
基于动态递归神经网络的洪水灾害损失预测
2014-04-27 10:03:12何树红杨博戴明爽
经济师 2014年5期
●何树红 杨博 戴明爽
基于动态递归神经网络的洪水灾害损失预测
●何树红 杨博 戴明爽
对洪水灾害损失进行预测,旨在为我国巨灾保险产品的创新提供新的理论依据。神经网络自身的联想能力决定了它在预测方面有比较大的优势,特别是在处理洪水灾害损失这类动态问题上,Elman动态神经网络能很好地预测洪水灾害损失,与静态神经网络相比,预测所得结果的精度进一步提高。
洪水灾害 损失预测 神经网络
关于洪水灾害损失的预测,我国目前仍处于起步阶段。常采用定性分析的方法,分析得出有关影响因素,并且进一步分析各因素对洪水灾害影响作用的大小。例如杨凯在对包括洪水灾害的巨灾风险进行分析之后指出我国巨灾风险最大的问题是:相关保险的供给不足,需求也不足。其中的根本原因是:国民的巨灾保险意识薄弱,巨灾保险存在再保险困难,巨灾保险目标市场难以确认;但是这些理论研究对我国如何防范洪水灾害风险的借鉴性比较小。洪水灾害风险防范的核心问题在于洪水灾害损失的预测,近年来有学者将数学模型引入到了洪水灾害损失预测,例如张正建立了洪水灾害损失的数学预测模型,通过利用历史数据,来完成对未来数据的预测。可这种研究方式有一个前提假设,即洪水灾害损失是一个静态问题,但是洪水灾害损失是否是一个静态问题值得商榷。
针对洪水灾害损失的特点,本文对其损失的预测将按照以下三个步骤进行。首先,需要对洪水灾害的影响因素进行分析;其次,本文分别利用静态神经网络和动态神经网络分别对洪水灾害损失进行预测,根据预测所的结果的精度来确定洪水灾害损失属于静态问题还是动态问题;最后,利用相应的神经网络对洪水灾害损失进行建模,从而实现洪水灾害损失预测。
一、洪水灾害的主要影响因素
(一)降雨量和持续时间
降雨量和降雨持续时间是洪水灾害发生的最直接的两个因素。洪水灾害的发生往往伴随着强降雨的发生。强降雨主要导致两方面的结果:一段时间内地面排水系统的排水量严重小于降雨量、山体表面的吸水能力严重小于降雨量。可是,仅仅依靠强降雨量来造成洪水灾害往往是不可能的。因为即使降雨量再大,持续时间过短,所造成的积水持续时间很短,对于山体的冲刷力度往往不足以造成洪水灾害。所以强降雨量加上较长的持续时间才会造成城市积水严重以及山体滑坡、泥石流等灾害。这两个因素对于洪水灾害的造成缺一不可。
(二)土质结构
土质是指土壤的构造和性质。我国国土幅员辽阔,不同地区之间的土质结构往往不同。我国的土质分为八类土,级别由低到高分别为:松软土、普通土、坚土、砂砾坚土、软石、次坚石、坚石、特坚石。级别越高,土壤中所含岩石成分就越高,土质也就越坚固。所以,在洪水发生的时候,在土质级别较低的地区容易发生泥石流等灾害,而土质级别越高的地方发生泥石流灾害的可能比较小。
(三)建筑物坚固程度
建筑物的坚固程度是指建筑物对于洪水灾害的抵抗能力。洪水灾害发生对建筑物的影响主要有三方面:第一,洪水发生时对建筑物的直接冲击作用,这种冲击力一般比较大,通常情况下结构性能较差的房屋会直接被这种冲击力冲毁。第二,洪水的不断冲刷使会使墙体的砂浆流失,砂浆的饱和程度下降,进而使墙体强度下降。第三,洪水灾害发生后,建筑物会长期浸泡在水中,水分子会不断进入土颗粒之间,破坏墙体结构,进而会导致建筑物开裂,结构受损。
(四)该地区洪水灾害的历史情况
该地区洪水灾害的历史情况是指该地区以前是否发生过洪水灾害。一次洪水灾害的发生所造成的灾难并不是在这次洪水灾害结束后就全部结束了,有可能上次洪水灾害已经造成了灾害但是没有显示出来,这对下次洪水发生时造成更大的灾难做了铺垫,所以发生过洪水灾害和没有发生过洪水灾害的地区两者相比,相同程度的洪水灾害在发生过洪水灾害的地区所造成的损失更大。
(五)排水力度
排水设施是指一个地区的积水排放效率和能力。一个城市是否容易造成积水,在不出现特大强降雨量的情况下,排水力度是决定因素。排水力度与能否造成城市积水呈反向关系,即排水力度好的城市产生严重积水的可能性就越小。
二、BP神经网络与Elman神经网络
(一)BP神经网络的结构
BP神经网络是最经典的静态神经网络,其核心思想是将BP算法运用到人工神经网络。它是由美国加利福尼亚的PDP(parallel distributed procession)小组将1974年P.Werbos在其博士论文中提出的适合多层网络的学习算法运用到神经网络所产生,其结构如图1所示。BP神经网络具有人工神经网络所具有的一切特点,但与一般人工神经网络不同的是:BP神经网络的学习过程由信号的正向传播与误差的反向传播两个过程组成,正向传播时,输入样本从输入层传入,经各隐藏层逐层处理后,传向输出层。若输出层的实际输出与期望的输出不符,则转入误差的反向传播阶段。误差反传是将输出误差以各种形式通过隐藏层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层的误差信号,此误差信号即作为修正各单元权值的依据。这种信号正向传播与反向传播的各层权值调整过程,是周而复始地进行的。一直进行到网络输出的误差减少到可接受的程度,或者到预先设定的学习次数为止。
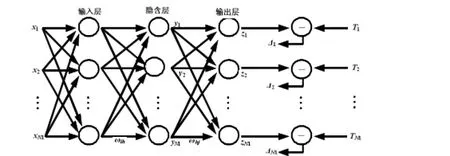
图1 BP神经网络结构图
(二)Elman神经网络的结构
Elman动态递归神经网络是一种典型的动态神经网络,它由Elman在1990年提出,其过程如图2所示。这种网络具有与MLP网络相似的多层结构,但与MLP网络不同的是,Elman网络接收两种信号,一种是外部输入的信号U(t),另一种是来自隐含层的反馈信号XC(t)。因为它除了普通隐含层以外,还有一个单元延迟模块(有时称为承接层),该层从普通隐含层接收反馈信号,承接层内的神经元输出被前向输出至隐含层。这里引入承接层的思想是通过对前馈神经网络中附加状态反馈神经元来描述系统的非线性动态行为。隐含层不仅接受来自输入层的信号,还接受隐含层节点自身的一步延时信号(来自承接层),这样承接层就记忆了上一个模式的网络状态。由此可见,承接层能存储系统过去的信息,从而增加网络对动态信息的处理能力。

图2 标准Elman网络
隐藏层输出:XC(t)
单位延迟模块:XC(t)=X(t-1)
输出层输出:Y(t+1)=WX(t+1)
(三)Elman网络相对于BP神经网络的特点
1.Elman神经网络具有特殊的结构。Elman网络保留了前馈神经网络的基本结构。但是与前馈神经网络不同的是,Elman加入了承接层。承接层的加入就意味着网络多了一个记录信息的单元。而这个单元可以使隐藏层的输出得到延迟和存储,然后将存储的信息与下一时刻隐藏层的输入自联。这就加强了网络对历史数据的敏感性与动态信息处理的能力,从而达到动态建模目的。
2.Elman神经网络中隐藏层与输出层神经元结构搭配特殊。隐藏层的神经元为tansig神经元,输出层的神经元为purelin神经元,这两种神经元的组合可以使得网络以任意精度去逼近任意函数。并且,训练时间并不会因为逼近对象的复杂性增加而大幅度增加,只需相应增加隐藏神经元数目即可。
3.Elman神经网络具有动态性的优点。Elman神经网络由于其特殊的网络结构,本身具有动态性的特点,所以对于动态问题具有更好的处理效果,不仅可以使网络具有非线性的动态特征,同时还可以避免静态神经网络无法实时改变模型结构以及缺乏对未来突变情况适应性的缺点。
4.Elman神经网络与静态神经网络相比具有双重联接的特性,即Elman神经网络不仅具有前馈联接,同时还具有反馈联接。这个特性使Elman神经网络可以避免前向型神经网络易陷入局部最小点、收敛速度慢的情况。
三、建立洪水灾害损失预测模型
利用神经网络建模,通常包括以下3个阶段:数据的收集及处理、设计神经网络结构、训练神经网络。
(一)数据的收集及处理
数据的收集及处理是利用神经网络建模的基础,同时也是泛化能力能否实现的关键。数据的收集及处理主要内容有:采集问题相关的原始数据、数据的预处理、数据样本容量是否达标。
采集相关的原始数据是指根据问题需要,查找相关的数据,并且保证数据的真实性。
样本容量的多少主要由两方面决定:一个是网络的复杂程度;另一个是数据中的噪声大小。最后须将与处理之后的数据进行分类,分为训练数据和检验数据,从而形成所需的训练样本和检测样本。
数据的预处理是一个比较重要的环节。在进行预测的时候,我们不能将原始数据输入至网络进行训练,特别是要进行多种数据预测时,因为原始数据有时候相差比较大,达到几倍或者几十倍。为了防止大数据将小数据的信息湮没,就必须对数据进行预处理。最常用的数据处理方法为归一化处理。归一化是指把某向量除以该向量的长度,而使其长度为1,使得网络输入的数值都在0和1之间。归一化的公式为:
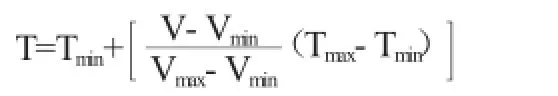
输出则按照:

还原回来即可。
其中:Vmax:该向量可能达到的最大值
Vmin:该向量可能达到的最小值
Tmax:与Vmax相对应的归一化后的最大值
Tmin:与Vmin相对应的归一化后的最小值
T:为实际值V的归一化值
(二)网络结构设计
1.网络层数。Elman动态递归神经网络与BP神经网络在结构上的不同就是相对于BP神经网络,Elman动态递归神经网络多了一个承接层。但是承接层具体的结构不用去设计。我们只需像BP神经网络一样设置输入层、隐藏层、输出层即可。因为Elman本身具有BP神经网络的特点,所以一个隐藏层的Elman神经网络在神经元足够大的情况下,可以无限逼近输入与输出的线性关系。所以在这里我们依然采用一个隐藏层的Elman动态递归神经网络。
2.输入层神经元个数的确定。输入层起缓冲存储器的作用,它接收外部的输入数据,因此神经网络的输入层神经元个数由输入向量的维数决定。
3.隐藏层神经元个数的确定。隐藏层神经元的作用是从样本中提取并存储其内在规律,每个节点有若干个权值,而每个权值都是增强网络映射能力的一个参数。而确定神经网络隐藏层神经元个数的最常用方法是试凑法。只不过对于不同的神经网络采用的经验公式不同。BP神经网络可先设置较少的隐藏元神经个数训练网络,然后逐渐增加隐藏层神经元个数,用同一样本集进行训练,从中确定网络误差最小时对应的隐藏层神经元个数。BP神经网络隐藏层神经元个数常用的经验公式为+c。其中,m表示隐藏层神经元个数,a表示输入层的神经元个数,b表示输出层神经元的个数,c表示1~10之间的一个常数。而Elman动态递归神经网络确定隐藏层神经元个数的方法根据输出单元和输入单元的多少分为两种:第一种是当输入单元和输出单元比较多的情况下,采用公式,确定其起始值,然后再逐个增加确定神经元个数;第二种是当输入单元和输出单元比较少的情况下,采用公式m=2a+d,确定其起始值,然后再逐个增加,通过试探来确定隐藏层神经元个数。其中,m、a、b的含义同前,d表示1~10之间的一个常数。
4.输出层神经元个数的确定。输出层起释放存储器的作用,它是网络利用它本身的泛化能力将所得结果输出。因此神经网络的输出层神经元个数由输出向量的分量个数决定。
(三)网络的训练、检验
神经网络结构确定好之后,就可以分别利用训练样本和检测样本进行训练和检测。
神经网络的训练是指利用样本数据修改连接权值或者阀值的过程。使其最终达到能够反映出训练样本数据中输入向量和输出向量的隐含关系。神经网络的训练并非训练的次数越多越好。这是因为我们所收集到的数据是含有噪声的,虽然通过归一化处理,可以减小噪声。但是神经网络的训练过程是一个反复利用样本数据的过程,过多的训练会使得包含噪声的数据被刻画的很具体,从而对输入向量与输出向量的正确映射关系造成影响。
神经网络的检验是指利用检验样本对已经训练好的网络进行检验,并根据输出结果与真实值对比,利用一定的误差标准来确定网络的适应性,以及是否具有泛化能力。泛化能力是衡量网络性能的主要标准,而并非输出结果与真实值的拟合程度。所以这就是检验的必要性的体现。如果利用检测样本得出网络具有泛化能力的结论,我们便可以对洪水灾害损失进行预测。
四、实证分析
本文将利用静态神经网络中的BP神经网络和动态神经网络中的Elman神经网络分别对洪水灾害的损失进行模拟。输入向量采用洪水灾害最直接的两个影响因素:降雨量和持续时间,而输出向量则采用最重要的洪水灾害损失。
(一)洪水灾害损失数据
由于我国洪水灾害管理体系不健全,数据收录不完全,本文所采用的19组数据来源于2005-2012年有准确数据可查的19次洪水灾害数据。
本文将采用14次洪水灾害的数据作为网络的训练样本,5次洪水灾害的数据作为检测样本。
(二)网络结构的设计
1.输入层神经元个数的确定。本文洪水灾害损失预测模型的输入向量的维数为2,所以输入层的神经元个数为2。
2.输出层神经元个数的确定。本文洪水灾害损失预测模型的输出向量中只有一个分量,故输入层的神经元个数就确定为1。
3.隐藏层神经元个数的确定。由于本文输入神经元个数与输出神经元个数较少,所以BP神经网络隐藏层神经元的个数根据经验公式确定为2,Elman神经网络隐藏层神经元个数确定为5。
(三)网络的训练
BP神经网络与Elman神经网络的结构设计好之后,就利用训练样本对其进行训练。对于BP神经网络分别建立隐藏层神经元个数为2至11个的10种神经网络,对于Elman神经网络分别建立隐藏层神经元个数为5至14个的10种神经网络。训练误差为0.05,最多训练次数为1000次。利用训练样本开始进行训练。
(四)实验结果与分析
神经元个数为2至11的BP神经网络与神经元个数为5至14的Elman动态递归神经网络的均方误差对比如表1所示。
从表1中我们可以得出以下结论:
1.Elman动态递归神经网络针对于BP神经网络在处理洪水灾害损失具有明显的优越性。用BP神经网络处理洪水灾害损失预测,误差容易出现。
2.根据静态神经网络与动态神经网络模拟结果的对比,实际数值与动态神经网络模拟所得结果更为接近,所以洪水灾害损失预测应该为动态问题。
3.本文最终模型定为隐藏层神经元个数为10的Elman动态递归神经网络,因为这个网络的均方误差已经为0.011092,已经非常精确。再增加神经元个数不但预测精度没有得到大幅度提高,反而会导致网络的复杂程度增加。

表1 两种神经网络的均方误差对比表
(五)模型的检验
利用事先准备好的检测样本,用训练好的Elman神经网络进行洪水灾害损失的预测,为了对比方便,本文在检验时同样利用BP神经网络进行了检验。在经过反归一化数据还原后,与实际损失数据进行对比,数据如表2所示:
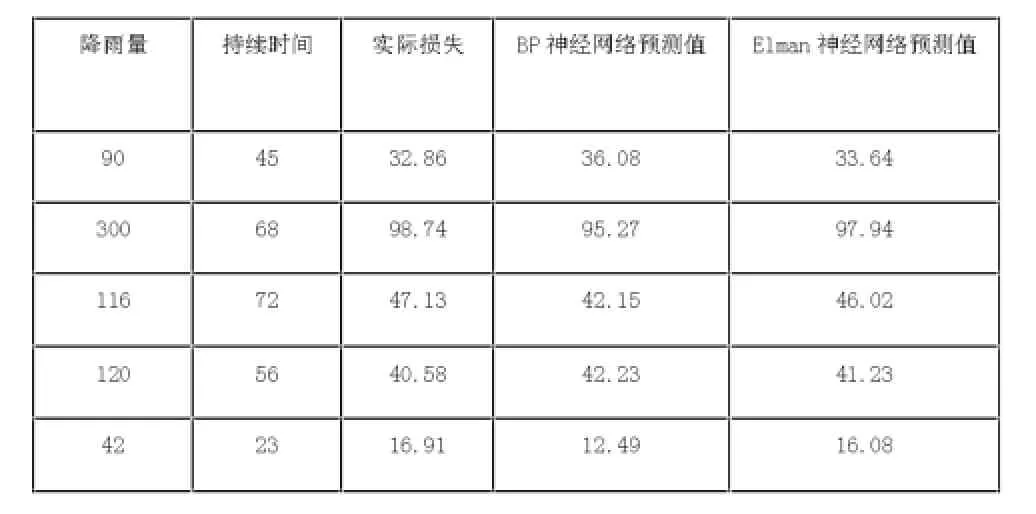
表2 实际损失与预测损失对比表
从表2中我们可以发现:
1.五次洪水灾害的实际损失为32.86、98.74、47.13、40.58、16.91亿元,而根据BP神经网络预测的洪水灾害损失为36.08、95.27、42.15、42.23、12、49亿元。偏差率分别为9.8%、3.5%、10.6%、4.1%、26.1%,平均偏差率为10.8%。由此我们可知BP神经网络预测得到的结果虽然大致可以预测洪水灾害的损失,但是精度差强人意。
2.根据Elman动态递归神经网络预测得到的洪水灾害损失分别为33.64、97.94、46.02、41.23、16.08亿元,偏差率分别为2.4%、0.8%、2.4%、1.6%、4.9%,平均偏差率为2.4%。由此我们可知Elman动态递归神经网络的预测精度比BP神经网络及改进后的BP神经网络的预测精度都要高,偏差也比较小。平均偏差率控制在了3%以下,预测效果较好。
3.造成BP神经网络与Elman动态递归神经网络平均偏差率相差较大的原因主要是因为第五组数据所造成,而第五组数据是来源于湖南的洞庭湖地区,这个地区就属于洪水灾害经常发生的地方。可见对于洪水灾害发生比较少的地方BP神经网络所得结果还勉强可以接受,但是对于经常发生洪水灾害的地区,就不能使用静态神经网络来进行模拟,否则误差会比较大。
五、结语
在实际运用当中,可以通过下述途径完成预测:首先,收集气象台在每次强降雨来临之前提供的预计降雨量、预计降雨时间这两个数据。其次,对数据进行归一化处理,做成神经网络的输入向量;最后,输入准备好的输入向量,利用训练好的Elman动态递归神经网络的联想能力,得到输出向量。对输出向量进行反归一化后,就可以得到洪水灾害损失的预测值。这将为我国巨灾风险证券化提供一个坚实的基础。
[1]何树红,杨博,戴明爽.基于动态递归神经网络的石油价格预测[J].云南民族大学学报(自然科学版),2013(1)
[2]杨凯,齐忠英,黄凤.我国发展巨灾保险所面临的供需不足分析及建议[J].商业研究,2006(6)
[3]张正,黄泰松,左春.基于BP神经网络的灾情预测模型[J].计算机工程,2005(1)
[4]施彦,力群,廉小亲.神经网络设计方法与实例分析[M].北京:北京邮电大学出版社,2009
[5]张良均,曹晶,蒋世忠.神经网络使用教程[M].北京:机械工业出版社,2009
[6]周开利,康耀红.神经网络模型及其MATLAB仿真程序设计[M].北京:清华大学出版社,2005
(责编:贾伟)
F840.69
A
1004-4914(2014)05-016-04
教育部人文社会科学研究一般项目(11YJA790040)】
何树红,博士,云南大学经济学院教授,硕士生导师,研究方向:数理金融与风险管理;杨博,云南大学数学与统计学院在读硕士;戴明爽,云南大学经济学院在读硕士云南昆明 650091)
猜你喜欢
自然杂志(2021年6期)2021-12-23 08:24:46
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
娃娃乐园·综合智能(2019年6期)2019-07-10 00:37:32
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
现代装饰(2018年5期)2018-05-26 09:09:01
天津诗人(2017年2期)2017-11-29 01:24:25
幼儿画刊(2016年8期)2016-02-28 21:00:52
电源技术(2015年5期)2015-08-22 11:18:38
