
英汉双向哲学社科术语词典系统设计与实现
2014-04-03 05:18:30刘伍颖梁晓波
中国科技术语 2014年2期
王 琳 刘伍颖 梁晓波
(1.国防科学技术大学,湖南长沙 410073;2.解放军外国语学院,河南洛阳 471003)
公元1799年在埃及发现的罗塞塔石碑(Rosetta Stone)制作于公元前196年。石碑上用三种不同文字(古埃及象形文Hieroglyphic、古埃及草书文 Demotic、古希腊文)平行刻着古埃及法老Ptolemy V的诏书。到近代古希腊文还是可阅读的,通过比对分析,人类破译了两种失传已久的古埃及文字的意义。
公元1909年在中国内蒙古额济纳旗发现的木刻雕版印刷纸本《番漢合時掌中珠》刊行于西夏乾祐21年(公元1190年),是一本西夏文和汉文双向双解注音词典,编者是西夏人骨勒茂才。书前有西夏文和汉文平行序言,“……不學番言,則豈和番人之眾;不會漢語,則豈入漢人之數……”表明该书目的在于方便西夏人和汉人互相学习对方语言。目前该书成为研究和破译西夏文的关键工具书。
罗塞塔石碑的多语平行文本设计、《番漢合時掌中珠》的双向双解设计在当时都是十分先进和实用的,对后世也产生了深远影响。当前大数据背景下,如何利用双语平行文本[1]和双向信息检索技术对术语大数据进行处理成为极具挑战的研究课题。
一 相关研究现状与研究意义
文章开始处的例子说明多语种平行文本和双语词典历来就是人类沟通不同语种的重要方法。随着计算机和网络的普及,这些古老的方法借助现代手段焕发出新的生命力。如金山词霸、有道词典、灵格斯(Lingoes)、Babylon、句酷等已经成为主流的电子词典和翻译软件。又如维基百科(Wikipedia)、微软(Microsoft)、谷歌(Google)等在多语种处理方面也是成果丰富。
金山词霸是金山公司推出的电子词典,收录了140多本版权词典。有道词典是网易有道推出的电子词典,它利用大数据挖掘技术对有道搜索引擎爬取的网页大数据进行处理,得到海量汉语与外语的平行文本,以此支撑词语和例句的查询。灵格斯是由凯文(Kevin)个人开发的翻译与词典软件,支持80多个国家语言的词语查询和全文翻译。Babylon是一款提供翻译和词典服务的桌面软件,它的多语种词典是由Babylon所属的语言专家开发出来的。句酷是北京邮电大学开发的双语例句搜索引擎,已积累了上千万的双语例句。
维基百科是一种借助维基技术开发的多语种百科知识库,它公布了截至2011年底因特网上最主要的35种网页内容语种。微软的Windows Phone 8手机操作系统能为用户提供50种不同国家和地区语种支持,微软的Windows 8操作系统支持多达109种语种。谷歌翻译目前可提供64种语言之间的即时翻译,而且还启动了濒危语言计划以挽救3054种濒危语种。
上述相关研究已经取得了很多产品级的应用成果。在技术上的启示是把桌面软件与网络数据库衔接起来,既有本地基本数据库,又有在线大数据库;借助搜索引擎网络爬虫技术和Wiki技术[2]不断扩充后台大数据库;词典与句典相结合,词语查询向机器翻译迈进。然而已有的产品在使用时还是暴露出一些不足。如大部分电子词典为了追求词量,把各种词典机械合成,造成结果重复、冗长、杂乱、大而不精;专业术语存在较多的翻译错误,或者根本查不到相关的专业术语等。
随着2010年底美国《规划数字化未来》报告的出炉,美国政府2012年投入2亿美元启动大数据研究发展倡议,大数据时代已经来临。微软研究院出版的《第四范式:数据密集型的科学发现》论文集全面描述了快速兴起的数据密集型科学研究,从理论上指导着大数据挖掘的方向。在大数据背景下,哲学和社会科学的飞速发展、计算技术和网络技术的不断进步、国际交流的日益深化使得多语种哲学社科术语不断涌现。本文对英汉双向哲学社科术语词典系统的构建方法进行了探索,对限定领域[3]的双向网络术语词典构建进行了尝试。目的是利用计算机和网络促进术语使用处理的规范化与标准化[4]、增强哲学社科术语翻译的准确性、提升使用者的英文文献阅读理解和写作能力。
二 架构设计与系统功能
英汉双向哲学社科术语词典系统(哲译通)是一套基于网络B/S架构的Web应用系统。哲译通系统架构如图1所示,总体上分为两大部分。
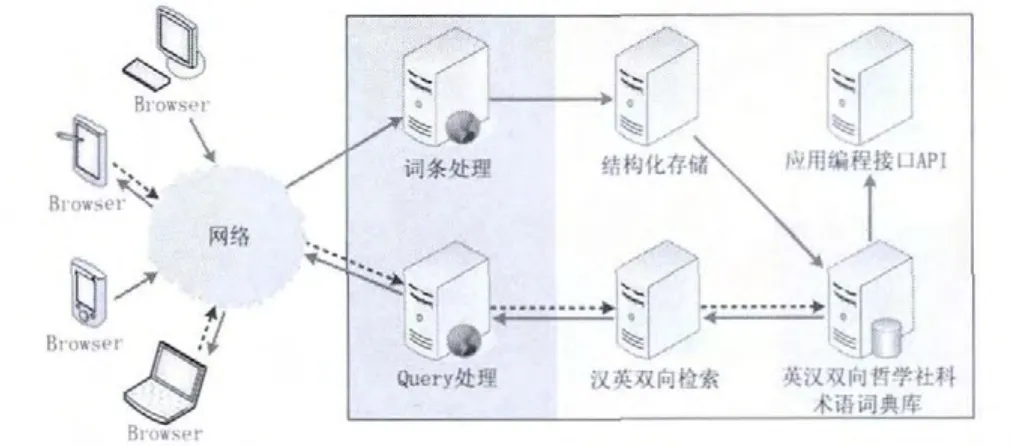
图1 哲译通系统架构
一部分是通过网络接入的各种用户终端,它们可以是安装了浏览器(browser)的任意接入设备,只需通过网络访问服务器就可以使用哲译通系统,简化了客户端的安装,便于跨硬件、软件、网络平台使用系统。另一部分是采用高速内网连接起来的各类服务器,包括用于存储英汉双向哲学社科术语词典库的数据服务器,提供结构化存储、汉英双向检索、应用编程接口的应用服务器,接收Web请求并进行相应处理的Web服务器。
服务器端的词条处理服务器并发接收单条词条的Web提交,也接收批处理词条提交,并把词条数据提交到结构化存储服务器。Query处理服务器接收汉文Query或英文Query的Web提交,支持高级搜索的逻辑表达式处理,并提交Query到汉英双向检索服务器,接收检索服务器的返回结果,通过网络反馈给浏览器端。结构化存储服务器支持词条数据的格式化、词条相关性挖掘、索引编排、数据库操作等功能。汉英双向检索服务器接收Query请求,查询英汉双向哲学社科术语词典库的索引,返回检索结果。应用编程接口服务器扩展通用的编程接口,提供印刷纸本词典的自动排版清样、机器翻译等数据增值服务。
我们设计的用于存储术语的数据库term表结构如图2所示,每条词条包含10个属性域(术语ID、汉文词条、英文词条、汉文注释、英文注释、插图文件名、学科类别、译文出处、提供者、联系方式),其中汉文注释和英文注释是双语平行文本,而插图采用文件系统进行存储,所以插图文件名是文件系统存储和访问路径。

图2 哲译通数据库term表结构
从系统功能角度分析,哲译通是一个以术语词典库为核心的综合系统,既包含词典数据高效收集、存储、维护、管理、分析、共享等基本功能,又包含汉英全文检索、组合逻辑检索、学科分类检索、相关推荐检索等便捷的搜索功能,还包含汉英双解展示、开放词条在线提交、纸本词典自动出版、机器翻译等数据增值服务功能。
三 系统实现
根据上文提出的系统架构,首先我们构造了英汉双向哲学社科术语词典库。《番漢合時掌中珠》将词条分为天体、天相、天变、地体、地相、地用、人体、人相、人事九大类。同理根据哲学和社会科学分类体系把英汉双向哲学社科术语分为哲学、历史、经济、法学、文学、教育、管理、军事、科技史九大类。如表1所示九大类总共收集了44 136条词条。
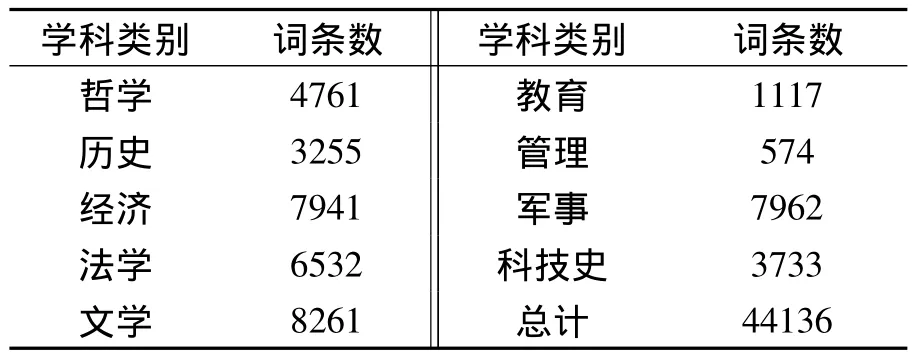
表1 哲译通学科类别和词条数
接着我们实现了结构化存储服务器和词条处理服务器,按照上文的term表结构对词条进行格式化,对用于挖掘的域(汉文注释、英文注释)文本进行分词处理,建立全文倒排索引,并存储到数据服务器。然后我们实现了汉英双向检索服务器和Query处理服务器,支持以下四种搜索方式。
1.基本搜索
基本搜索类似于谷歌主页的搜索,实现汉英全文检索功能。在哲译通主页面的输入框中输入搜索请求(Query),点击搜索按钮就可以得到详细的双语双解词条信息。哲译通基本搜索可以很好地支持对汉文英文的全文搜索,对Query中的人名、地名、机构名等专名进行了识别,提高了搜索的语义准确性。
2.学科搜索
学科搜索实现按照学科分类进行检索的功能。由于在构造英汉双向哲学社科术语词典库时,对每条词条进行了学科分类,因此在输入框上方有相应的学科分类链接,通过点击链接选择学科,能够更加精准地限定搜索范围,提高返回词条的相关性。
3.高级搜索
高级搜索能够实现复杂的多条件组合逻辑检索。通过“+”“-”按钮增删搜索条件,搜索条件之间的逻辑关系可以通过逻辑下拉框设定,包括“并且”“或者”和“不含”三种逻辑运算符。除此之外,每个条件的权重可以通过权重输入框设定,通常权重采用一个整数表示。用户通过权重设置来准确描述自己搜索的侧重点。
4.推荐搜索
推荐搜索是采用数据挖掘技术计算Query与每条词条内容的相关性,输出术语词条中不含Query文本,但术语内容与Query紧密相关的词条。这是一种暗含的隐式搜索,不需要用户人工干预,伴随上述三种搜索方式自动完成的。比如:输入Query(秦始皇)点击搜索按钮后的搜索结果页面,除了两条搜索结果(秦始皇、秦始皇陵)之外,还向用户推荐有可能感兴趣的三条相关词条(秦兵马俑、先秦思想、郡县制度),如果用户感兴趣可以进一步点击相关词条链接打开具体内容页面。
最后我们还实现了应用编程接口服务器,支持印刷纸本词典的自动排版清样生成功能,这是对传统纸本词典出版的一次变革,能够缩短词典版本更新周期,提高词典的时效性。此外应用编程接口服务器还为机器翻译提供术语翻译接口[5]。
哲译通系统不仅词库容量大、学科类别全,而且词条注释详略得当、译文出处权威准确,2008年底在军网上线试运行[6],方便教学和科研人员查询、提交词条。查询时用户只需要输入汉文或英文词条,便可获得译文词条、汉英注释、插图、学科类别、译文出处、提供者等信息。提交新词时用户只需要根据哲译通词条模板逐项填写,其中包括提供者的姓名,通过审核后提供者自动成为哲译通电子词典的作者之一[7]。试运行以来得到用户广泛好评,成为从事哲学与社会科学教学和科研人员的好助手。
四 结语
时代划分依据多种多样,若以“纸”为依据,我们可以把纸发明之前的人类文明时期称为“纸前时代”,从纸的发明到普及使用称为“纸质时代”,那么今天趋于无纸化的大数据时代则是当之无愧的“后纸时代”。罗塞塔石碑是纸前时代的多语平行语料库,《番漢合時掌中珠》是纸质时代的双向双解词典,而哲译通就像是后纸时代对英汉双向网络词典的一种有益尝试。尽管信息记录材料发生了翻天覆地的变化,但上述三者的本质并没有太多不同,哲译通不过是古今中外跨语言文字信息处理的一种延续。
在下一步的研究工作中,我们将加强用户与研发者之间的交流互动,根据试运行反馈完善系统功能,扩充系统词量使得词典覆盖面越来越广。可以预见哲译通将在哲学与社会科学研究领域发挥更大的作用。此外进一步扩展应用编程接口,将英汉双向哲学社科术语词典作为一种重要的知识源,支撑机器翻译领域进行更深的研究。还可以通过迁移学习技术把我们设计的术语词典系统构建方法和实现的软件部件用于医药术语库、气象术语库、古籍翻译术语库、国防缩略术语库[8]、军事术语库[9]等其他专业术语网络词典建设之中。
[1]王克非,黄立波.国外双语库研制与应用评析[EB/OL].(2013-04-23)[2013-11-15].http://www.npopsscn.gov.cn/n/2013/0423/c362514 -21242066.html.
[2]王莉,梁冰,郝春云,等.基于Wiki技术的标准术语库的设计与实现[J].数字图书馆论坛,2011(3):44-51.
[3]向音,李苏鸣.领域术语特征分析——以军语为例[J].中国科技术语,2012(5):5-9.
[4]冯志伟.一个新兴的术语学科——计算术语学[J].术语标准化与信息技术,2008(4):4-9.
[5]罗季美.机器翻译中的术语错译分析[J].中国科技术语,2013(1):41-45.
[6]况守忠,周雨花.国防科大人文与社会科学学院开发出我国第一部“哲译通”电子辞典[N].解放军报,2008-12-26.
[7]王握文.在线电子辞典,网友也能当作者——国防科大研发“哲学与社会科学专有名词电子辞典”纪实[N].解放军报,2009-2-17.
[8]易绵竹,刘伍颖,刘万义,王琳.多语种国防缩略术语库研究[J].中国科技术语,2013(5):18-21.
[9]张国君,吴晓燕,丁国瑞.建立多语种军事术语数据库系统的基本构想[J].中国科技术语,2013(5):9-13.
猜你喜欢
山西高等学校社会科学学报(2023年7期)2023-07-26 09:05:00
山西高等学校社会科学学报(2022年10期)2022-10-25 10:45:54
山西高等学校社会科学学报(2021年4期)2021-04-30 03:18:12
知识经济·中国直销(2016年5期)2016-11-07 09:35:07
知识经济·中国直销(2016年4期)2016-11-07 09:34:04
外语教学理论与实践(2016年1期)2016-06-11 05:51:46
全国新书目(2016年5期)2016-06-08 08:54:10
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:16
知识经济·中国直销(2016年10期)2016-02-27 16:16:54
信息安全研究(2015年3期)2015-02-28 20:17:53
