
云计算环境下基于遗传蚁群算法的任务调度研究
2014-07-07 01:49张雨李芳周涛
计算机工程与应用 2014年6期
张雨,李芳,周涛
上海理工大学管理学院,上海 200090
云计算环境下基于遗传蚁群算法的任务调度研究
张雨,李芳,周涛
上海理工大学管理学院,上海 200090
对云计算中任务调度进行了研究,针对云计算的编程模型框架,提出一种融合遗传算法与蚁群算法的混合调度算法。在该求解方法中,遗传算法采用任务-资源的间接编码方式,每条染色体代表一种具体调度方案;选取任务平均完成时间作为适应度函数,再利用遗传算法生成的优化解,初始化蚁群信息素分布。既克服了蚁群算法初期信息素缺乏,导致求解速度慢的问题,又充分利用遗传算法的快速随机全局搜索能力和蚁群算法能模拟资源负载情况的优势。通过仿真实验将该算法和遗传算法进行比较,实验结果表明,该算法是一种云计算环境下有效的任务调度算法。
云计算;蚁群算法;遗传算法;任务调度
1 引言
云计算是一种新兴的商业计算模式,由网格计算脱胎而来,但更注重商业化,近年来受到各行各业的青睐。云计算在许多方面只是互联网的一个比喻词,亦即计算和数据资源日益迁移到Web上的比喻词[1]。云计算代表网络计算价值的一个新的临界点。它提供更高的效率、巨大的可扩展性和更快、更容易的软件开发。其中心内容为新的编程模型、新的IT基础设施以及实现新的商业模式。
目前,IBM、Google、Amazon、Microsoft等巨头纷纷涉足云计算,提供了很多基于云计算的服务,比如Google Docs、Google Earth、Gmail、Google App Engine、Amazon EC2(Elastic computing cloud)和S3(Simple storage service)、Microsoft的Windows Live Web及Hotmail等,未来还将有各种各样的云服务呈现[2]。
迄今为止,针对云计算的任务调度问题仍属于一个比较前沿的课题。现有的一些理论还不是十分成熟完善,缺乏一个系统的科学方法。如果采用简单的分配调度方法,例如常用的轮转法、加权轮转法、最小负载(或链接数)优先、加权最小负载优先法、哈希法等,很难达到物理服务器负载均衡,进而会造成服务性能不均衡和其他相关问题。启发式智能化方法近年来愈来愈引起了众多学者的关注和兴趣,诸如神经网络、模拟退火、禁忌搜索、遗传算法、蚂蚁算法等,它们毫无争议地成为解决组合爆炸及NP类问题的锐利工具。文献[3]提出了一种具有双适应度的遗传算法(DFGA),在传统调度算法专注任务的总完成时间最小的同时,也考虑到任务的平均完成时间,但该类算法对系统中的反馈信息利用不够,求解效率不高;文献[4]提出一种基于蚁群优化的计算资源分配算法,根据云计算环境的特点,分析了诸如带宽占用、线路质量和响应时间等因素对分配的影响;文献[5]以云计算计价标准为切入点,提出了一种改进蚁群算法,力图达到整体网络负载均衡,延长网络寿命并获得利润。但由于蚁群算法初始阶段缺乏信息素,存在搜索时间过长,易于停滞的问题,因此该算法在搜索效率上有待提高。
在启发式任务调度算法中,无论单纯利用遗传算法还是蚁群算法都无法获取较好的实际效果,而且还存在不能满足资源节点的负载均衡要求和不能满足用户对服务质量要求的问题,所以实现不同算法的融合非常必要和有意义[6]。因此本文提出了一种遗传蚁群算法对云计算的任务调度策略进行改进,以最大限度地提高云计算环境的效率。
2 问题描述
2.1 云计算中的编程模型分析
目前的云计算环境中大多采用Google提出的MapReduce分布式计算模式[7],将任务自动分成多个子任务,通过Map和Reduce两步实现任务在大规模计算节点中的调度与分配。大部分信息技术厂商提出的云计划中采用的编程模型,都是基于MapReduce的思想开发的编程工具。MapReduce特别适用于产生和处理大规模的数据集。其执行过程如图1所示。
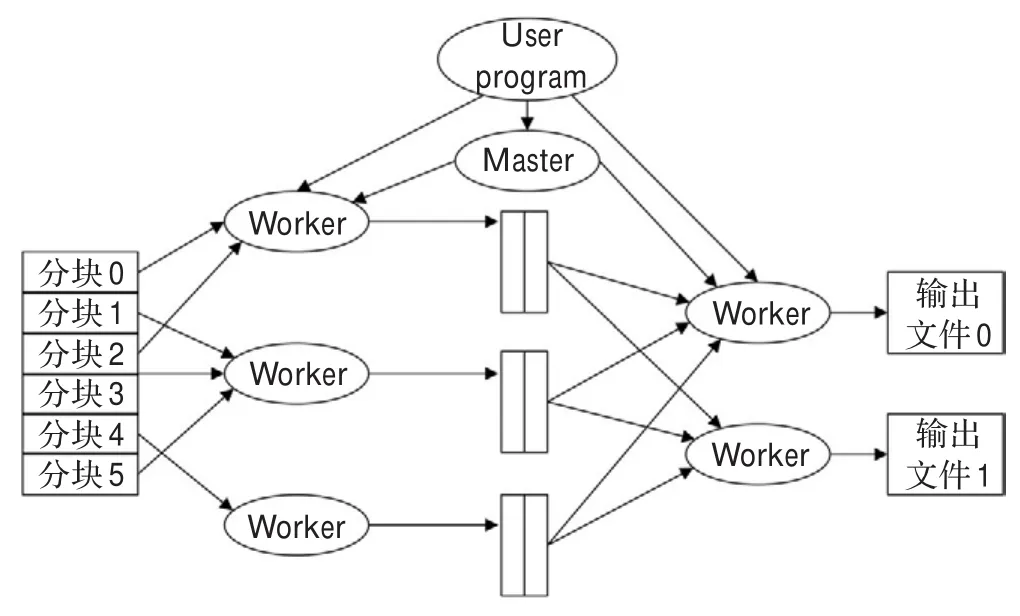
图1 MapReduce的具体执行过程
从图1可看出,MapReduce有7个过程,经总结可分为两个主要阶段:
(1)Map阶段:把一个较大的任务首先通过用户程序里的MapReduce库分割成M个片,每个片的大小一般16~64 MB。然后配给多个worker并行执行,输出处理后的中间文件。
(2)Reduce阶段:将Map阶段处理后的结果进行汇总分析,输出最后的处理结果:R个输出文件。
在MapReduce编程模型下,如何对众多的子任务进行调度是个复杂的问题。每个任务被细分成Map阶段的M片,Reduce阶段R片。M和R应当比worker机器的数量大许多,每个worker要执行许多不同的工作。如何对众多的任务进行调度,来达到资源的动态负载均衡,同时也要考虑响应时间,这是本文所要考虑的主要问题。本文依据云计算环境下调度模型的特点,提出一种适用于大规模并行处理系统的新的调度算法,即充分利用遗传算法的群体性、快速搜索能力,同时利用蚁群算法的正反馈性、并行性等优势,把这两种算法结合起来,以建立一个较优的分配调度策略。并通过仿真实验,验证应用遗传蚁群算法进行任务调度可以在减少任务总完成时间的同时,均衡系统负载,提高任务调度的效率。
2.2 有关概念的引入
首先,引入资源能见度的概念,即资源本身的属性。云计算系统的后台有成千上万的普通或高级的服务器,任务调度中心的调度器(或中间服务器)统计各个资源的属性信息,用来衡量资源节点的计算能力和通信能力,主要参数包括CPU的个数m及处理能力p(MIPS),另外还有其所处网络的带宽B(决定作业从分配到传送到节点所用时间)。同时还要引入一个负载平衡因子,它的数值采用资源的负载完成率,也就是已经完成的任务量和分配的任务量之比,计算公式为:Lr=La/Lf,其中Lγ表示负载完成率,La表示完成的任务量,Lf表示分配到的任务计算量之和。调度中心的调度器应不断地探测资源的负载及其任务的完成情况,以便对后续任务的分配产生积极的影响。每当有新任务完成后,任务完成率高的资源信息素增加一些,完成率低的信息素降低一些[8]。
通过资源能见度和负载平衡因子的引入,充分利用蚁群算法的正反馈优势,蚁群算法能更好地模拟云计算系统的实时负载情况。
3 遗传算法的优化机理与模型描述
遗传算法是由美国密执安大学的John Holland教授于1975年首先提出的一类仿生型优化算法,并行性和全局解空间搜索是GA的两个最显著特性。但是遗传算法对系统中的反馈信息利用不够,求解到一定范围时往往产生大量的冗余迭代,求解效率不高,不一定找到最优的分配方案[3,6]。
3.1 染色体编码与解码
染色体编码有很多种方式,可以采用直接编码,即直接对任务的执行状态编码,也可以采用间接编码。本文针对云计算环境下MapReduce编程模型的特点,采用任务-资源(task-worker)的间接编码方式[9],并用十进制实数编码。利用rand函数随机生成一定数量的十进制实数编码种群,每条染色体代表问题的一种解。假设有n个相互独立的任务(task),m个可用的资源(worker),染色体的长度为n+m,前n(1,2,…,n)个整数表示任务,n+1到n+m代表可用的资源(任一n+i对应可用资源i)。定义如下规则:队列中临近的任务被分配到右边最近的资源执行。
如假设n=5,m=3,以下一条染色体解释如下:
16237458:任务1分配给资源1执行,任务2,3分配给资源2执行,任务4,5分配给资源3执行。
之后就是对染色体进行解码,得到各个worker上的task分布情况,生成多组以资源编号的task序列,如将上述染色体16237458解码为:


3.2 遗传操作
3.2.1 适应度函数的选取

3.2.2 个体选择

3.2.3 交叉与变异操作
交叉:采用Davis提出的顺序交叉方法,先进行常规的双点交叉,再进行维持原有相对访问顺序的巡回路线修改。
变异:采用逆转变异方法。
交叉概率和变异概率分别为常数c1,c2,在实际操作中利用random生成r∈[0,1],若r小于交叉概率,则进行交叉操作,反之不然;同变异操作。如此进行,比较生成个体的适应度函数值,只有适应值有改进的才接受下来,否则操作皆为无效。经递归迭代数次,生成若干组优化解,为蚁群算法做准备。
4 遗传算法与蚁群算法的融合
蚁群算法(ant colony algorithm)是由意大利学者M.Dorigo等人于20世纪90年代初期通过模拟自然界中蚁群集体寻径的行为而提出的一种基于种群的启发式仿生进化算法,它又是一种全局优化方法,特别适合并行计算,而且具有正反馈机制,能模拟负载情况。缺点是初期信息素缺乏,导致搜索初期积累信息素占用的时间较长。研究表明,蚁群算法有60%以上的时间都是用在初期信息素的积累[10-11]。
4.1 遗传算法与蚁群算法衔接
遗传算法后期求解效率不高,容易造成大量的冗余迭代,故遗传算法与蚁群算法的衔接是一个难题,传统策略将遗传算法设置为运行固定的迭代次数,但过早或过晚结束都会影响算法的效果。为此本文借鉴了一种动态融合策略,确保遗传算法与蚁群算法在最佳时机融合。具体如下:
(1)设置最小遗传迭代次数Genemin和最大遗传迭代次数Genemax。
(2)在遗传迭代过程中统计子代群体的进化率,并以此设置子代群体最小进化率Genemin-impro-ratio。
(3)在设定的迭代次数范围内,如果连续Genedie代(Genemin≤Genedie≤Genemax),子代群体的进化率都小于Genemin-impro-ratio,说明这时遗传算法优化速度较低,因此可终止遗传算法过程,进入蚁群算法。
4.2 蚁群算法信息素的设置
真实蚁群通过在觅食路径上释放信息素(Pheromone)最终可以在蚁穴和食物之间找到一条最短路径,蚁群算法正是通过模拟真实蚁群的这一特征工作的。本文借鉴比利时学者Thomas Stutzle提出的MMAS(Max-Min Ant System)算法中信息素的设置[12]:
信息素的初值设为:τS=τC+τG,τC是一个根据具体求解问题规模给定的一个信息素常数,τG是遗传算法求解结果转换的信息素值。
4.2.1 遗传算法向信息素的转换
遗传算法求解结果向信息素值转换:选取遗传算法终止时种群中适应值最好的前10%个体作为遗传优化解集合,记为开始时,设置τG为0,对于中每个解,τG自加常数k(自设)。
4.2.2 确定资源选择概率
在t时刻,任务被分配到每个资源上去的概率可表示为:

其中η是资源的能见度,定义为η=amP+bB,a,b分别表示资源处理能力和带宽在资源能见度中所占的比重,α是信息素权重,β是资源能见度权重。
5 算法仿真结果
由于云计算的局部可以看作一个特殊的网格环境,所以本文采用Gridsim[13-15]网格仿真工具来模拟云计算的一个局部,以验证本算法在这种特殊网格环境下的运行情况。其中,采用遗传算法作为比较,设置初始参数如表1。
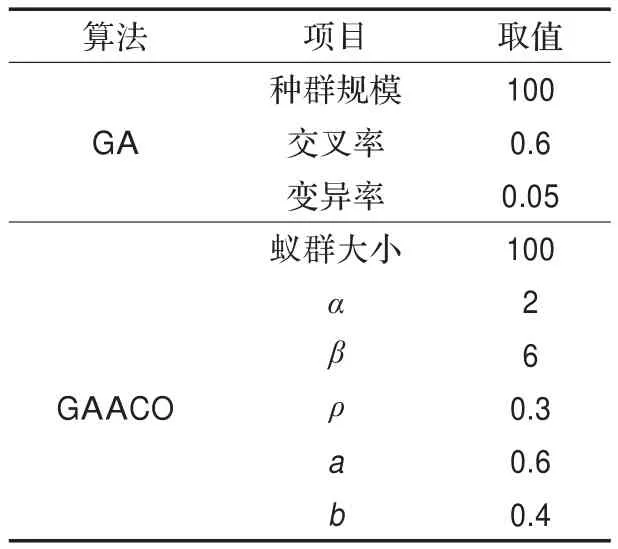
表1 两种算法的主要参数
遗传蚁群算法中各路径信息素初值τC设为60,遗传算法求解结果转换的信息素值是经过路径加2,Genemin为50,Genemax为200。
基于表1的设定,两种算法搜寻20%可用节点的仿真结果如下(显示的均为平均后的结果):


搜寻10%可用节点的仿真结果如下:
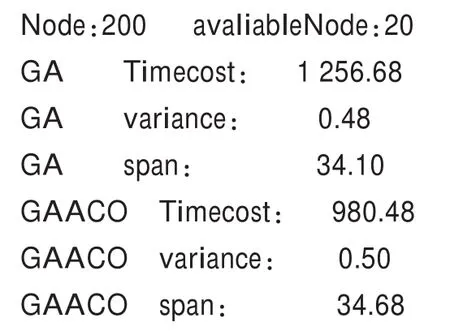
对比以上仿真结果发现,可用节点比率减小时,本算法更具优势,说明本算法在云计算中任务调度中的应用是正确的。
现改变算法的参数,参数设置如表2。

表2 两种算法的主要参数
再次执行搜寻10%可用节点的仿真,结果如下:
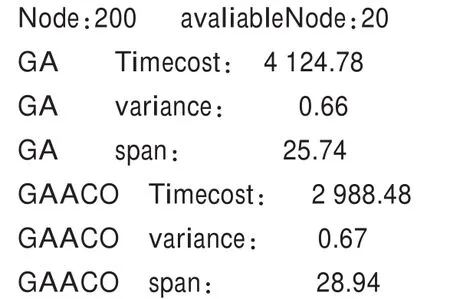
经对比发现,本算法在搜索规模扩大的情况下,优势较明显。
图2为基于表1设定的两种算法的模拟结果的连续曲线图。

图2 仿真结果曲线图
总结:云计算环境的特点之一即节点数多,而节点的失效是一种常态。经以上对比发现,本算法在节点多,而有效节点少时工作效率较高,所以是云计算环境下一种有效的调度算法。
6 结束语
本文提出了一种融合了遗传算法与蚁群算法的任务调度算法,该算法不但把任务完成时间作为一个重要的判断标准,而且也把资源的能见度及负载均衡作为直接的参考量。通过本算法可以实现云计算环境下有效的任务调度。
[1]房秉毅,张云勇,程莹.云计算国内外发展现状分析[J].电信科学,2010(S1):1-5.
[2]张为民,唐剑锋,罗治国,等.云计算:深刻改变未来[M].北京:科学出版社,2009.
[3]李建锋,彭舰.云计算环境下基于改进遗传算法的任务调度算法[J].计算机应用,2011,31(1):184-186.
[4]华夏渝,郑骏,胡文心.基于云计算环境的蚁群优化计算资源分配算法[J].华东师范大学学报,2010(1):127-134.
[5]范杰,彭舰,黎红友.基于蚁群算法的云计算需求弹性算法[J].计算机应用,2011,31(1):1-4.
[6]王静宇,谭跃生,陈振江.基于遗传蚁群混合算法的网格任务调度研究[J].计算机与信息技术,2008,9(3):53-55.
[7]周敏.MapReduce综述[D].广州:暨南大学信息科技学院,2008.
[8]魏东.基于混合蚁群算法的网格任务调度研究[D].哈尔滨:哈尔滨工程大学,2008.
[9]林剑柠,吴慧中.基于遗传算法的网格资源调度算法[J].计算机研究与发展,2004(12):2195-2199.
[10]田文洪,赵勇.云计算—资源调度管理[M].北京:国防工业出版社,2011.
[11]熊志辉,李思昆,陈吉华.遗传算法与蚂蚁算法动态融合的软硬件划分[J].软件学报,2005,16(4):503-511.
[12]丁建立,陈增强,袁著祉.遗传算法与蚂蚁算法的融合[J].计算机研究与发展,2003,40(9):1352-1356.
[13]The Clouds Lab.Gridsim[EB/OL].(2010-06-25).http:// www.cloudbus.org/gridsim.
[14]Foster I,Zhao Yong,Raicu I,et al.Cloud computing and grid computing 360 degree compared[C]//Proceedings of the 2008 Grid Computing Environments Workshop.Washington,DC:IEEE Computer Society,2008:1-10.
[15]Armbrust M,Fox A,Griffith R,et al.Above the clouds:a Berkeley view of cloud computing[EB/OL].(2010-01-25). http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-28.pdf.
ZHANG Yu,LI Fang,ZHOU Tao
College of Management,University of Shanghai for Science and Technology,Shanghai 200090,China
How to schedule masses of tasks efficiently is an important issue to be resolved in cloud computing environment.An algorithm combining Genetic Algorithm(GA)and Ant Colony algorithm(ACO)is brought up for the programming framework of cloud computing.In the algorithm,the GA adopts task-worker coding method,every chromosome representing a specific scheduling scheme,and chooses the average completing time of all tasks as its fitness function.Then the ACO adopts Genetic Algorithm to give initial information pheromone to distribute.This combination not only overcomes the slow speed of ACO caused by lack of information pheromone on the path early,but also takes full use of GA, that is fast-speed,randomly and global search.There is a contrast between GA and the combined algorithm through simulation experiment,and the result shows the proposed algorithm is efficient in the cloud computing environment.
cloud computing;ant colony algorithm;Genetic Algorithm(GA);task scheduling
A
TP301.6
10.3778/j.issn.1002-8331.1206-0039
ZHANG Yu,LI Fang,ZHOU Tao.Task scheduling algorithm based on genetic ant colony algorithm in cloud computing environment.Computer Engineering and Applications,2014,50(6):51-55.
上海市重点学科建设资助项目(No.S30504)。
张雨(1987—),女,硕士研究生,主要研究方向为科技管理、云计算;李芳(1966—),女,博士研究生,副教授,主要研究方向为工业工程、生产运作管理;周涛(1989—),男,硕士研究生,主要研究方向为工业工程、供应链管理。E-mail:zhangyu627253082@163.com
2012-06-04
2012-08-16
1002-8331(2014)06-0051-05
CNKI网络优先出版:2012-09-25,http://www.cnki.net/kcms/detail/11.2127.TP.20120925.1001.047.html
猜你喜欢
消费电子(2022年7期)2022-10-31
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
电子制作(2017年20期)2017-04-26
统计与决策(2017年2期)2017-03-20
智能系统学报(2015年4期)2015-12-27
信息通信技术(2015年6期)2015-12-26
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
