
基于判别式分类和重排序技术的藏文分词
2014-02-28 03:30华却才让才智杰姜文斌吕雅娟
中文信息学报 2014年2期
孙 萌,华却才让,才智杰,姜文斌,吕雅娟,刘 群
(1. 中国科学院计算技术研究所 中国科学院智能信息处理重点实验室,北京 100190; 2. 中国科学院大学,北京,100049; 3. 青海师范大学 藏文信息研究中心,青海 西宁 810008)
1 前言
藏文分词是藏文信息处理的基础。在藏文中,词与词之间缺乏间隔标记,和汉语类似都是字符或字的序列,因此藏文信息处理面临和汉语同样的问题,即如何将字符序列切分成合理的词语序列。而现有的藏文分词技术切分的准确率和实用性还有较大提升空间。这一方面是因为藏文编码方案较多并且藏文研究起步较晚,另一方面更是由于藏文本身构词规律的复杂性。
研究者在藏文分词方面提出了很多有效的算法,这些方案大体可以分为两类。第一类是基于藏文特有的语言学知识的规则方法。陈玉忠[1-2]从藏文的字切分特征、词切分特征和句切分特征三个方面深入研究藏文特有的语法接续规则,提出了基于格助词和接续特征的藏文分词方法。祈坤钰[3]分别用格切分、边界符判定和模式匹配算法实现对藏文的三级切分。才智杰[4-5]首先识别格助词,然后将其作为分隔符对句子进行切分,采用最大匹配的算法依次对切分之后的块分词。孙媛[6]在格助词分块的基础上,引入词频信息改进分词质量。刘汇丹[7]提出临界词识别方法和词频消歧方法有效地提高分词正确率。基于规则的藏文分词算法通常需要一个规模足够大的词典,采用最大匹配算法,即以在词典中查到的最长的词条作为句子的切分,算法实现简单,效率较高。这种方法不能很好的处理切分歧义问题,另外对于未登录词的识别能力不强。第二类是基于统计的机器学习方法,用到的统计模型主要是隐马尔科夫模型[8-9],然而相对复杂的藏文构词现象,隐马模型仍然略显简单。而其他统计模型的研究,如最大熵、感知机和条件随机场等模型的应用已经成为汉语分词的主流方向,目前此类模型应用于藏文分词的研究较少,一方面因为藏文分词标注语料库的规模限制,另一方面由于藏文不仅具有与汉语类似的字符顺次拼接的构词方式,在时态上还具有曲折变化,是一种具有逻辑格语法体系的拼音文字。
在汉语分词领域,Xue[10]提出了基于最大熵的汉语分词方法,将分词过程看作对每个字的分类,从而将分词转换成序列标注问题,即对每个字的判别式分类的过程。Collins[11]采用基于感知机的方法进行词性标注,也获得了较高的测试效果。采用基于字标注方法的优势在于: (1)可以融入任何特征以改善分词效果;(2)识别未登录词的能力较强。在基于统计的藏文分词领域,Liu[12]根据藏文构词特点,提出基于条件随机场的藏文分词,然而由于藏文构词规律的复杂性,在汉语上效果良好的序列标注模型不适合直接用于藏文分词。因此本文提出一种基于格助词规则与字符序列标注模型相结合的分词模型,用以精确刻画藏文的构词方式。
藏文的词语通常由一个或者若干音节组成,但是在有些情况下,需要将一个音节切分,和此音节之前或者之后的音节组成词语。本文深入讨论了以藏文字丁、藏文字丁-音节点、音节作为序列标注的基本单位对分词效果的影响。基于字标注方法的分词算法通常采用局部特征,即字级别的特征。非局部特征,比如词语级别的特征,也能显著提高分词效果,但是却很难融入到现有的解码算法中。Jiang[13]提出一种基于词图的重排序算法,融入非局部特征,分词精确率得到较大提升。本文在基于词图的重排序方法上,提出了基于词典惩罚的最短路径算法,用以提高藏文分词的性能。
2 藏文分词框架
针对藏文分词各个层面的处理对象以及问题特点,我们将原子切分、基于感知机解码和构建最短路径这三个模型有机的融合在一个统一的框架下,如图1所示。

图1 藏文分词框架
首先,根据藏文特有的构词规律将句子切分成最小粒度的序列,称之为单元序列;随后,根据感知机模型提供的判别式分类的权重,在单元序列上进行维特比解码,从而生成有向图,并通过查询词典为边赋予不同的权重;最后,通过动态规划算法求解加权有向图中的最短路径,生成最终分词结果。
3 藏文最小构词粒度切分
一个或多个藏文字丁组成一个音节,一个或者多个音节组成词,音节之间由音节点分隔。如图2所示的藏文片段,其中文含义是“处在某一个级别”。

图2 藏文片段
基于序列标注模型的汉语分词过程可以视为在字层面上的组合,而藏文分词的复杂性在于,不能在直接音节层面上进行组合,在有些情况下需要将某个音节拆分,和左边或者右边音节组合,或者独立成词。由于这种组合的灵活性,对于藏文的标注序列的最小构词粒度必须是小于音节的单位。本文设计三种构词粒度的方案以描述其构词规律,如图3所示。
方案1: 藏文字丁。对句子按照每个字丁进行切分,如图3中的切分a。
方案2: 藏文字丁-音节点。不将音节点单独切分出来,而是将其与左边字丁组合,如图3中的切分b。
方案3: 音节。定义特殊格助词表,先按照音节扫描切分句子,一旦音节中含有特殊格助词则匹配相对应的规则切分此音节,如图3中c所示。

图3 三种构词粒度切分方案举例
选择藏文的最小构词粒度的关键,在于将原始句子切分为分词的原子序列。分词的原子指的是分词的最小处理单元,在分词过程中,可以组合成词,但内部不能做进一步拆分。a方案没有考虑任何构词规律,在分词标注语料有限,藏文字丁构词规律较为复杂的情况下,统计模型缺乏足够的知识进行标注学习;b方案在a方案的基础上考虑音节规律,减小了分词时的解码搜索空间;而方案c则最大程度保存了音节的内部结构,却又不会破坏构词粒度的原子性。本文实验部分探讨了在同样规模标注语料库下,采用以上不同的切分策略对最终分词效果的影响。
4 基于感知机的藏文粗切分
对原子序列通过维特比算法进行序列标注,而序列标注的权重由感知机模型训练得到,其中感知机模型是判别式分类模型的一种。Collin[11]提出的基于感知机的序列标注方法是一种在线的学习方法。感知机模型的训练速度快,分类效果好。本文采用平均感知机算法[6]进行句子的粗切分,该算法记录每一次权重的改变,以提高分词系统的稳定性,如算法1所示。
设输入句子的原子序列xi∈X,输出标注序列yi∈Y,X表示训练语料中的所有句子,Y表示对应的标注,其中{b,m,e,s}是标注的符号集合。b表示词的开始,m表示词的内部,e表示词的结尾,s表示单独成词。
算法1 平均感知机算法
1: 输入: 训练实例(xi,yi)
3: Fort← 1…T,i← 1…Ndo

为了尽可能的拟合数据,本文将Jiang[13]设计的特征模板的窗口扩展为4,如表1所示。
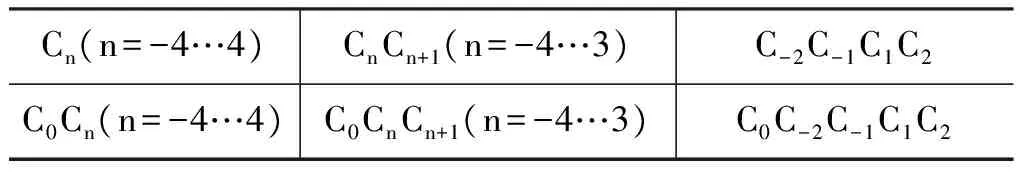
表1 特征模板
5 基于词图的重排序
对于基于感知机的分词,除了通常使用的局部特征,非局部特征的引入也会提升分词的性能。但是,非局部特征要在解码的过程中动态的生成,很难直接将其加入到分类器中,并且引入非局部特征也会影响训练过程中对应特征的调节。在自然语言处理的其他领域也面临着类似的问题,一般的解决方案是使用重排序的方法引入非局部特征。然而,传统方法是在n-best结果基础上进行重排序,n-best所能表示的搜索空间较小,并且储存冗余。感知机模型进行藏文粗切分的过程中保存分词的候选,并将候选分词结果压缩为词图,最后采用基于词图的重排序算法寻找最合适的分词结果。
本文针对藏文本身的特点,提出了基于最短路径的词典惩罚算法,快速从词图中选择一条最优路径。
5.1 词图的生成与剪枝
可以将词图看作一个有向无环图,如图3所示。以构词单元之间的空隙作为图的顶点,顶点之间的连线表示顶点之间的字符组合成词。每条边通过词典获得相应的权重,在词图上寻找一条最短路径,例如: <1,4>,<4,7>。

图3 词图
按照词图顶点的拓扑顺序,对每个节点保存以此节点为终点的所有边,可以生成词图。例如,对于顶点3,保存边<2,3>和<1,3>;对于顶点4,保存边<1,4>、<2,4>和<3,4>。
如果保存解码过程中的所有边,则词图中会包含过多的无用路径,在一定程度上会影响最短路径的生成。本文通过限制每个节点的入度,只保存得分最高的n条边,实现词图的简单剪枝。由于词图结构的特点,即使限制节点入度,同样会包含很多路径信息。
5.2 词典惩罚策略

可能有如下三种切分:


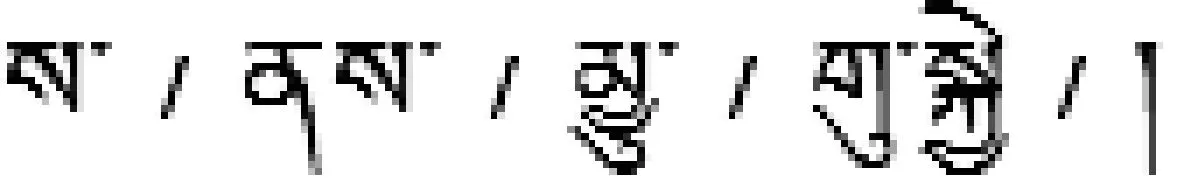
5.3 基于词图的重排序算法
压缩词图经由词典惩罚策略转换为加权有向图,所求的最终分词结果就是从初始节点到结束节点的最短路径。基于单源有向无环图的最短路径问题,可以采用Dijkstra贪心算法求解。 Dijkstra算法的时间复杂度为O(V2),其中V表示图中的顶点数,求解的是单源点到图中所有点的最短路径,而求解基于加权有向图的最短路径问题具有两个不同之处: 首先有向边的源点编号均小于终点编号,有向边的方向具有一致性;其次,只需求解首尾两点的最短路径。因此,本文提出的最短路径算法可以视为Dijkstra算法的简化。算法从左到右依次计算每个节点与源点之间的最短路径,时间复杂度为O(E),其中E表示图中的边,对每个顶点,其每条入边仅被检测一次,所以算法实际总共迭代|E|次。
如算法2所示,v表示词图中的顶点,E表示顶点的连线,即边。其中边的权重是通过查询词典获取,Path记录最短路径的信息,Path[v].previous表示以顶点v为终点的边的起始顶点v′。 每个节点均存储其上一个节点的信息,因此,在求解出最短路径后,可以通过回溯算法快速生成最终的分词结果。
算法2 生成最短路径
1: 输入: 词图L
2:Path← 0
3: Forv∈L.V按照拓扑顺序 do
4: Forv′ 按照拓扑顺序在v之前 do
5:E←
6: IfPath[v].score>Path[v′].score+E.weight
7:Path[v].score←Path[v′].score+E.weight
8:Path[v].previous←v′
9: 输出: 最短路径Path
6 实验及分析
我们现有由青海师范大学提供的12 942条人工分词的藏文句子,共110K词语,语料的领域较为广泛,从一定程度上能够检验系统的鲁棒性和可移植性。从中随机选择500句作为测试集,剩余的作为训练集。
为了研究构词粒度对于基于感知机的藏文分词性能的影响,以基本字丁、基本字丁-音节点和音节为切分单位,本文设计3组实验,实验结果如表2所示。

表2 藏文分词系统的性能
我们发现,构词粒度增大,分词结果的性能也在提升,基于音节的感知机藏文分词系统的F值比基于基本字丁的系统提高了3.3个百分点。可以将藏文分词看作序列标注的过程,增大构词粒度,则序列变短,分类器决策的次数将减少,减少了搜索空间,准确率提高。
但是基于音节的感知机藏文分词系统所达到的F值91.21%仍低于现有的基于规则的藏文分词系统(基线系统)的F值94.87%。我们将以上三组实验看作是基于感知机模型的粗切分,分词结果中往往会出现不成词的切分。我们在基于音节的分词系统上加入基于词图的重排序模块,通过查询词典赋予每条边不同的权重,从而搜索最短路径。最终分词的F值达到96.25%,比基于规则的分词系统提高了1.38个百分点,比基于音节的分词系统提高了5.04个百分点。
7 结论及未来工作
本文提出一种基于判别式模型的藏文分词方法,并探究构词粒度的大小对分词性能的影响,从而确定藏文分词的基本切分粒度。然而,由于非局部特征不能直接用于感知机,我们采用基于词图的重排序算法引入非局部特征,并运用最短路径算法产生最优的分词结果。
在基于统计的汉语分词领域,最大熵和条件随机场也获得了较好的分词效果, 未来我们将对比在同样特征集合下,哪个模型更适于藏文分词。另外,在重排序中我们仅考虑当前词的词典特征,没有考虑到当前词的上下文信息。下一步的工作将研究语言模型在重排序中的作用。
[1] 陈玉忠,李保利,俞士汶,等. 基于格助词和接续特征的藏文自动分词方案[J].语言文字应用,2003(1):75-82.
[2] 陈玉忠,李保利,俞士汶. 藏文自动分词系统的设计与实现[J].中文信息学报, 2003,17(03):15-20.
[3] 祁坤钰.信息处理用藏文自动分词研究[J]. 西北民族大学学报(哲学社会科学版), 2006,(4):92-97.
[4] 才智杰. 藏文自动分词系统中紧缩词的识别[J]. 中文信息学报, 2009,23(1):35-37.
[5] 才智杰. 班智达藏文自动分词系统的设计与实现[J]. 青海师范大学民族师范学报,2010,21(2):75-77.
[6] 孙媛,罗桑强巴,杨锐,等.藏语交集型歧义字段切分方法研究[C]//第十二届中国少数民族语言文字信息处理学术研讨会论文集,2009.
[7] 刘汇丹,诺明花,赵维纳,等. SegT: 一个实用的藏文分词系统[J]. 中文信息学报, 2012, 26(1):97-103.
[8] 苏俊峰,祁坤钰,本太. 基于HMM 的藏语语料库词性自动标注研究[J]. 西北民族大学学报(自然科学版), 2009, 30(1): 42-45.
[9] 史晓东,卢亚军. 央金藏文分词系统[J]. 中文信息学报,2011,25(4):54-56.
[10] Nianwen Xue, Libin Shen. Chinese word segmentation as LMR tagging[C]//Proceedings of the 2nd SIGHAN Workshop on Chinese Language Processing, in conjunction with ACL’03, Sapporo, Japan, 2003: 176-179.
[11] Collins,Michael. Discriminative training methods for hidden markov models: Theory and experiments with perceptron algorithms[C]//Proceedings of the Empirical Methods in Natural Language processing Conference, Philadelphia, America, 2002: 1-8.
[12] Huidan Liu, Minghua Nuo, Longlong Ma, et al. Tibetan Word Segmentation as Syllable Tagging Using Conditional Random Fields[C]//Proceedings of the 25th Pacific Asia Conference on Language, Information and Computation, Singapore, 2011:168-177.
[13] Wenbin Jiang, Haitao Mi, QunLiu. Word lattice reranking for Chinese Word Segmentation and Part-of-Speech Tagging[C]//Proceedings of 22nd International Conference on Comtutational Linguistics, Manchester, UK, 2008:385-392.
猜你喜欢
海外文摘·学术(2022年3期)2022-05-07
外语学刊(2021年1期)2021-11-04
西藏研究(2021年1期)2021-06-09
校园英语·月末(2021年13期)2021-03-15
布达拉(2020年3期)2020-04-13
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
西夏学(2019年1期)2019-02-10
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
长江学术(2016年3期)2016-08-23
