
带偏射补偿机制的Birkhoff-von-Neumann交换机方案及其性能分析*
2014-03-05 09:00张景辉叶通Lee闫芳芳胡卫生
电讯技术 2014年4期
张景辉,叶通,Lee T T,闫芳芳,胡卫生
(上海交通大学区域光纤通信网与新型光通信系统国家重点实验室,上海 200240)
1 引言
调度器对于输入排队交换机来说是一个核心问题。一个好的调度器能够最大化吞吐量,减少端到端延时以及减少计算复杂度。过去十几年里,业界提出了许多在线算法[1-5],它们根据输入队列的实时请求给交换结构分配连接模式。尽管这些在线算法可以获得100%的吞吐量,但当输入端口数N和传输线速率增大时其可扩展性将变得很差。
为了给每个输入/输出端口对(或者称为虚电路VC)提供带宽保证且避免在线计算,文献[6]提出了一种称为路径交换的准静态算法,后来在文献[7]中被称作 Birkhoff-von-Neumann(BvN)交换。这个算法先由平均输入业务矩阵得到一系列置换矩阵,然后根据这些矩阵预先安排好交换机的连接模式。由于连接模式不需要在线计算,所以其在线计算复杂度为O(1),可扩展性很强。同时,文献[8]提到了只要输入业务不超过预设的到达曲线[9],那么这个算法就能达到100%的吞吐量和有界的端到端延时。然而,如果输入业务是突发的,BvN交换机的性能将变得不可预测。
为了处理突发业务,文献[10]和文献[11]引入了一种两级的负载均衡BvN(LB-BvN)交叉开关交换机。在第一级,输入业务被均匀分发到该级的各个输出端,使第二级输入业务均匀化;在第二级,通过运行N个循环移位置换矩阵实现交换。虽然这种方法在线计算复杂度为O(1)且可以处理任意的业务模式,但是它会在输出端造成严重的包乱序(即使输入业务是平稳的)。为了解决乱序的问题,业界提出了一系列改进方案。文献[12-14]均引入了三级交换结构来解决包乱序问题,但是这样导致了较高的额外硬件成本。文献[11]在中间缓存管理中引入了先到先服务(FCFS)和时限最早优先(EDF)策略,但是FCFS要求中间缓存要有N倍的加速,而EDF要求每个时隙都要检查所有业务包的时限,这都使得交换机扩展性变差。文献[15]提出了一种基于反馈的LB-BvN交换机,这种方法需要频繁地向输入端反馈中间缓存的占用情况,从而加大了交换机的实现难度。
在本文中,为了增强突发业务下BvN交换机性能的同时减少包乱序问题,我们引入了业务偏射补偿机制,提出了带偏射的BvN(D-BvN)交换机方案。许多包交换网络都采用偏射路由来解决冲突,如Tandem Banyan网络[16]、带纠错路由的双重混洗交换网络[17]、光突发交换机[18]以及可容错的片上网络[19]。与这些偏射机制不同的是,我们算法的目的是平稳输入业务的波动以及均衡各个VC间的负载。另外,我们的设计也与LB-BvN交换机随意分发业务包不一样:只有溢出的突发业务才会被偏射。因此,业务包的乱序概率会显著下降。除此之外,我们的算法只需较少的缓存就可以获得接近100%的输入负载吞吐量,能够显著地减少业务包端到端延时,同时它继承了BvN交换机的准静态调度方式,其在线算法复杂度仍然是O(1)。
本文余下部分如下安排:在第2节简要介绍BvN交换机的基本概念以及讨论它由于准静态调度带来的缺点;在第3节提出了带偏射补偿的交换机结构以及相关的调度算法;在第4节提供了D-BvN交换机的仿真条件,并给出了丢包率、最小缓存需求、包乱序概率以及业务包延时的仿真结果,同时与BvN交换机的相应性能做比较;最后总结本文。
2 BvN交换机回顾及分析
在N×N的BvN交换机中,每个输入端口都设置了N个虚输出队列(VOQ)。从输入端口i到输出端口j的业务包缓存在VOQij里(如图1(a)所示,其中N=4)。BvN交换机的准静态调度方法原理其实是双随机矩阵的 Birkhoff-von-Neumann分解定理[20]。
记λij为从输入端口i到输出端口j的平均业务速率,且∑iλij≤1 以及∑jλij≤1。根据输入业务矩阵[λij]N×N,可以找到一个容量矩阵[cij]N×N,满足 λij≤cij以及∑icij=∑jcij=1。基于 BvN分解定理[20],[cij]N×N可以分解成若干置换矩阵的线性组合,其中每个置换矩阵代表交换机的一种连接模式,如图1(b)所示。
在一个帧的连续F个时隙里面,我们根据BvN分解的权重来安排这些预设的连接模式(如图1(c)所示,其中F=10)。通过周期性地运行这些连接模式,BvN交换机保证了每个I/O对(i,j)的容量cij。如果输入i和输出j在某个时隙内是连接的,我们就称VCij得到了一个令牌,允许传输一个业务包。

图1 BvN交换机原理Fig.1 The principle of BvN switch
BvN交换机根据平均业务速率给VC提供容量保证,所以它能够处理平稳的输入业务。如图2(a)所示,当输入业务比较平稳时,即使有突发业务到达(如图中t1时刻),VOQ也能够把暂未能服务的业务缓存起来,待输入速率降低后(如图中t2时刻)再服务。由此可见,当输入业务平稳时,BvN交换机能够获得高容量利用率和高吞吐量。但是,当输入业务具有突发性时,BvN交换机的性能将变差。如图2(b)所示,在t1时刻,输入业务速率比VC的容量小,VC的容量得不到充分利用(即令牌被闲置);而在t2时刻,大量业务到达VC,输入业务的速率明显大于VC的容量,VOQ缓存会被占满,从而导致丢包。由此可见,在突发业务下,BvN交换机会同时带来低容量利用率和低吞吐量。总的来说,随着输入业务突发度的增长,BvN交换机的容量利用率和吞吐量都会随之下降。

图2 输入平稳和突发业务时BvN交换机性能对比Fig.2 Comparison of BvN switch performance between smooth and bursty traffic
然而,交换机中的VC不大可能都在同一时刻出现突发,尤其是当交换结构的端口数N比较大的时候。这就意味着我们可以利用空闲VC的闲置容量去处理其他繁忙VC溢出的业务包,从而改善吞吐量和容量利用率。下一节中我们将根据这个想法设计带偏射补偿的BvN交换机。
3 D-BvN交换机方案
基于上述的讨论,我们提出带偏射补偿的Birkhoff-von-Neumann(D-BvN)交换机,其主要思想是充分利用BvN交换机中不能被利用的空闲容量去处理溢出的业务包。那些在BvN交换机中被闲置的令牌主要起到以下两个作用:一是偏射溢出业务,二是给溢出业务提供重新进入系统的带宽。
如图3所示,为了实现D-BvN交换机,每个输入端口都设置一个回收缓存(记输入端口i的回收缓存为TBi),用于在偏射前暂时存放从饱和VOQ溢出的业务包。同时,每对编号相同的输入输出端口都有一条反馈连接,用于让偏射包重新进入系统。将到达第i个输入端口,且要被交换到第k个输出端口的包记为Aik。当Aik到达时,D-BvN交换机的包交换过程可以分成下面几步:
步骤 1:如果VCik的缓存VOQik未满,Aik进入VOQik并且等待服务;否则,转到步骤2;
步骤2:如果Aik是一个未偏射包,转到步骤3;否则,Aik尝试进入i输入端口的回收缓存TBi,转到步骤4;
步骤3:如果VOQik中有偏射包,挑出其中一个偏射包放到TBi,Aik进入VOQik并等待服务;否则,Aik尝试进入TBi,转到步骤4;
步骤4:如果TBi已满,丢弃 Aik;否则,Aik进入TBi。当Aik成为了TBi的队头包且VCij当前有一个空闲令牌(也就是说VOQij是空的),Aik就通过VCij偏射到输出端口j,转到步骤5;
步骤5:如果j=k,那么Aik到达了它的目的端口;否则,将Aik反馈到输入端口j,重复步骤1。

图3 溢出业务包的偏射过程Fig.3 Deflection process of overflow packet
由于交换机相同编号的输入输出端口通常在同一个线卡上[4],故D-BvN交换机中的反馈连接只需要很少的硬件成本。另外,与BvN交换机相比,DBvN交换机只是分别在输入输出端各添加了一个判断模块,故D-BvN交换机没有引入很多额外的在线计算,其在线计算复杂度应与BvN交换机一样是O(1)。
4 D-BvN交换机性能评估
为了评估D-BvN交换机的性能,并与BvN交换机的性能比较,我们对这两种交换机做了性能仿真。通过仿真我们可以看到,D-BvN交换机的吞吐量相比BvN交换机有显著的提升。在吞吐量较高的情况下,D-BvN交换机只带来了很低的包乱序概率,同时其业务包延时也比BvN交换机的延时低。
4.1 仿真条件
在仿真中,我们假设交换机是一个分时隙的系统,并且输入业务是均匀的,也就是说每个VC的平均输入业务速率都相等,同时它们都有相同的VOQ缓存K以及容量C。在每个端口处,我们都设置了相同大小的回收缓存BT。每个VC的输入业务都是离散时间的马尔可夫调制on-off业务源,它们的on期和off期状态转移概率均为α和β。在on期中,每个时隙会以一定概率^λ产生一个业务包,而在off期中则没有业务包到达。所以,业务源的峰值速率为,平均到达速率这里,类似于突发长度的定义[1],我们定义业务的突发度。我们使用一组N个循环移位置换矩阵,在每个时隙随机抽出其中一个置换矩阵给交换机做交换状态配置,从而保证了每个VC的容量C都相等。
4.2 丢包率和缓存需求
如图4(a)所示,我们首先进行了BvN交换机和D-BvN交换机的丢包率比较。在仿真中,我们给BT设置了不同的值(分别是每个端口所有VOQ缓存总和的1%、5%、10%)进行比较。可以看出,DBvN交换机的丢包率比BvN交换机有明显的下降。这是因为在相同的VOQ缓存下,D-BvN交换机利用空闲容量偏射溢出业务,实质上是给溢出业务提供了一个动态缓存,避免了丢包的发生。另一方面,我们也可以看到,随着回收缓存的增大,丢包率会进一步下降。这是因为实际系统中,溢出业务和空闲容量不是同时产生的,如果有更大的回收缓存,就可以让更多的溢出业务等待空闲容量的到来,从而减少丢包。
图4(b)所示是BvN交换机和D-BvN交换机对缓存的需求仿真比较。这里我们定义缓存需求为使系统丢包率达到10-5所需的最小VOQ缓存。可以看到BvN交换机对缓存的需求比D-BvN交换机的需求大得多。这是因为D-BvN交换机偏射溢出业务的时候,相当于利用空闲容量做一个动态缓存来避免丢包,从而减少了对VOQ缓存的需求。

图4 丢包率与缓存需求的仿真结果比较图Fig.4 Comparison of simulation results between traffic loss rate and VOQ buffer requirement
4.3 包乱序概率
偏射会在输出端导致业务包乱序。一个数据包只有被偏射之后,它才会在输出端导致乱序。因此,可以用业务被偏射的概率来分析包乱序。图5给出了3种不同回收缓存大小下业务被偏射概率随VOQ大小变化的仿真数据图。从图5看出,在3种不同回收缓存大小的情况下,当D-BvN交换机的丢包率为10-5时(对应于图4和图5中的VOQ为K1、K2、K3这三点),D-BvN交换机的包乱序概率分别为Pd1=0.01146,Pd2=0.00957,Pd3=0.0053。可以看出,这些概率都很低,不会在输出端造成严重的包乱序。
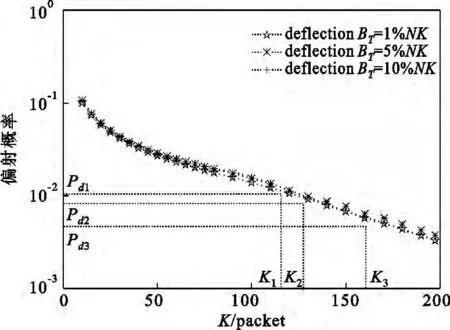
图5 D-BvN交换机业务偏射概率的仿真结果Fig.5 Simulation results of packet deflection probability in D-BvN switch
4.4 业务包延时
通过仿真,我们比较了系统丢包率均为10-5时,BvN交换机和D-BvN交换机的业务包延时,并发现D-BvN交换机的业务包延时比BvN交换机的业务包延时有显著的下降,如图6所示。

图6 业务包延时的仿真结果比较图Fig.6 Comparison of simulation results of packet delay
因为相对于D-BvN交换机来说,BvN交换机需要更多的VOQ缓存才能使系统丢包率达到10-5(见图4(b)),所以在BvN交换机中,受阻塞的业务包会在VOQ缓存中形成很长的队列;但在D-BvN交换机中,VOQ缓存较小,受阻塞的业务包不会形成很长的队列。根据排队论中的Little's Law,DBvN交换机的业务包排队延时应该比BvN交换机的业务包排队延时要小。同时,由于D-BvN交换机的偏射概率很低(见图5),所以业务包的平均偏射延时也很低。因此总的来说,D-BvN交换机的业务包延时要低于BvN交换机的业务包延时。
5 结束语
为了避免BvN交换机在突发业务下的缺点,我们引入了偏射机制来增强BvN交换机的性能。DBvN交换机有以下特点:
(1)在突发业务下,D-BvN交换机只需较少的VOQ缓存就能获得与BvN交换机相同的吞吐量;
(2)D-BvN交换机只引入了少量的额外硬件要求且在线计算复杂度与BvN交换机一样为O(1);
(3)尽管偏射会影响业务包的输出顺序,但是在丢包率较低的情况下,包乱序概率几乎可以忽略不计;
(4)D-BvN交换机能显著减少业务包延时。
[1]Mckeown N.The iSLIP scheduling algorithm for inputqueued switches[J].IEEE/ACM Transactions on Networking,1999,7(2):188-201.
[2]Hu Bing,Yeung K L,Zhang Zhao-yang.An efficient single-iteration single-bit request scheduling algorithm for input-queued switches[J].Journal of Network and Computer Applications,2013,36(1):187-194.
[3]Danilewicz G,Dziuba M.The new MSMPS Packet Scheduling Algorithm for VOQ Switches[C]//Proceedings of 20128th International Symposium on Communication Systems,Networks & Digital Signal Processing.Poznan:IEEE,2012:1-5.
[4]He Chunzhi,Yeung K L.D-LQF:An efficient distributed scheduling algorithm for input-queued switches[C]//Proceedings of 2011 IEEE International Conference on Communications.Kyoto:IEEE,2011:1-5.
[5]Yu Xia,Chao H-J.Module-level matching algorithms for MSM clos- network switches[C]//Proceedings of 2012 IEEE 13th International Conference on High Performance Switching and Routing.Belgrade:IEEE,2012:36-43.
[6]Lee T T,Lam C H.Path switching-a quasi-static routing scheme for large-scale ATM packet switches[J].IEEE Journal on Selected Areas in Communications,1997,15(5):914-924.
[7]Chang Chengshang,Chen Wen-Jyh,Huang Hsiang-yi.On service guarantees for input-buffered crossbar switches:a capacity decomposition approach by Birkh off and von Neumann[C]//Proceedings of 1999 Seventh International Workshop on Quality of Service.London:IEEE,1999:79-86.
[8]Chan M C,Lee T T,Liew S Y.Statistical performance guarantees in large-scale cross-path packet Switch[C]//Proceedings of 2000IEEE International Conference on Communications.New Orleans,LA:IEEE,2000:1748-1752.
[9]Cruz R L.A calculus for network delay.I.Network elements in isolation[J].IEEE Transactions on Information Theory,1991,37(1):114-131.
[10]Chang C S,Lee D S.Jou Y S.Load balanced Birkhoff-von Neumann switches,part I:one-stage buffering[J].IEEE Computer Communication,2002,25(6):611-622.
[11]Chang C S,Lee D S,Jou Y S.Load balanced Birkhoff-von Neumann switches,part II:multistage buffering[J].IEEE Computer Communication,2002,25(6):623-634.
[12]Antonakopoulos S,Fortune S,McLellan R,et al.Collector-based cell reordering in load-balanced Switch fabrics[C]//Proceedings of 2013 IEEE 14th International Conference on High Performance Switching and Routing.Taipei:IEEE,2013:1-6.
[13]Wang Xiaolin,Cai Yan,Xiao Sheng,et al.A three-stage load-balancing Switch[C]//Proceedings of IEEE 27th Conference on Computer Communications.Phoenix,AZ:IEEE,2008:1993-2001.
[14]Hu Bing,Yeung K L.Load-balanced three-stage Switch Architecture[J].Journal of Network and Computer Applications,2012,35(1):502-509.
[15]Hu Bing,He chunzhi,Yeung K L.On the scalability of feedback-based two-stage Switch[C]//Proceedings of 2012 IEEE International Conference on Communications.Ottawa,ON:IEEE,2012:2956-2960.
[16]Bassi S,Decina M,Giacomazzi P,et al.Pattavina A.Multistage shuffle networks with shortest path and deflection routing for high performance ATM switching:the open-loop shuffleout[J].IEEE Transactions on Communications,1994,42(10):2881-2889.
[17]Liew S C,Lee T T.N log N dual shuffle-exchange network with error-correcting routing[C]//Proceedings of 1992 IEEE International Conference on Communications.Chicago,IL:IEEE,1992:262-268.
[18]Hsu Ching-Fang,Liu T L,Huang Nen-fu.Performance analysis of deflection routing in optical burst-switched networks[C]//Proceedings of Twenty- First Annual Joint Conference of the IEEE Computer and Communications Societyes.New York:IEEE,2002:66-73.
[19]Kohler A,Radetzki M.Fault-tolerant architecture and deflection routing for degradable NoC switches[C]//Proceedings of 3rd ACM/IEEE International Symposium on Networks-on-Chip.San Diego,CA:IEEE,2009:22-31.
[20]Chang C S,Chen W J,Huang H-Y.Birkhoff-vonneumann input buffered crossbar switches[C]//Proceedings of 2000Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies.Tel Aviv,Israel:IEEE,2000:1614-1623.
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
计算机与数字工程(2022年1期)2022-02-16
农业工程与装备(2021年1期)2021-05-17
自动化仪表(2020年10期)2020-11-13
电子制作(2019年14期)2019-08-20
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
铁道科学与工程学报(2015年4期)2015-12-24
船舶力学(2015年6期)2015-12-12
