
基于SVM的查询向量微博话题跟踪技术研究
2014-04-02 02:02:46,,
中原工学院学报 2014年6期
, ,
(郑州轻工业学院,郑州 450000)
随着互联网信息科技的快速发展,微博已经成为人们日常生活中信息交流的重要平台。每天微博中都充斥着数以万计的信息,人们利用微博话题检测技术可以从这些杂乱无章的信息中很容易地获取自己需要的内容。在微博系统的使用中,人们在发现了自己需要或者感兴趣的话题后,不仅想知道该话题事件以前和当前都发生了什么,更想知道该话题事件将来会发生什么。微博话题跟踪技术就是根据用户的需求,按照一定的算法,对相关的话题内容进行跟踪,并将跟踪到的结果进行归类整合,自动提供给用户的一种计算机技术。
本文介绍了微博话题跟踪技术中常用的两种方法:支持向量机(SVM)算法和基于查询向量的话题跟踪算法,在结合传统话题跟踪技术和微博自身特点的基础上,提出了一种基于SVM的查询向量话题跟踪算法,并给出了该算法在微博话题跟踪应用中的流程,最后通过数据模拟实验对该算法的性能进行验证。
1 微博话题跟踪的流程
微博话题的跟踪过程,从数学角度上来说,可以形容为一个关系的映射。它是将最新出现的微博话题文本(A)根据一定的跟踪规则(f)与系统中已有的话题进行对比,并映射到相应话题集(B)中去的一个过程。公式(1)为话题关系映射的表示形式:
f:A→B
(1)
其中,A表示最新的话题集;B表示已知的、系统预设的话题集;f表示跟踪映射规则,该规则的主要内容为:系统根据已知话题的样本集,归纳出话题间内在联系的判别规则f,当有新的话题出现时,系统就根据上述规则f将新来的话题归入相应的话题类中。
微博话题跟踪流程[1]分为两个阶段,如图1所示。第一个阶段为训练阶段,主要目的是形成分类模型,方法是先对预设话题进行一定数量的训练,从而形成训练样本,然后对训练样本进行信息预处理,并根据一定的算法,最终生成分类模型。第二个阶段为分类阶段,目的是形成分类结果,方法是对新出现的话题进行信息处理,并与第一阶段生成的分类模型进行比较,再根据一定的分类算法判断该报道属于哪个话题。

图1 话题跟踪的流程
2 传统的微博话题跟踪算法
2.1 支持向量机(SVM)算法
支持向量机(SVM)算法理论是在1995年由Vapnik提出的[2-4],该理论的提出是为了解决训练集有限的问题。它包含了统计学的VC维理论和结构遇险概率最小化的理论,是在二者相结合的基础上建立的。
支持向量机(SVM)算法的主要理论内容是:将训练样本表示为一个空间向量模型,并对该模型进行二次规划求解,从而求得一个最优分类函数,然后将待分类的文本向量代入该最优分类函数求值,并根据求得的值判断该文本向量的类别,如果其值能够满足某个分类条件,就将该文本向量划入相应分类中去。支持向量机算法(SVM)的示意图如图2所示。
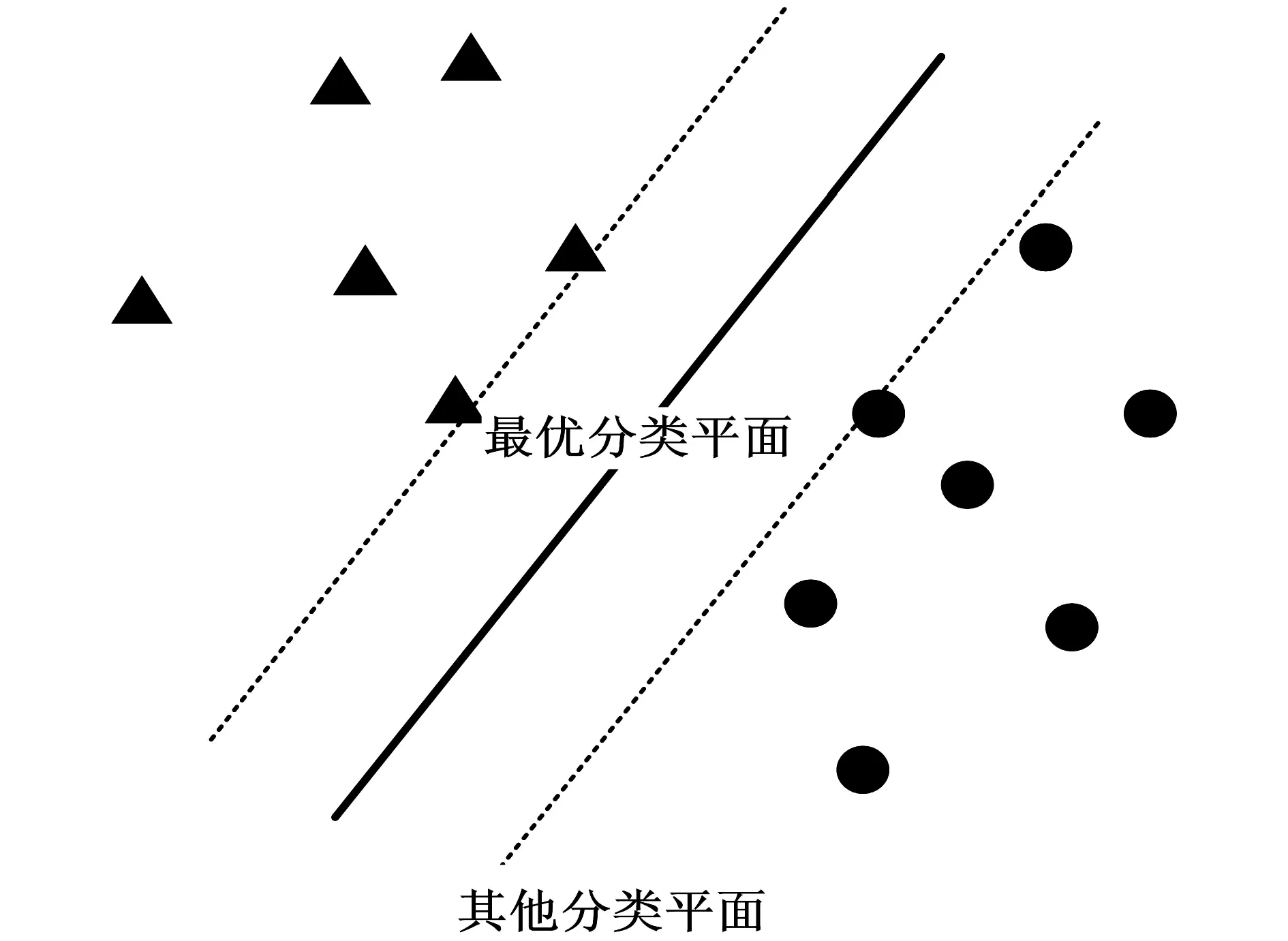
图2 支持向量机算法(SVM)示意图
图2中,▲和●分别表示不同类别的文本;虚线表示其他分类平面,该平面平行于最优分类平面,且穿过离最优分类平面最近的文本向量。虽然这样的分类平面有无数多条,但是只有最优分类平面可以使文本类别间的距离最大。
支持向量机(SVM)算法的优点是:它在样本数量有限的情况下,能够获得最好的分类结果,这解决了实际应用中样本有限的问题,比较贴近实用。该算法的缺点是:它通过最优分类函数将样本划分到不同的聚类中,而不是将样本的划分精确到数值,故准确率不高。
2.2 基于查询向量的话题跟踪算法
美国国防部高级研究设计局和美国国家标准与技术研究所等单位联合开展研究了TDT(Topic Detection and Tracking)问题。在研究过程中,为了解决话题跟踪任务不直接给定主题的问题,研究者们只给出了1~4篇蕴含话题的相关报道作为训练样本。虽然训练样本数量很有限,但是在此基础上,衍生出了很多的话题跟踪算法,比如KNN算法[5]和决策树算法等。然而,基于查询向量的话题跟踪算法在TDT研究的基础上,不用去考虑先验报道的稀疏性[6]。
基于查询向量话题跟踪算法的主要思想是:在话题检测完成的基础上,将检测出的话题向量作为查询向量,将对微博用户页面信息进行采集得到的XML数据作为文本向量,并将查询向量和文本向量进行相似度计算,然后将计算出的结果与提前设置的阈值进行比较,根据比较结果来判断话题向量是否为相关话题的后续报道。该方法适用于微博话题的跟踪[7]。
基于查询向量的话题跟踪算法的优点是:不用去考虑前面查询向量的稀疏性报道,算法简单且高效。该算法的缺点是:由于事件随着时间不断地发展变化,从而使相关话题也跟着变化,故而可能出现话题漂移现象,影响话题跟踪的准确率。
基于查询向量的话题跟踪算法的流程如图3所示。
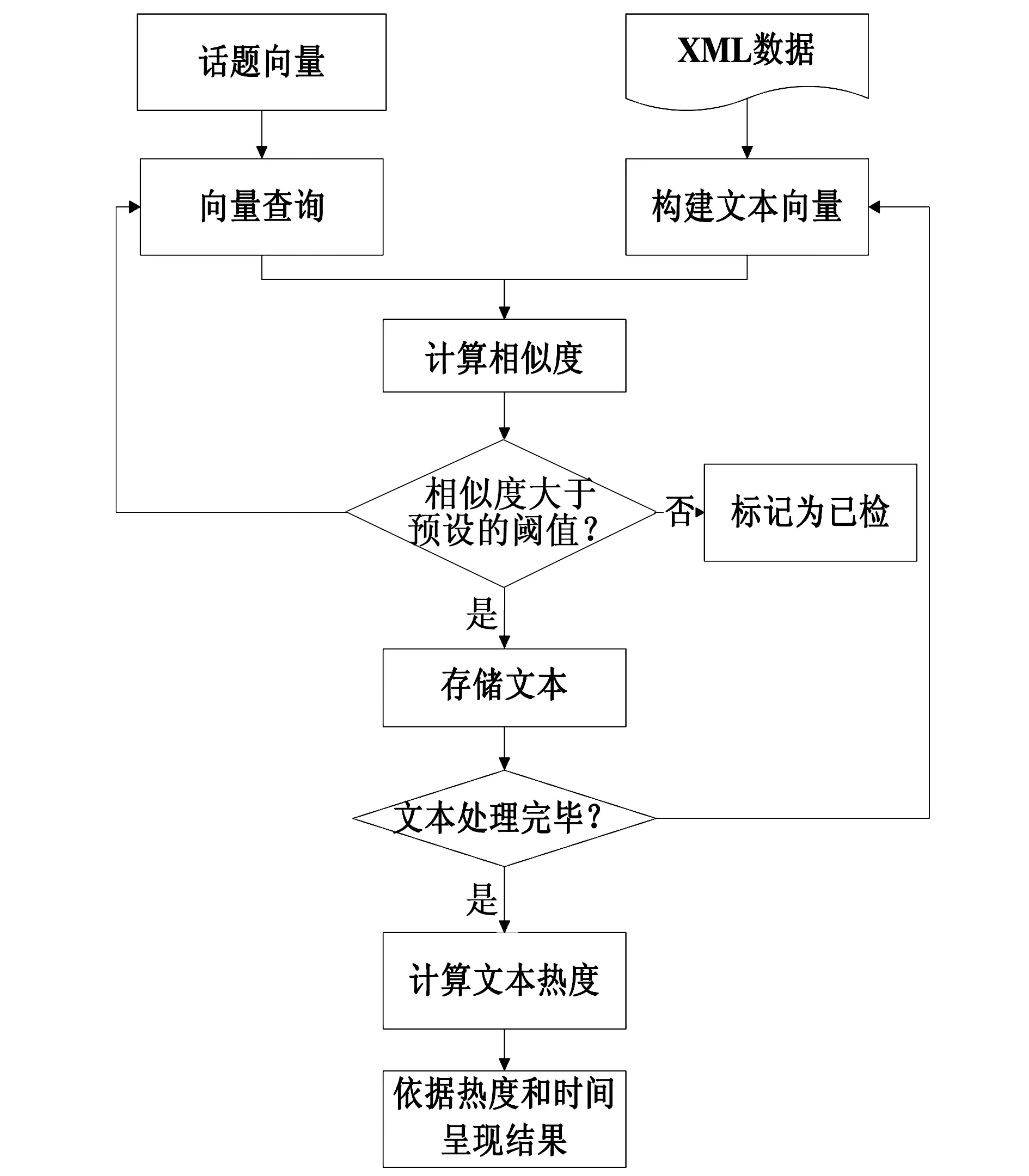
图3 基于查询向量的话题跟踪算法流程图
3 基于SVM的查询向量话题跟踪算法
支持向量机(SVM)算法虽然能够在样本数量有限的情况下获得较好的分类结果,但是其分类的精度还不高。而基于查询向量的话题跟踪算法虽然可以不考虑先验报道的稀疏性,但可能会引起话题漂移现象。所以,本文在考虑上述两种算法优缺点的基础上,提出一种新的算法,即基于SVM的查询向量话题跟踪算法。
基于SVM的查询向量话题跟踪算法的主要思想是:第一,在话题检测完成的基础上,将检测出的话题向量作为查询向量,将对微博用户页面信息进行采集得到的XML数据构建为文本向量;第二,对构建好的文本向量模型进行二次规划求解,从而求得一个最优分类函数;第三,将待分类的文本向量代入该最优分类函数求值,并根据求得的值判断该文本向量的类别;第四,将待分类的文本向量根据判断类别进行分类后,将刚进入该类的文本向量作为查询向量,与已构建的文本向量进行相似度计算,并将计算出的结果与提前设置的阈值进行比较;第五,根据比较结果来判断话题向量是否为相关话题的后续报道。
该算法既能够利用SVM算法的最优分类函数确定话题区域,缩小话题范围,提高跟踪准确率,又能够运用基于查询向量的算法优化话题空间,减小话题漂移差距。
基于SVM的查询向量话题跟踪算法的流程图如图4所示。
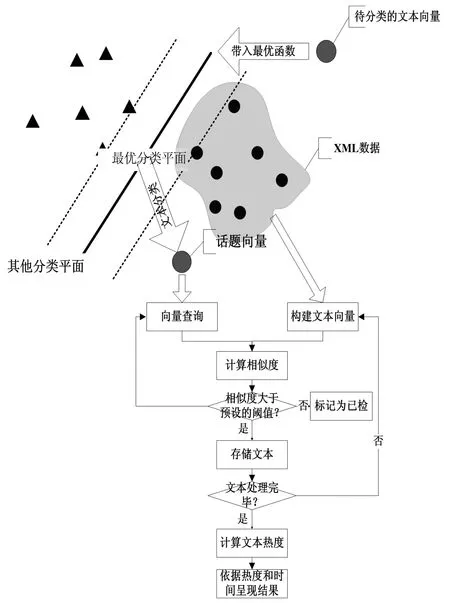
图4 基于SVM的查询向量话题跟踪算法流程图
4 实验结果与分析
为了验证基于SVM的查询向量话题跟踪算法在实际应用中是否能够提高话题跟踪的准确率和综合效率,本文进行了数字模拟实验。
实验严格按照TDT话题评测规则进行,主要从召回率(R)、准确率(P)、F值3个指标进行量化考察。
召回率(R)是指对于某一个话题属性,系统能够正确识别出来的话题文本数(D)占系统应该识别出来的话题文本总数(T)的比重。其具体公式如下:
R=D/T×100%
准确率(P)是指对于某一个话题属性,系统能够正确识别出来的话题文本数(D)占系统已经识别出来的话题文本数(U)的比重。其具体公式如下:
P=D/U×100%
F值是描述召回率(R)与准确率(P)综合性能的指标,是反映话题跟踪技术整体性能的重要指标。其具体公式如下:
F=2PR/(P+R)×100%
实验设备:惠普Compaq dx2390 服务器,英特尔Pentium(R) Dual-core E5200 2.5GHz处理器,2046MB内存,Microsoft windows XP professional (5.1,版本2600)操作系统,网络带宽10 M。
实验数据选取如下:从网页中随机抽取18 543个XML文件;通过话题检测随机抽取得到10个微博话题;在微博系统中随机选出1 000个微博用户,并对这1 000个微博用户的主页面和二级页面进行信息提取,共提取出27 654个话题信息,并将这些信息转变为27 654个XML数据。
为了增强实验的对比性,分别对传统的支持向量机(SVM)算法、基于查询向量的话题跟踪算法和新提出的基于SVM的查询向量话题跟踪算法进行话题跟踪模拟实验。经过实验,得到了评测结果,如表1所示。
通过实验评测结果可以看出,支持向量机(SVM)算法和基于查询向量的话题跟踪算法虽然都能够较快地完成话题跟踪任务,但是其准确率及综合性能相对较差,而基于SVM的查询向量话题跟踪算法在微博话题跟踪任务中的召回率、准确率、F值都优于前两种算法。虽然该算法在用时上还有待缩短,但是它提高了话题跟踪的准确率,是一种优良的算法。
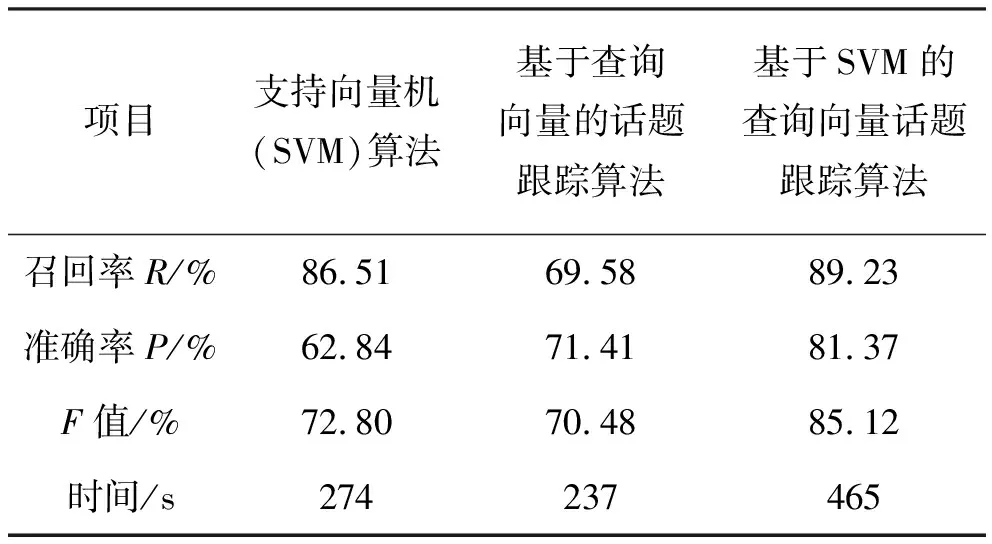
表1 话题跟踪评测结果
5 结 语
目前,关于话题跟踪技术常用的算法有支持向量机(SVM)算法和基于查询向量的话题跟踪算法。然而在实际运用中,这两种算法都存在微博话题跟踪的准确率不高的问题。为了进一步提高微博话题跟踪的准确率,本文提出了基于SVM的查询向量话题跟踪算法,该算法既能够运用最优分类函数缩小话题范围,又能够运用查询向量减少话题漂移现象,从而提高微博话题跟踪的精确度。通过模拟实验证明,该算法虽然在用时上还有待缩短,但确实提高了微博话题跟踪准确率。
参考文献:
[1] 韩威,赵铁军.网络舆情热点发现与话题跟踪技术研究[D].哈尔滨:哈尔滨工业大学,2012.
[2] 张健沛,徐华.支持向量机(SVM)主动学习方法研究与应用[J].计算机应用,2004,24(1):1-3.
[3] 王顺利.基于支持向量机(SVM)的图像去噪方法[J].微电子学与计算机,2005,22(4):96-99.
[4] Cortes C, Vapnik V.Support Vector Networks[J].Machine Learning,1995,20(3):273-297.
[5] 李秀娟.KNN分类算法研究[J].科学信息,2009(31):25-28.
[6] 洪宇.基于语义结构和时序特征的话题检测与跟踪技术研究[D].哈尔滨:哈尔滨工业大学,2009.
[7] 孙胜平,张真继.中文微博热点话题检查与跟踪技术研究[D].北京:北京交通大学,2011.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
