
Web数据挖掘在校园网搜索引擎系统中的应用研究
2014-04-29 01:17:17牛凯
中国信息化 2014年11期
牛凯
随着数字化校园的迅速发展,搜索引擎技术得到广泛应用,Web数据挖掘作为数据挖掘技术的一种也应运而生。搜索引擎是基于Web数据挖掘的一个重要研究方向,校园网信息每天以不可估量的速度增长,数以万计的网页资源让师生在浩瀚的信息海洋中眼花缭乱,而搜索引擎的出现则很好的解决了这一现实问题。Web数据挖掘能够从大量的Web文档和网页中抽取出师生感兴趣的、潜在的、隐含的信息,为校园网搜索引擎系统提供了强有力的技术支持。
1.Web数据挖掘技术
随着信息时代的飞速发展,互联网己成为人们获取信息的重要途径。网络作为信息资源平台,为人们的日常生活提供了便利快捷的服务。然而,在大量的网络信息面前, 如何不被淹没,如何从海量信息中及时发现提取有价值的信息,成为互联网信息检索面临的首要问题。面对这一挑战, Web数据挖掘技术提供了一种比较好的解决方法。Web数据挖掘技术包括数据库、计算机网络和人工智能技术,Web数据挖掘技术使用了很多数据挖掘技术,但是它并不是传统数据挖掘技术的一个简单应用,它是一个新的研究领域。Web数据挖掘技术一般分为Web结构挖掘、Web内容挖掘、Web日志挖掘三类。Web内容挖掘是指利用某种算法策略对网络资源进行抽取,以期发现有用的知识,常用的策略有总结、分类、聚类和关联分析等。Web页面内部结构挖掘与外部结构(链接分析)是Web结构挖掘的两个主要研究方向,内部结构挖掘应用于信息抽取、网站结构模式提取和页面分类,链接分析则主要应用于搜索引擎领域。Web日志挖掘主要通过识别用户浏览模式,并通过改进Web站点结构,达到用户能够更加方便浏览的目的,以此来吸引更多的用户访问站点。
Web数据挖掘与搜索引擎联系紧密,校园网搜索引擎除了使用传统搜索引擎相关的理论和技术方法外,还需要新的方法和技术来满足学校师生要求,Web数据挖掘的很多技术可以应用在校园网的搜索引擎中,Web内容挖掘能对互联网上海量的网页信息进行总结、分类、集群、关联分析和趋势预测等。通过对网页内容的挖掘,可以实现网页的聚类和分类,能够对网络信息进行分类浏览和检索,从而提高网络信息的标引准确度,提高检索效率。
根据数据挖掘的一般方法和相关理论,可以得出Web数据挖掘的流程图,如图1所示。
网络数据的收集主要是从Web站点上的数据信息中提取一个数据子集,主要包括页面数据、超链接信息和用户的访问历史记录等,为数据挖掘提供资源支持。数据的预处理主要是对数据源进行组织重构和加工处理,并以此构建主题数据库,为Web数据挖掘提供相应的平台。模式发现及分析是Web数据挖掘最核心的部分,它主要是通过运用各种数据挖掘技术,从数据对象中发现潜在的、能被人所理解的知识模式,并最终发现描述性模式和预测性模式。
2.校园网搜索引擎系统架构设计
2.1 整体框架模型设计
校园网搜索引擎系统设计以智能化为目标,最大程度上满足学校师生不同需求的查询。系统首先收集海量的网页信息,然后搜索引擎程序会自动对收集到的网页内容进行分析,并通过分词程序得到语句关键词,再利用索引来构建索引数据库。当用户通过Web页面来查询索引数据库时,系统就会返回所有与检索关键词相匹配的网页。一个搜索引擎系统主要由以下四部分组成,分别是:页面采集模块、页面分析模块、索引数据库模块和信息检索模块。从功能上来说,四部分内容既相互独立,又相互联系,形成一个有机的整体。搜索引擎系统架构如图2所示。
2.2 系统模块设计
本文设计的校园网搜索引擎系统与传统搜索引擎系统的主要不同之处是搜索引擎被分解为多个任务不同的专业搜索引擎, 每个专业搜索引擎只搜索特定相关的信息。该搜索引擎系统主要包括5个模块。
(1)信息抓取模块:搜索引擎系统首先收集用户所要查询关键词和搜索引擎返回的查询结果,并对收集到的数据进行预处理。
(2)概念提取模块:系统从收集到的搜索结果中选取前100条数据,进行概念提取,然后将提取到的概念存入相应数据库。最后,搜索引擎系统计算概念联系度并将计算结果存储到数据库中,为后面的概念聚类做好准备。
(3)用户建模模块:系统针对用户的搜索关键字进行概念提取,从而获得用户感兴趣的相关概念,然后,根据已经建立的概念联系,确定与用户搜索关键字有联系的概念。
(4)查询概念聚类模块:系统根据用户兴趣模型建立查询概念二分图,然后使用基于查询概念的二分图聚类算法对查询和概念分别进行聚类。
(5)查询优化模块:聚类形成相似的查询和相似的概念,相似的查询用以优化查询语句,优化后的查询语句由系统提交给搜索引擎。相似的概念以搜索建议的形式提供给用户,系统根据用户兴趣模型产生聚类结果。
3.Web数据挖掘技术在数字化校园中的应用
在数字化校园建设中,主要以教师和学生为主体,如何更好地协调教师和学生的关系是数据挖掘首要考虑的问题。本文以学生的数字化校园中的基本信息作为基础信息,通过对学校的各个子库的个人信息进行加工处理,运用简单的统计方法对每个子库信息进行聚合,从而得到进行数据挖掘的基本信息。
搜索引擎系统首先需要将不同的数据源集中到统一的数据仓库中,执行数据的清洗和转换操作。为了方便不同数据仓库之间的数据交换,采用统一的数据挖掘元数据模型。Web数据挖掘技术利用统一的驱动程序存取数据仓库中的数据,并且采用统一的结果模型表示形式,应用程序通过统一的接口访问数据挖掘服务。数据挖掘应用程序构架如图3所示,其中Data是待挖掘数据,存放在关系数据库或文件中。Data Access获取文件、数据库或视图中的数据,并将数据保存到数据仓库。数据源可以来自分布式和远程数据库。Data Warehouse用来存放待挖掘的数据,Driver提供统一的数据库驱动程序,DMT提供不同的算法为应用程序服务。数据挖掘算法(DMM)在数据上应用所得的结果,不同DMT之间可以相互调用数据挖掘模型,用于结果应用、评估和可视化。Application是客户端应用程序,调用一个或多个数据挖掘服务,得到数据挖掘的结果模型,从而获得决策需要的信息。
Web数据挖掘中,应用关联分析技术寻找网页信息库中的值的相关性,应用分类方法分析进行网页信息库中的web数据的分析,这样能够为每个类别实现数据模型建立、分类规则挖掘、从而对数据类别做出准确的描述,另外应用聚类方法对网页信息库中的记录数据进行分析,也就是对记录集合进行合理的规划并对每个记录所在的类别进行确定。这样就能精炼出一个集成度高、易于使用、冗余度地的索引数据库,方便师生的信息检索和查找。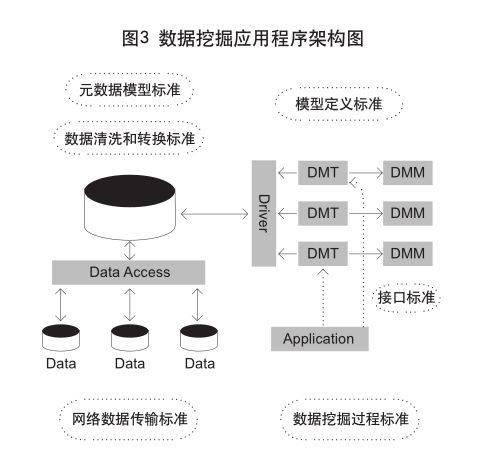
4.结论
Web数据挖掘技术是一个新兴的且有着巨大发展前景的研究领域,经过众多研究者的努力,已经取得了一些成果,在校园网搜索系统的应用中起到了很大的推动作用,但是要想将Web数据挖掘技术普及推广到校园数字化建设中,还需要相当多的工作,还需要不断深入研究。
作者单位:天津职业技术师范大学 信息技术学院
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
甘肃教育(2020年18期)2020-10-28 09:05:54
电子制作(2019年10期)2019-06-17 11:45:26
电子制作(2017年8期)2017-06-05 09:36:15
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
中国卫生(2015年12期)2015-11-10 05:13:38
电子设计工程(2015年17期)2015-02-27 12:08:04
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
