门为二维空间位置而优化过[11],有利于存储二维的数据结构。因此,并行解码过程中,将主机计算好的系数矩阵的逆存储在纹理Cache中,可以充分利用纹理Cache的优势,加快各个线程对系数矩阵逆的访问,基于纹理Cache的并行解码过程如图4所示。

图4 基于纹理Cache并行解码
5 实验评估与性能分析
为了验证基于GPU架构的并行网络编码系统的有效性和高效性,在Nvidia GTX280实验平台上模拟了网络编码过程,其中GTX280的主要参数如表2所示。测试的原数据大小包括16 KB、32 KB、64 KB和128 KB;评估了并行编码速度和基于纹理Cache解码带宽两个主要的性能指标。

表2 Nvidia GTX280的相关配置
5.1 基于纹理Cache并行解码
图5显示了编码片段大小对编码运行速度的影响,由图5可以发现,片段越小(1 Byte),虽然可开发的并行性越多,但是编码速度却远低于期望值;编码片段大小选择为2个Byte,虽然可开发的并行性似乎减少了,但是性能却表现较好;编码片段大小选择为4个Byte时所表现出来的性能与选择为2个Byte时差别不大,同时,由于受到GPU计算核字长的限制,片段大小超过2个Byte后,计算的精确度就很难保证了。由图5可以得出,片段并不是越大越好,也不是越小越好,这是因为,并行粒度的大小与计算资源的利用率以及线程间的通信息息相关,只要充分利用计算资源就好,并不是所有计算资源都忙起来就好,当然也不能让它们处于空闲。因此,实验数据也说明选择片段大小为2个Byte是正确的、高效的。

图5 片段大小对编码时间的影响
5.2 基于片段的并行编码速度
为了验证基于片段的并行网络编码的高效性,标识文献[7,10-12]采用将有限域上的乘法操作转换为基于对数和指数的并行查表的技术进行编码的方法为TB(Table-Based);标识本文提出的基于片段并行编码的方法为Frag;Frag方法是一个原生的并行技术,并没有对其结合GPU结构进行优化;因此,标识经过优化的片段并行方法为Frag+Opt,这些优化方法主要包括面向GPU体系结构的一些优化技术,主要包括:基于设备运行时组件加速乘法操作和有效利用共享存储空间优化线程间通信和简化中间流管理。
图6和表3显示了基于片段的并行编码及其优化技术对编码性能提升的影响,基于片段的并行编码与基于查表的编码方法相比较,性能提升显著,但是面向GPU体系结构的优化对编码速度的提升并不是很明显,这是因为并行编码的性能瓶颈不在于乘法操作到底是多少个周期内完成,同时,由于选择的片段大小为2 Byte,其乘法操作符合GPU字长的要求,因此不需要分割数据进行循环乘加运算,也减少了进程间通信的机会。因此,面向GPU结构的优化在此对性能的提升不明显,但是这些优化方法可以推广至其他GPU应用中。

图6 编码速度比较图

表3 编码速度比较表
5.3 基于纹理Cache的并行解码带宽
图7和表4显示了纹理Cache对并行解码性能的提升是显著的。在不引入纹理Cache进行缓存优化的情况下,在平台Nvidia GTX280下,每个线程块运行512个线程时,其带宽利用率与Shojania等人在文献[11]中的相同配置下的表现相当;引入纹理Cache对系数矩阵的逆进行缓存优化后性能攀升显著。性能提升的另外一个重要原因就是本文将随机系数生成、矩阵求逆等任务都交给了主机,也减少了GPU的处理时间,主机协作对带宽利用率的提升贡献也不少。而Shojania等人在文献[11]中只是将部分任务交给了主机。因此,纹理Cache缓存以及主机协作计算等都是并行解码过程中带宽利用率提升的重要原因。
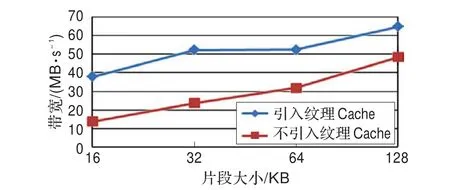
图7 解码带宽比较图

表4 解码带宽比较表
5.4 系统性能分析
分析图6和图7的实验数据可以发现,Frag方法与TB方法比较,编码的速度提升了2倍之多;基于纹理Cache的并行解码的带宽利用率也提升了近2倍。虽然这个加速比不是很高,但是它比较的对象是网络编码在GPU上优化后的实现版本,并不是与单核或多核CPU比较的结果,因此这个性能加速比还是可以接受的。
但是,从图6还可以发现Frag+Opt方法与Frag方法比较,性能提升不明显,这与设计的初衷是不统一的。为了充分发挥Shared Memory的效用,减轻Shared Memory的压力而求助纹理Cache优化并行解码,但是Shared Memory最后发挥的效用甚微,因此,Shared Memory可以尝试用来缓存系数矩阵,因为访问Shared Memory比访问纹理Cache更有优势。当然,基于纹理Cache缓存系数矩阵也有自己的优势,它的空间比较大,可以缓存较大量的数据集,这是Shared Memory所不能比的。
同时,比较表2和图6还可以发现,即使是基于纹理Cache优化后的带宽利用率也是很低的,当然,这个带宽利用率不能仅仅只与GPU内部的最大的可用带宽比较,因为它还受限从CPU到GPU的数据传输速率。但是,比较表2和图6至少可以说明基于GPU的并行网络编码系统的性能瓶颈在于存储带宽。如何进一步提高GPU存储带宽的利用率将会成为研究的难点。
总之,基于众核GPU加速应用必须深入理解GPU的体系结构及存储层次,权衡技术的利弊及相互影响,最大限度开发利用GPU的资源。
6 结束语
网络编码一经提出便引起了工业界和学术界的广泛关注和认同,但是现实中网络编码的应用还远未普及,在很大程度上是因为网络编码引入的计算开销。基于众核GPU加速的系统来优化加速网络编码可以有效缓解上述难题,但是,GPU结构是一种新涌现的高性能体系结构,如何更好地利用其强大的计算资源和可用的存储带宽、GPU与主机之间的通讯协作、GPU应用的自动优化技术等亟需更深入的研究。
[1]杨林,郑刚,胡晓惠,等.网络编码的研究进展[J].计算机研究与发展,2008,45(3):400-407.
[2]Dimakis A G,Godfrey P B,Wainwright M,et al.Network coding for distributed storage systems[C]//Proceedings of the 26th Annual IEEE Conference on Computer Communications(INFOCOM 2007),Anchorage,USA,2007:2000-2008.
[3]Jafarisiavoshani M,Fragouli C,Diggavi S.Bottleneck discovery and overlay management in network coded Peerto-Peer systems[C]//Proceedings of the SIGCOMM Workshop on Internet Network Management,Kyoto,Japan,2007:293-298.
[4]Gkantsidis C,Miller J,Rodriguez P.Comprehensive view of a live network coding P2P system[C]//Proceedings of the 6th ACM SIGCOMM on Internet Measurement,New York,NY,2006:177-188.
[5]汪洋,林闯,李泉,等.基于非合作博弈的无线网络路由机制研究[J].计算机学报,2009,32(1):54-68.
[6]Chou P.Practical network coding[C]//Proceedings of the Allerton Conference on Communication,Control,and Computing,Monticello,IL,2003:63-68.
[7]Shojania H,Li Baochun.Pushing the envelope:extreme network coding on the GPU[C]//Proceedings of the 29th IEEE International Conference on Distributed Computing Systems,Montreal,QC,2009.
[8]黄政,王新,Huang Z.网络编码中的优化问题研究[J].软件学报,2009,20(5):1349-1360.
[9]Ho T,Medard M,Koetter R,et al.A random linear network coding approach to multicast[J].IEEE Transactions on Information Theory,2006,52(10):4413-4430.
[10]Shojania H,Li Baochun.Parallelized network coding with hardware acceleration[C]//Proceedings of the 15th IEEE International Workshop on Quality of Service,Chicago,IL:2007:1-9.
[11]Shojania H,Li Baochun,Xin W.Nuclei:GPU-accelerated many-core network coding[C]//Proceedings of the INFOCOM,Rio de Janeiro,Brazil,2009:459-467.
[12]Chu X W,Zhao K Y,Wang M.Massively parallel network coding on GPUs[C]//Proceedings of the IEEE Performance,Computing and Communications Conference,Austin,Texas,2008:144-151.
[13]NVIDIA.CUDA programming guide 2.0[S].NVIDIA Corporation,2008.
[14]甘新标,沈立,王志英.基于CUDA的并行全搜索运动估计算法[J].计算机辅助设计与图形学学报,2010,22(3):457-460.
TANG Shaohua
Department of Information Engineering,Hunan Engineering Polytechnic,Changsha 410151,China
It is well known that network coding has emerged as a promising technique to improve network throughput, balance network loads as well as better utilization of the available bandwidth of networks,in which intermediate nodes are allowed to perform processing operations on the incoming packets other than forwarding packets.But,its potential for practical use has remained to be a challenge,due to its high computational complexity which also severely damages its performance.However,system accelerated by many-core GPU can advance network coding with powerful computing capacity and optimized memory hierarchy from GPU.A fragment-based parallel coding and texture-based parallel decoding are proposed on CUDA-enable GPU.Moreover,random linear coding is parallelizing using CUDA with optimization based on proposed techniques.Experimental results demonstrate a remarkable performance improvement,and prove that it is extraordinarily effective to parallelize network coding on many-core GPU-accelerated system.
network coding;Graphic Processing Unit(GPU);parallelizing;Compute Unified Device Architecture(CUDA); optimization
A
TP338.6
10.3778/j.issn.1002-8331.1403-0071
TANG Shaohua.Parallelizing network coding on manycore GPU-accelerated system with optimization.Computer Engineering and Applications,2014,50(21):79-84.
国家高技术研究发展计划(863)(No.2012AA010905);国家自然科学基金(No.60803041,No.61070037);湖南省教育厅2012年度科技项目(No.12C1024)。
唐绍华(1980—),男,讲师,工程师,研究领域为信息安全,计算机网络,高性能计算。E-mail:tsh1181@163.com
2014-03-10
2014-04-28
1002-8331(2014)21-0079-06
CNKI出版日期:2014-07-11,http://www.cnki.net/kcms/doi/10.3778/j.issn.1002-8331.1403-0071.html
猜你喜欢
中国石油石化(2022年12期)2022-07-16
智能计算机与应用(2021年6期)2021-12-17
综艺报(2020年21期)2020-11-30
网络安全技术与应用(2020年1期)2020-01-07
中国外汇(2019年19期)2019-11-26
电脑爱好者(2019年17期)2019-10-30
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
环球市场(2017年36期)2017-03-09
计算机与网络(2014年6期)2014-05-25
