
基于Torque的新型作业调度策略的研究
2014-07-25 09:00周凯,林明
网络安全与数据管理 2014年22期
周 凯,林 明
(江苏科技大学 电子信息学院,江苏 镇江 212003)
0 引言
集群的使用在高性能计算中并不鲜见。在高性能计算中,大部分是并行批处理作业,对于集群的高效运转,优良的作业调度软件以及调度策略显得至关重要[1-2]。目前已有很多集群作业管理系统,具有代表性的有Wisconsin-Madison大学的Cordor、IBM公司的Platform LSF、Altair公司的PBS pro以及开源软件Torque,其中,Cordor是科研项目,LSF和PBSpro是商业软件,而Torque是开源项目。它们各有特点[3],Cordor比较全面地实现了检查点的操作;LSF和PBS pro虽然较为完备,但是使用它们需要购买昂贵的license;而Torque由于是开源项目,正如Linux系统一样,有全球数量众多的Linux系统爱好者的强大支持,并且它提供灵活的作业调度策略和用户身份认证机制,所以本文采用Torque作为作业调度软件来研究。与此同时,由于文中的测试作业对运行时间和IO吞吐率有较高的要求,因此还需要对Torque进行二次开发,加入新提出的调度策略,并通过与自带的调度策略进行对比,体现该调度策略的优越性。
1 Torque的基本架构和工作原理
Torque原名为PBS(Portable Batch System),是由美国国家宇航局(NASA)Ames研究中心、劳伦斯利物莫国家 实 验 室 (Lawrence Livermore National Laboratory)以 及墨绿信息解决公司(Veridian Information Solutions,Inc)牵头发起的一项针对高并发、大数据量作业调度的科研项目[4]。该作业调度软件自带FIFO类型的作业调度器pbs_sched,同时也支持其他调度器,本文就是采用目前较为流行的Maui调度器。目前PBS分为两部分:由Altair公司经营的商业版PBS pro和由Adapting Computing公司运营的Torque,后者开源,并支持使用其他调度器替换自带的pbs_sched,更适宜用来研究,而且也支持复杂的自定义调度策略,能满足本课题的需求。
1.1 Torque的体系结构
如图1所示,Torque使用一个主主机、任意多的执行主机以及作业提交主机,主主机是Torque集群的中央管理者。一台主机既可以被设置成主主机,也可以被设置成执行主机。通常情况下将提交主机与主主机合并。
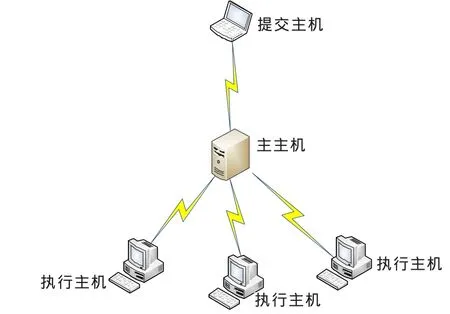
图1 PBS集群的体系架构
1.2 Torque的工作原理
Torque能正常调度作业,需要启动pbs_server、psb_mom和pbs_sched(本文采用Maui调度器mauid)三个守护进程。
1.2.1 pbs_server进程
psb_server是在主主机上执行的进程,是批处理系统的核心,在集群中只有一个,它的主要功能有:提供一些基本的批处理服务,接收/创建一个批处理作业、修改作业,在系统崩溃时保护作业,将用户请求送达pbs_mom进程并进行交互等。
1.2.2 pbs_mom进程
pbs_mom是在执行主机上运行的进程,如果需要主主机也进行计算操作,则主主机上也需要运行该进程,它负责收集执行主机上的系统资源。pbs_mom的主要作用是在pbs_server进程的指令下启动、监控和终止作业。
1.2.3 pbs_sched进程
pbs_sched运行在主主机上,它的作用是决定什么时候在什么地方运行作业。它从psb_server进程请求作业状态信息,从pbs_mom进程请求资源状态信息,然后决定如何调度作业。Maui调度器的进程mauid与pbs_sched类似,不再赘述。
1.2.4 Torque处理批作业的过程
在Torque中,三个进程分工明确,三者通过Socket彼此通信,一方面能使主主机快速将用户作业需求分派下去,另一方面也能实时监控集群系统信息。图2展示了Torque的内部结构原理。

图2 Torque作业调度过程图
整个作业调度的过程分析如下:
(1)用户提交作业请求到Torque的Server端;
(2)Server端根据作业需求向调度器Scheduler发起询问;
(3)调度器通过Socket与执行器Mom通信以获取节点资源信息;
(4)执行器中的首节点Mom Superior向Scheduler返回集群节点资源信息,包括可用内存量、CPU负载信息等;
(5)Scheduler检查作业队列并为作业分配资源,同时将作业ID传递给Server;
(6)Server通过Socket通知首节点Mom Superior去执行批处理作业脚本的命令;
(7)作业执行完成后,Mom将结果信息返回给Server端;
(8)Server端根据预先设定的方法将作业结果返回给用户。
2 Torque默认的调度器
Torque自身集成一个简单的基于C语言的FIFO调度器,并且提供源代码,实际应用当中Torque大都另外集成了别的调度器,本文采用的是常用的Maui调度器。
Torque自带调度器调度流程图如图3所示。Torque自带的FIFO调度器其实并不是真正意义上的先进先出,它是追求CPU的最大利用率[5]。实际上它的原理与FirstFit策略类似,即扫描作业请求,执行集群现有资源能满足的第一个作业[6]。该策略可能会使大作业(需求资源较多)迟迟得不到运行,因此会产生饥饿现象。为了克服此问题,FIFO引入了饥饿作业调度方法,当某一作业在队列中等待时间超过一定阈值 (默认是24小时)时,会对所需资源进行预约,故能解决大作业的饥饿等待。但同时出现一个问题,被预约的资源不能被别的作业使用,这样就丧失了集群的整体公平性,作业间的时间空隙没有得到有效利用。可见,Torque自带的调度器功能有限,因此,集成其他更优秀的调度器以及采用更为优化的调度策略显得尤为重要。
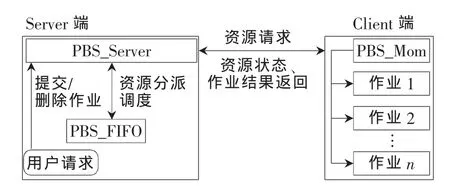
图3 Torque自带调度器调度流程图
3 基于节点负载情况自定义优先级回填策略
给提交的作业预先设定优先级,并根据优先级对提交的作业进行排队,然后再按照队列中的作业顺序依据FCFS的方式执行作业[1]。这种方法有一个弊端,即优先级在作业提交时就已经被设定了,如果high priority的作业的需求资源远高于集群现有可用资源,该作业就会长时间处于等待状态。为解决此问题,提出了新的策略约定,当某一大作业的等待时间超过预设的阈值时,就对需求资源进行预约,同时,计算出多个预约作业之间的时间空隙,将队列中一些资源需求小的作业插入到其中执行。该策略总体的执行过程如图4所示。
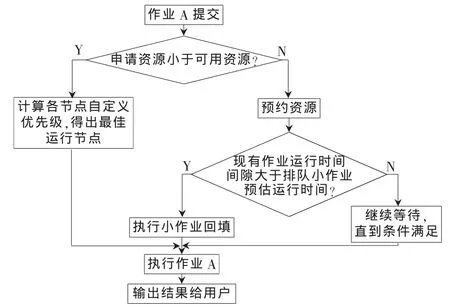
图4 作业策略执行流程图
3.1 节点负载情况的计算
节点的负载情况很大程度上影响作业调度系统对资源的选取,负载大的节点计算出的资源评估值应该较小,表示越不容易被选中执行作业。资源选择是一个作业从资源列表(Rselected)中选择资源的过程,因此,就需要给出一个算法,帮助调度系统选择执行某一作业的最优资源。资源选择所使用的算法应能从目前的资源状态考虑,并能根据一定的计算公式来算出最适宜的资源。由于现实中选择作业运行资源最关注的往往是CPU和内存的利用率,因此本文提出的选择资源的算法主要考虑节点的CPU和RAM,计算公式定义如下:

其中,WCPU代表分配给CPU速率的权重,CPUload代表目前CPU的负载,CPUspeed代表CPU的实际速率,CPUmin是CPU的速率最小值,WRAM是分配给RAM的权重,RAMusage是当前RAM使用率,RAMsize是RAM的原始容量,RAMmin是最小的RAM值。
下面给出一个实际的例子,根据上面给出的负载计算公式从三组候选的资源中选择一种资源,假设每种资源的相关参数如表1所示。
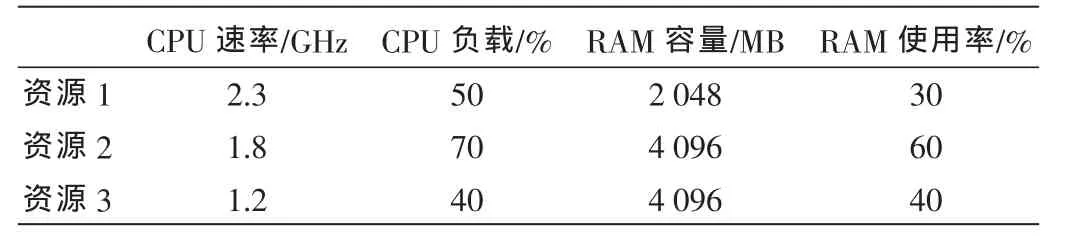
表1 资源负载情况列表
假设该算法中整个权重为10,其中CPU权重为6,RAM的权重为4。设定CPU速率最小值为1 GHz,RAM最小值为1 024 MB,将值代入式(1)~(3),可得资源负载估计值如下:
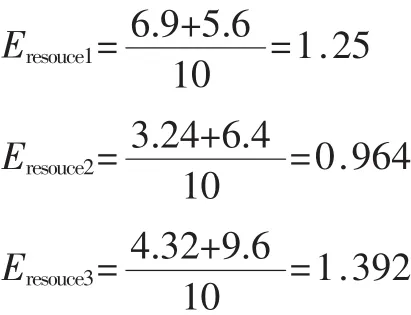
从负载估计值来看,资源3为最优执行资源。
3.2 作业优先级的确定
提交作业的优先级不仅与作业类型、作业所需资源类型及多少有关,还与作业提交后等待执行所花的时间有关,等待时间越长,作业在队列中的优先级应该越高,表示该作业越易被执行。当然,还需要设定一个优先级阈值,当优先级超过这个阈值后,系统将对该作业所需资源进行预约。
定义 提交作业的优先级公式为:
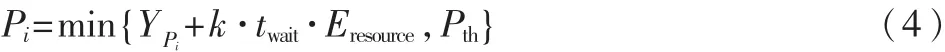
其中,YPi是提交者与管理员共同商议的作业预设优先级,k为常数权重因子,twait为作业等待的时间 (以min计),Eresource为资源负载情况,Pth为预设优先级阈值。 由式(4)可知,等待时间越长,负载估值越大,作业优先级越大,表示该作业越易被执行。作业的实际优先级需要将式(4)中前半部分与预设的优先级进行比较,取较小者,如果计算值大于阈值,则系统对所需资源进行预约。
假设目前集群中可用资源为资源1,现在有作业1、作业2、作业3共三个作业提交,预设优先级为10、15、8,预设的优先级阈值为55,权重因子k=1,等待时间为120 s、100 s、238 s,根据式(4)可计算出三个作业的优先级分别为P1=12.500,P2=17.083,P3=12.958,三者均小于预设优先级阈值,不需对资源进行预约,故根据前述定义可知,三个作业的执行顺序为作业2→作业3→作业1。
3.3 回填策略的设计
上节提到的案例中,三个作业经过计算得出的优先级都没有超过优先级阈值,故没有对资源进行预约。如果超过了阈值,就需要对集群资源进行预约,被预约的资源不能再分配给别的作业使用,这种要求就容易造成多个作业间时间空隙被浪费的现象,而通过引入回填策略,就能很好地解决这个问题,这里主要介绍一下回填策略的设计。
假设集群里的资源(处理器数目)有限,目前有三个大小不等的作业在运行,队列中还有两个作业在排队,默认的FCFS策略,排队的作业会等待前三个作业都运行结束后再进入集群执行,但如果引入了回填策略,则系统会先扫描集群中运行的作业之间是否存在时间间隙,然后再据排队作业所需资源的多少和预估时间,将排队的作业插到空闲周期中运行,这样能充分利用资源,提高集群吞吐率。具体过程示意图如图5所示。
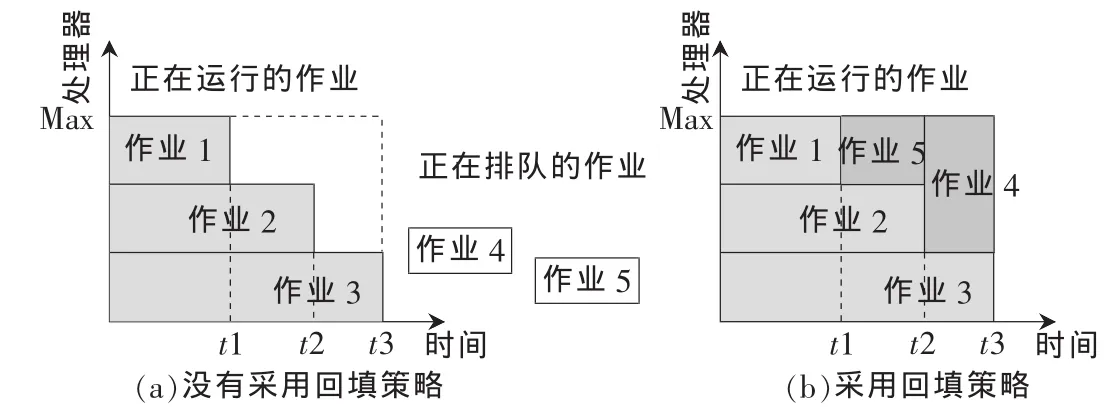
图5 采用回填策略前后的对比
由图5可知,加入回填策略后,当作业等待时间超过一定值(可以设定一个等待时间阈值)后,系统会扫描全部队列,选择作业预估时间小于空闲周期时间的作业插入空闲周期执行,充分利用了集群的空闲周期,减少作业等待时间。
3.4 新型调度策略与默认调度策略对比
上文已经提过,Torque自带的FIFO调度器实际上原理与FirstFit策略类似,即在队列中选择当前系统资源能满足的第一个作业执行。测试集群环境为4台IBM PureFlex X240刀片式服务器,1台作为主主机,其他3台作为执行主机,所有机器上都装好了Torque和Maui,在Maui的配置文件maui.cfg中添加新策略设置。对比测试中,将作业响应时间作为衡量指标,它代表从作业提交到作业开始执行所花时间。测试时,构建了三个测试作业集,分别有1 000、1 500、2 000个作业,为了方便,统一设定预设优先级为0,常数权重因子为1,预设优先级阈值为55。不同策略的作业响应时间对比如图6所示。因为基于节点负载情况自定义优先级回填策略兼顾了公平性和高效性,既有优先级设置,也有回填策略考虑,所以相比于FirstFit的调度策略,在排队作业较多时,作业响应时间有明显的提升,由图6可知,作业数目为1 000、1 500、2 000时,作业响应时间分别减少了26.1%、13.2%和12.5%。
4 结论
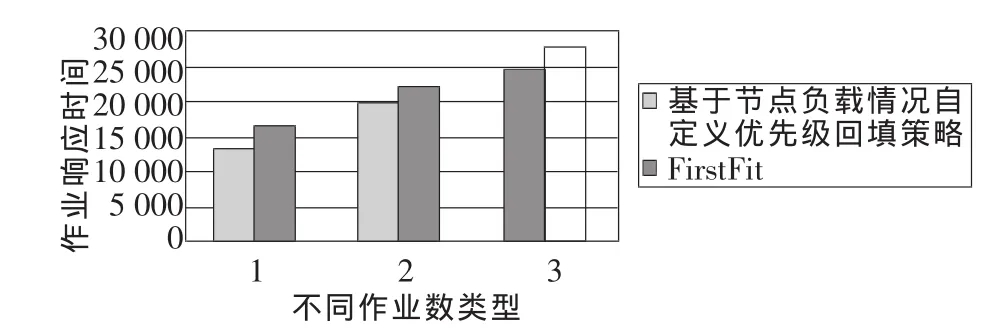
图6 不同策略的作业响应时间对比
本文提出了一种基于节点负载自定义优先级回填策略,它能根据节点负载计算出资源评估参数,结合作业的预设优先级及等待时间,得出相应优先级参数,将各作业按照此优先级排序,逐个执行。当作业优先级超过阈值时,系统将对作业所需资源进行预约,在预约过程中,已运行的作业之间可能会产生时间空隙,这时根据回填策略设置,系统扫描作业间隙,将作业预估时间小于时间间隙的作业投入到集群中执行,以达到充分利用集群资源、增大集群吞吐率的目的。通过作业响应时间的对比可以看到,基于节点负载情况自定义优先级回填策略比默认的调度策略在作业响应时间上有较好的提升。
[1]刘萍.作业调度算法研究[J].现代计算机,2012,10(1):15-17.
[2]兰文富,罗江华,程克非.集群系统的资源调度管理实现[J].科技创新导报,2011,24(4):43-44.
[3]童瑞,董小社,李纪云,等.基于OpenPBS的机群作业管理系统的设计与实现[J].计算机工程与应用,2004,13(2):123-125.
[4]张丽晓,袁立强,徐炜民.基于任务类型的集群调度策略[J].计算机工程,2004,7(30):63-64.
[5]BRIM M,GEIST A,LUETHKE B,et al.M3C:managing and monitoring multiple cluster[C].Proceedings of the First IEEE/ACM International Symposium on Cluster Computing and the Grid,2001:386-393.
[6]王阳,周智力,卢康.高性能计算集群调度策略优化及应用程序并行效率研究[J].高科技产品研发,2013,20(2):31-32.
猜你喜欢
——国外课堂互动等待时间研究的现状与启示
中小学教师培训(2022年6期)2023-01-11
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
公民与法治(2016年2期)2016-05-17
新教育时代电子杂志(学生版)(2015年31期)2015-12-20
视野(2015年14期)2015-07-28
新闻传播(2015年21期)2015-07-18
新闻传播(2015年10期)2015-07-18
