适用于智能传感器系统的SVM集成研究
2014-07-01 23:28卞桂龙沈海斌
传感器与微系统 2014年8期
卞桂龙, 丁 毅, 沈海斌
(1.浙江大学 超大规模集成电路设计研究所,浙江 杭州 310027;2.西湖电子集团有限公司,浙江 杭州 310012)
适用于智能传感器系统的SVM集成研究
卞桂龙1, 丁 毅2, 沈海斌1
(1.浙江大学 超大规模集成电路设计研究所,浙江 杭州 310027;2.西湖电子集团有限公司,浙江 杭州 310012)
以支持向量机(SVM)为代表的人工智能技术在智能传感器系统中得到了广泛的应用,但传统的SVM有“灾难性遗忘”现象,即会遗忘以前学过的知识,并且不能增量学习新的数据,这已无法满足智能传感器系统实时性的要求。而Learn++算法能够增量地学习新来的数据,即使新来数据属于新的类,也不会遗忘已经学习到的旧知识。为了解决上述问题,提出了一种基于壳向量算法的Learn++集成方法。实验结果表明:该算法不但具有增量学习的能力,而且在保证分类精度的同时,提高了训练速度,减小了存储规模,可以满足当下智能传感器系统在线学习的需求。
传感器; 支持向量机; 壳向量; Learn++算法; 增量学习
0 引 言
随着科学技术的发展,传感技术得到了迅猛发展,无论是工业领域还是日常生活,都应用到了各式各样的传感器。传感器是自动控制系统和智能控制系统的重要器件,自动化和智能化的水平越高,对传感器的依赖程度也就越高,但传统的传感器在性能、可靠性和稳定性等方面的瓶颈已经越发不能满足工业生产技术进一步的需求。在20世纪末逐渐成熟起来的以支持向量机(support vector machine,SVM)为代表的人工智能技术为新一代的智能传感器的发展指明了方向。Vapnik等人根据统计学理论提出的SVM学习方法[1],近年来受到了国内外学术界的广泛重视,并且已经广泛应用于智能传感器系统。如同其他分类器,SVM的性能和精度依赖于训练数据集是否具有典型性。但在现实应用中,获取这样典型的数据集往往代价昂贵并且费时,因此,得到的数据集通常都是来自不同时间段的小的分批量的数据集。在这种情况下,典型做法是利用新的数据集和先前所有的数据集,重新训练一个新的分类器。换句话说,重新训练的分类器在从新数据那学习新知识时也不能忘记从先前数据那获取的旧知识。但是,学习新知识同时也不能遗忘先前所学过的知识,就会带来“稳定性/可塑性(stability/plasticity)”困境。性能完全稳定的分类器可以保留旧知识,但不能学习新知识,而性能完全可塑的分类器可即时学习新知识,但不能保留以前的知识。目前普遍做法是丢弃现有分类器,将旧数据集和新数据集汇总,利用汇总后的数据集训练一个新的分类器,但是,这种做法就会带来“灾难性遗忘(catastrophic forgetting)”[2]问题,即SVM在保留已有知识的基础上无法再学习新类,这就会影响智能传感器系统的稳定性。
解决上述问题最好的方法是增量学习。增量学习[3~5]是指在新数据可用之时,系统能够在已有知识的基础上进行学习,从而快速地获取新知识并且不丢失已有的有用知识。Learn++算法是由国外学者Polikar R[6]提出的一种用于解决分类问题和监督学习的集成式增量学习算法。它能够增量地学习新来的数据,即使新来数据属于新的类,也不会忘记已经学习到的旧知识,较好地解决了“稳定性/可塑性”难题。
SVM本质是根据训练样本集构造出最优分类超平面,使得样本集可以被该超平面尽可能正确地分开,并使离超平面最近的向量与超平面之间的距离最大,因此,SVM是无法进行增量学习的,这种特性显然是不满足智能传感器系统实时性要求。其次,SVM是性能稳定的分类器,有“灾难性遗忘”现象。对于上述问题,国内外学者提出了各种方法用于SVM的增量学习[7~9]。与此同时,不少文献提出利用分类器集成来实现对SVM分类性能和精度的进一步改进,如Boosting算法和Bagging算法[10~12]。
本文对SVM基分类器采用了Learn++集成,使得集成后的SVM分类器具有增量学习能力,满足了智能传感器系统的实时性和稳定性。其次,为了提高SVM集成的训练速度,把壳向量引入到基分类器SVM的训练过程中,即将壳向量集作为新的训练样本集,不但提高了智能传感器系统的响应速度,而且也减小了智能传感器系统的存储规模。
1 壳向量
1.1 壳向量简介
SVM的训练速度主要是由训练样本数量决定的,样本数量越多,其训练速度也就越慢。事实上,训练样本集中通常只有很少一部分可能成为支持向量,大多数训练样本都无法成为支持向量,然而这些样本却占用了大部分的训练时间。所以,如果能够只对那些最有可能成为支持向量的训练样本进行训练,不仅可以提高训练速度,而且大大减小了训练样本集规模,并且对算法的性能也无太大影响。
训练样本集的凸壳是指包含某一类训练样本集的最小凸集(一般为多面体),而壳向量则是该训练样本集的凸顶点[13]。壳向量包含了所有的支持向量,而并非所有的壳向量都是支持向量,但支持向量一定是壳向量。如图1所示, □和○均是训练样本集L不同类别的壳向量,支持向量是在壳向量中产生的,不可能是样本集凸壳内部的样本点。所以,只要求得壳向量集,并在此样本集上进行SVM训练,就可大大缩短训练时间。
对于一个二分类问题,求取壳向量的算法步骤如下:
设有训练样本集L(分L+和L-两类)。
1)训练样本集有线性可分和线性不可分2种情况。若训练样本集为线性可分,则直接跳转到步骤(2);若训练样本集为线性不可分,则通过核函数将其映射到一个线性可分的特征空间;

3)在此样本集上进行SVM的训练,得到SVMVH,并以此构造出最优决策函数。
1.2 壳向量分析
设有训练样本集L,维数为k,样本个数为n,则其壳向量个数mk和样本数n之间关系如下[15]:
1)当n→∞ 时,k维球体中均匀独立地随机分布n个点,其壳向量个数mk为O(n(k-1)/(k+1));
2)当n→∞ 时,若训练样本集是呈k维正态分布的,那么,壳向量个数mk为O((logn)(k-1)/2) ;
3)当n→∞ 时,若k维空间中的n个样本点是独立地从任意连续分布的集合中随机选取的,那么,壳向量个数mk为O((logn)k-1)。
2 基于壳向量的Learn++集成
Learn++算法[6]是一种基于Boosting思想的集成式增量学习算法,它有效地克服了传统分类算法难以避免的“灾难性遗忘”问题。当有新的样本集加入时,该算法会生成新的基分类器,而最终决策则是利用权重投票方式由所有集成分类器共同完成。为了更好地适应于增量学习,Learn++算法在训练单个基分类器时,更新样本权重和赋予分类器权值中使用的都是整个集成分类器的加权预测错误,而不是采用当前基分类器的预测错误。其次Learn++算法在训练样本集上引入了一定的随机性,从而间接地提高了基分类器的多样性,使得它不必依赖于特定的基分类器算法。这也就意味着本身不支持增量学习的基分类器可以通过Learn++集成具备增量学习的能力,如SVM。
基于壳向量的Learn++集成是基于以下思路:Learn++算法将初始训练样本集D分成了K个训练样本子集S(k),根据权重分布Dt从当前训练样本子集S(k)中随机选择训练集TRt和测试集TEt。利用Qhull算法求取训练集TRt的壳向量集TRtHV,并将其作为新的样本集来训练SVM。每个训练样本集S(k)产生Tk个SVM基分类器,最后将所有的SVM基分类器通过权重投票的方式获得最终集成的SVM。对于一个二分类问题,基于壳向量的Learn++集成方法步骤如下:
输入:
将初始训练样本集D分成K个训练样本子集S(k),其中,k=1,2,…,K。每个训练样本子集包含m个训练样本,S(k) = [(x1,y1),(x2,y2),……,(xm,ym)];
基分类器SVM;
每个训练样本子集S(k)对应的迭代次数Tk。
训练阶段:
fork=1toKdo
将每个训练样本的权值进行初始化,权值w1(i)=D1(i)=1/m,i= 1,2,…,m。其中,w1(i)代表样本i的权重,m代表样本集的样本数量。
fort=1toTkdo


3)在训练集TRtHV上训练基分类器SVM,并得到假设(分类器)ht:X→Y;
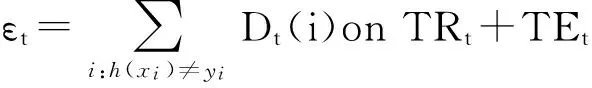

6)设Bt=Et/(1-Et),修改训练样本集中样本的权值
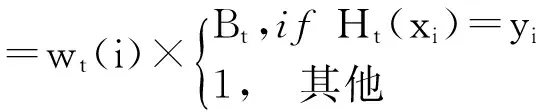
通过以上算法步骤流程可知,对于有着高错误率的样本,从严格意义上来说可能是属于新类或者之前一直未曾用来训练基分类器。这些被错分的样本有着很高的权值,在下次循环和所有之后的循环中,会有很高的可能性被重新取样。而获取的新基分类器都是建立在这些重新加权过的样本集上,并且这些新基分类器也会更专注于对这些错分的样本进行正确分类,然后再根据这些新基分类器的分类结果相应地增加或者减小这些样本的权值。所以,利用Learn++算法集成后的SVM分类器可以有效地进行增量学习,避免了“灾难性遗忘”现象的产生。
3 实验与分析
3.1 实验数据设置
1)UCI数据库中的Iris数据集有150个样本,分三类,将Setosa类作为正类,其它两类作为负类。随机选取120个样本作为训练集,剩余的30个样本作为测试集。
2)UCI数据库中的Bupa数据集有345个样本,共两类。随机选取294个样本作为训练集,剩余的51个样本作为测试集。
3)UCI数据库中的Balance-scale数据集有625个样本,分三类,将Left类作为正类,其他类作为负类。随机选取510个样本作为训练集,剩余的125个样本作为测试集。
为了验证本文所提算法的可行性和有效性,将训练集随机平均分成3个训练样本子集,其中,Iris3组样本子集数目为40,40,40;Bupa3组样本子集数目为98,98,98;Balance3组样本子集数目为190,190,190。第1组训练样本子集作为初始样本集,其余2组分别作为新增样本集,每次增量学习完成后用测试集来检验分类性能。所有的实验都是在酷睿双核 (1.5GHz),2G内存,Matlab2012b的环境下进行的。
3.2 实验结果
为了进行比较,对3种不同的算法进行了仿真实验。算法1采用标准的SVM方法,即利用所有的样本进行SVM训练,没有增量学习的过程,记为SVM;算法2是直接对SVM基分类器采用Learn++集成,记为LSVM;算法3则是本文所提的基于壳向量的SVM集成方法,记为QLSVM。算法2和算法3的增量学习的过程分别记为LSVM(1),LSVM(2),LSVM(3)和QLSVM(1),QLSVM(2),QLSVM(3),其集成规模均设为4。3种算法各实验10次取平均值,结果如表1和表2所示。

表1 3种算法性能对比Tab 1 Comparison of performance of three kinds of algorithms
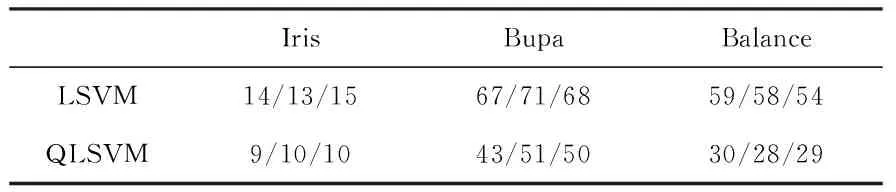
表2 LSVM和QLSVM支持向量总数对比Tab 2 Comparison of total numbers of LSVM and QLSVM
从表1可以看出:1)随着增量学习的不断深入,LSVM和QLSVM的分类精度均能得到明显地提高,有效地证明了采用Learn++算法集成的SVM基分类器具有增量学习的能力。2) LSVM在完成所有增量学习的过程后其分类精度均优于标准的SVM方法,说明采用Learn++集成的SVM基分类器可以通过对训练样本集的改变来间接地提高基分类器的多样性,从而起到改善集成分类器分类精度的作用。3) QLSVM的分类精度依赖于样本集的分布,对于Iris数据集和Bupa数据集,LSVM和QLSVM的分类精度相当;对于Balance数据集,QLSVM的分类精度则有所下降。
从表2可以看出:QLSVM支持向量总数比LSVM减少了20 %~30 %左右,因此,在分类精度相当的情况下其分类决策速度更快,不但加快了训练速度而且也缩小了训练集规模。因此,本文提出的方法是非常有效的。
4 结 论
本文将SVM基分类器利用Learn++算法进行集成,使得集成后的SVM分类器具有增量学习的能力,避免了“灾难性遗忘”现象的产生,满足了智能传感器系统的稳定性和实时性需求。同时将壳向量引入到SVM基分类器的训练过程,在精度相当的情况下,大大提高了集成训练与分类速度,不但减小了其在智能传感器系统的存储规模,而且也提高了系统的响应速度。另一方面,在增量学习的过程中,Learn++集成分类器规模是不断增大的,但集成分类精度并不会一直随着基分类器数目的增加而提高,这就牵涉到选择性集成的问题,关于这方面还需以后的进一步研究。
[1] 张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-42.
[2] French R M. Catastrophic forgetting in connectionist networks[J].Trends in Cognitive Sciences,1999,3(4):128-135.
[3] Giraud-Carrier C.A note on the utility of incremental learning[J].AI Communications,2000,13(4):215-223.
[4] Bouchachia A,Gabrys B,Sahel Z.Overview of some incremental learning algorithms[C]∥2007 IEEE International Fuzzy Systems Conference,IEEE,2007:1-6.
[5] Godin R,Missaoui R.An incremental concept formation approach for learning from databases[J].Theoretical Computer Science,1994,133(2):387-419.
[6] Polikar R,Upda L,Upda S S,et al.Learn++:An incremental learning algorithm for supervised neural networks[J].IEEE Transactions on Systems,Man,and Cybernetics,Part C:Applications and Reviews,2001,31(4):497-508.
[7] 萧 嵘,王继成,孙正兴,等.一种 SVM 增量学习算法[J].南京大学学报:自然科学版,2002,38(2):152-157.
[8] Xiao R,Wang J,Zhang F.An approach to incremental SVM learning algorithm[C]∥Proceedings of 2000 12th IEEE International Conference on Tools with Artificial Intelligence,ICTAI 2000.IEEE,2000:268-273.
[9] 吴崇明,王晓丹,白冬婴,等.基于类边界壳向量的快速 SVM 增量学习算法[J].计算机工程与应用,2010,46(23):185-187.
[10] Valentini G,Muselli M,Ruffino F.Bagged ensembles of support vector machines for gene expression data analysis[C]∥Procee-dings of the International Joint Conference on Neural Networks, IEEE,2003:1844-1849.
[11] Valentini G,Muselli M,Ruffino F.Cancer recognition with bagged ensembles of support vector machines[J].Neurocompu-ting,2004,56:461-466.
[12] Pavlov D,Mao J,Dom B.Scaling-up support vector machines using boosting algorithm[C]∥Proceedings of 2000 15th International Conference on Pattern Recognition,IEEE,2000:219-222.
[13] 薛贞霞,刘三阳,齐小刚.基于壳向量和中心向量的支持向量机[J].数据采集与处理,2009,24(3):328-334.
[14] Barber C B,Dobkin D P,Huhdanpaa H.The quickhull algorithm for convex hulls[J].ACM Transactions on Mathematical Software (TOMS),1996,22(4):469-483.
[15] 李东晖,杜树新,吴铁军.基于壳向量的线性支持向量机快速增量学习算法[J].浙江大学学报:工学版,2006,40(2):202-206.
[16] 张宏达,王晓丹,白冬婴,等.一种基于凸壳算法的SVM集成方法[J].计算机工程,2008,34(17):28-30.
Research on SVM integration for intelligent sensor system
BIAN Gui-long1, DING Yi2, SHEN Hai-bin1
(1.Institute of VLSI Design,Zhejiang University,Hangzhou 310027,China;2.Westlake Electronics Group Company Limited,Hangzhou 310012,China)
Support vector machine (SVM) as the representative of artificial intelligent techniques has been widely used in the intelligent sensor system,however,traditional SVM suffers from the catastrophic forgetting phenomenon,which results in loss of previously learned information,so it is unable to meet the requirements of real-time intelligent sensor system.The strength of Learn++ lies in its ability to learn new data without forgetting previously acquired knowledge,even when the new data introduce new classes.In order to solve the above problem,a Learn++ integration method based on hull vectors is proposed.Experimental results show that the algorithm not only has the ability of incremental learning,improve training speed and reduce the storage size,but also can ensure the classification precision,which meets the current demand of intelligent sensor systems for online learning.
sensor; support vector machine(SVM); hull vector; Learn++ algorithm; incremental learning
10.13873/J.1000—9787(2014)08—0044—04
2014—01—06
TP 212;TP 18
A
1000—9787(2014)08—0044—04
卞桂龙(1988-),男,江苏泰州人,硕士研究生,研究方向为智能安全与芯片设计。
猜你喜欢
当代陕西(2022年6期)2022-04-19
科技创新与应用(2020年6期)2020-02-29
中学生数理化·中考版(2019年9期)2019-11-25
计算机应用(2017年4期)2017-06-27
北京理工大学学报(2016年6期)2016-11-22
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
电信科学(2016年9期)2016-06-15