
MapReduce模型下的模糊C均值算法研究
2014-06-07 05:53王永贵李鸿绪
计算机工程 2014年10期
王永贵,李鸿绪,宋 晓
(辽宁工程技术大学软件学院,辽宁葫芦岛125105)
MapReduce模型下的模糊C均值算法研究
王永贵,李鸿绪,宋 晓
(辽宁工程技术大学软件学院,辽宁葫芦岛125105)
针对模糊C均值算法需要不断迭代来计算样本数据的隶属度值以及聚类中心的特点,利用MapReduce模型解决海量数据下的模糊C均值问题,进而提出高效的模糊C均值算法。在Map阶段和Reduce阶段分别完成隶属度和聚类中心的计算,每次迭代都需要启动一次完整的MapReduce执行过程。通过多次迭代计算出隶属度值以及聚类中心,并更新聚类中心文件,供下一轮作业使用,重复执行这一过程直至得到最终聚类结果。实验结果表明,该算法能够有效减少MapReduce计算过程中的迭代次数,从而提高整体执行效率。
模糊C均值算法;MapReduce模型;海量数据;高效;迭代
1 概述
模糊均值C(Fuzzy C-means,FCM)算法是由Dunn最先提出的,随后被广泛应用于数据挖掘等领域。模糊C均值算法是聚类分析和模糊理论的结合体,聚类分析是对原有数据按照某种规律来进行数据分类的一个过程,模糊理论是进行描述和分析人类语言的模棱两可的理论。模糊C均值在处理少量维度低的数据时是有效的[1],但是在处理大量的高维度数据时,不能够在有效的时间内计算出聚类结果[2]。随着网络信息技术的发展,人们可以采集并利用的数据越来越多,因此,如何处理海量数据下的模糊C均值是迫切需要解决的问题。Google提出的MapReduce[3]并行编程框架,在处理海量数据问题上具有显著的优势[4],该模型具有良好的扩展性及容错性[5],能够满足人们对海量数据处理的需要[6],在大数据处理中起着重要的作用[7]。Apache推出的Hadoop平台[8]实现了MapReduce模型,其将Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)和MapReduce模型有效的结合为大数据处理提供了方便的平台[9],并且该平台得到了广泛的推广和应用[10]。因此,可以通过改进传统的模糊C均值算法,使其适应MapReduce并行编程模型,从而能够有效地解决海量数据下的模糊C均值问题。文献[1]中针对模糊C均值算法需要不断迭代来计算样本数据的隶属度值以及聚类中心的特点,提出了利用MapReduce模型来解决海量数据下的模糊C均值问题,Map阶段完成隶属度的计算, Reduce阶段完成聚类中心的计算,每一次迭代需要启动一次MapReduce执行过程。
本文针对文献[1]中提出的MapReduce模型下的模糊均值C算法进行改进,使其减少MapReduce计算过程中的迭代次数,提高算法的整体执行效率。
2 模糊C均值算法
模糊均值C算法:{di,i=1,2,…,n}作为原始数据样本的集合[11],其中,di为第i个样本数据;n代表原始数据样本的总个数,n≥2;聚类类别个数c, 2≤c≤n;{li,i=1,2,…,n}是聚类中心集合,li为第i个聚类中心的值,n≥1;χj(di)代表第i个样本数据对于第j类隶属度的函数[12];Tf为聚类损失函数,可通过隶属度函数表示为:

其中,m>1是一个常数,控制聚类结果的模糊程度。
最小化式(1)得到的损失函数与隶属度函数的定义有密切关系,不同的隶属度函数定义会得到不同的损失函数。模糊C均值要求样本数据对于每个聚类中心的隶属度值的和为1,表示为:

通过式(1)与式(2)结合求损失函数的极小值,令Tf对li和χj(di)的偏导数为0,可得必要条件如下:

模糊C均值算法的核心是用迭代的方式求解式(3)和式(4),具体步骤如下[13]:
步骤1 初始化聚类中心个数c和模糊程度常数m;
步骤2 初始化聚类中心li和迭代停止阈值ε;
步骤3 将当前的聚类中心带入式(4)求得隶属度值;
步骤4 将当前的隶属度值带入式(3)计算并更新的聚类中心,若计算得到的隶属度值稳定,相邻的2次隶属度值之差小于ε则停止迭代,算法结束,否则,返回步骤3继续执行。
3 MapReduce模型
MapReduce是目前较为流行的用于大数据处理的并行编程模型,Hadoop开源平台实现了这一模型,并得到了广泛应用[14]。图1为 MapReduce模型,模型中包含了1个Master节点和若干个Slave节点,其中,Master节点负责控制及调度MapReduce的整个运作流程;Master节点根据用户提出的需求,将任务分配给Slave节点。Slave节点分为2个主要的执行过程,分别是Map阶段和Reduce阶段,Slave节点接收到任务后,首先读取原始数据,原始数据被划分为若干个数据分片,并最终以<key,value>键值对的形式由Map函数读入,Map函数通过预设的函数来处理输入数据,同样产生<key,value>键值对形式的输出,供Reduce阶段使用,Reduce函数接收到Map的中间结果后,将最终处理得到的结果输出。Slave节点在执行任务的过程中会不断地与Master节点进行交互,Master节点则根据当前系统的运行状况来调节各个Slave节点,使得任务能够顺利完成。关于MapReduce的研究目前主要在MapReduce模型的改进和通过MapReduce模型处理具体问题这2个方面,文献[15]提出了Hadoop++,通过改进自定义函数来提高MapReduce的性能。文献[16]提出HaLoop,该版本是对Hadoop的改进,使其能有效地处理迭代的问题。尽管MapReduce已经成为热点研究对象,但是有关利用MapReduce框架处理具体问题,还有待于继续学习和探讨。

图1 MapReduce模型
4 MapReduce模型下的模糊C均值算法
高效迭代模糊C均值算法的原理为:模糊均值C算法要求多次迭代计算出隶属度值以及聚类中心,因此每一次迭代需要一个完整的MapReduce计算过程来实现,Map读取待分类的数据以及各个聚类中心的值,Map任务根据读入的带分类数据以及各个聚类中心,计算出新的隶属度值,并通过该隶属度值计算出新的聚类中心值,将新的聚类中心值更新到聚类中心文件中,当其他Map任务进行计算时,直接读取更新后的聚类中心文件,当所有Map任务完成计算后,将隶属度值作为输出结果传递给Reduce任务,Reduce任务根据待分类的数据以及Map输出的隶属度值,计算出新的聚类中心,并更新到聚类中心文件,供下一轮作业使用,重复执行这一过程直到得到最后的聚类结果。
图2描述了高效迭代模糊C均值算法的基本原理。

图2 高效迭代模糊C均值算法流程
4.1 Map阶段的设计
Map阶段具体设计如下:
步骤1 Map函数以待分类数据集合DATA_LIST作为输入,形式为(key,value),其中,key为数据的行偏移量;value为行记录,并读取聚类中心集合CLUSTER_LIST,Map函数根据集合DATA_LIST和CLUSTER_LIST按照式(4)计算出点的隶属度值,并做好相应的类别标记。
步骤2 判断新计算出的中心与当前的聚类中心之间的差值是否小于指定的阈值,若小于阈值范围则执行步骤6,否则执行步骤3。
步骤3 判断该Map阶段是否为第1轮作业的执行过程,若是则执行步骤5,否则执行步骤4。
步骤4 将步骤1计算出的隶属度值带入式(3)得到新的聚类集合,并更新CLUSTER_LIST。
步骤5 输出隶属度值,供Reduce阶段使用,输出形式为(CLUNUMi,(LINNUM,MEi)),其中,CLUNUMi为第i个聚类中心的序号;LINNUM为当前数据的行偏移量;MEi为当前数据到第i个聚类中心的隶属度值,本轮Map任务结束。
步骤6 输出中间结果(CLUNUMi,(LINNUM,DATA)),DATA为当前的数据记录值。
4.2 Reduce阶段的设计
Reduce阶段具体设计如下:
步骤1 判断新计算出的中心与当前的聚类中心之间的差值是否小于指定的阈值,若小于阈值范围则执行步骤4,否则执行步骤2。
步骤2 Reduce函数以Map输出的中间结果作为输入,即Reduce的输入为(CLUNUMi,(LINNUM,MEi)),CLUNUMi相同的记录会被分配到同一个Reduce任务,Reduce函数根据每一个数据对各个聚类中心的隶属度值来计算出新的聚类中心。
步骤3 输出聚类结果,输出形式为(CLUNUMi,CLUSTERi),CLUSTERi为第i个聚类中心的值,更新聚类中心集合,本轮任务结束,启动下一轮MapReduce任务。
步骤4 Reduce函数以Map输出的中间结果作为输入,即Reduce的输入为(CLUNUMi,(LINNUM,DATA)),计算最后的聚类结果并输出,输出的形式为(CLUNUMi,DATALISTi),DATALISTi为属于第i类聚类的所有数据集合,任务结束。
5 实验与结果分析
5.1 实验环境
本文实验环境是由9台高速千兆网络连接的PC机组成,每个PC机的配置为Intel Core Duo 2.10 GHz CPU,内存为4 GB,操作系统为Ubuntu 12.10。其中,一台机器作为Master节点;其他8台机器作为Slave节点,图3为集群配置。本文采用的Hadoop平台版本为1.1.2,代码编译采用JDK1.6。

图3 集群配置
实验所用到的数据集由文献[7]中的标准数据生成工具生成,实验数据的条数从2×105条~10×105条不等,实验数据的维度从2~8不等,要求生成8个~12个聚类类别,初始聚类中心值随机产生。在实验中,首先用文献[1]提出的基于MapReduce的并行模糊 C均值算法(BC)与 Intel Parallel Amplifier下多核平台上的并行模糊 C均值算法(IC)进行对比,然后用本文提出的MapReduce模型下的高效模糊C均值算法(HC)与BC算法进行对比,具体工作如下:
(1)算法性能随着数据维度变化情况;
(2)算法性能随着数据量的变化情况;
(3)算法性能随着任务节点数量的变化情况。
5.2 不同模型下的FCM算法比较
在本文实验中,对IC,BC以及HC 3种算法执行效率进行比较,由于IC算法是将多核技术实现到模糊C均值算法的并行化中,因此实验采用一台双核机器进行实验,实验数据量从1×103~10×103不等,数据维度为4。表1为实验的结果,从表中可以看出随着数据量的增加,BC和HC算法的执行效率明显高于IC的执行效率,因此可以得出MapReduce模型下的模糊C均值算法具有更高的执行效率。
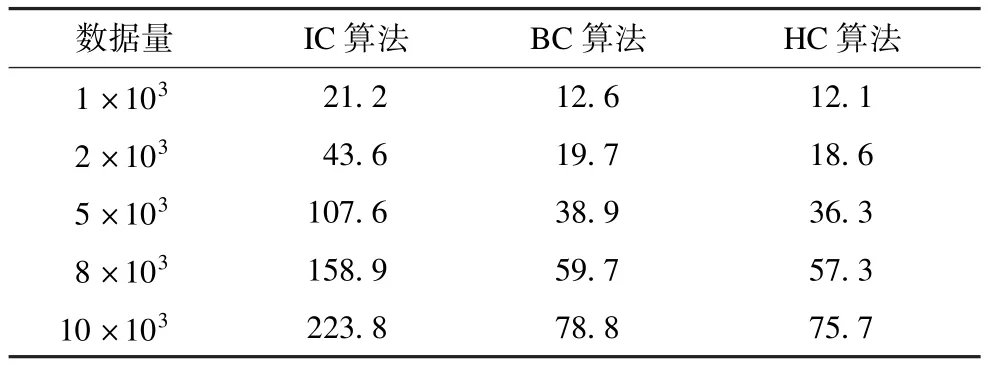
表1 模糊C均值算法运行时间比较 s
5.3 FCM算法性能随数据维度的变化情况
图4表示模糊C均值算法的性能随数据维度变化的情况,实验数据条数为10×105,任务节点数为8。图4表示模糊C均值算法运行时间的测试结果。可以看出,2个模糊C均值算法的执行时间在低维度时相差不大,在数据维度达到8时,算法执行时间差距明显增大,原因是随着数据维度的增大,算法执行时的计算量开始增大,迭代次数也随之增加,而本文提出的HC算法能够有效降低迭代次数,所以执行效率相对较高。

图4 模糊C算法运行时间与数据维度的关系
5.4 FCM算法性能随数据量的变化情况
图5表示模糊C均值算法性能随着数据量变化的情况,实验的数据维度为8,任务节点数为8,可以看出,随着数据量的增大,模糊C均值算法的运行时间增加,因为随着数据量的增加,算法的计算量开始增大,迭代次数开始增多,使得算法的开销增大,本文实验的数据量是从2×105~10×105,能够说明算法对海量数据处理的能力。可以看出,BC算法的运行时间高于本文的HC算法,原因是本文的HC算法通过Map阶段计算结果的回带有效地降低了算法的整体迭代次数,从而提高了算法的执行效率。

图5 模糊C算法运行时间与数据量的关系
5.5 FCM算法性能随任务节点数量的变化情况
图6表示模糊C均值算法的性能与任务节点数变化的关系,实验的数据条数为10×105,数据维度为2。可以得出,随着任务节点数量的增加,2个模糊C均值算法的运行时间都呈现下降的趋势,因为随着任务节点数量的增加,系统的并行处理能力随之增强,所以处理相同的数据其所消耗的时间也越来越少。

图6 模糊C均值算法运行时间与节点数的关系
本文算法在Map任务阶段需要根据隶属度值计算出新的聚类中心,并更新到聚类中心文件中,供其他的Map任务使用,在此阶段会有部分提前运行的Map任务未能接收到更新后的聚类中心文件,随着Map任务节点的数量增大,同时开始的Map进程个数将增大,因此更多的Map进程将不能获得更新后的聚类中心,但通过实验比较,如图6所示,本文算法仍具有较高的效率,该情况不会影响算法的整体执行效率。
6 结束语
本文针对如何利用MapReduce模型实现海量数据下的模糊C均值算法进行研究。分析了文献[1]提出的基于MapReduce的并行模糊C均值算法的不足并对其进行改进,进而提出MapReduce模型下的高效模糊C均值算法,通过实验对比可知,本文提出的算法能够更有效地解决海量数据下的模糊C均值问题,具有较高的准确性和可用性。
[1] 虞倩倩,戴月明.基于MapReduce的并行模糊C均值算法[J].计算机工程与应用,2013,49(14):133-137,151.
[2] 胡 磊,牛秦洲,陈 艳.模糊C均值与支持向量机相结合的增强聚类算法[J].计算机应用,2013,33 (4):991-993.
[3] Highland F,Stephenson J.Fitting the Problem to the Paradigm:Algorithm Characteristics Required for Effective Use of MapReduce[J].Procedia Computer Science,2012,12:212-217.
[4] Polo J,CarreraD.Performance-driven Task Coscheduling for MapReduce Environments[C]//Proc.of IEEE Network Operations and Management Symposium. [S.l.]:IEEE Press,2010:373-380.
[5] Marozzo F,Talia D,Trunfio P.P2P-MapReduce:Parallel Data Processing in Dynamic Cloud Environments[J]. Journal of Computer and System Sciences,2011,78(5): 1382-1402.
[6] 李建江,崔 健,王 聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[7] 林 彬,李姗姗,廖湘科,等 .Seadown:一种异构MapReduce集群中面向SLA的能耗管理方法[J].计算机学报,2013,36(5):977-987.
[8] 赵彦荣,王伟平,孟 丹,等.基于Hadoop的高效连接查询处理算法CHMJ[J].软件学报,2012,23(8): 2032-2041.
[9] Shafer J,Rixner S,Cox A L.The Hadoop Distributed Filesystem:Balancing Portability and Performance[C]// Proc.of 2010 IEEE International Symposium on Performance Analysis of Systems&Software.Washington D.C., USA:IEEE Computer Society,2010:122-133.
[10] 廖 彬,于 炯,张 陶,等.基于分布式文件系统HDFS的节能算法[J].计算机学报,2013,36(5): 1047-1064.
[11] 王 骏,王士同.基于混合距离学习的双指数模糊C均值算法[J].软件学报,2010,21(8):1878-1888.
[12] 肖立中,邵志清,马汉华,等.网络入侵检测中的自动决定聚类数算法[J].软件学报,2008,19(8): 2140-2148.
[13] 武小红,周建江.可能性模糊C-均值聚类新算法[J].电子学报,2008,36(10):1996-2000.
[14] 栾亚建,黄翀民,龚高晟,等.Hadoop平台的性能优化研究[J].计算机工程,2010,36(4):262-264.
[15] Dittrich J,Quiane R J A,Jindal A,et al.Hadoop++: Making a Yellow Elephant Run Like a Cheetah(Without It Even Noticing)[J].VLDB Endowment,2010,3(1/ 2):518-529.
[16] Bu Y,Howe B,Balazinska M,et al.HaLoop:Efficient It Erative Data Processing on Large Clusters[C]//Proc.of the 36th International Conference on Very Large Data Bases.Singapore:[s.n.],2010:285-296.
编辑 陆燕菲
Research on Fuzzy C-means Algorithm on MapReduce Model
WANG Yong-gui,LI Hong-xu,SONG Xiao
(College of Software,Liaoning Technical University,Huludao 125105,China)
Fuzzy C-means(FCM)algorithm requires constant iteration to calculate the characteristics of the membership value of the sample data and cluster center,using MapReduce model to solve the FCM under massive data.Map stage calculates membership degree,and Reduce stage completes computing cluster center.Each iteration needs to start a MapReduce implementation process.Through multiple iterations,it calculates the value of membership and cluster center, and updates cluster center file for the use of next round job.Repeat this process until get the final clustering results. Experimental results show that the algorithm can effectively reduce the number of iterations during the calculation and improve the overall efficiency of the implementation.
Fuzzy C-means(FCM)algorithm;MapReduce model;mass data;high efficiency;iteration
1000-3428(2014)10-0047-05
A
TP391.41
10.3969/j.issn.1000-3428.2014.10.010
国家自然科学基金资助项目(60903082);辽宁省教育厅基金资助项目(L2012113)。
王永贵(1967-),男,教授、硕士,主研方向:云计算,绿色计算,数据挖掘;李鸿绪、宋 晓,硕士研究生。
2013-09-29
2013-11-29E-mail:theone_theone@163.com
中文引用格式:王永贵,李鸿绪,宋 晓.MapReduce模型下的模糊C均值算法研究[J].计算机工程,2014, 40(10):47-51.
英文引用格式:Wang Yonggui,Li Hongxu,Song Xiao.Research on Fuzzy C-means Algorithm on MapReduce Model[J]. Computer Engineering,2014,40(10):47-51.
猜你喜欢
交通科技与管理(2022年19期)2022-10-12
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电讯技术(2016年8期)2016-11-02
科技传播(2016年17期)2016-10-10
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
电子设计工程(2015年6期)2015-02-27
数学年刊A辑(中文版)(2014年4期)2014-10-30
郑州大学学报(理学版)(2014年4期)2014-03-01
