
模糊C-均值聚类分析的黑龙江省大豆种植业战略分区研究*
2014-07-10 10:48:47孙立娜于金平
大豆科技 2014年2期
孙立娜,左 鹏,于金平,苏 睿
(1.东北农业大学食品学院,哈尔滨 150030;2.东北农业大学理学院/东北农业大学大豆生物学教育部重点实验室,哈尔滨 150030)
模糊C-均值聚类分析的黑龙江省大豆种植业战略分区研究*
孙立娜1,左 鹏2**,于金平1,苏 睿2
(1.东北农业大学食品学院,哈尔滨 150030;2.东北农业大学理学院/东北农业大学大豆生物学教育部重点实验室,哈尔滨 150030)
基于黑龙江省大豆总产量、大豆总种植面积、大豆化肥(农药)施用量、以及气候因素(全年地表总积温、全年总降水量、全年光照)等影响因子,构建黑龙江省大豆种植业战略分区指标体系,采用模糊C-均值聚类算法为区划方法,对黑龙江省大豆种植业进行战略分区。研究结果将黑龙江省富锦市、海伦市、讷河县等6个县市分为大豆主产区,将克山县,宝清县,五大连池等7个县市分为大豆高产区,将穆棱市,密山市,庆安县等23个县市分为大豆中产区,将呼兰区,方正县,木兰县等43个县市分为大豆低产区。为黑龙江省大豆产业发展的进一步研究,高效利用现有土地资源,实现大豆产业腾飞提供科学决策依据。
黑龙江;大豆种植业;战略分区;模糊C-均值聚类算法
1 引言
黑龙江省种植大豆历史悠久,情况复杂,年度波动较大,这就给大豆产业战略分区带来了很大困难。随着近年来农业国际化、市场化、商品化程度的提高,对国家大豆产业化程度的要求也越来越高。合理的大豆产业战略分区可以对国家制定大豆政策提供依据,避免政策的盲目性、重复性。以大豆产业战略分区为基础,逐步加大政策的倾斜与宣传,可以充分调动全省大豆种植积极性。振兴黑龙江省的大豆产业,促进大豆农业生产发展和相关产业链增长,有助于为粮农增收寻找长期稳定的源动力,为黑龙江省经济增长提供新的增长点。因此搞好大豆信息管理系统与产业战略分区是当前大豆产业兴旺发展极其重要的课题之一。研究目的首先在于全面评估大豆产业数据,根据大豆产量、种植面积、化肥农药施用量、气候因素等主要影响因子,制定黑龙江省土大豆产业分区原则,建立黑龙江省大豆产业战略分区指标体系,探索影响大豆产业发展的关键因素及相互关系和变动规律。并采用模糊C-均值聚类算法对大豆信息数据进行分类分析,提出黑龙江地区大豆产业战略分区结果和相关政策建议。
2 指标体系的建立
黑龙江省的大豆种植历史悠久,品种繁多,种植地域复杂。因此进行黑龙江省大豆产业战略分区是制定全省大豆产业宏观调控政策的前提条件。根据大豆产业本身的特点及其主要影响因素,选择适宜的分区指标,明确各指标的概念和量化标准对大豆产业分区结果是否合理有很大影响。分区指标的设置必须满足全面性、代表性、易取性的要求,而且能反映出分区的目的以及所依据的原则,采用黑龙江省各县大豆总产量(t)、大豆总种植面积(hm2)、大豆种植中化肥及农药施用量(t)、气候因素(全年地表总积温(℃)、全年总降水量(mm)、全年总光照(J/m2)为大豆战略分区的指标。
2.1 大豆总产量
大豆总产量(t,soybean yields)缩写为(SY)是战略分区的重要因素,因为产量的高低直接决定了农业政策的制定与方向,进而影响到全省农业结构布局和产业方式,在一定程度上决定着全省大豆产业的生产方式、结构特点和发展方向。
2.2 大豆总种植面积
总种植面积(hm2,soybean growing area)缩写为(SA)与大豆产量乃至于大豆产业息息相关,种植面积的大小直接影响到县级行政区划的农业重点和农民的主要收入来源,对大豆产业有着重要的影响。
2.3 化肥及农药施用量
化肥及农药施用量(t,chemical and pesticides fertilizer)缩写为(CF与PF),其中化肥施用量包括:氮肥、磷肥、钾肥以及复合肥施用量。化肥及农药施用量能反映出农户对大豆种植的投入情况,并对大豆产业的经济效益有着重要影响。
2.4 气候因素
气候因素(climatic factor)缩写为(CL),其包括全年地表总积温(℃)(accumulated temperature)、全年总降水量(mm)(amount of precipitation)、全年总光照(J/m2)(light of sun)直接影响大豆产量,并能反映出地域种植大豆的适宜度,对大豆种植分布起着重要的作用。
2.5 土壤状况
土壤状况(soil regime)缩写为(SR)是地球陆地上可以生长植物的疏松表层,其中存在为植物生长供应、协调营养条件和环境条件的土壤肥力,是人类赖以生存的物质基础,是农业生产的基本条件。
3 大豆种植业分区原则与方法
3.1 分区原则
参照行政区划、灌溉区划、土质区划、农业区划、气候区划等,按照归纳相似性,区别差异性的总原则进行分区,具体分区原则为:以各县市大豆总产量、大豆总种植面积、化肥施用量、农药施用量、气候因素等分布规律,特别是大豆主要种植区的分布规律,为分区的基础;归纳各县市大豆产业的一致性,及大豆种植所需条件差异为分区依据;各县市区大豆产业相互独立;以发展各县市大豆产业的可持续发展,努力提高产业经济效益,生态效益和社会效益为目的;为合理制定大豆产业宏观调控政策并保持行政区界的完整性。综合考虑,黑龙江省大豆产业战略分区基准单元采用行政区县为单位,若包含地级市则以地级市所辖区为基准单位。
3.2 分区方法
传统的聚类分析是把每个待分类的对象严格地划分到某个类中,体现了非此及彼的性质,分类界限是分明的。然而客观事物之间的界限往往是不分明的,这就提出了模糊划分的概念。根据黑龙江省大豆产业特点,采用改进的模糊C-均值聚类算法,模糊C-均值聚类算法是一种无监督的动态聚类算法,其算法思想是基于寻找一种最佳的分类。该算法首先选择若干样本作为聚类中心,然后遵循某种聚类准则(如最小距离准则),使其他样本向各中心聚类,从而得到一个初始分类。在初始分类基础上,判断初始分类是否合理,若不合理则修改分类如此反复进行,直到得到合理的分类结果为止。同时兼顾农业分区、土质分区、灌溉分区、行政分区等其他分区,制定科学合理和严谨的分区指标以及分区等级,对黑龙江省大豆产业进行战略分区,与实际情况和基于MapInfo软件下的黑龙江省大豆产量分布图进行比较对照,并进行相互验证,得到恰当的黑龙江省大豆产业分区的最佳分类结果。
4 模糊C-均值聚类分析原理
传统中的聚类方法人为地将样本严格地划分到某类中,划分的界限很明显,但实际上现实生活中大多数对象并没有严格的属性,它们在形态和类属性方面存在着兼容性,所以需要用模糊的眼光对此类样本进行分类。用模糊的方法来处理分类问题,称之为模糊聚类分析。模糊聚类分析是把模糊数学的概念引入聚类分析中,以用来研究“物以类聚”的一种多元统计分析方法,是数值分类学的一门年轻分支,也是无监督模式识别的一个重要分支。模糊聚类分析的实质一般是指根据研究对象本身的属性来构造模糊矩阵,并在此基础上根据一定的隶属度来确定聚类关系。即用模糊数学方法把样本之间的模糊关系定量的确定,从而客观且准确地进行聚类。
4.1 数据标准化
实际问题中不同的数据一般具有不同的量纲,数据之间的相互比较首先需要统一量纲,并且一般根据模糊矩阵要求将数据压缩到[0,1]区间上。
采取平移极差变换法:
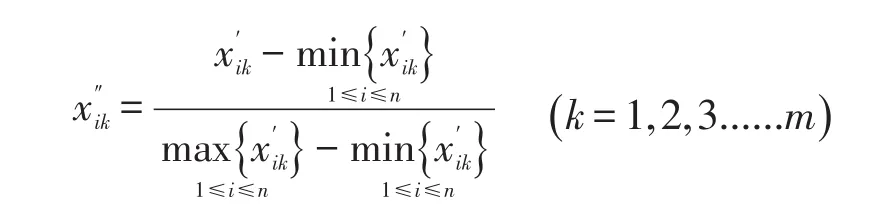
4.2 建立模糊相似关系
将待分类样本总体设为论域X={x1,x2,....,xn},总体中的每个分类样本xi(i=1,2,3......n)均具有m个特征,将其量化,则每个样本都对应描述它们各种特征的一组数:xi1,xi2,xi3,......xik,......xim
选择合适的统计量rij计算模型,在论域X上建立相似关系。按给定性质相似的程度,这样由份就可组成模糊相似矩阵,即:
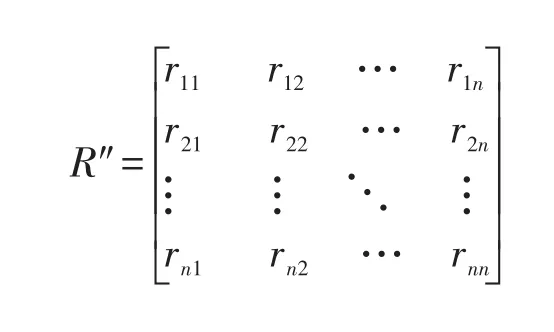
式中,rij为X中元素Xi和Xj相似的程度,有0≤rij≤1,(i,j=1.2.3......n);若rij=0表示Xi和Xj截然不同,毫无相似之处;若rij=1,表示Xi和Xj完全相似(或等同);当i=j时,则rij就是自己与自己相似的程度,显然rij恒取1。
通过上述过程得到的模糊相似关系(矩阵)具有如下性质:(1)自反性,即统计量rij=1;(2)对称性,即统计量rij=rji,(i,j=1.2.3......n)。
黑龙江省大豆产业样本数据取自县级单位播种面积,肥料,气候等相似矩阵中的列取自不同母体,故确定rij的方法选取传统聚类分析中的指数相似系数法:
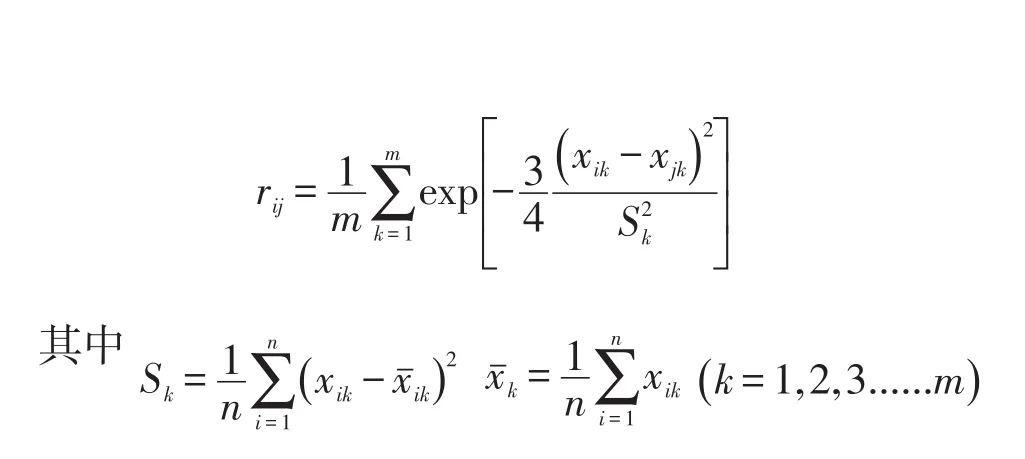
4.3 模糊相似矩阵的改造
建立起模糊关系R*和相似矩阵后,它一般只满足自反性和对称性,而不一定具有传递性,即不一定是模糊等价矩阵,因此需要对模糊相似矩阵R*进行改造,使其具备自反性、对称性和传递性,成为模糊等价矩阵然后进行总体分类。利用二次方法对模糊矩阵进行改造:从模糊相似矩阵R*出发,一次求二次方,即:R➝R2➝R4➝…➝R2i➝…当第一次出现Rk·Rk=Rk时则可知R*在保留自反性和对称性的同时还具有传递性,Rk即为所求模糊等价矩阵(传递闭包)。
4.4 最佳阈值λ的选取
在模糊聚类分析中,对于各个不同的阈值λ∈[0,1],可以得出不同的分类情况,现实中一般需要选择一个确定的阈值λ,然后确定样本的一个具体分类,采取2种方法确定阈值λ。
4.4.1 经验法 利用MapInfo软件对2006年黑龙江省各区县大豆产量、种植面积及单位面积产量进行划分,从分区地图上观察分成几个区域较合理,反之到模糊聚类中寻找对应的阈值。
4.4.2 F检验方法 设论域U={x1,x2,......,xn}为样本空间(样本总数为n),而每个样本xi有m个特征(每个对象所对应的m个数据),从而得到原始数据矩阵。其中
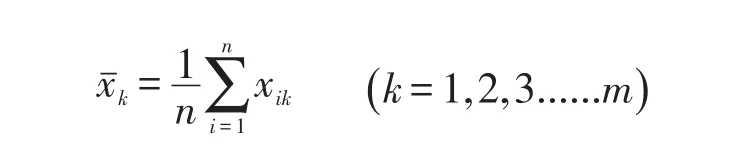
设对应阈值λ的分类数为r,第j类样本数为nj,第j类样本数记为:,第j类聚类中心为向量
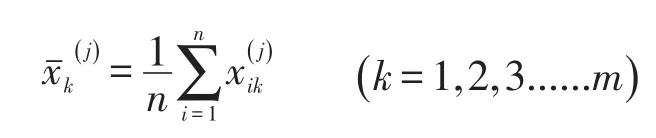
作F统计量:
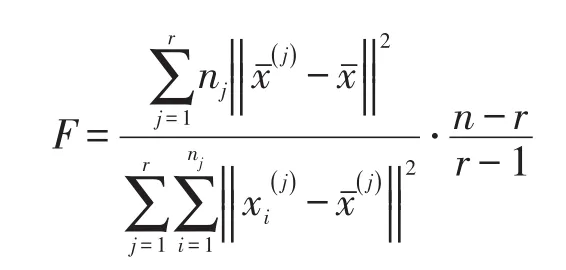
若F>Fa(r-1,n-r)(95%的置信区间)则可知类与类之间差异明显,说明分类较合理;若F>Fa(r-1,n-r)得F值不止一个,则选取较大的为优。
5 基于模糊C-均值聚类的大豆种植业分区
以2006年黑龙江省79个县市区为例,选取各县市大豆产量、大豆总种植面积、大豆化肥及农药施用量、气候因素(全年地表总积温、全年总降水量、全年总光照)数据极差标准化后生成模糊相似矩阵利用Matlab软件对黑龙江省大豆产业进行指数相似系数模糊聚类分析。阈值λ取值依次为:1,0.999 4,0.998 2,0.997 8,0.994 2,0.992 1,0.990 8,0.988 8,0.988 3,0.987 1,0.984 4,0.976 6,0.970 5,0.967 6,0.959 2,0.958 4,0.953 6,0.952 8,0.950 7,0.940 6,0.939 0,0.938 7,0.937 6,0.936 8,0.935 4,0.933 6,0.925 1,0.922 3,0.921 5,0.917 6,0.914 5,0.910 5,0.908 7,0.905 2,0.903 6,0.900 0,0.899 8,0.889 0,0.878 7,0.878 2,0.873 0,0.866 7,0.856 0,0.852 3,0.847 9,0.841 0,0.838 9,0.834 3,0.833 9,0.828 1,0.826 4,0.823 8,0.822 2,0.817 4,0.816 8,0.813 6,0.806 6,0.804 3,0.803 8,0.799 3,0.789 5,0.787 8,0.786 1,0.785 0,0.780 5,0.778 1,0.775 5,0.766 8,0.735 2,0.710 8,0.699 4,0.684 2,0.652 0,0.616 5,0.609 7,0.604 1,0.556 4
当λ=0.6994时可将黑龙江省大豆产业分为7类,当λ=0.6842时,可分为6类,当λ=0.6520时,可分为5类,当λ=0.6165时,可分为4类,当λ>0.6994时分类过细,当λ<0.6165时分类过粗,此时讨论价值不大。且F=5.69,Fa(r-1,n-r)=F0.05(4-1,79-4)=2.72,则F>Fa(r-1,n-r)从数理统计角度来看阈值λ选取恰当,分区合理;还比照2006年黑龙江省各个区县实际种植面积及大豆产量区域划分地图(如图1、2)。
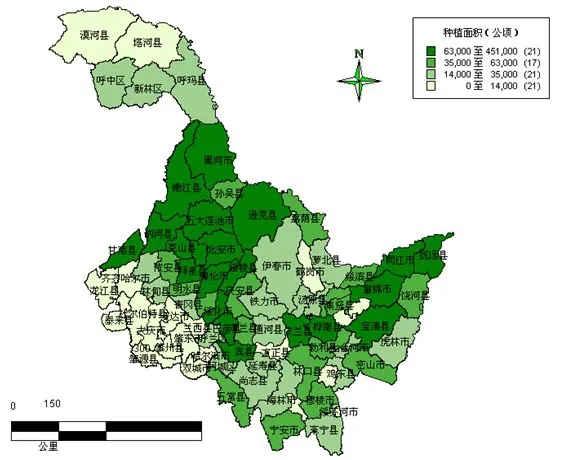
图1 2006年黑龙江省各区县大豆种植面积区域划分地图
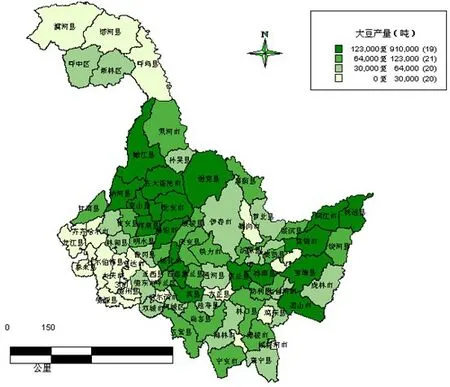
图2 2006年黑龙江省各区县大豆产量区域划分地图
进行比对最终选择阈值λ=0.6165,故全省大豆战略分区为4部分,模糊聚类见图3。
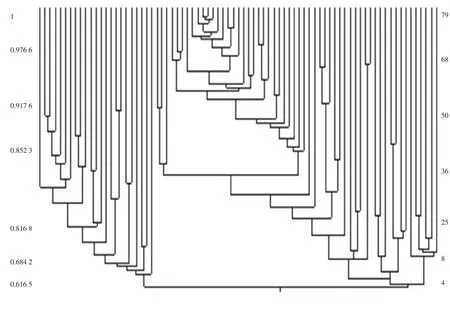
图3 黑龙江省大豆产业战略分区模糊聚类图
黑龙江省大豆产业战略分区结果:
主产区:富锦市,海伦市,讷河县,嫩江县,拜泉县,依兰县。
高产区:克山县,宝清县,五大连池,桦南县,巴彦县,克东县,北安市。
中产区:穆棱市,密山市,庆安县,甘南县,双城县,五常县,宁安市,集贤县,宾县,阿城区,抚远县,逊克县,林口县,依安县,明水县,虎林市,海林市,汤原县,绥棱县,同江市,东宁县,通河县,铁力市。
低产区:哈尔滨,呼兰区,方正县,木兰县,延寿县,尚志县,龙江县,泰来县,富裕县,鸡西市,鸡东县,鹤岗市,萝北县,绥滨县,双鸭山,友谊县,饶河县,大庆市,肇州县,肇源县,林甸县,伊春市,嘉荫县,佳木斯,桦川县,七台河,勃利县,牡丹江,绥芬河,黑河市,孙吴县,绥化市,望奎县,兰西县,青冈县,安达市,肇东市,呼玛县,塔河县,漠河县,齐齐哈尔,杜尔伯特蒙古族自治县,大兴安岭地区。
本着分区指标具有全面性、概括性、易取性等原则,采用数学统计的方法,依据客观事物间的特征、亲疏程度和相似性,通过建立模糊相似关系对客观事物进行分类,以其严格的理论基础和计算方法,能揭示因素间的内在本质差别和联系,消除了传统经验分区的主观性和任意性,其结果可靠、准确,用模糊聚类分析方法处理带有模糊性的聚类问题要更为客观、灵活、直观,计算也更加简洁,更能反映客观实情。采用模糊聚类方法将黑龙江省大豆产业分为主产区、高产区、中产区及低产区。对2006年黑龙江省各市县实际大豆生产数据可得分析结果符合实际情况。其中主产区各县大多在黑龙江省中西部及东北部地形以平原为主,农机械化普及率较高,适合大规模集中种植大豆,并且大豆种植面积占全县农作物总面积40%左右;高产区及中产区中各县农作物生产种类较复杂,大豆种植面积及相关各项投入所占全县比重较小;低产区中包括各地级市辖区,大豆种植面积较小,以及北部山区和东部丘陵地带,地理因素上决定,其大豆产业发展滞后。
6 结论及对策研究
对黑龙江省大豆种植业的地域分布、产业目标、运动过程和构成要素进行了研究,建立了一套大豆种植业战略分区的指标体系,对各样本数据的选取与量化以及大豆种植业的分区原则进行了详细阐述,在此基础上,将模糊聚类分析法应用于黑龙江省大豆生产情况分区,应用基于模糊等价关系的传递闭包方法计算模糊等价矩阵,并利用地理信息系统产量分区的方法确定了最佳阐值,得到黑龙江省大豆生产情况分区结果。将富锦市,海伦市,讷河县等6个县市分为大豆主产区,将克山县,宝清县,五大连池等7个县市分为大豆高产区,将穆棱市,密山市,庆安县等23个县市分为大豆中产区,将呼兰区,方正县,木兰县等43个县市分为大豆低产区。
根据所建立的黑龙江省大豆信息管理系统及模糊聚类将黑龙江省大豆产业分为4个区域,政府决策部门应因地制宜地制定大豆政策;积极开发大豆低产区生产潜力,重点培养中产区,使其稳步发展,大力扶植高产区,打造龙江大豆精品产区,由点及面,全面带动黑龙江省大豆产业发展壮大。
[1]朱明旱,罗大庸,易励群.一种广义的主成分分析特征提取方法[J].计算机工程与应用,2008,44(26):38-40,44.
[2]吴景社,康绍忠,王景雷,等.基于主成分分析和模糊聚类方法的全国节水灌溉分区研究[J].农业工程学报,2004,20(4):64-68.
[3]李鸿吉.模糊数学基础及实用算法[M].北京:科学出版社,2005:99-102.
[4]汪丽娜,陈晓宏,李粤安,等.基于人工鱼群算法和模糊C-均值聚类的洪水分类方法[J].水利学报,2009,40(6):743-748,755.
[5]侯鲁川.四川省节水农业综合效益评价及分区研究[D].成都:四川农业大学,2006:7-8.
[6]邹忠,殷丽萍.基于耕地质量管理的农作物施肥专家系统研究应用[J].现代农业科学,2009,16(4):107-109.
[7]于合龙,陈桂芬,赵兰坡,等.吉林省黑土区玉米精准施肥技术研究与应用[J].吉林农业大学学报,2008,30(5):753-759,768.
[8]王海江,崔静,陈彦,等.基于模糊聚类的棉田土壤养分管理与分区研究[J].棉花学报,2010(4):339-346.
[9]丁斌.动态Fuzzy图最大树聚类分析[J].数值计算和计算机应用,1992(2):157-160.
[10]黄斌,史亮,陈德礼,等.一种处理混合型属性的聚类算法在计算机取证中的应用[J].陕西科技大学学报:自然科学版,2010(02):127-130.
Strategic Planning of Soybean Planting in Heilongjiang Province Based on Fuzzy C-Means Clustering
Sun Lina1,Zuo Peng2,Yu Jinping1,Su Rui2
(1.College of Food Science,Northeast Agricultural University,Harbin 150030,Heilongjiang,China 2.College of Science,Northeast Agricultural University/Key Laboratory of Soybean Biology,Ministry of Education,Harbin 150030,Heilongjiang,China)
The strategic planning of Heilongjiang soybean planting was established using Fuzzy C-Means Clustering based on soybean total yield,total palnting acreage,amount and rate of fertilizer(pesticide),and climatic factors(total accumulated temperature at surface throughout the whole year,total annualprecipitation,and annual illumination).Six main soybean-producing regions were divided,including Fujin,Hailun,Nehe cities.Seven high soybean-producing regions were divided,including Keshan,Baoqing,Wudalianchi cities,and 23 median soybean-producing regions,as well as 23 low soybean-producing regions were also divided.This analysis and evaluation provided the scientific base for making decision on further study of soybean industry development in Heilongjiang Province,and for efficiently utilizing the existing soil resource and achieving take-off of soybean industry.
Heilongjiang;Soybean planting;Strategic planning;Fuzzy C-Means Clustering
S565.1
B
1674-3547(2014)02-0010-08
2014-01-09
孙立娜,女,讲师,硕士,研究方向为食品微生物,E-mail:857847089@qq.com
东北农业大学大豆生物学重点实验室开放基金项目(No.SB12C03)
**通讯作者:左鹏,男,讲师,硕士,研究方向为数学生态,E-mail:zuopeng111@sina.com
猜你喜欢
环球时报(2022-03-29)2022-03-29 17:14:11
应用能源技术(2020年11期)2021-01-26 00:16:50
收藏界(2019年2期)2019-10-12 08:27:04
收藏界(2019年3期)2019-10-10 03:16:48
收藏界(2018年1期)2018-10-10 05:23:20
知识经济·中国直销(2018年7期)2018-07-27 02:49:52
黑龙江省人民政府公报(2017年6期)2017-07-25 09:26:34
黑龙江省人民政府公报(2017年22期)2017-03-26 08:20:10
黑龙江省人民政府公报(2017年21期)2017-03-20 05:29:12
中国糖料(2016年1期)2016-12-01 06:49:04
