
一种基于MapReduce的关联规则挖掘算法
2014-03-02 09:15周国军
玉林师范学院学报 2014年5期
□周国军
(玉林师范学院 数学与信息科学学院,广西 玉林 537000)
一种基于MapReduce的关联规则挖掘算法
□周国军
(玉林师范学院 数学与信息科学学院,广西 玉林 537000)
本文从减少I/O时间的角度出发,结合云计算Hadoop平台的MapReduce模型,提出了一种基于MapReduce的关联规则挖掘算法. 算法采用幂集计算候选项集,采用MapReduce模型在多个节点上并行找出所有频繁项集,只需要扫描事务数据库1次. 实验结果表明:在事务的平均项长较小的情况下,算法具有很好的加速比和数据规模增长性.
关联规则;MapReduce;云计算;Hadoop
1 引言
关联规则挖掘是一种重要的数据挖掘方法,其目标是从大型事务数据库中找出隐藏的、有趣的、属性间存在的关联和规律[1].Agrawal等人在1994年提出的Apriori算法[2]是最有影响力的关联规则挖掘算法,已经有很多学者针对Apriori算法需要多次扫描数据库、产生大量候选项集的缺点进行了改进.随着计算机技术的发展,各行业、各部门积累的数据在急剧增长,对大数据进行关联规则挖掘需要强大的计算能力,传统的串行算法已不能满足这个要求.随着云计算[3]的出现,利用云计算技术对大数据进行关联规则挖掘已成为一种新的解决方法[4].
MapReduce[5]是Google提出的一种处理大数据的并行编程模型,它将复杂的数据处理过程抽象成两个函数:Map和Reduce,Map函数和Reduce函数可以在分布式集群的大量节点上并行运行,从而达到了快速、高效地处理大数据的要求[6].Hadoop[7]是Apache软件基金会开发的一个开源的分布式计算框架,也是一个典型的云计算平台,它实现了Google的MapReduce模型,可以在大量廉价的硬件设备组成的集群上运行MapReduce应用程序,目前已经有一些关联规则挖掘算法在Hadoop平台上得到了改进和实现,取得了很好的数据挖掘效果[8].
在关联规则的挖掘过程中,对事务数据库进行扫描需要耗费较多的I/O时间,影响了算法执行的效率.本文从减少I/O时间的角度出发,结合云计算Hadoop平台的MapReduce模型,提出了一种基于MapReduce的关联规则挖掘算法.
2 相关知识及定义
2.1 本文算法的相关知识及定义
设事务数据库为D,事务T(T∈D)的所有项构成的集合称为项集,D中的所有项构成的集合表示为I={I1,I2,…,Im},其中Ik(1≤k≤m)是项的编号.
定义1项集A(A∩I)在事务数据库D中出现的频率称为项集A的支持度,记为support(A),如果A满足预定义的最小支持度阈值,则称A是频繁项集.
定义2关联规则表示为“A=>B”的蕴涵式,其中A∩I,B∩I,A∩B=φ,A称为规则的前件,B称为规则的后件.D中同时包含A和B的事务数与包含A的事务数的百分比称为关联规则“A=>B”的置信度,其计算公式为:
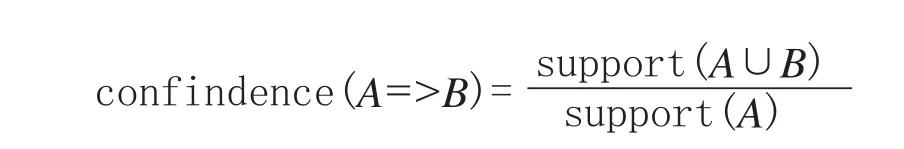
如果A∪B满足最小支持度阈值,confidence(A=>B)满足最小置信度阈值,则称关联规则“A=>B”是强关联规则.
定义3对于任意一个非空集合X,X的全部子集作为元素构成的集合ρ(X)称为X的幂集[9].
定义4对于任意集合X和Y,且X是Y的一个真子集,由Y中所有不属于X的元素构成的集合称为集合X在Y中的补集.
2.2 Hadoop平台的MapReduce模型
Hadoop采用分布式文件系统(简称HDFS)存储数据,一个大数据集被划分多个较小的数据块,这些数据块分别存储在集群内的多个节点上.Hadoop的MapReduce框架采用主/从式结构:主节点称为JobTracker节点,负责将计算任务分配给各个从节点;从节点称为TaskTracker节点,负责执行具体的计算任务.
MapReduce程序使用
(1)Hadoop把数据块的记录解析成
(2)Redcue函数接收
一般的MapReduce数据流如图1所示[10].
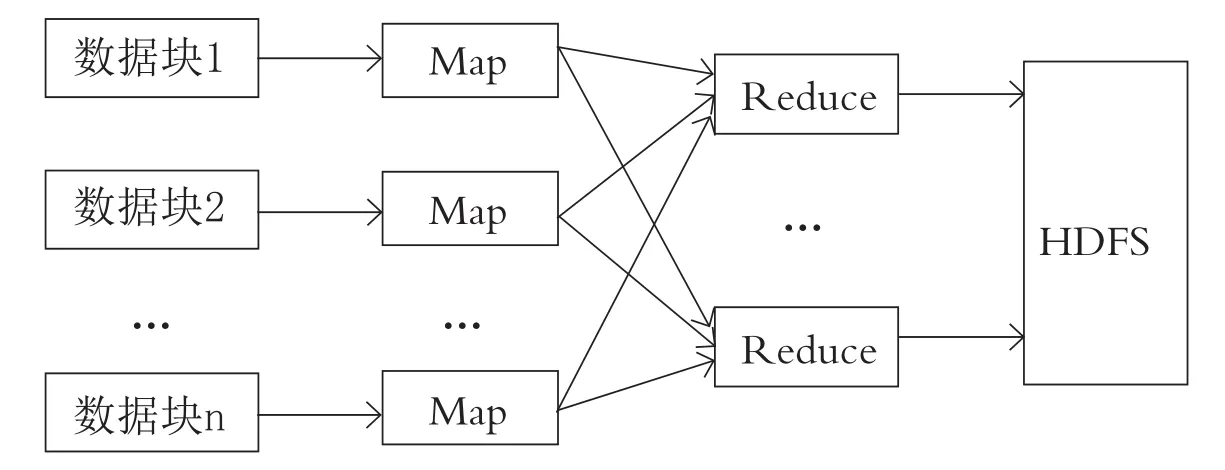
图1 MapReduce的数据流
Map函数输出的数据量往往很大,为了减少Map与Reduce之间传输的数据量,可以定义一个用于将Map输出的中间结果进行合并的Combine函数[11].在MapReduce模型中添加Combine函数后,Map函数产生的结果就输出到本地的Combine函数,Combine函数对key相同的value进行合并或处理,并将产生的结果以list
在一个节点上可以启动1个或多个Map(Reduce)进程去执行Map(Reduce)函数,Map或Combine进程产生的结果输出到哪一个Reduce进程是由Partition分区函数决定的,分区函数返回值一般定义为:hash(key) % nReduce,其中nReduce是集群中Reduce进程的总个数.
3 算法的基本思想及描述
3.1 算法的基本思想
关联规则的挖掘过程可以概括为两个步骤:第一步是从事务数据库中找出所有频繁项集,第二步是根据最小置信度阈值由频繁项集产生强关联规则[10].
在第一步的过程中,为了减少算法执行所需的I/O时间,本文采用幂集求候选项集,只需要扫描事务数据库1次便可找出所有频繁项集.方法如下:对事务T的项集Ik求幂集ρ(Ik),ρ(Ik)中除之外的其他元素即是候选项集.例如:一个事务T的项集Ik={I1,I3,I5},Ik的幂集ρ(Ik)={φ,{I1},{I3},{I5},{I1,I3},{I1,I5}, {I3,I5},{I1,I3,I5}},则事务T包含的所有候选项集为:{I1},{I3},{I5},{I1,I3},{I1,I5},{I3,I5}, {I1,I3,I5}.接下来,Map函数计算候选项集的局部支持度,Reduce函数对局部支持度求和,得到全局支持度,然后根据最小支持度阈值,输出频繁项集及其支持度.
在第二步的过程中,采用幂集和补集求出所有关联规则.方法如下:对频繁项集l的项集Ik求幂集ρ(Ik),ρ(Ik)中除φ和Ik之外的其他元素即是关联规则的前件A,对中除和Ik之外的其他元素求其在Ik中的补集Ic,Ic便是关联规则的后件B.根据最小置信度阈值,就可以得到所有“A=>B”的强关联规则.例如:频繁项集l的项集Ik={I1,I2,I4},Ik的幂集ρ(Ik)={φ,{I1},{I2},{I4},{I1,I2},{I1,I4},{I2,I4},{I1,I2,I4}},求关联规则的过程如下:A={I1},A在Ik中的补集B={I1,I2,I4}{I1}={I2,I4},则得到一条关联规则I1=>I2∧I4.相应的可以求出其他关联规则:I2=>I1∧I4,I4=>I1∧I2,I1∧I2=>I4,I1∧I4=>I2,I2∧I4=>I1.
3.2 算法描述
(1)将事务数据库D分成多个数据子集Di,事务T(T∈Di)解析成 <事务Tid,项集Ik> 键/值对输入Map函数.Map函数计算事务T的候选项集c,将候选项集c及其支持度计数1以

(3)定义一个分区函数Partition:hash(c) % nReduce,其中hash(c)返回候选项集c在候选项集集合中的字典顺序编号,nReduce是集群中Reduce进程的总个数.
(4)Reduce函数计算候选项集c的全局支持度support,如果c满足最小支持度阈值,则将c及其支持度以


(5)主函数从HDFS输出文件中逐一读取频繁项集l及其支持度计数support,并将l添加到链表L的表尾,将support添加到链表S的表尾,使l在L中的索引号与support在S中的索引号一致,以便获取l的支持度support.接下来,使用幂集计算关联规则的前件A,使用补集计算关联规则的后件B,最后输出满足最小置信度的强关联规则,伪代码如下:

4 实验及结果分析
4.1 实验环境与实验数据
使用8台计算机搭建了一个Hadoop集群,其中1台作为JobTracker节点,其余7台作为TaskTracker节点.计算机的硬件和软件配置相同,硬件配置是:Intel Core2 Duo CPU(主频为2.93GHz)、2GB内存、320GB硬盘、100M网卡,安装的软件是:Ubuntu 12.04 LTS(32位)、Hadoop 1.2.1、JDK 1.7.0_51.
采用Java语言编程实现本文算法,使用IBM数据生成器生成9个数据集,如表1所示,其中平均项长是事务包含项的平均个数,总项数是事务数据库中不同项的总个数,数据集db4、db5、db6、db7、db8、db9的事务条数(数据规模)分别是数据集db3的2、3、4、5、6、7倍.
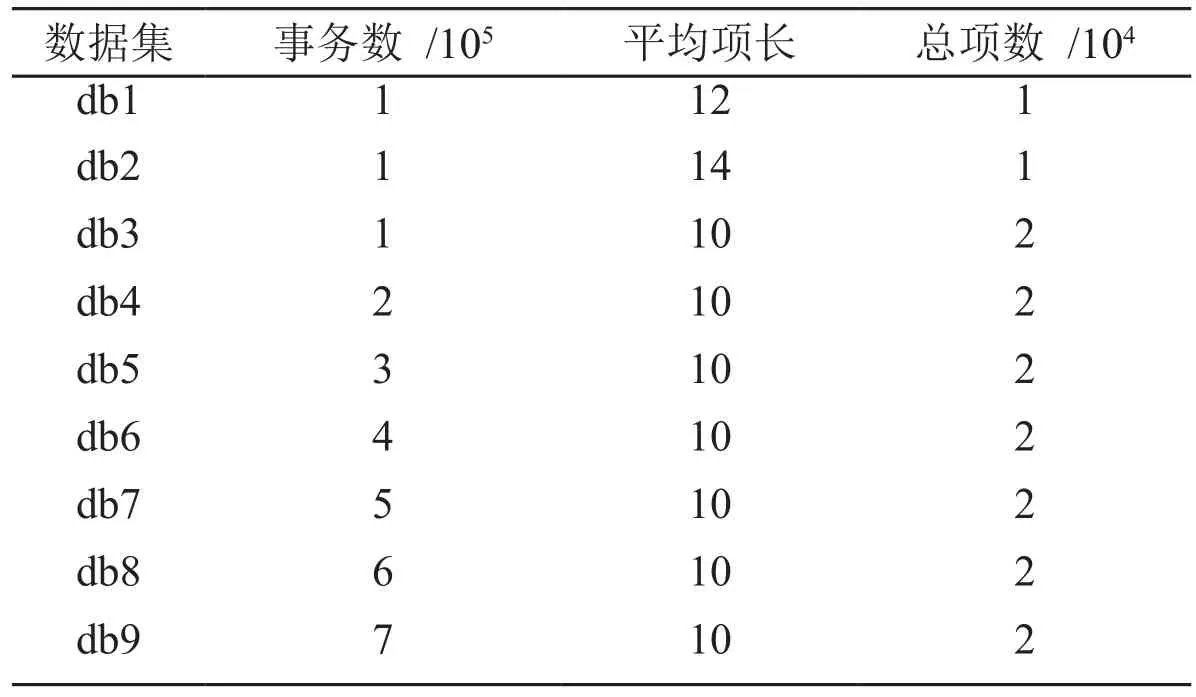
表1 实验数据集
4.2 实验结果与分析
使用两组实验分别测试算法的加速比和数据规模增长性,算法的加速比计算公式如下:
seedup(m)=t1/tm,式中t1、tm分别表示在1个TaskTracker节点、m个TaskTracker节点上运行算法所用的时间[12].
算法的数据规模增长性计算公式如下:
sizeup(DB,m)=tm×DB/tDB,式tm×DB中表示对规模为m×DB的数据集运行算法所用的时间,tDB表示对规模为DB的数据集运行算法所用的时间[12].
(1)加速比实验
使用实验数据集db1、db2测试算法的加速比,最小支持度阈值为30%,最小置信度阈值为50%.算法的运行时间如表2所示,算法的加速比如图2所示.

表2 算法的运行时间
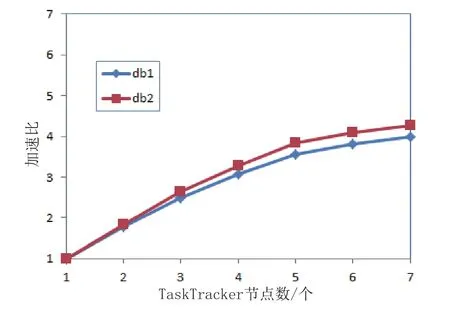
图2 算法的加速比
从图2可以看出,算法对db1、db2都有较好的加速比.从表2可以看出,在事务数相同的情况下,事务的平均项长增长,算法的运行时间也大大增加.这是因为事务的项长增加,则采用幂集求出的候选项集的数量大大增加,计算时间和内存开销也随之增大,可见本文算法适合对平均项长较小的数据集挖掘关联规则.
(2)数据规模增长性实验
使用7个TaskTracker节点,对数据集db3、db4、db5、db6、db7、db8、db9测试算法的数据规模增长性,最小支持度阈值为30%,最小置信度阈值为50%,实验结果如图3所示.
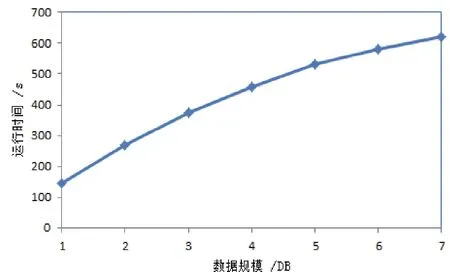
图3 数据规模增长性实验结果
从图3可以看出,在平均项长不变、总项数不变的情况下,随着数据规模的成倍增长,算法的运行时间并没有成倍增长.由于本文算法对数据集一次扫描便可求出所有频繁项集,所需的I/O时间很少,对于大数据集能取得更好的运行效率.可见本文算法有较好的数据规模增长性,能适用于对大数据集进行关联规则挖掘.
5 结语
对大数据进行扫描需要耗费大量的I/O时间,本文从减少I/O时间的角度出发,提出了一种基于MapReduce的关联规则挖掘算法.本文算法在找出所有频繁项集的过程中只需要扫描事务数据库1次,所需的I/O时间很小,能取得较高的运行效率.采用MapReduce模型在多个节点上并行地找出所有频繁项集,缩短了计算时间,能以较快的速度从大数据集中挖掘出所有关联规则.实验结果表明:在平均项长较小的情况下,本文算法具有很好的加速比和数据规模增长性.但是,算法也存在缺点:在平均项长较大的情况下,性能下降很快,这是下一步要解决的问题. ■
Abstract:From the viewpoint of reducing I/O time, according to MapReduce of Hadoop platform of cloud computing, this paper presents an algorithm for mining association rules based on MapReduce. The algorithm uses power set to compute candidate itemsets, and finds all frequent itemsets in parallel with MapReduce model, which scan the transaction database only once. Experimental result shows that the algorithm can achieve a good speedup and data sizeup under the condition that the length of itemset in transaction is not very longer.
Keywords:association rules, MapReduce, cloud computing, Hadoop
[1]王平水.关联规则挖掘算法研究[J].计算机工程与应用,2014,46(30):115-116.
[2]Agrawal R,Srikant R. Fast Algorithms for Mining Association Rules [C]//Proc. of the 20th Intl. Conf. on Very Large Data Bases (VLDB’94) . Santiago,Chile,1994:4 87-499.
[3]Armbrust M,Fox A,Griffith R,et al. Above the Clouds: A Berkeley View of Cloud Computing[R/OL]. UC Berkeley,RAD Laboratory,2009 [2014-07-05]. http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/ EECS-2009-28.html.
[4]李玲娟,张敏.云计算环境下关联规则挖掘算法的研究[J].计算机技术与发展, 2011,21(2):43-46.
[5]Dean J,Ghemawat S. MapReduce:Simplified Data Processing on Large Clusters[C]//Proc. of the 6th Symposium on Operating System Design and Implementation. San Francisco, California, 2004: 137-150.
[6]应毅,刘亚军. MapReduce并行计算技术发展综述[J].计算机系统应用,2014,23(4):1-6.
[7]Apache Hadoop[EB/OL]. The Apache Software Foundation, 2014[2014-07-05]. http://hadoop.apache. org/.
[8]郝晓飞,谭跃生,王静宇. Hadoop平台上Apriori算法并行化研究与实现[J].计算机与现代化,2013,211(3):1-4.
[9]陈自力.一种新的基于幂集的数据挖掘算法[J].甘肃联合大学学报:自然科学版,2011,25(6):65-67.
[10]黄立勤,柳燕煌.基于MapReduce并行的Apriori算法改进研究[J].福州大学学报:自然科学版,2011,39(5):680-685.
[11]周丽娟,王翔.云环境下关联规则算法的研究[J].计算机工程与设计,2014,35(2):499-503.
[12]杨勇,王伟.一种基于MapReduce的并行FP-growth算法[J].重庆邮电大学学报:自然科学版,2013,25(5):651-657.
【责任编辑 谢明俊】
A Algorithm of Mining Association Rules Based on MapReduce
ZHOU Guo-jun
( College of Maths & Information Science, Yulin Normal University, Yulin, Guangxi 537000)
From the viewpoint of reducing I/O time, according to MapReduce of Hadoop platform of cloud computing, this paper presents an algorithm for mining association rules based on MapReduce. The algorithm uses power set to compute candidate itemsets, and finds all frequent itemsets in parallel with MapReduce model, which scan the transaction database only once. Experimental result shows that the algorithm can achieve a good speedup and data sizeup under the condition that the length of itemset in transaction is not very longer .
association rules; MapReduce; cloud computing; Hadoop
An Algorithm of Mining Association Rules Based on MapReduce
ZHOU Guo-jun
(College of Maths & Information Science, Yulin Normal University, Yulin, Guangxi 537000)
TP311
A
1004-4671(2014)05-0128-07
2014-07-11
广西教育厅2014年度广西高校科学技术研究项目(项目编号:LX2014300)。
周国军(1975~),男,湖南宁远人,硕士,玉林师范学院数学与信息科学学院讲师,研究方向:数据挖掘。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
河南水利年鉴(2020年0期)2020-06-09
当代陕西(2019年15期)2019-09-02
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
学苑创造·A版(2018年11期)2018-02-01
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
读者(2017年5期)2017-02-15
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
