
基于Lucene的全文检索管理系统设计与实现
2014-06-27 05:48:29何萍成都信息工程学院图书馆四川成都610225
长江大学学报(自科版) 2014年22期
何萍 (成都信息工程学院图书馆,四川成都 610225)
李凡 (成都信息工程学院计算机学院,四川成都 610225)
基于Lucene的全文检索管理系统设计与实现
何萍 (成都信息工程学院图书馆,四川成都 610225)
李凡 (成都信息工程学院计算机学院,四川成都 610225)
全文检索是各种信息系统实现对各种繁多的电子文档进行分析处理的基础,而依赖于数据库的全文检索功能存在许多局限性。Lucene是一种基于纯Java技术的轻量级的文本索引和查询引擎,几乎适合于任何需要全文检索的应用。设计了一个基于Lucene技术的全文检索管理系统(id XMS)。全文检索管理系统(id XMS)采用纯Java技术实现,以Lucene作为核心引擎,总体上分为8个功能模块,分别是系统管理器、索引管理器、查询管理器、文档解析器管理器、配置管理器、优化器管理器、I/O模块和Lucene全文检索引擎。
全文检索管理系统(id XMS);Lucene;Java技术
随着信息技术的发展,各式各样的电子文档取代了原来的纸制文献,用户面对海量的数据,如何更好、更准确的抓住所需信息,已经成为一道难题。随着全文检索技术的诞生,在一定程度上解决了这一问题。全文检索技术能对各种文档的信息进行提取,创建快速查询索引,是实现对文档的快速查找,对信息进一步提炼加工的基础设施。因此,全文检索技术已被广泛的应用在信息系统中。然而,许多信息系统虽使用全文检索技术,但没有提供独立的全文检索模块,而是完全依赖于数据库提供的全文检索能力或SQL查询能力,这必然导致以下几点问题:应用与特定数据库邦定;增加了数据库的查询负载,可能引起整体性能的大幅下降;不利于数据在不同数据库产品间移植;系统全文检索模块没有组件化,与其他模块间无法达到松散耦合。所以,建立一个独立的组件式的高效稳定的全文检索模块或全文检索服务系统已经成为新趋势。要设计如此的管理系统,Lucene技术的使用是必须的。Lucene是一个高性能、纯Java的全文检索引擎,而且免费、开源[1]。Lucene是Apache开源组织著名的开源项目,目前已得到广泛的使用和测试,具有良好的性能和可靠的稳定性。为此,笔者开发设计了一个以Lucene作为核心引擎的全文检索管理系统(id XMS)。
1 系统设计
全文检索管理系统(id XMS)采用纯Java技术[2-3]实现,以Lucene作为核心引擎,总体上分为8个功能模块,分别是系统管理器、索引管理器、查询管理器、文档解析器管理器、配置管理器、优化器管理器、I/O模块和Lucene全文检索引擎(见图1)。系统既可作为独立服务器提供全文检索服务,又能作为独立组件集成到其他信息系统当中。
此外,系统除了提供最基本的文本检索和查询功能,还具有以下功能:能对WORD、PDF、RTF、HTML等多种格式的文档建立索引,并可通过新增自定义的文档解析器来支持自定义文档;能建立并维护多个文档索引目录;支持文件系统、数据库或网络等多种索引存储方式;能定时自动合并优化索引,提高系统检索性能;系统配置基于XML,简单易维护。
2 系统的功能模块
2.1 Lucene全文检索引擎
Lu c e n e全文检索引擎是整个系统的核心组成部分。Lu c e n e中的索引(I n d e x)对象有多个文档(Do c ume n t)对象,每个文档对象又包含多个域(Field)对象,每个域对象又包含众多的单词(Term)对象。文档对象就表示一个实际要处理的文档(如一个PDF文档),为了提高查询效率,Lucene采用增量更新。一个新增的文档成为一个子索引,称为“段”,当子索引达到一定数量后就要合并这些子索引以提高整体查询效率,这一工作主要靠优化器对象(Optimizer)来完成。文档中的“域”可以看作关系数据库表的“字段”,Lucene中的域分为“Keyword”、“UnIndex”、“UnStored”、“Text”4种类型,Keyword类型用于表示短文本对象,如标题等;UnIndex类型用于表示不需要进行索引的对象;UnStored类型用于表示需要进行索引而不需要保存全文的大文本对象,如正文等;Text类型用于表示既需要索引又需要在索引中保存全文的大文本对象,如摘要等;通过以上分析,在设计该系统时为每个文档都预建了一组域。
在设计的整个系统中Lucene引擎主要具有以下功能:由配置管理器调用,在解析配置文件过程中创建新的索引;由索引管理器调用,新增或删除指定索引中的文档;由查询管理器调用,在指定的索引查询文档;由优化器调用,合并指定索引中的子索引。
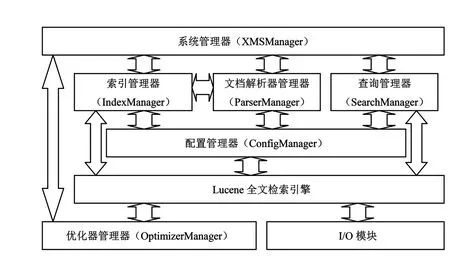
图1 系统主要组成模块
2.2 系统管理器
为了提供统一的用户接口,在设计本系统时采用了设计模式中的正面(Facade)模式,其他管理器模块由系统管理器类(XMSManager)控制和协调,系统管理器类本身采用了单实例(Singleton)模式[4]。系统管理器提供的API主要可分为以下几类:
1)索引操作 获取索引类别名称集合:getIndex Names(…);判断指定的索引是否存在:indexExists (…);获取指定索引中的文档数:getIndex NumDoc(…);优化指定的索引:optimizeIndex(…)。
2)文档操作 在指定的索引中添加文档:add Document(…);在指定的索引中删除文档:removeDocument(…)。
3)查询操作 获取指定索引中的所有文档:search All(…);在指定索引中进行查询:search (…);在指定索引的日期型域中进行查询:searchDate(…);在指定索引的日期型域中进行日期范围查询:search DateRange(…)。
4)系统监视器操作 启动查询池监视器:startSPMonitor(…);停止查询池监视器:stopSPMonitor (…);判断查询池监视器是否启动:isSPMStarted(…);启动连接池监视器:startCPMonitor(…);停止连接池监视器:stop CPMonitor(…);判断连接池监视器是否启动:isCPMStarted(…)。
5)索引优化器操作 启动自动优化器:startOptimizer(…);停止自动优化器:stop Optimizer(…)。
2.3 配置管理器
系统的配置管理器类(Config Manager)主要负责在系统启动时解析配置XML文件,提供系统各模块的初始化信息,同时在系统运行过程中负责提供Lucene引擎的Index Writer和Index Reader对象实例。为了保证数据的一致性,配置管理器类采用单实例(Singleton)模式(见图2)。
2.4 索引管理器
系统的索引管理器类(Index Manager)主要负责对指定索引的具体操作,包括增删文档、优化索引、获取索引相关信息(如最大文档数、当前文档数、索引域名集合、索引单词集合等)等。索引管理器类采用单实例(Singleton)模式,向系统管理器提供服务。
2.5 查询管理器
系统的查询管理器类(Search Mananger)是系统管理器中查询功能的最终实现者,能提供针对单词、短语(多个单词)、前缀(prefix)、模糊(fuzzy)、通配符(wildcard)和日期等多种方式的查询。由于查询是比较耗费系统资源的操作,为了灵活的限制查询操作消耗的资源总量,系统使用了查询对象池,可通过配置XML文件中的<pool>元素的属性来设置池中的最大活动实例数(max Active)、最大空闲实例数(maxIdle)和最大等待请求数(max Wait)。

图2 系统各模块包和类结构图
2.6 文档解析器管理器
系统的文档解析器管理器类(Paser Manager)负责管理解析各种类型文档的解析器基类(DocParser)的子类对象。系统已预建了WORDParser、PDFParser、RTFParser、HTMLParser等子类,分别用于解析Office Word文档、Adobe PDF文档、RTF文档和HTML文档,从中提取标题、作者、正文、创建时间等文本(如无相应的内容则可为空)。在设计系统时,为了便于自定义扩展新的文档解析器,采用了设计模式中的模版方法(Template Method)模式[4]。
2.7 优化器管理器
系统的优化器管理器类(Optimizer Manager)是系统管理器中优化器相关功能的最终实现者。由于引擎采用了增量更新方式,在一定时间内会存在多个子索引,如果子索引数量过多就会大大影响系统的查询效率,所以必须不断进行合并子索引(优化)的操作,但是在合并子索引过程中索引处于写保护和读保护状态,使系统无法提供服务,因此构建了优化器(Optimizer)以守护线程的方式对索引进行定时优化(见图2)。
2.8 I/O模块
系统扩展了Lucene的I/O模块,使索引可以直接将索引存储于指定数据库中。为了便于扩展支持其他数据库,采用了模版方法(Template Method)模式和工厂(Factory)模式[5],抽象基类DBDirectory继承了Lucene的I/O模块中的抽象类Directory(对目录的抽象),而要支持其它数据库,需继承DBDirectory实现其中的抽象方法,同时继承Lucene的I/O模块中的抽象类InputStream和OutputStream,并提供2个输入输出子类。
3 系统的配置文件
系统采用了基于XML的配置文件,下面给出配置文件的部分文档类型定义(DTD):


4 系统应用与实现
基于Lucene引擎的全文检索管理系统(id XMS)在Web上的应用,基本用户查询界面如图3所示。
5 结语
基于Lucene引擎的全文检索管理系统(id XMS)具有独立的组件式的高效稳定的全文检索模块。因此使用Lucene技术来构建一个信息管理系统将大大提高系统中文查询效率,这也是全文检索管理系统的研究重点。

图3 Web XMS查询界面
[1]Otis Gospodnetic.Advanced Text Indexing with Lucene[EB/OL].http://www.onjava.com/pub/a/onjava/2003/03/05/ lucene.html,2003-03-05.
[2]Scott Oaks,Henry Wong.Java Threads[M].OReilly&Associates,1999.
[3]Doug Lea.Concurrent Programming in Java:Design Principles and Patterns Second Edition[M].Addison Wesley Longman,Inc, 1999.
[4]Gamma E,Helm R,Johnson R,et al.Design Patterns:Elements of Reusable Object-Oriented Software[M].Addison Wesley Longman, Inc,1994.
[5]车东.基于Java的全文索引引擎Lucene简介[EB/OL].http://www.chedong.com/tech/lucene.html,2014-08-25.
[编辑] 张涛
TP391
A
1673-1409(2014)22-0035-04
2014-04-02
何萍(1979),女,硕士,馆员,现主要从事图书馆信息化建设和数字图书馆等方面的研究工作。
猜你喜欢
电脑爱好者(2020年10期)2020-07-28 17:10:30
数码世界(2018年2期)2018-12-21 21:23:46
商周刊(2017年22期)2017-11-09 05:08:31
现代计算机(2016年27期)2016-10-29 01:52:32
河南电力(2015年5期)2015-06-08 06:01:46
皖西学院学报(2015年5期)2015-02-28 17:52:46
电子设计工程(2015年12期)2015-02-27 12:06:09
东莞理工学院学报(2014年3期)2014-07-12 13:21:36
电脑迷(2014年2期)2014-04-29 19:21:13
阜阳职业技术学院学报(2013年3期)2013-04-29 13:40:50
