
移动用户个性化服务技术与应用
2014-05-08 09:57赵树超周昊薇曹丙瑞
河北省科学院学报 2014年4期
赵树超,周昊薇,曹丙瑞
(河北经贸大信息技术学院,河北 石家庄 050061)
1 移动个性化服务基本内涵
传统个性化服务是移动个性化服务的基础,后者是前者从互联网到移动终端的延伸,两者的基本思想相似,即收集用户信息并发现用户兴趣从而进行推荐,但移动个性化服务需要着重考虑移动环境带来的影响。下面介绍个性化服务的概念,分析移动用户的特点,把移动用户个性化服务与传统个性化服务进行对比。
1.1 什么是个性化服务
随着信息内容的日益增长,给人们搜索信息带来了困难。个性化服务可以为不同用户提供实时、有价值的信息以满足用户不同时期、目的、背景的查询请求。对于个性化服务的定义,文献[1]中认为个性化服务技术就是为不同用户提供不同的服务,以满足不同的需求。文献[2]中认为个性化服务是通过收集和分析用户信息来建立数学模型,学习用户兴趣和行为,发现用户隐藏的兴趣和群体用户的行为规律,从而制订相应的服务内容和服务策略,主动地为用户推荐服务。笔者认为个性化服务是一种有针对性的服务方式,依据各种合法渠道对资源进行收集、整理和分类,根据分析用户数据得到用户需求,向用户推荐实时的、有价值的信息,以满足用户的需求。
目前很多互联网公司如百度、淘宝、谷歌、Amazon等都在个性化服务技术及应用方面取得较大进展,较好地满足了用户的个性化需求。
1.2 移动用户的特点
与传统互联网用户相比,移动用户有着绑定性[3]、动态性[4]、实时性[5]等特点。
(1)绑定性。移动终端一般属于移动用户私人所有,具有个人化、私有化等特点,因此所采集的信息更为明确、真实可靠。
(2)动态性。移动用户和终端具有移动性特点,用户的需求会随着周围上下文(例如位置、天气等)改变和时间推移阶段性地发生变化。因此,移动用户需求获取过程是一个不断调整、动态变化的过程。
(3)实时性。因为移动用户具有动态性,用户的特征数据会动态变化,当用户需要服务时,只有实时获取用户的信息才能向用户提供及时、准确、有用的服务。
1.3 移动用户个性化服务与传统个性化服务的异同点
移动个性化服务是传统个性化服务从互联网到移动终端的延伸,但传统用户个性化服务却不能直接应用到移动用户个性化服务中[6]。两者在服务思想上是类似的,但服务方式有很大差别。要充分考虑用户和终端的移动性,移动用户周围的上下文动态变化,终端设备能力差,实时性要求高等因素。两者具体差异见表1。

表1 传统个性化服务与移动用户个性化服务对比
2 关键技术
为了实现高质量的个性化服务,首先需要对移动用户的特征数据进行采集、存储并分析,挖掘用户的兴趣和行为规律,选取推荐资源的特征进行分类,挑选出适合该用户的资源进行推荐。此外,还必须考虑系统的评价指标。下面分别对用户特征数据、推荐技术、评价方法和评价指标三方面展开进行分析。
2.1 移动用户特征数据
了解移动用户特征数据并进行收集和更新是实现个性化服务的首要任务,下面分别介绍用户特征数据的分类及信息的收集。
2.1.1 移动用户特征数据分类
移动用户特征数据主要包括移动用户信息、环境信息、移动设备信息三大类。
(1)用户信息:主要指描述移动用户的生活和行为的相关信息:①基本信息。例如姓名、性别、年龄、职业、文化程度等;②生活信息。例如性格、生活习惯、消费水平、社会关系等;③行为信息。主要有:用户历史行为记录,例如过去事件发生时间、重复频率等。
(2)环境信息:主要指移动用户所处环境的物理信息:①时空上下文。例如时间、日期、季节、坐标、移动轨迹等;②周围环境。例如公司、学校、餐厅等;③自然因素。例如天气状况、交通状况等。
(3)设备信息:主要包括:①设备能力。描述移动终端硬件的配置,包括CPU、RAM、ROM、分辨率、相机像素、电池容量等;②终端环境。描述终端所在的网络环境状态的信息,如网络带宽、服务质量、信号强度、通信成本等。
2.1.2 信息收集
推荐系统可以显式和隐式两种方式对移动用户信息进行收集[7],但前提是必须征得用户同意并且保证用户隐私不会遭到泄漏。
显式方式是需要用户主动填写自己的基本信息和兴趣爱好,推荐系统在此基础上为移动用户进行推荐,用户对推荐内容进行评价和反馈并促使推荐系统进行改进。隐式方式是推荐系统获取用户的行为动作进行分析从而得到用户的喜好。显式方式比较简单直接,但需要用户进行配合,并且所得到的信息不一定是真实的,当用户不愿意进行反馈或故意反馈错误信息时,此方法不太实用。隐式方式通过用户行为进行分析得到用户喜好且不需要用户配合,可靠性和独立性较高。
2.2 推荐技术分析与比较
个性化推荐可以采用基于规则、基于内容过滤、协作过滤以及混合推荐技术,下面将分别介绍这几种算法的关键技术,并简要分析他们的优缺点。
2.2.1 基于规则的推荐技术
基于规则的技术是指按照已经生成的规则向用户推荐信息的方式。规则一般利用基于关联规则的挖掘技术来发现。
基于规则的推荐系统一般分为三层(如图1所示),由下到上分别是关键词层、描述层和用户接口层。关键词层将用户属性和资源属性抽象为关键词提供给描述层,并定义关键词之间的关系。描述层的个性化规则是动态变化的,用来定义资源描述文件和用户特征数据。用户接口层根据关键词层、描述层定义的个性化规则将满足规则的资源推荐给用户。
基于关联规则的推荐算法[8]可以分为两个阶段,模型建立阶段和模型应用阶段。第一阶段比较费时,需要离线地使用各种关联规则挖掘算法建立关联规则;第二阶段根据已建立的关联规则向用户提供实时的有价值的个性化服务。
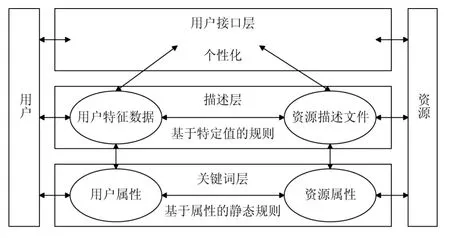
图1 基于规则技术的系统结构
关联规则应用于推荐系统时,存在以下缺点[9]:
(1)数据预处理繁杂。需要提前对系统中的不相关数据和噪音数据进行清洗和处理,换成标准格式。
(2)实时性差。当向系统添加新数据时,需要对系统规则库进行更新,影响系统的推荐准确性和应变程度。
2.2.2 基于内容过滤的推荐技术
基于内容过滤的推荐技术指对资源与用户特征数据进行比较,相似度满足某一阈值时,向用户进行推荐,如图2所示。它的关键问题是相似度计算。
具有如下几个优点:不需要用户的评分数据,有效缓解了系统评分数据稀疏性的问题;通过列出推荐资源的特征数据,可以较好地解释推荐该资源的理由。
然而,基于内容的推荐系统也具有一些难以克服的缺点[10]:
(1)特征提取的能力有限:对某些特殊资源没有有效的特征提取方法。如图像、音乐等媒体资源。
(2)推荐的资源范围狭窄:推荐资源仅仅局限于跟用户以前浏览的类似的资源。无法推荐相关信息,例如某用户购买过鼠标,系统会向用户推荐其它类别的鼠标,而不会推荐键盘等与鼠标相关的商品。
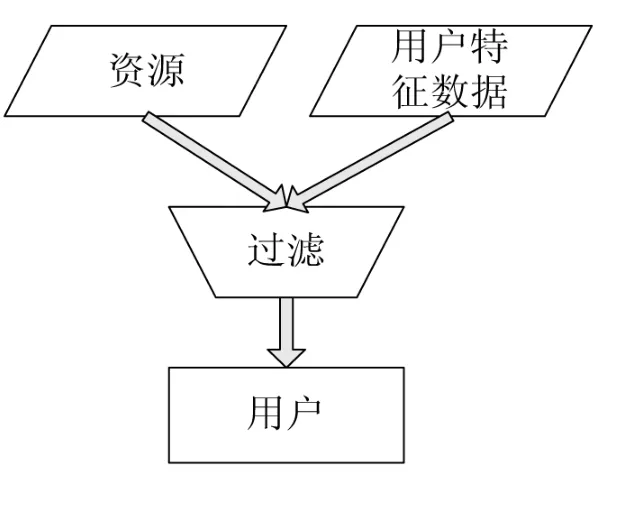
图2 基于内容过滤技术
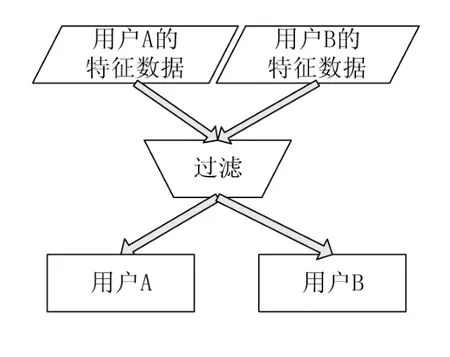
图3 协作过滤技术
2.2.3 协作过滤技术
协作过滤技术是根据相似用户来推荐资源,为用户推荐出新的感兴趣的内容。其关键问题是将用户进行聚类[11]。
和基于内容的过滤方法相比,协作过滤适合于过滤难以分析内容的资源,如图形、图像、视频、音乐等;协作过滤推荐的资源范围大大增加,为用户推荐事先是预料不到的信息。
协作过滤技术在稀疏性和可扩展性存在着问题,系统使用初期没有足够多已获评价的资源,因此很难利用这些评价来发现相似的用户。当系统用户和资源形成一定规模,对存储和比较算法带来困难,该方法性能会越来越低。
2.2.4 混合推荐技术
由于各个单一推荐技术均存在不足,可以按照不同的组合策略(如加权、串联、特征组合等)将多种推荐技术进行组合。
在移动推荐系统中,研究和应用最多的是将协作过滤推荐与基于内容推荐混合起来。根据不同方式将协作过滤和基于内容的方法进行合并,混合推荐可以分为以下四种类型[12]:
(1)以基于内容的方法为主,加入协作过滤的一些特征进行综合运用;
(2)以基于协作过滤的方法为主,加入基于内容的一些特征进行综合运用;
(3)基于内容和协作过滤的方法各自单独实施,评分时进行最终综合预测;
(4)结合基于内容和协作过滤的特征来构建统一通用的模型。
2.2.5 推荐技术的比较
本文采用多个指标对基于规则的技术、基于内容的过滤和协作过滤三种推荐技术进行衡量,比较结果见表2。

表2 推荐技术的比较
从表2可以看到,协作过滤和基于内容的过滤是较好的两种推荐技术,关联规则更适用于在缺乏足够的用户评分数据及资源描述信息的情况。协作过滤技术需要解决数据稀疏性和扩展性差问题。
2.3 推荐系统评价方法与评价指标
对现有的推荐系统评价方法进行了回顾,对准确度、覆盖率评价指标进行多角度阐述。
2.3.1 评价方法
推荐系统的评价方法可分为在线评价和离线评价两种[13]。
在线评价方法根据用户在线实时评分来衡量对推荐资源的满意度。目前最常用的在线测试方法是A/B测试,A/B测试就是为同一个目标制定A方案和B方案,将用户分为两组分别使用两种方案,记录下用户的使用情况,分析哪个方案更符合设计目标。它的核心思想是:1)多种方案并行测试;2)每种方案只有一个变量不同;3)以某种规则优胜劣汰。
离线评价是根据推荐系统在实验数据集上的表现,计算出评价指标来衡量推荐系统的质量。在线测试方式简单直观,但是实验过程所需成本较高。而离线评价方法更加方便经济,只需将推荐系统在选好的数据集上运行即可。
2.3.2 准确度指标
准确度指标指推荐系统在多大程度上能够准确预测用户对推荐商品的喜欢程度。它主要包括预测评分准确度[13,14]和分类准确度,其中预测评分准确度包括平均绝对误差、平均平方误差、均方根误差、标准平均绝对误差,分类准确度包括准确率和召回率。
(1)预测评分准确度
平均绝对误差(MAE)是所有单个观测值与算术平均值的偏差的绝对值的平均。与平均误差相比,平均绝对误差不会出现正负相抵消的情况,因而能更好地反映预测值误差的实际情况。
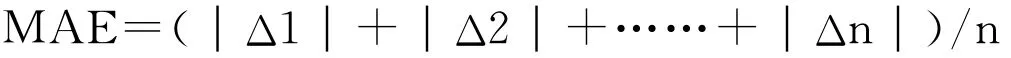
式中Δ1、Δ2、…Δn为各次测量的绝对误差。
此外,平均平方误差(MSE)、均方根误差(RMSE)以及标准平均绝对误差(NMAE)都是与平均绝对误差类似的指标。它们分别定义为:
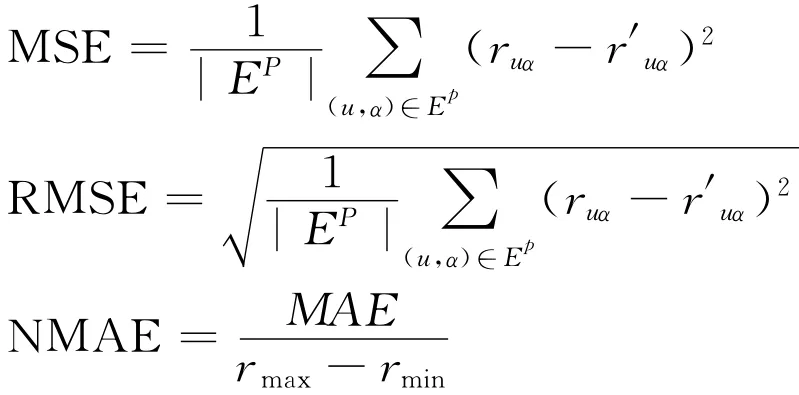
式中,rmax和rmin分别为用户评分区间的最大值和最小值。
(2)分类准确度
准确率和召回率用来评价结果的质量,广泛用于信息检索和统计学分类领域。准确率衡量的是检索系统的查准率。召回率衡量的是检索系统的查全率。
以检索为例,可以把搜索情况分为以下四种:A.检索到且相关;B.检索到但不相关;C.未检索到但相关;D.未检索到的且不相关。准确率和召回率的计算公式为:
准确率=A/(A+B)
召回率=A/(A+C)
(3)覆盖率指标
覆盖率指标是指推荐系统向用户推荐的资源能覆盖全部资源的比例,覆盖率尤其适用于那些需要为用户找出所有感兴趣的资源的系统。覆盖率可以分为预测覆盖率,推荐覆盖率和种类覆盖率3种。
预测覆盖率表示系统可以预测评分的资源占所有资源的比例,公式为:
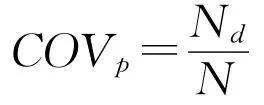
式中,Nd表示系统可以预测评分的资源数目;N为所有资源数目。
推荐覆盖率指系统能够为用户推荐的资源占所有资源的比例,推荐覆盖率与推荐列表的长度L相关。其公式为:
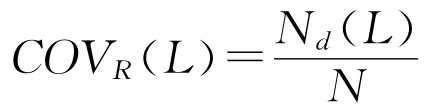
式中,Nd表示所有用户推荐列表中出现过的不相同的资源的个数。推荐覆盖率与系统给用户推荐的资源种类成正比关系。
种类覆盖率(COVC)指推荐系统为用户推荐的资源种类占全部种类的比例。在计算种类覆盖率前要先对资源进行分类。
衡量推荐系统的表现需要用覆盖率和预测准确度一起考虑,保证推荐准确度的同时尽量提高覆盖率。
推荐系统评价指标总结如表3所示。

表3 推荐系统评价指标
3 移动个性化服务典型应用
移动用户需求获取技术应用领域主要有移动搜索、移动推荐、移动社交网络等。本节主要介绍应用软件推荐[15]、移动个性化搜索方面的研究进展。
3.1 应用软件推荐
目前主流的手机操作系统安卓和IOS系统均存在海量各类应用,用户选择存在一定困难。移动推荐系统可以根据用户特征数据获取用户爱好、消费习惯、设备消息、网络环境等信息,挖掘用户、上下文、应用软件之间的潜在关联,为用户提供有效的支持,帮助用户找到符合需求的应用软件。
3.2 个性化搜索
移动搜索对分布在传统互联网和移动互联网上的数据信息进行搜索,满足移动用户的实时性要求。由于移动终端所具有的个人化特性,使移动搜索更容易获取用户的搜索记录、个人信息等内容,从而使用户获得更准确的、满足自己需求的搜索结果。例如,将基于用户信息统计、基于协作过滤的方法与基于关联规则的推荐加以混合,应用到移动搜索。其中,用户统计信息包括用户信息、环境信息、移动设备信息等;协作过滤算法中,通过移动用户的显式评分或隐式推导得到用户的偏好;使用各种关联规则挖掘算法建立关联规则。
4 难点与热点
目前很多移动个性化服务推荐系统大部分都只是研究原型,该技术仍有很多值得研究和探讨的难点与热点,分析如下:
4.1 个人隐私保护与安全问题
移动用户的隐私保护和安全问题严重制约了移动推荐系统的发展。为了给移动用户提供准确的推荐,移动推荐系统需要记录并分析移动用户的信息、行为、位置等,但一旦移动推荐系统遭受攻击导致信息泄露,用户的隐私将得不到保证。因此移动推荐系统必须征得用户允许才能获取用户信息,对用户敏感隐私如真实姓名、手机号、身份证号、银行卡号进行加密处理,为了缓解由于信息集中带来的安全问题,移动推荐系统数据采用分布式存储,避免了用户信息集中的问题。
4.2 冷启动问题
对首次使用系统的移动用户,由于系统没有或只有少量关于该用户的信息,因此暂时不能准确地获取用户偏好并对其提供有效的资源。新资源问题是指新加入的资源暂时没有移动用户对其浏览并评价,在使用基于协作过滤的推荐系统中,由于新资源没有被移动用户浏览或评分,因此不能被推荐。
4.3 信息共享问题
目前大多数互联网公司提供个性化服务是相互独立的,如果各公司所获得的用户特征数据以及提供过的个性化服务历史记录及用户评价进行共享,建立一个综合用户特征数据,将会大大提高个性化服务的有效性和准确性,但这也涉及到上文所提到的安全问题,信息共享会使用户隐私及信息更容易遭到窃取和滥用,各大互联网公司为了自身利益也很难达成一致形成信息共享,因此个性化服务信息共享仍需要进一步研究找出移动用户、互联网公司双赢的模式。
5 结束语
为移动用户提供个性化服务的目标是方便移动用户高质量获取信息,因此在学术界和工业界广泛关注和努力解决的关键问题是怎样提高移动推荐的性能与质量,要达到这一目标,目前仍然有大量问题需要进行深入细致的研究和突破。本文只是对移动个性化服务的基本内涵、用户特征数据获取技术、推荐技术、系统模型及其应用的研究进展、难点与热点进行分析、归纳与总结,整体上对该方向的研究现状给予分析与描述,希望能对该领域相关研究感兴趣的读者有所帮助。
[1] 曾春,邢春晓,周立柱.个性化服务技术综述[J].软件学报,2002,(10):1952-1961.
[2] 王立才,孟祥武,张玉洁.上下文感知推荐系统[J].软件学报,2012,(1):1-20.
[3] Meng XW,Hu X,Wang LC,Zhang YJ.Mobile recommender systems and their applications.Ruan Jian Xue Bao/Journal of Software,2013,24(1):91 108 (in Chinese with English abstract).http://www.jos.org.cn/1000-9825/4292.htm [doi:10.3724/SP.J.1001.2013.04292]
[4] Pérez IJ,Cabrerizo FJ,Enrique HV.A mobile decision support system for dynamic group decision-making problems.IEEE Trans.on Systems,Man,and Cybernetics-Part A:Systems and Humans,2010,40(6):1244 1256.[doi:10.1109/TSMCA.2010.2046732]
[5] Gibson W.Implementing apersonalized and location based service for delivering advertisements to android mobile users.European Journal of Innovation and Business,2013,10(1):15.
[6] Adomavicius G,Tuzhilin A.Context-Aware Recommender Systems.In:Ricci F,Rokach L,Shapira B,Kantor PB,eds.Recommender Systems Handbook.Springer-Verlag,2011.217 253.[doi:10.1007/978-0-387-85820-3_7]
[7] 孟祥武,王凡,史艳翠,张玉洁.移动用户需求获取技术及其应用[J].软件学报,2014,03:439-456.
[8] Sarwar,B.,Karypis,G.,Konstan,J.,and Riedl,J.Analysis of Recommendation Algorithms for E-Commerce.ACM Conference on Electronic Commerce,2000.
[9] 高建煌.个性化推荐系统技术与应用[D].中国科学技术大学,2010.
[10] 曾春,邢春晓,周立柱.基于内容过滤的个性化搜索算法[J].软件学报,2003,(5):999-1004.
[11] 纪良浩,王国胤.基于协作过滤的个性化服务技术研究[J].计算机工程与设计,2008,(4):983-986.
[12] 李春,朱珍民,叶剑,周佳颖.个性化服务研究综述[J].计算机应用研究,2009,(11):4001-4005.
[13] 朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,(2):163-175.
[14] 宋青,汪小帆.最短路径算法加速技术研究综述[J].电子科技大学学报,2012,(2):176-184.
[15] 孟祥武,胡勋,王立才,张玉洁.移动推荐系统及其应用[J].软件学报,2013,(1):91-108.
猜你喜欢
文苑(2020年4期)2020-05-30
作文成功之路·小学版(2019年8期)2019-09-18
新闻传播(2018年12期)2018-09-19
读者(2017年14期)2017-06-27
汽车与新动力(2016年6期)2017-01-04
现代商贸工业(2016年22期)2016-12-27
电脑知识与技术(2016年25期)2016-11-16
读写算(下)(2016年9期)2016-02-27
金融理财(2015年7期)2015-07-15
电子工业专用设备(2015年4期)2015-05-26
