
射电干涉阵GPU相关器的研究初探
2014-05-12 10:36田海俊陈学雷李长华吴峰泉汪群雄
天文研究与技术 2014年3期
田海俊,徐 洋,陈学雷,李长华,吴峰泉,汪群雄,刘 勇
(1.三峡大学,湖北 宜昌 443002;2.中国科学院国家天文台,北京 100012)
射电干涉阵GPU相关器的研究初探
田海俊1,2,徐 洋2,陈学雷2,李长华2,吴峰泉2,汪群雄1,刘 勇1
(1.三峡大学,湖北 宜昌 443002;2.中国科学院国家天文台,北京 100012)
射电干涉仪阵列规模的不断扩大使其观测能力越来越强,但与之俱来的密集型数据的实时处理对传统解决方案的性能和成本等带来巨大的挑战,针对该挑战设计并验证了GPU解决方案。首先着重分析了射电干涉仪的相关器在运算和传输等方面的基本需求,然后根据射电干涉阵列信号的特征,尝试了多种GPU相关器模型,通过将相关器的计算任务有效映射为GPU线程模型,显著提高了GPU的利用率,使单GPU的实际计算性能达到了理论峰值性能的77%。最后以我国正研制的天籁计划为依托,开展了多种关键技术的先导实验,为进一步在GPU集群环境下针对大型射电干涉仪的需求研发一套同时兼备成本低、性能高、功耗少等优势的相关器打下了坚实的基础。
射电干涉仪;FX相关器;GPU;实时处理系统
CN53-1189/P ISSN1672-7673
典型的干涉阵列的信号处理包括:时间序列信号的模数转化(Digitization)、干涉显示度的计算(Complex Visibility)和校准、噪音的消除、天图的傅里叶重构。其中干涉显示度的计算又主要包括各路信号的傅里叶变换(F-engine)和交叉互关联(X-engine)两部分,它是射电干涉仪数据实时处理过程中最关键也是计算量最大的部分,它的计算量按阵元数目的平方急剧增长,即O(N2)。
目前国际上干涉仪的阵元个数正向数百乃至数千发展。世界上大多数已建成的天文干涉仪阵列,如美国的甚大阵列(Very Large Array,VLA),印度的巨型米波射电望远镜(Giant Meter wave Radio Telescope,GMRT)等都由几十个单元组成。但随着干涉仪技术的不断成熟,人们已经开始筹划或正在建越来越大的阵列,例如,我国正研制的“天籁计划”,以及国际上正在筹建的平方千米阵列望远镜(Square Kilometer Array,SKA)预期都由数百乃至数千个单元组成,欧洲即将建成的低频射电干涉阵列(Low Frequency Array,LOFAR)由20000个天线构成的48个基站组成。如此大规模的天线阵列对数据采集、传输、处理等有极高的技术要求,特别是随着阵列单元数的增加,各天线间信号交叉相关的实时计算是一个极其困难的任务。以低频射电干涉阵列为例,它采用了IBM BlueGene/P超级计算机集群专门用于数据的在线处理。它通过各基站分别计算,合成一些波束后再进行干涉的办法来降低所需的数据传输率和计算速度,即使这样也无法实现所有单元同时进行干涉。如何应对这些挑战,尤其是如何以低廉的成本应对目前万亿次每秒甚至亿亿次每秒的实时处理需求是国际上关注的一个难题。
图形处理器(Graphics Processing Unit,GPU)的不断发展为这类问题的解决带来了新的希望。图形处理器的概念自NVIDIA公司于1999年首次以图像加速器提出以来,如今已经发展成为一种高度并行化的多线程、众核处理器,不仅具备高质量和高性能的图形处理能力,而且具有杰出的浮点计算能力和存储带宽,这使其能作为中央处理器的协处理器有效地加速科学运算。
国际上目前在积极利用图形处理器为各大射电望远镜系统寻求一种成本更低、性能更好、功耗更少的数据处理解决方案。2008年10月,文[1]作者利用模拟数据测试了图形处理器在做傅里叶变换和信号交叉相关时的性能,他们着重考察了不同的图形处理器并行方案对计算性能的影响,虽然该实验比较简单,但图形处理器的高性能、低功耗的潜能已经充分表现出来。2009年8月,文[2]作者利用图形处理器专门针对澳大利亚的默奇森宽视场射电望远镜阵列(Murchison Widefield Array,MWA)的原型系统(32个天线阵元)进行FX加速实验,该实验基于单个图形处理器(型号为Nvidia C1060)实现了32路信号交叉相关的实时计算,结果表明图形处理器运算性能高于单线程中央处理器程序68倍,但是由于PCI-E(Host与Device之间的传输协议)带宽的限制,单图形处理器无法胜任较大的天线阵元数目。同年,文[3]作者对多核中央处理器和众核架构下(比如IBM Cell,IBM BG/P,Intel Core i7,ATI Radeon 4870,Nvidia C1060)射电干涉仪相关器的性能做了全面的测试,结果IBM的两个平台取得了很高的性能。事实上,上述3个小组的实验在很大程度上受到数据传输带宽的束缚,虽然他们都使用了基本的内存管理策略,比如共享内存的窗口配置策略和寄存器优化策略,但系统整体性能仍然只发挥了图形处理器理论性能的10%到30%,这表明图形处理器更多潜能需要进一步去挖掘。在这种情况下,2011年7月,文[4]作者利用新一代的Fermi架构图形处理器卡GTX480,综合了前面3个小组的经验,采用多层次的内存优化策略,将信号交叉相关运算的整体性能提高至理论性能的79%,大大增加了图形处理器在干涉仪相关器中的竞争优势。
1 射电干涉仪在运算和传输等方面的需求分析
射电干涉仪在做信号的实时处理时,采取不同的方式,计算的复杂度有很大的差别,因此首先简要介绍两种基本的相关器。
1.1 相关器
射电干涉仪在做数据的实时处理时,可以采用XF方式,即先做实域的交叉互关联(X-engine),再做傅里叶变换(F-engine);也可以使用相反的处理方式,即FX方式。同样的信号数据,XF方式要比FX方式计算复杂度较大,因为先做傅里叶变换,再做交叉相关时,只需要做同频率的相关,不同频率间的相关为0。因此,随着天线阵元的增加,国际上更倾向FX方式。
在实际情况中,可能还会采用FFX算法,即先做一个时间序列信号的快速傅里叶变换,得到时间频域数据,再做一个空间序列信号的快速傅里叶变换,得到空间频域数据,最后再做相关,这时只需计算时域频率、空域频率都相同的信号,这样可以进一步降低运算量。上述空域快速傅里叶变换,可以采用二维的,即对分布在一个平面上的阵列,沿两个方向均做快速傅里叶变换[5]。比如国家天文台陈学雷研究员正研制的“天籁计划”将采用柱面望远镜阵列,沿南北方向的阵列单元较长,而沿东西方向则只有有限的几个,使用快速傅里叶变换并不能减少计算量,因此只需沿同一柱面做一维快速傅里叶变换,不同柱面间则直接计算相关。
1.2 FX相关器的数据传输和运算复杂度
本小节基于FX相关器,在给定干涉仪各种参数指标情况下,详细讨论数据传输压力与运算复杂度。
假设干涉仪的天线数目为Na,每个天线的极化数为Np,采集的每个数据点通过模拟数字转换为Nb位整型数据,干涉仪的频率带宽为Δν(根据Nyquist原理,干涉仪的采样频率Ns至少为2Δν)。相关器在做数据实时处理时,傅里叶变换的长度取Nf,相关运算需要考虑N2p个极化对和Na(Na+1)/2个天线对(即基线的个数NB,其中包括了Na(Na-1)/2个交叉相关和Na个自相关),每一个相关运算的输出结果是时间tI的积累。干涉仪的最大积分时间与它的基线长度Lb和地球的自转速度ωr有关,基线的长度越长,允许的积分时间越短。因此,干涉仪的积分时间通常不能超过最长基线对应的积分时间,即
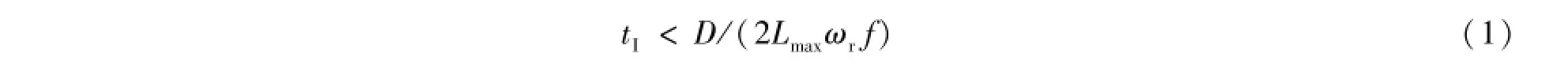
这里ωr=7.272×10-5rad/s;D为望远镜的口径;f为过采样的倍率。这里积分时间的限制是满足干涉的基本要求,实际积分时间的设置还与科学目标有关,比如探寻快速射电暴需要毫秒级的积分时间。
1.2.1 相关器的数据传输率
图1展示了FX相关器的数据传输示意图,前端数据采集和数据的模拟数字转换等部分已经略去。该图以模拟数字的输出作为FX相关器的输入,模拟数字的输出为整型数据。
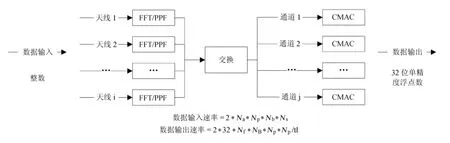
图1 FX相关器的数据传输示意图Fig.1 Illustration of the data transmission of the FX correlator
根据干涉仪的参数,可以估算每秒内所有天线的数据产出,即模拟数字转换的数据输出为:
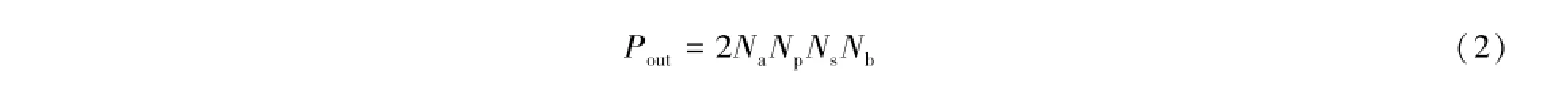
为了防止傅里叶变换或多向滤波器(Polyphase Filter,PPF)数据溢出,需要将输入的整型数据扩展为高位的浮点型数据,这里因子2表示将数据的位数扩展了2倍。
在傅里叶变换阶段,每一个天线采集的数据傅里叶变换接口的输入或输出数据率为(傅里叶变换不改变数据的存储大小):
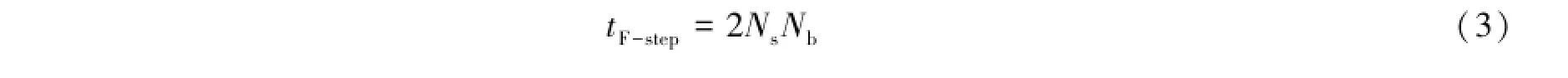
那么在傅里叶变换阶段,总的数据输入或输出率为:
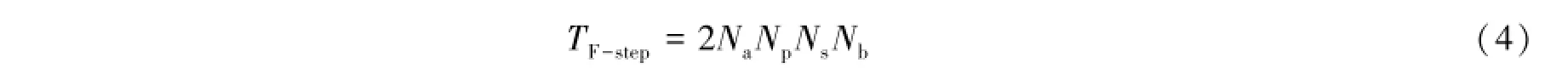
在交叉互关联阶段,即图1所示的复数的乘累加(Complex-Multiplication-and-Accumulation,CMAC)阶段,每个频率通道向交叉互关联的输入数据率为:
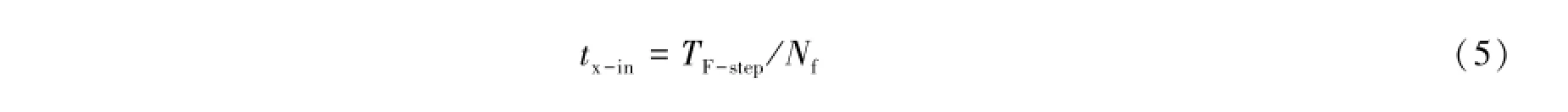
交叉互关联的输出数据率较为复杂,因为它和积分时间有关,积分时间与基线长度、望远镜口径、地球自转速度等因素有关,积分时间的上限由(1)式给出。那么,交叉互关联总的数据输出率为:
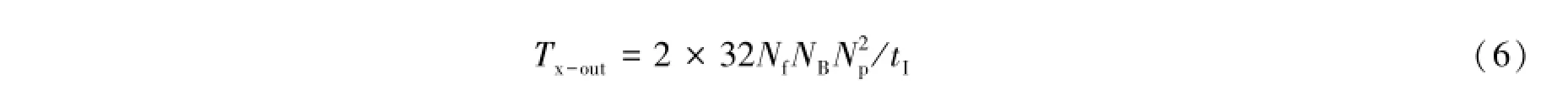
因子2是指复数由实部和虚部两部分实数组成,因子32意味着每个实数的字节数为32位,这是由望远镜设计者根据数据精度的要求确定。式中1/tI的意义为每秒数据输出的次数,但实际数据的输出频率可能小于1/tI,比如积分时间为0.1 s,而数据输出的频率可能设置为每秒一次,这样可以大大降低数据的输出量。
1.2.2 相关器的运算复杂度
这里运算复杂度主要指相关器在执行傅里叶变换和交叉互关联操作时每秒的浮点运算次数。
Cooley-Tukey是一种常用的快速傅里叶变换算法,它的运算复杂度为(3Nf/2)log2Nf(其中包括(Nf/2)log2Nf次乘法运算和Nflog2Nf次加法运算)。由该复杂度公式可知,傅里叶变换的计算复杂度除了与天线的个数Na和极化数Np等因素有关之外,最主要是由傅里叶变换的长度Nf决定,即:
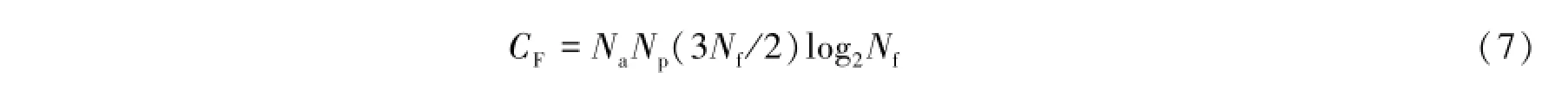
交叉互关联是相关器计算量最大的一部分,也是相关器最核心的部分。对于每秒的输入数据,相关运算都需要执行NsNBN2p/Nf次复数的乘累加操作,每次复数的乘累加需要8次的浮点运算,所以每个频率通道每秒的浮点运算次数为:

每秒浮点运算总量为:

1.2.3 “天籁计划”的性能需求分析
“天籁计划”是我国正在建设的一个大型射电干涉仪阵列,主要科学目标是探测宇宙中的暗能量[6]。
表1给出了“天籁计划”一期和二期工程设备拟采用的参数设置。表2是根据表1的参数设置,估算了FX相关器在3个主要环节中数据传输和运算的需求。对于“天籁计划”运算需求的简单估算:一块典型四核中央处理器(比如:Intel Core i7)的计算性能大概为70GFLOPS (0.54GFLOPS/Watt),根据表2的估算结果,仅仅完成天籁一期工程交叉相关运算,至少需要430个Intel Core i7处理器完成交叉相关的计算;而一块同时期的典型图形处理器(比如Nvidia Geforce GTX 580)的计算性能至少为1.5TFLOPS (6.5GFLOPS/Watt),完成天籁一期工程的实时数据处理一共只需30多个图形处理器即可,无论从能耗还是从硬件成本上,图形处理器方案都将远远低于中央处理器的方案。
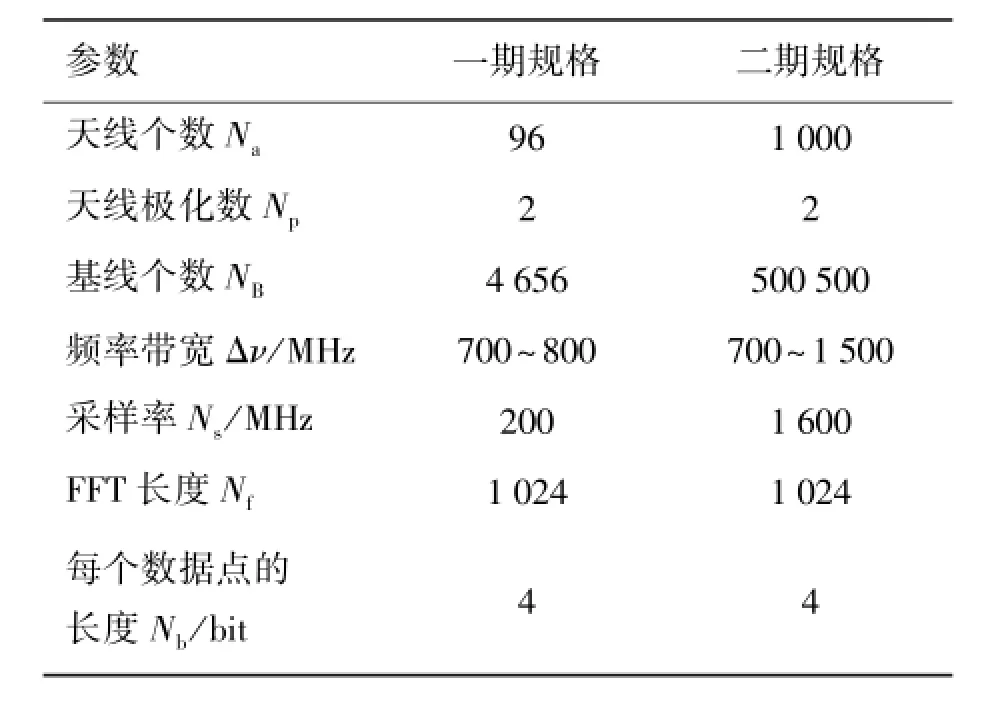
表1 “天籁计划”一期和二期工程拟采用的参数设置Table 1 The parameters planned for the Phase 1 and Phase 2 of the Tianlai project

表2 “天籁计划”的数据传输和运算性能需求Table 2 The requirements on the data transmission and computing performances in the Tianlai project
2 FX相关器图形处理器实现的优化模型
如(7)式和(9)式所示,交叉互关联的计算量将远大于傅里叶变换的计算量,因此本文将重点讨论交叉互关联的性能优化。
利用图形处理器实现相关器,其性能主要由数据传输和运算两部分决定,但数据传输通常是图形处理器整体性能的瓶颈,受限于数据的传输速率,图形处理器的实际性能一般只能达到理论性能的10%~30%。为了提升图形处理器的实际性能,必须减少数据的反复读写,提高数据的利用率。图形处理器的存储器模型设计了多种存储类型,包括全局存储器、纹理存储器、共享存储器、寄存器等,根据不同存储器的特点,合理使用多层次存储器对数据进行缓存加速,可以有效减少图形处理器对显存的反复访问,提升程序的性能。
FX相关器的设计,正是利用多层次存储器,将线程模块与数据模块合理映射,实现了数据的有效调度,下面从基本的模型出发详细讨论线程模块与数据模块的配比。
在图形处理器线程模型中[7],多个线程构成一个线程块(block),线程块为线程的基本组织单位,多个线程块组成一个线程网格(grid)。每个线程都拥有自己的寄存器,各线程寄存器之间不能直接通信。每个线程块中所有的线程共享一个共享存储器(shared memory),同一个线程块中的线程可以自由读写共享存储器。虽然寄存器速度最快,但是寄存器为线程私有,线程之间不能通过寄存器共享数据,因而共享存储器为图形处理器上数据缓存方式的首选。
前文讲过,FX相关器只需要计算同频率信号之间的交叉关联。各天线在某频率f1上的信号构成一个大小为Na的向量,那么该频率上的交叉关联为一个Na×Na的矩阵,其有效部分为矩阵的下(或上)三角(对应基线个数NB),如图2中左边的三角形所示。为了提高数据的利用率,需要尽可能多地将数据缓存在共享存储器中,但是图形处理器上的每个共享存储器的大小有限,只能存储部分数据,因而需要将数据分块,分散到不同的线程块分别进行处理。假设处理时将Na分解为宽度为W的B个正方形数据块分别进行处理(Na=WB),那么对于一个频率为f1的交叉关联运算,图形处理器的数据加载总次数为[4]:
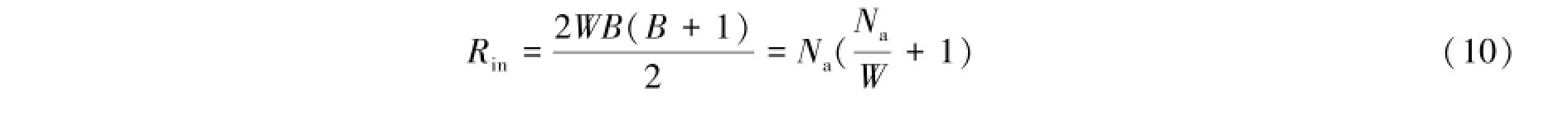
图2(左)所示,每个不同颜色的区域代表一个W×W大小的线程块,其总数量为B(B+1)/2个,每个线程块每次处理在X方向和Y方向上都需要W个数据点。如果将这B(B+1)/2个不同颜色的格子按照颜色从浅到深的方向展开,即可形成右图中网格在gx方向的布局,如果再将gy方向上表示为不同的频率,那么一个图形处理器的线程网格就可以完成干涉仪阵列中所有基线上某序列频率段(f1~fn)的交叉相关任务的计算。从(12)式可知,当W越大时,图形处理器的数据加载次数越小,当W=Na时,也即一个线程块一次处理Na个数据,此时,数据加载次数Rin最小,即2Na。但是实际上每个线程块的共享存储器大小有限,且线程个数(处理能力)有限,在Na很大的情况下,W不可能等于Na,且当W逐渐增大时,线程块中的可用资源(寄存器、指令发射单元、执行单元等)的利用率会逐渐趋向于饱和,虽然Rin在减小,但是总的计算时间可能会成倍地增长,因而需要根据干涉仪的规模,同时结合图形处理器硬件配置等情况合理地选择W的大小,将Na分解到多个线程块中去。
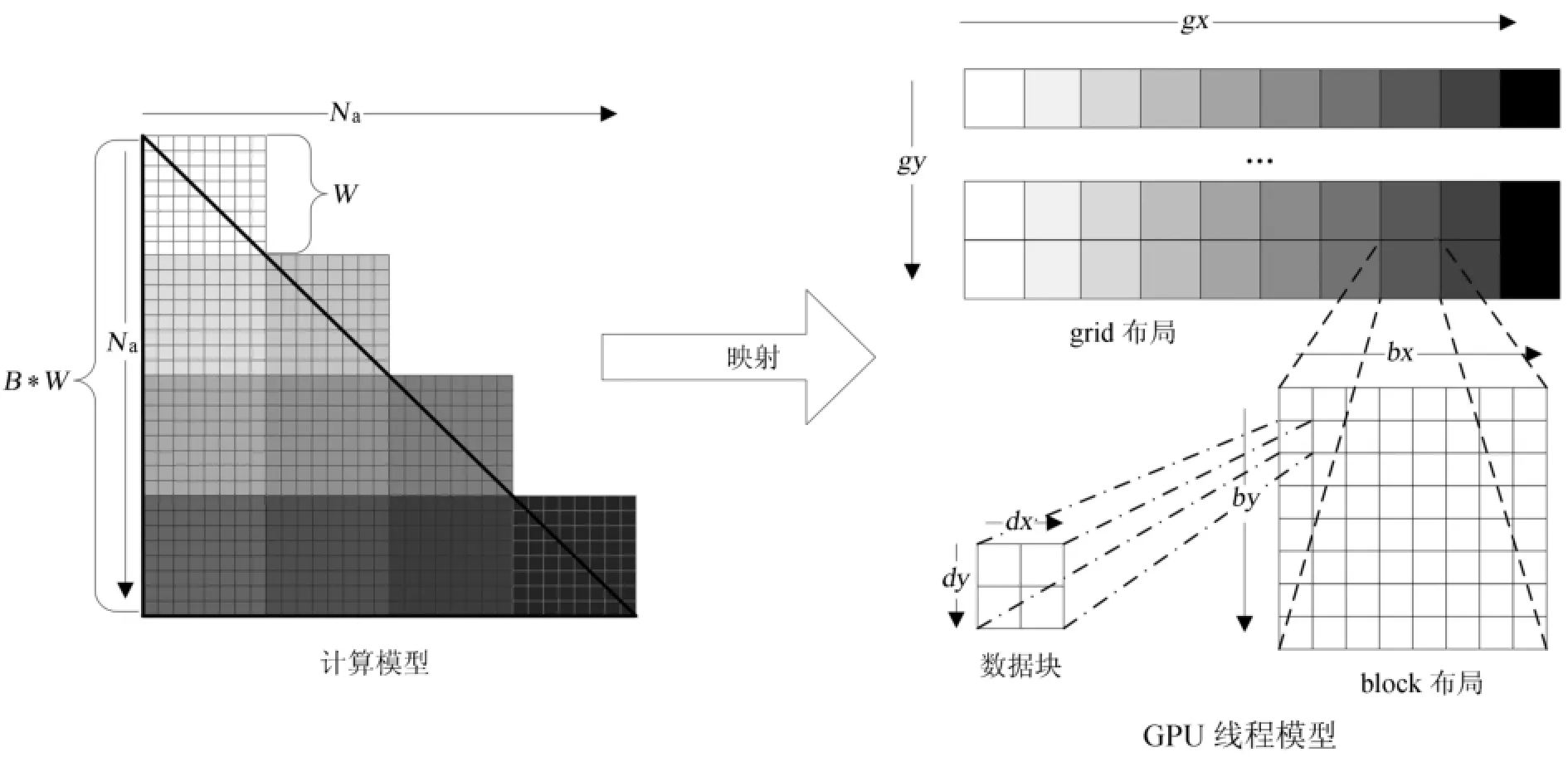
图2 交叉关联部分计算任务与线程数目的对应关系[4]Fig.2 The mapping of data blocks in cross-correlation computations to grid threads[4]
(10)式中Rin的大小直接影响图形处理器线程模型的布局,图2中,图形处理器线程模型中包括线程网格布局、线程块布局和数据块3部分,其中数据块代表每个线程每次处理的数据大小。下面将对线程块布局和数据块的关系进行量化分析:
假设线程块的宽度和高度分别为Bx和By,线程块中每个线程每次读取k个浮点数据,每个线程处理的数据块的宽度和高度分别为Dx和Dy,线程块所需的数据即为线程块中所有线程读取的数据之和:
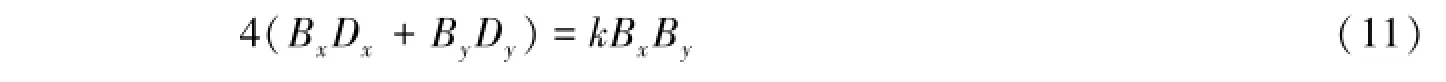
式中,BxDx和ByDy分别为计算模型在X轴和Y轴方向的单位数据长度,对应图2中的W;数字4代表双极浮点数据的大小(字节)。由上面的分析可知每个线程能够读取的数据k的大小、数据块的宽度Dx和高度Dy都需要根据图形处理器的硬件参数进行适当调整。实际程序实现时,大部分图形处理器的配置并不一样,而且由于摩尔定律的存在,图形处理器的计算性能每年都会翻倍增长(图形处理器硬件架构或各硬件参数都将随着改变),因而这些参数的最优取值并不会一成不变,只有根据实际硬件配置进行适当调整,才能使系统整体的性能达到最大。例如对先导实验所使用的Nvidia GTX480显卡,当Dx=Dy=2,Bx=By=8时,实际性能可以达到理论性能的77%。
3 关键技术的先导实验
经过充分的调研之后,分别在两种不同图形处理器架构(AMD和NVIDIA)下,基于两种图形处理器编程模型(OpenCL和Cuda C),利用复正弦模拟信号做了傅里叶和多路信号交叉相关的原型实验。实验过程中使用图形处理器相关模型对信号进行互关联,同时结合各种优化措施,比如纹理缓存、架构(cuda)流并行技术等,在GTX480显卡上将交叉互关联的计算性能从最初的100多GFLOPS(约理论性能的10%)提升至1033GFLOPS(约理论性能的77%),如图3。但从数据的传输速率角度看,主要瓶颈在于主机到设备的传输(即PCI-E的传输速率),如图4。
从图3可以看出GTX460的Kernel性能(即只包括内核程序执行而不包括数据传输的性能)最高达到401Gflops,约占理论性能的44%,总体性能最高达到335GFlops,约占理论性能的37%。而GTX480的Kernel性能最高达到1033Gflops,约占理论性能的77%,总体性能最高达到786GFlops,约占理论性能的58%,具体如表3。可见无论是Kernel性能还是总体性能,GTX480都比GTX460高出至少20个百分点,这里最主要的区别在于GTX480与GTX460硬件架构不同:GTX480的核心架构为GF100,每个核心中有32个流处理器;而GTX460的核心架构为GF104,每个核心中有48个流处理器。但是他们的指令发射单元都是两个,每个指令发射单元每次发射16个指令,因此GTX480中每次发射的指令数刚好与流处理器个数相符,而GTX460中有一个指令发射单元需要连续发射两次指令才能满足48个流处理器的处理需求,这就导致GTX460中的指令发射密度高于GTX480,即GTX460架构需要更高的指令级并行,这种指令级并行最终要对应到代码的优化上,本先导实验的代码设计主要是针对GTX480,因此GTX460的实验性能相对理论性能较低。
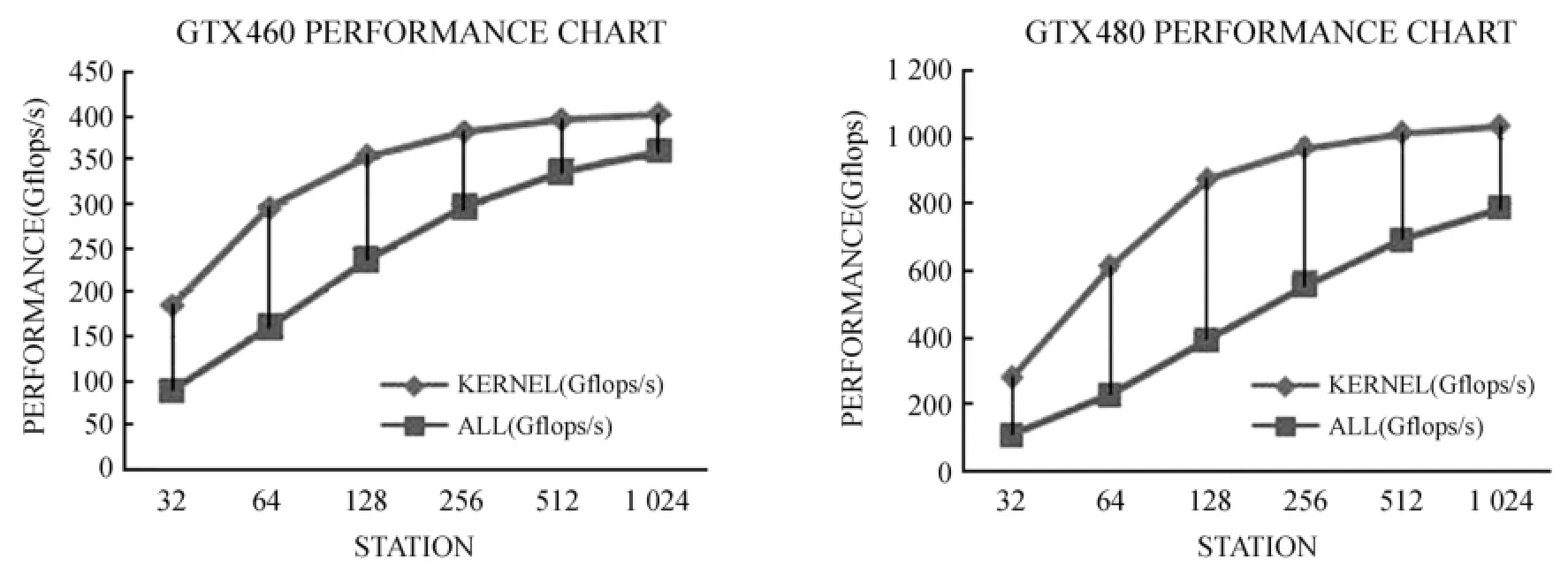
图3 GTX460与GTX480在不同天线个数时的计算性能曲线图Fig.3 Computing speeds of GTX460 and GTX480 for different antenna numbers
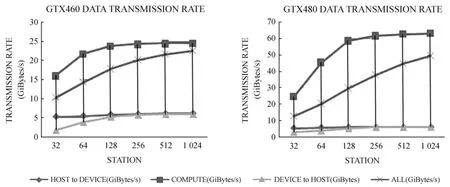
图4 GTX460与GTX480在不同天线个数时的数据传输速率曲线图Fig.4 Data transmission rates of GTX460 and GTX480 for different antenna numbers

表3 GTX460与GTX480的Kernel性能和总体性能与理论性能的百分比Table 3 The performances of the kernel and overall performances of GTX460 and GTX480 (expressed in percentages of theoretically possible values)
这里计算的性能只包含算法本身的计算量,不包含系统实际运行所消耗的计算量。对于GTX480的77%的Kernel性能,未包括系统实际运行所消耗的运算量(如指令调度、内存寻址等),因此,Kernel的实际运算性能可能达到理论值的90%以上。所以,在今后性能优化方面,Kernel算法优化空间不大,将着重考虑数据传输方面的优化。
频谱泄漏相关的测试。用离散傅里叶变换作谱分析时,由于信号长度的截断,总是会伴随频谱泄漏,这会对信号处理带来诸多负面影响,对于这个问题也做了一定的研究和实验。减小频谱泄漏的方法,往往通过使用窗口函数,在先导实验中,实验了较为复杂的多相滤波器方法[8],图5是多相滤波器在不同环境下的实现结果,图中每个子图都有4条使用多相滤波器滤波后的曲线,多相滤波器有一个参数taps,即对信号分段滤波并叠加的次数,如图当taps=4时,图中的黑线,频谱泄漏已非常小。对于大数据量的信号,中央处理器架构下运行性能往往要低于图形处理器,但它可以检查图形处理器结果的精确度和正确性。如图5所示,左图为在中央处理器下用Matlab计算的结果,中间图为在中央处理器下用C语言实现滤波用fftw函数库做傅里叶变换的结果,右图为在图形处理器下用C语言实现滤波并用架构的FFT库做傅里叶变换的结果。
4 总结与展望
本文从目前国际上射电干涉仪阵列数据实时处理的运算瓶颈入手,提出了图形处理器相关器的解决方案,然后详细分析了FX相关器进行数据的实时处理时在各主要环节上数据的传输率和运算复杂度等问题,并根据“天籁计划”的具体参数设置估算了该项目在数据传输和运算等方面的需求,详细讨论了使用图形处理器进行信号交叉关联时计算模型与线程模型的对应关系。最后,在NVIDIA的单块图形处理器架构下,基于Cuda C,利用复正弦模拟信号完成了傅里叶和多路信号交叉相关的原型实验,并通过图形处理器相关模型结合各种优化技术将计算性能从最初的100多GFLOPS(约理论性能的10%)提升至1033GFLOPS(约理论性能的77%),该结果证实了图形处理器杰出的浮点计算能力和很高的传输带宽,使图形处理器在射电干涉仪相关器的开发上具有极大的潜力。更重要的是,单图形处理器相关器的研发和实验可以为今后图形处理器集群环境下相关器的实现打下了良好的基础。
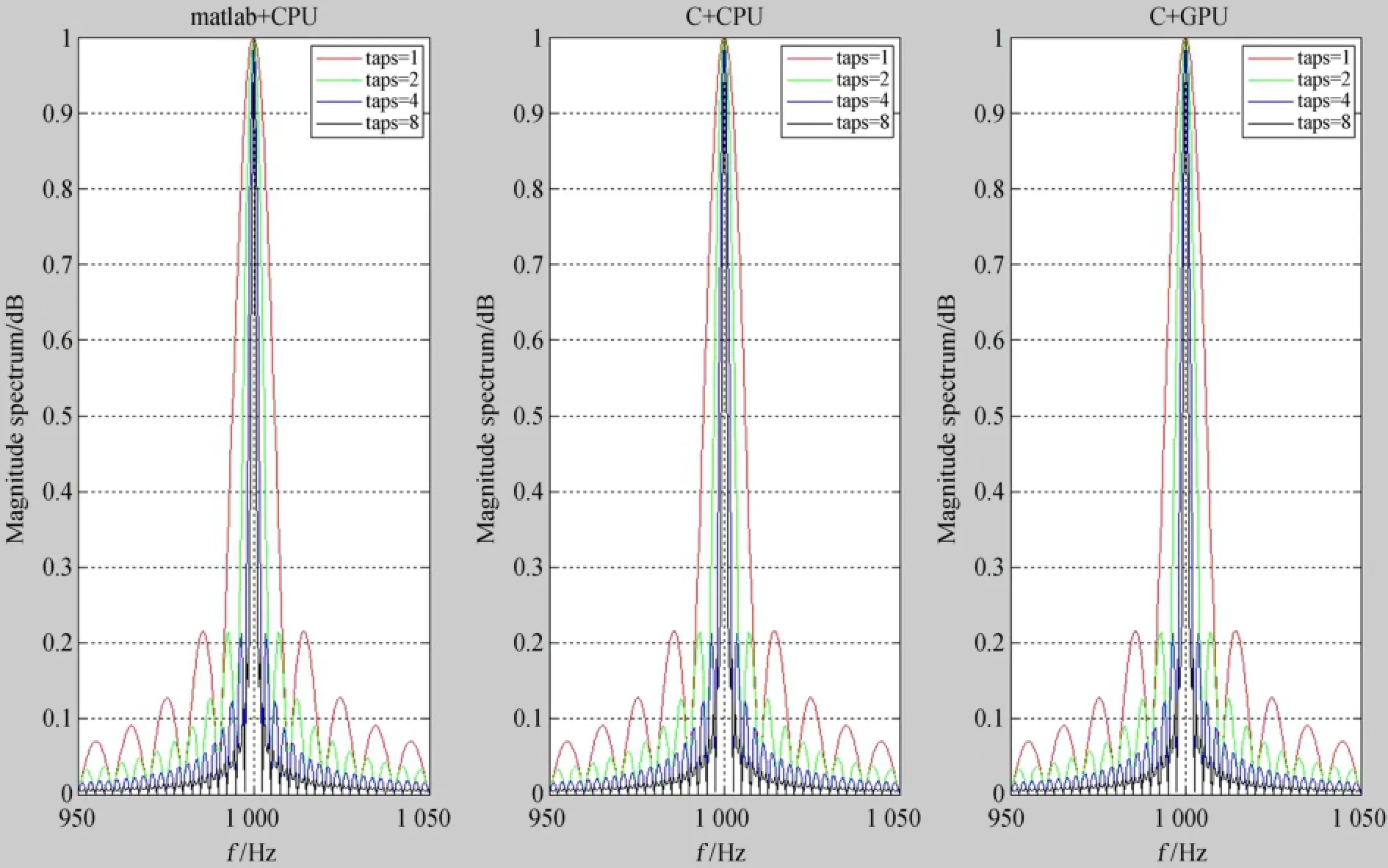
图5 频谱泄漏测试中央处理器与图形处理器结果验证比较Fig.5 Test results of spectral leakage for a CPU architecture and a GPU architecture
单图形处理器只能处理数个天线的信号处理,面对由几百乃至上千个天线组成的大型射电干涉阵,需要图形处理器集群才能应对。先导实验表明,图形处理器的计算性能足以应对复杂的运算,虽然图形处理器各节点可以通过OpenMP或MPI等标准的消息传递协议完成任务的调度,但是上千路信号之间的交叉互相关,势必导致图形处理器节点之间的数据传输压力过大。为解决这个问题,可以尝试分频分布式信号并行处理技术:将同频率的数据直接汇聚到相同的计算单元上,每个计算单元仅仅负责部分频率点的相关性运算。这样做的好处是,不需要计算单元之间的相互通信,减少了数据交换的压力,并且方便计算节点的扩充,可以适用于将来更大规模的接收机。
在后面的研究工作中,将进一步尝试多种优化策略,比如使用多流水线的技巧,使计算和数据传输同时进行,以避免因传输的瓶颈而导致计算资源的等待,甚至还可以尝试去掉从主机到设备的传输环节,可以将数据从望远镜的模拟数字转换器直接送到图形处理器的设备存储器中。从GTX460和GTX480的整体对比情况来看,图形处理器硬件的更新对FX相关器的影响也非常大,目前图形处理器正处于快速发展时期,NVIDIA公司已经推出新一代开普勒(Kepler)架构图形处理器,其性能比Fermi(GTX480即为Fermi架构)强3到4倍,而功耗更低,下一步将对该架构图形处理器进行测试。
总之,经过不断的测试,寻求各种最佳方案,利用图形处理器逐步实现一套成本更低、性能更高、功耗更少的相关器,更好地满足天籁计划的需求。
参考文献:
[1] Harris C,Haines K,Staveley-Smith L.GPU accelerated radio astronomy signal convolution[J]. Experimental Astronomy,2008,22(1-2):129-141.
[2] Wayth R B,Greenhill L J,Briggs F H.A GPU-based real-time software correlation system for the murchison wide-field array prototype[J].Publications of the Astronomical Society of the Pacific,2009,121:857-865.
[3] van Nieuwpoort R V,Romein J W.Using many-core hardware to correlate radio astronomy signals [C]//the 23rd ACM International Conference.2009:440-449.
[4] Clark M A,La Plante P C,Greenhill L J.Accelerating radio astronomy cross-correlation with graphics processing units[J].International Journal of High Performance Computing Applications,2013,27(2):178-192.
[5] Tegmark M,Zaldarriaga M.Omniscopes:Large area telescope arrays with only N logN computational cost[J].Physical Review D:Particles,Fields,Gravitation and Cosmology,2010,82:10pp.
[6] 陈学雷.暗能量的射电探测——天籁计划简介[J].中国科学:物理学力学天文学,2011,41 (12):1358-1366.
Chen Xuelei.Radio detection of dark energy-the Tianlai project[J].Scientia Sinica:Physica,Mechanica&Astronomica,2011,41(12):1358-1366.
[7] 张舒,褚艳利,赵开勇,等.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009.
[8] Harris C J.A parallel model for the heterogeneous computation of radio astronomy signal correlation [M].Australia:The University of Western Australia,2009:33-38.
A Preliminary Study on GPU-based Correlators for a Radio Interferometer Array
Tian Haijun1,2,Xu Yang2,Chen Xuelei2,Li Changhua2,Wu Fengquan2,Wang Qunxiong1,Liu Yong1
(1.China Three Gorges University,Yichang 443002,China,Email:hjtian@lamost.org;2.National Astronomical Observatories,Chinese Academy of Sciences,Beijing 100012,China)
As scales of radio interferometer telescope arrays increase,it becomes a tremendous challenge for the traditional solution to deal with intense real-time radio-astronomy data with high performances and low costs.In this paper we propose a creative and effective GPU-based solution to fit the needs of processing data from new arrays.We first give a brief description of the requirements on an effective solution,i.e.a highspeed low-cost procedure to transmit data and compute for real-time processing of data from a large-scale radio interferometer.We then present our GPU-based model,which improves practical computing performances of a single GPU card through accurately mapping data blocks in cross-correlation computations to GPU grid threads. The model achieves performances of up to 77%of those theoretically possible.Finally,several tests are carried by tailoring the model parameters to the requirements of the Tianlai project.The tests pave the way for realizing an on-line signal processing system with even much higher performances and a lower cost in an environment of GPU clusters.Such a system is to work for future more complicated and much larger radio interferometers.
Radio interferometer;FX Correlator;GPU;Real-time processing system
TP302
A
1672-7673(2014)03-0209-09
2013-10-21;
2013-11-14
田海俊,男,博士后.研究方向:天文信息学.Email:hjtian@lamost.org
猜你喜欢
军事文摘(2022年12期)2022-07-13
儿童故事画报·自然探秘(2022年6期)2022-07-05
九江学院学报(自然科学版)(2022年2期)2022-07-02
军事文摘(2021年22期)2022-01-18
少儿科技(2021年12期)2021-01-20
制造技术与机床(2019年6期)2019-06-25
航天电子对抗(2019年4期)2019-06-02
北京航空航天大学学报(2018年1期)2018-04-20
制导与引信(2017年3期)2017-11-02
太空探索(2016年9期)2016-07-12
