
基于程序执行轨迹与动态切片的错误定位研究
2014-09-11 09:10:27孙士明侯秀萍孙琳琳长春工业大学计算机科学与工程学院长春300苏州大学附属第一医院江苏苏州5006
吉林大学学报(信息科学版) 2014年5期
孙士明, 侯秀萍, 高 灿, 孙琳琳(. 长春工业大学 计算机科学与工程学院, 长春 300; . 苏州大学 附属第一医院, 江苏 苏州 5006)
基于程序执行轨迹与动态切片的错误定位研究
孙士明1, 侯秀萍1, 高 灿2, 孙琳琳1
(1. 长春工业大学 计算机科学与工程学院, 长春 130012; 2. 苏州大学 附属第一医院, 江苏 苏州 215006)
为解决程序调试过程中的错误定位问题, 将程序执行轨迹和动态切片技术应用于错误定位。程序执行轨迹中包含与错误无关语句, 影响错误定位的准确度。在执行轨迹的基础上, 通过使用动态切片技术降低不相关语句在错误定位时的影响。建立基于程序执行轨迹和动态切片的语句怀疑度计算模型, 使用该模型计算每条语句的怀疑度, 并根据怀疑度对每条语句进行排序, 给出查错的推荐方案。通过实验对比其他算法, 证明了基于程序执行轨迹与动态切片的错误定位方法是有效的。
执行轨迹; 动态切片; 怀疑度
0 引 言
软件生命周期中的任何一个阶段的程序调试都需要程序员进行大量的人机交互[1]。为保证软件开发的质量, 工业界在软件测试阶段投入了大量的人力物力。据统计, 软件测试约占软件开发和维护成本的50%~75%[2], 其中最耗时、 代价最昂贵的任务之一就是程序调试[3-6], 这是指对程序错误进行定位和修正的过程, 而错误定位又是程序调试中最耗时和困难的任务。
在程序的调试过程中, 程序员准确识别导致程序出错的位置称为错误定位[7]。错误定位的有效性取决于程序员对程序的理解程度, 以及逻辑判断能力和调试经验。错误定位研究可以分为两部分[8]: 使用某种技术识别可能含有错误的代码和程序员通过检查识别含有错误的代码。笔者研究的是识别可能含有错误的代码。
1 错误定位方案
在错误定位研究过程中, 有很多种方法可以定位错误。常见的方法是对源程序进行相应的程序理解或动态跟踪出现错误的测试用例的执行轨迹并获取错误信息, 利用人工智能的方法或统计的方法计算每条语句的怀疑度[9], 然后定位错误可能发生的位置。笔者根据程序的执行轨迹和动态切片信息进行错误定位。由于面向对象程序具有抽象、 封装、 继承和多态的特性, 对于部分具有多态特性的程序, 动态切片获取工具不能获取准确的切片[10], 如果只使用动态切片技术进行错误定位, 这将导致动态切片中可能不会包含错误语句, 使错误定位的精度降低。含有错误的语句一定会在执行轨迹中, 但执行轨迹中包含大量与错误发生无关语句, 利用动态切片技术降低执行轨迹中无关语句的影响, 又不会遗漏执行轨迹中的错误语句。笔者进行错误定位的流程如图1所示。
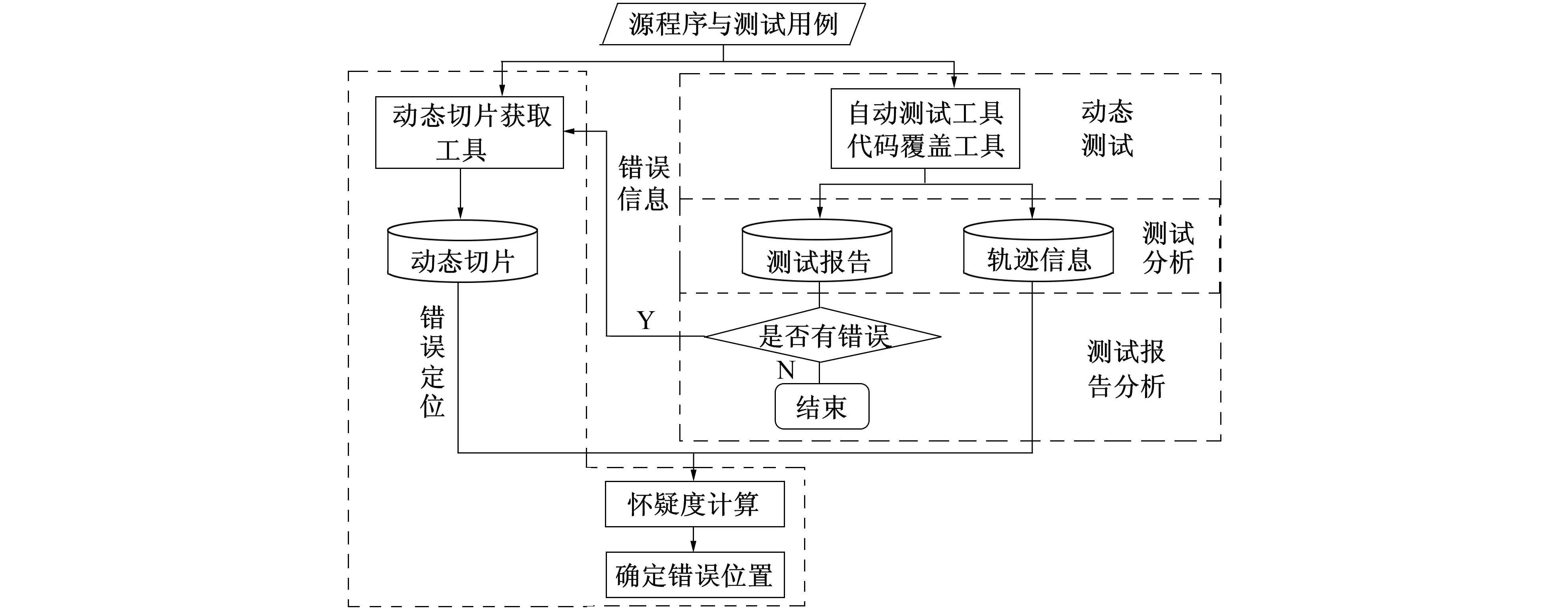
图1 错误定位流程图Fig.1 Flow chart of fault localization
首先运行测试用例, 在运行测试用例时记录程序的执行轨迹和生成测试报告。分析测试报告内容, 报告中是否含有运行失败的测试用例, 如果没有, 则测试结束; 如果有, 将错误信息和参数信息传递给动态切片获取程序, 计算每个参数信息对应的动态切片。最后利用怀疑度计算模型估计每条语句含有错误的可能性, 给出推荐方案, 确定错误发生的位置。
2 怀疑度计算模型
2.1 相关定义
错误定位的过程就是计算每条语句含有错误可能性大小的过程, 也称作怀疑度计算。为计算怀疑度, 做如下定义。
定义1 失败切片数mi: 由运行失败的测试用例对应的参数计算得出的动态切片中覆盖到语句Si的动态切片数。
定义2 正确切片数ni: 由运行成功的测试用例对应的参数计算得出的动态切片中覆盖到语句Si的动态切片数。
定义3 失败路径数pi: 动态测试中, 测试用例运行失败且路径中覆盖到语句Si的测试用例数。
定义4 正确路径数qi: 动态测试中, 测试用例运行成功且路径中覆盖到语句Si的测试用例数。
定义5x: 运行失败的测试用例总数。
定义6y: 运行成功的测试用例总数。
定义7 影响因子αi:αi是经过动态切片后, 通过执行Si并且运行失败的测试用例数与总的运行失败测试用例数的比值进行计算, 即αi=mi/x。
定义8 影响因子βi: 是经过动态切片后, 通过执行Si并且运行成功的测试用例数与总的运行成功测试用例数的比值进行计算, 即βi=ni/y。
2.2 怀疑度模型
运行成功或失败的测试用例对判断语句中含有错误均有贡献[11]。对每条语句Si, 当测试用例运行失败且运行Si时, 则认为语句Si含有错误的可能性增加; 当测试用例运行成功且运行Si时, 则认为语句Si含有错误的可能性降低。运行成功的测试用例和运行失败的测试用例的数量不同, 运行成功的测试用例多时, 会导致所有的语句含有错误的可能性降低。所以, 不仅考虑运行成功或失败且经过Si的数量, 还要考虑其在总的运行成功或失败的测试用例中所占的比例。在获取的路径中含有导致错误产生无关的语句, 为减少这些语句, 对产生错误语句中的变量做动态程序切片。通过程序切片降低不相关的语句含有错误的可能性。
怀疑度SSuspicious(Si), 语句Si不同时,Si中含有错误的可能性大小也不一样,把这种含有错误的可能性定义为怀疑度, 怀疑度的计算公式如下
3 Trace & Slicing错误定位算法
笔者进行错误定位的思想是, 先分析动态测试报告, 检查是否有运行失败的测试用例, 如果有运行失败的测试用例, 根据运行过程中的错误信息获取程序的动态切片, 再根据动态切片信息和执行轨迹信息计算每条语句的怀疑度, 进行错误定位。算法所使用的类之间关系的设计如图2所示。
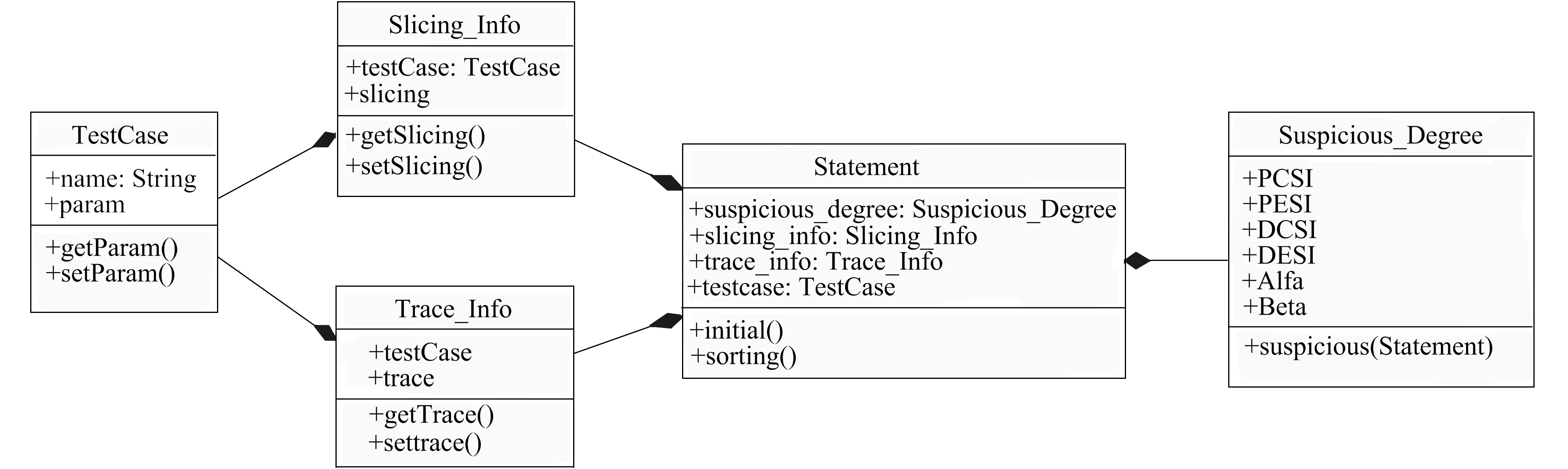
图2 类关系图Fig.2 Class diagram
在图2中TestCase为测试用例类, 其中name为测试用例名, param为测试用例的参数信息, 该参数也作为获取动态切片的参数。Slicing_Info为动态切片信息, 每个测试用例的参数对应一条切片信息。Trace_Info为执行轨迹信息, 每个测试用例对应一项执行轨迹信息, 该信息保存在测试报告中。Statement存储每条语句动态切片和执行轨迹的覆盖信息。Suspicious_Degree为怀疑度, 其中suspicious(Statement)方法计算怀疑度, 具体计算过程根据式(1)进行, 每条语句对应一个怀疑度值, 根据怀疑度值的大小判断含有错误可能性的大小。
3.1 算法描述
算法Trace & Slicing具体描述如下。
输入: 测试用例集, 源程序
输出: 查错方案
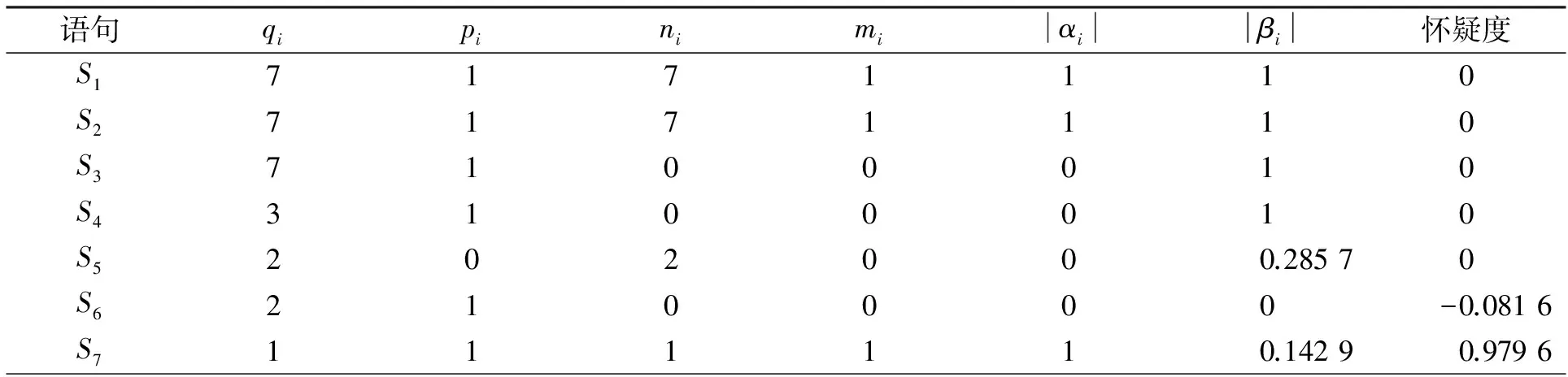
initial TestCase, Path_Info and flag;//Path_Info数组存储每个测试用例的路径信息, flag标注是否有运行失败的用例for(inti=0;i if(Path_Info[i].result==False){ computing dynamic slicing;∥如果有运行失败的测试用例, 则计算对应的动态切片 initial Statement;∥初始化每条语句的状态 flag=true; break; } flag=false; } if(flag){∥如果有运行失败的测试用例, 则计算每条语句的怀疑度, 进行错误定位 for(intj=0;j Statement[j].suspicious_degree=Suspicious(Statement[j]);∥计算每条语句的怀疑度 } sorting Statement by suspicious_degree and recommending scheme of finding fault/*根据怀疑度对语句排序并给出推荐方案*/ } 3.2 实例分析 图3所示的程序为计算输入的3个数的中间数, 其中在第7行中正确的语句应该是m=x, 由于误写成m=y, 导致程序存在错误。下面将用此例介绍如何定位错误发生的位置。 图3 MiddleNum源码图Fig.3 Source code of MiddleNum 对图3中的程序编写了8个测试用例(见表1), 这8个测试用例分别选取不同的参数。T1是一组随机数,T2选取两个相等的参数,T3~T8选取3个不同大小的数, 对其进行排列组合作为测试用例的输入参数。表2中的数据是根据定义2.1中的定义进行计算的,怀疑度根据式(1)计算得出, 其计算结果如表2所示。 表1 测试用例表 表2 MiddleNum怀疑度表 (续表2) 根据怀疑度排列语句可得出如下序列 S7->S1->S2->S3->S4->S5->S8->S9->S11->S13->S14->S15->S10->S6->S12 由上面的序列可得出语句S7含有错误的可能性最大, 程序员查找差错时可首先检查语句S7是否含有错误。 为评估所提出算法的有效性, 本节将对比Trace & Slicing算法与Tarantula[9]算法的有效性(见图4~图6)。Tarantula算法通过程序的执行轨迹信息计算语句含有错误的可能性, 只考虑了运行成功与运行失败的测试用例的执行轨迹是否覆盖了该语句, 没有考虑不相关语句的影响。该实验数据来自http://sir.unl.edu, 其中有XML-Security, JDepend, CheckStyle测试程序。 图4 XML-Security错误定位速率Fig.4 Rate of fault localizationof XML-security 图5 JDepend错误定位速率Fig.5 Rate of fault localizationof JDepend 图6 CheckStyle错误定位速率Fig.6 Rate of fault localizationof CheckStyle 实验对比了经过错误定位算法计算后, 前5行推荐语句发现错误的百分比。通过图4~图6可以看出, Trace & Slicing算法经过动态切片降低不相关语句的影响后, 含有错误语句的排列被前置。在被测试的3组数据中, Trace & Slicing比Tarantula发现错误的比例高, 并且Trace & Slicing算法能在前3行定位到约80%的错误。 测试用例的运行信息可用于错误定位, 并且导致错误产生的语句包含在用例的执行轨迹中。执行轨迹中含有大量与错误产生无关的语句, 检查这些无关的语句是否含有错误会浪费程序员的时间。通过动态切片技术降低无关语句的影响, 使可能对错误产生有影响的语句排列提前, 有助于程序员提前发现错误。通过实验结果证明, 笔者提出的算法提高了错误定位的效率。 [1]JONES J A, BOWRING F J, HARROLD M J. Debugging in Parallel [C]∥Proceedings of the 2007 International Symposium on Software Testing and Analysis (ISSTA 07). New York, NY, USA: ACM, 2007: 16-26. [2]HAILPERN B, SANTHANAM P. Software Debugging, Testing, and Verification [J]. IBM Systems Journal, 2002, 41(1): 4-12. [3]JONES J A. Semi-Automatic Fault Localization [D]. Atlanta, USA: Computing Department, Georgia Institute of Technology, 2008. [4]SANTELICES R, JONES J A, YU Y, et al. Lightweight Fault-Localization Using Multiple Coverage Types [C]∥Software Engineering, 2009, ICSE 2009, IEEE 31st International Conference on. Vancouver, Canada: IEEE, 2009: 56-66. [5]虞凯, 林梦香. 自动化软件错误定位技术研究进展 [J]. 计算机学报, 2011, 34(8): 1411-1422. YU Kai, LIN Mengxiang. Advances in Automatic Fault Localization Techniques [J]. Chinese Journal of Computers, 2011, 34(8): 1411-1422. [6]张云乾, 郑征, 季晓慧, 等. 基于马尔科夫模型的软件错误定位方法 [J]. 计算机学报, 2013, 36(2): 445-456. ZHANG Yunqian, ZHENG Zheng, JI Xiaohui, et al. Markov Model-Based Effectiveness Predicting for Software Fault Localization [J]. Chinese Journal of Computers, 2013, 36(2): 445-456. [7]WONG W E, DEBROY V. Software Fault Localization [J]. IEEE Transactions on Reliability, 2010, 59(3): 473-475. [8]WONG W E, DEBROY V, CHOI B. A Family of Code Coverage-Based Heuristics for Effective Fault Localization [J]. Journal of Systems and Software, 2010, 83(2): 188-208. [9]XIE X, WONG W E, CHEN T Y. Metamorphic Slice: An Application in Spectrum-Based Fault Localization [J]. Information and Software Technology, 2013, 55(5): 866-879. [10]SAHOO S K, CRISWELL J, GEIGLE C, et al. Using Likely Invariants for Automated Software Fault Localization [C]∥Proceedings of the Eighteenth International Conference on Architectural Support for Programming Languages and Operating Systems. New York, NY, USA: ACM, 2013: 139-152. [11]JONES J A, HARROLD M J, STASKO J. Visualization of Test Information to Assist Fault Localization [C]∥Proceedings of the 24th International Conference on Software Engineering.Orlando, FL, USA: ACM, 2002: 467-477. (责任编辑: 刘俏亮) Research on Fault Localization Based on Execution Trace and Dynamic Slicing SUN Shiming1, HOU Xiuping1, GAO Can2, SUN Linlin1 The problem of faulty localization during program debugging is studied, and execution trace and dynamic slicing are applied to faulty localization. Irrelevant statements of fault localization are included in execution trace, accuracy of fault localization is affected by these statements. The influence of irrelevant statements is reduced by dynamic slicing technology based on execution trace. The model of suspicious degrees computing based on execution trace and dynamic slicing had been established, and suspicious degree of each statements could be computed by this model. After sorting these statements by their suspicious degrees, recommendation of fault localization would be reached. The experimental results are compared with other algorithms’, and the method of faulty localization based on execution trace and dynamic slicing is proved effective. execution trace; dynamic slicing; suspicious degrees 1671-5896(2014)05-0528-06 2014-01-14 国家科技部863高技术基金资助项目(2011AA040602) 孙士明(1986— ), 男, 山东莱芜人, 长春工业大学硕士研究生, 主要从事软件工程研究, (Tel)86-13756116537(E-mail)sunshiming0634@qq.com; 侯秀萍(1964— ), 女, 长春人, 长春工业大学教授, 硕士生导师, 主要从事软件工程研究, (Tel)86-18643194774(E-mail)houxiuping@mail.ccut.edu.cn。 TP311 : A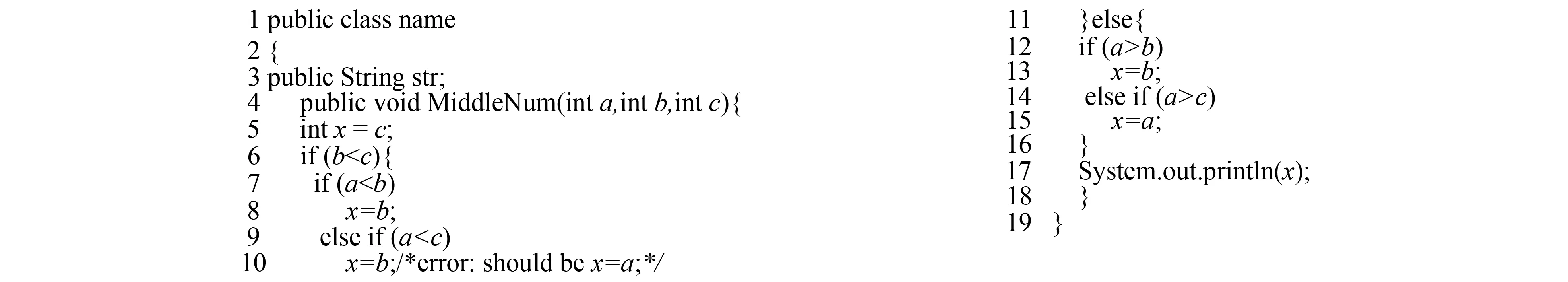

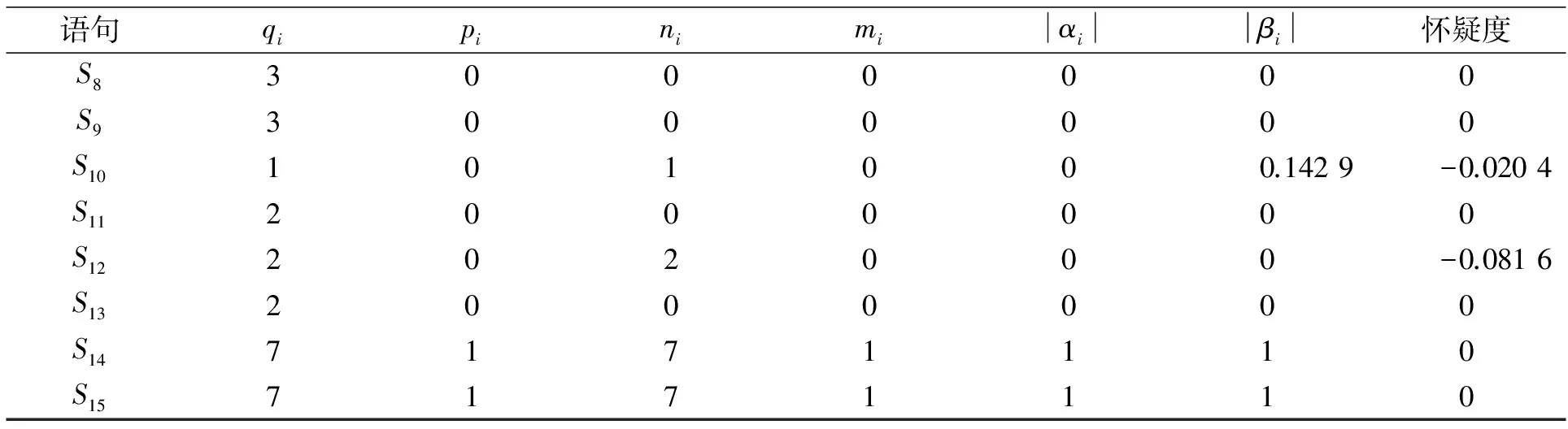
4 对比分析
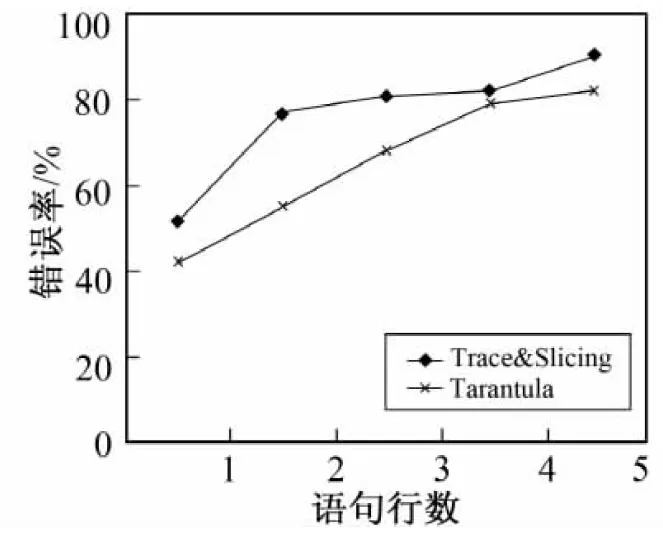
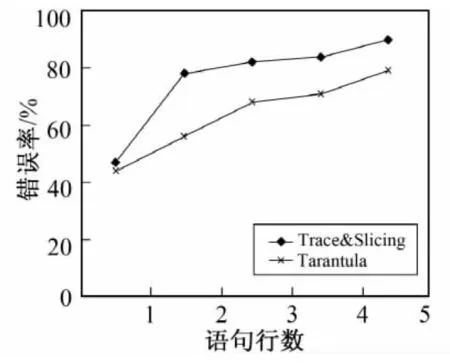
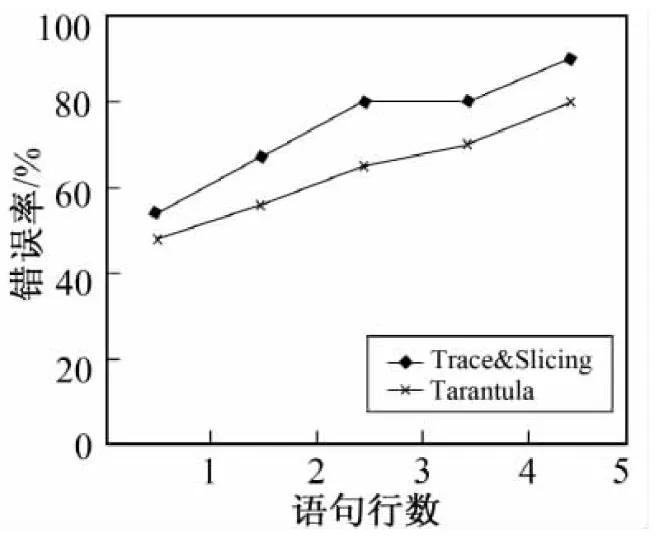
5 结 语
(1. School of Computer Science and Engineering, Changchun University of Technology, Changchun 130012, China;
2. The First Affiliated Hospital, Soochow University, Suzhou 215006, China)
猜你喜欢
铁道通信信号(2020年6期)2020-09-21 09:23:22新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50传感器与微系统(2018年7期)2018-08-29 00:44:18作文评点报·低幼版(2017年44期)2017-11-16 08:24:58电信科学(2016年11期)2016-11-23 05:07:58中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40浙江理工大学学报(自然科学版)(2015年7期)2015-03-01 02:54:29中国当代医药(2015年17期)2015-03-01 02:03:38语文知识(2014年4期)2014-02-28 21:59:52空间控制技术与应用(2010年3期)2010-12-23 08:04:57
