
基于多特征微博话题情感倾向性判定算法研究
2014-02-28 04:51刘全超黄河燕
中文信息学报 2014年4期
刘全超, 黄河燕, 冯 冲
(北京理工大学 计算机科学与技术学院,北京 100081)
1 引言
随着社交网络在中国的蓬勃发展,互联网逐渐形成“以用户为中心,用户参与”的开放式构架理念,用户已经由单纯的“读”网页进入到“写”网页、“共同建设”互联网阶段,因此互联网上产生了海量的用户生成内容(User Generated Content, UGC),尤其是微博的兴起,据报道*第十一届中国网络媒体论坛。,微博在中国已经突破了3亿用户。由于微博消息发布及时性、发布方式多样性[1-2]、书写内容随意性,受到越来越多的人喜爱。
微博在互联网上形成的海量信息表达了人们的各种情感色彩和情感倾向性,例如,喜、怒、哀、乐和批评、赞扬等等。由于越来越多的用户乐于在微博上分享自己的观点或体验,使得这类信息迅速膨胀,仅靠人工的方法难以应对微博海量信息的收集和处理,因此迫切需要计算机帮助用户快速获取和整理这些相关信息。
然而微博话题具有特征稀疏性、奇异性、动态性、交错性等特点。由于短文本信息的长度短,信息量少,可区分度低,因此,在以词为维度的向量空间模型中,呈现出特征稀疏的特点。奇异性指中文网络聊天语言中广泛存在谐音词、简写词、网络语言等,如“稀饭”代表“喜欢”,“杯具”代表“悲剧”,“3Q”代表“谢谢”,用表情符号表示喜、怒、哀、乐等,在传统的新闻媒体中是极少出现的。动态性反映短文本信息流上的流行词语随时间不断变化,并不断有新词出现。交错性指短文本信息流中的会话交错出现,相邻的信息可能讨论不同的话题。本文依据微博的上述特点,对微博话题的情感倾向性进行了分析与研究,获得了一种有效可行的微博话题情感倾向性判断方法。
2 相关工作
该文针对微博的特征稀疏性、奇异性、动态性、交错性等特点,采用不同策略实现微博话题的情感倾向性判定算法,即对描述微博话题的文本内容进行情感倾向性判定。在以往的相关工作中,(Go et al.,2009)基于远距离监督的机器学习算法[3]实现了Twitter信息的情感分类,利用一元语法、二元语法以及一元与二元相结合的方法实现了Twitter信息特征的抽取,分别使用朴素贝叶斯模型、最大熵模型、支持向量机模型进行了情感倾向性判定实验,实验结果正确率均达到80%左右。但是Go等人并未将表达情感的表情符号加以考虑,并且该方法对特定领域(例如电影评论)的Twitter进行情感倾向性分析效果比较明显。Barbosa 和Feng考虑了Twitter的结构特征和词汇信息[4],在三种数据源Twendz*http://twendz.waggeneredstrom.com/、Twitter Sentiment*http://teittersentiment.appspot.com/和Tweetfeel*http://www.tweetfeel.com/的基础上,解决数据的偏置和噪声问题,利用极性标签的组合实现了Twitter的情感倾向性判定,但是该方法对含有对立情绪的句子无法做出判断,其实验结果正确率达到80%左右。Go和Barbosa等人的方法均未考虑Twitter上下文的关系在情感倾向性判断中所起的作用,实际上,没有明显情感倾向的Twitter在一定语境的上下文中是带有情感色彩的。Long et al.利用句法分析器实现对目标的情感倾向性判断[5],并进一步利用Twitter上下文之间的转发、评论等关系,使得Twitter情感倾向性判断正确率达到85.6%。但是Long的算法针对英文Twitter,且未考虑互联网流行的网络用语词汇在情感倾向性分析中的作用。
本文以HowNet提供的情感分析用词语集*http://www.keenage.com/html/c_index.html和台湾大学总结整理的中文情感词典NTUSD*http://nlg18.csie.ntu.edu.tw:8080/opinion/index.html(National Taiwan University Sentiment Dictionary)为基础,通过人工构建表情符号库以及网络用语词典,利用句法分析器、支持向量机实现微博话题的情感倾向性判断[6-7],并结合微博间的转发、评论等关系[2,5]进一步优化微博话题的情感倾向性判定。主要通过三个步骤实现微博话题的情感倾向性判定。
第一步: 实现微博话题的主、客观性判定,即对话题有情感倾向的微博和对话题没有情感倾向的微博进行分类;
第二步: 对话题具有主观性的微博进行极性分类,即对微博中的话题做出正向或者负向的情感倾向性判定;
第三步: 在步骤二中利用微博间的转发、评论等关系进一步优化微博话题的情感倾向性判定算法;
在步骤一和步骤二中分别使用LIBSVM*http://www.csie.ntu.edu.tw/~cjlin/libsvm进行数据训练,完成分类任务。本文组织结构如下所述: 第三部分描述数据构建,包括微博情感符号库构建、情感词典以及社交网络用语词典的构建;为了提高评价目标的覆盖率,第四部分描述评价目标的扩展算法;第五、六部分分别描述不同的情感倾向性判定方法;第七部分描述情感倾向性判定的优化算法;第八部分对实验过程及其实验结果进行了分析;第九部分描述对未来工作的展望,即下一步的工作重点。
3 数据构建
文中实验数据全部来源于新浪微博与腾讯微博,我们常见的在Web上显示的微博如图1所示。图中“#...#”标识出微博话题,“//”标识转发关系,同时也指明用户间的转发顺序,“@”指明了用户,即对“@用户”进行的转发、评论等操作。从图1中我们得知用户李开复对用户蔡文胜的原始博文进行了评论,用户Toby_Bit转发了用户李开复的博文,并进行了评论,其内容表达形式多种多样,例如出现了情感符号。
3.1 情感符号库构建
针对情感符号库的构建,本文提出微博表情库与统计方法相结合的构建方案。前者用于选择微博自带的表情库,如新浪微博、腾讯微博中的表情库。后者用于选择互联网社交媒体中经常使用的表情符号。
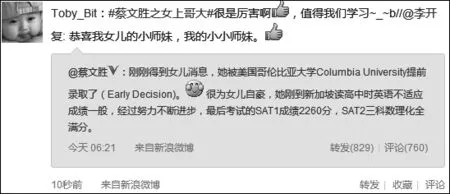
图1 微博实例
首先,构建基于微博自带表情库的情感符号库,由两位实验室人员分别对新浪微博、腾讯微博自带默认表情库进行人工统计分析,获得情感倾向性一致的表情符号,正向情感标注为“+1”,负向情感标注为“-1”,而忽略有歧义的表情符号,共获得118个情感鲜明的情感符号,部分情感符号如表1所示。

表1 微博自带的部分情感符号
其次,为了扩大收集情感符号,特别是社交网络中用户自制的表情符号[8],同样由两位实验室人员搜集、整理出用户自制情感符号,用上述方法分析出情感倾向性一致的表情符号,并进行标注,共获得89个用户自制情感符号,部分用户自制情感符号如表2所示。
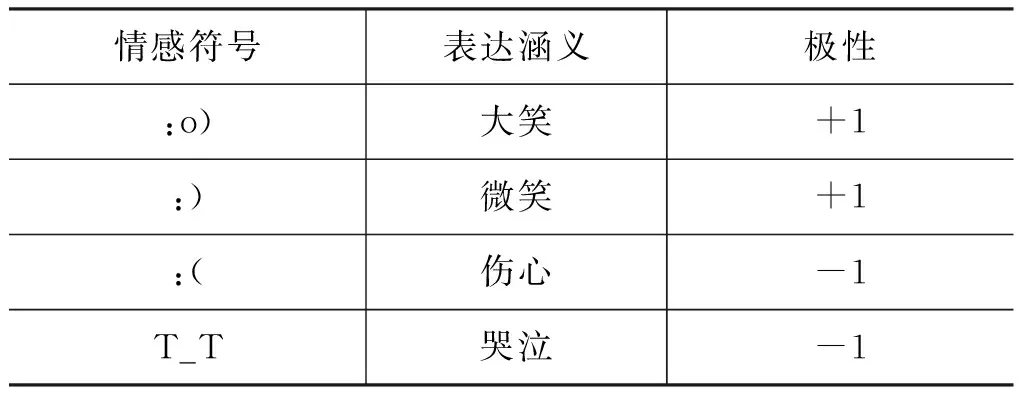
表2 用户自制的部分情感符号
同时,为了保证人工标注的可靠性,采用KA-PPA值对两位人员标注的207个情感符号情感一致性进行评测。KAPPA值适用于计数资料的一致性评测,可由四格表的数据加以计算。实验室甲、乙两位人员标注的数据如表3所示。
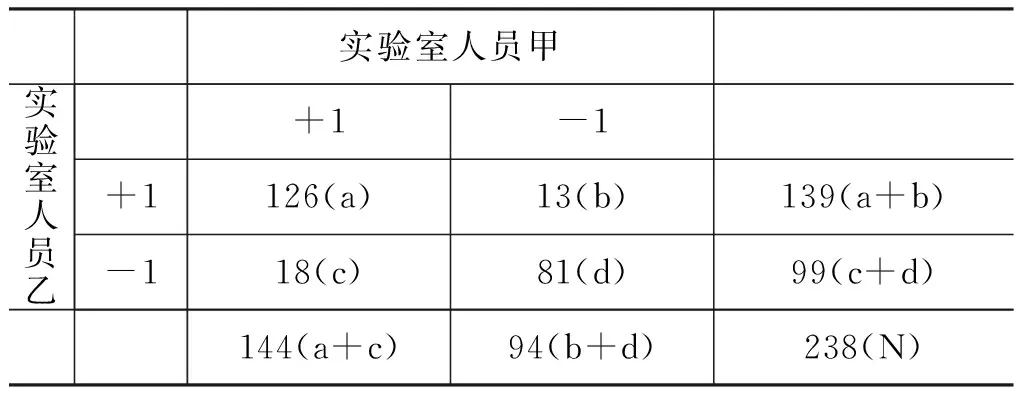
表3 情感符号的情感一致性评测
其中N=a+b+c+d,且有
a表示甲乙两位人员“+1”标注一致的数;
b表示人员甲标注为“-1”例数,人员乙标注为“+1”例;
c表示人员甲标注为“+1”例数,人员乙标注为“-1”例;
d表示甲乙两位人员“-1”标注一致的例数。
根据表3数据,我们计算出KAPPA值为:
≈0.73
KAPPA值为0.73,说明实验室甲、乙两位人员标注的情感倾向一致性是可靠的。
3.2 情感词典以及网络词汇词典构建
情感词是最好的表示文本情感的特征之一[9],丰富的情感词有助于提升情感倾向性判定效果。情感词典和网络词汇词典的构建是微博话题情感倾向性判定的重要基础工作,同时也是一项耗时、耗力的工作。
3.2.1 情感词典构建
为了获得较为丰富的情感词,本文以HowNet提供的情感分析用词语集和NTUSD为基础,采用词汇融合策略,不断丰富情感词典,同时为后来微博中新出现的不同领域的候选情感词提供极性判定方法。
HowNet是一个以汉语和英语词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。自2007年10月起HowNet发布“情感分析用词语集”,包括“中文情感分析用词语集”和“英文情感分析用词语集”,现包含词语共约17 887个,其中中文词语约8 942个。NTUSD是台湾大学总结整理的中文情感词典,包括简体中文和繁体中文两个版本,每个版本包含正向情感词2 812个,负向情感词8 276个。
词汇融合策略[8,10]是以情感倾向比较明显的种子词为基础,根据被测试词与这组种子词的相关紧密程度,通过计算得到情感倾向值。本文分别采用20个具有强烈褒贬倾向且具有代表性的种子词[11],如表4和表5所示。
表4 正向情感种子词集
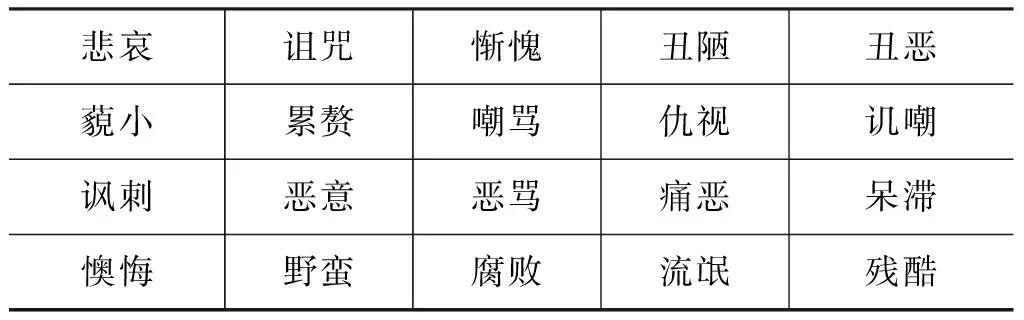
表5 负向情感种子词集
因此词汇融合策略中所采用的词汇情感倾向性计算公式SO-PMI(sentiment orientation-pointwise mutual information)如式(1)所示。
其中,pword、nword分别是正向情感种子词、负向情感种子词;Pset、Nset分别是正向情感种子词集合和负向情感种子词集合;PMI(word1, word2)的计算如式(2)所示,由于语料规模的限制,避免语料规模较小带来的数据稀疏问题,word的概率可以通过Google搜索引擎返回的Hits值占搜索引擎总的索引页面数的比例来计算。当SO-PMI(word)值大于零时情感倾向呈现正向,否则呈现负向情感倾向。
3.2.2 网络词汇词典构建
由于微博话题具有奇异性、动态性等特点,随着时间变化,不断有新词出现,这些新词包括谐音词、简写词、网络语言等[12],所以本文构建网络词汇词典用于支撑微博话题的情感倾向性判定。
网络词汇词典的构建以国家语言资源监测与研究中心*http://www.clr.org.cn/的网络用词为基础,由实验室两位人员通过社交网络搜集、整理,共获得1 430个网络用词,并分别对其进行情感标注,保留情感倾向性标注一致的网络用词1 065个,人工标注的情感一致性达到74.48%,说明许多网络用词在没有上下文的语境下,情感倾向性是有歧义的,我们只保留情感明显的网络用词。部分网络用词及其情感倾向性标注如表6所示。
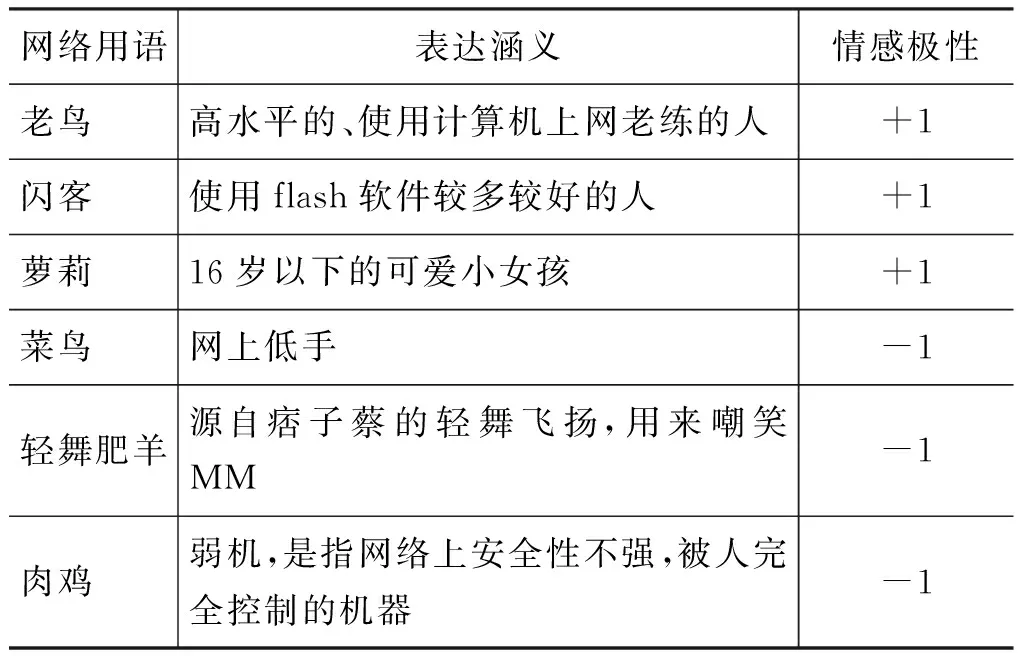
表6 部分网络用词及其倾向性
4 微博话题扩展
人们在评论某一事件或者某一对象时,往往愿意从与其相关的方面说起,间接给目标做出评价,这种现象在产品评论中尤为常见[13]。微博话题扩展过程中,话题词不仅仅只是包含在话题中的词,同时包括与话题相关的关键词。例如微博实例“诺基亚5800屏幕很好,键盘操作也很方便,通话质量也不错”,该微博中对诺基亚5800的评价表现在对诺基亚的屏幕、键盘、通话质量的评价。因此我们需要对话题中评价对象“诺基亚”进行扩展,获得新的评价对象集合{诺基亚5800,屏幕,键盘,通话质量}作为话题词。
在微博集中我们会预定义一些名词短语作为话题词,并在此基础上利用式(2)原理对话题词进行扩展。此时式(2)中P(word1&word2)表示语料中word1和word2在一条微博中共现的概率。式(2)定义了两个词之间的相关性度量,PMI值越大,说明两个词相关性越强,将相关性比较强的名词或名词短语作为扩展目标,加入到话题词集合中,提高评价话题的覆盖率。
5 基于短语路径的微博话题情感解析
汉语句法分析一直被认为是中文信息处理的一个重要技术。其可以分为两种方法: 一种是短语结构解析,即将句子划分成短语,解析句子短语间的层次结构关系[14];另一种是依存结构解析,即解析句子词语间的依存关系[15]。在社交网络用语中,由于内容简短,表达的意思相对集中,不会过于分散,使得情感词往往距离评价目标比较近,因此本文方法一利用短语结构树方法[16],即利用句子短语间的层次结构关系实现评价目标的情感倾向性判定。例如微博实例“恭喜我女儿的小师妹,我的小小师妹”的短语结构树如图2所示。微博中评价目标是“小师妹”,由短语结构树中叶子节点“小师妹”出发,依次寻找短语路径,所谓短语路径是指在短语结构树上链接任意两个短语节点之间的短语结构,如“小师妹—NN—NP—NP—DNP—NP—NP—PN—我”,“小师妹—NN—NP—NP—VP—VV—恭喜”等,最终在所经过的短语路径中会发现正向情感词语“恭喜”,从而判定出“小师妹”的正向情感倾向性,即关于话题“小师妹”的整个微博内容是正向情感。短语结构树中,标点符号将一棵树分成若干个子树,短语路径的寻找从子树开始,如果没有发现情感词,则终止于标点符号。
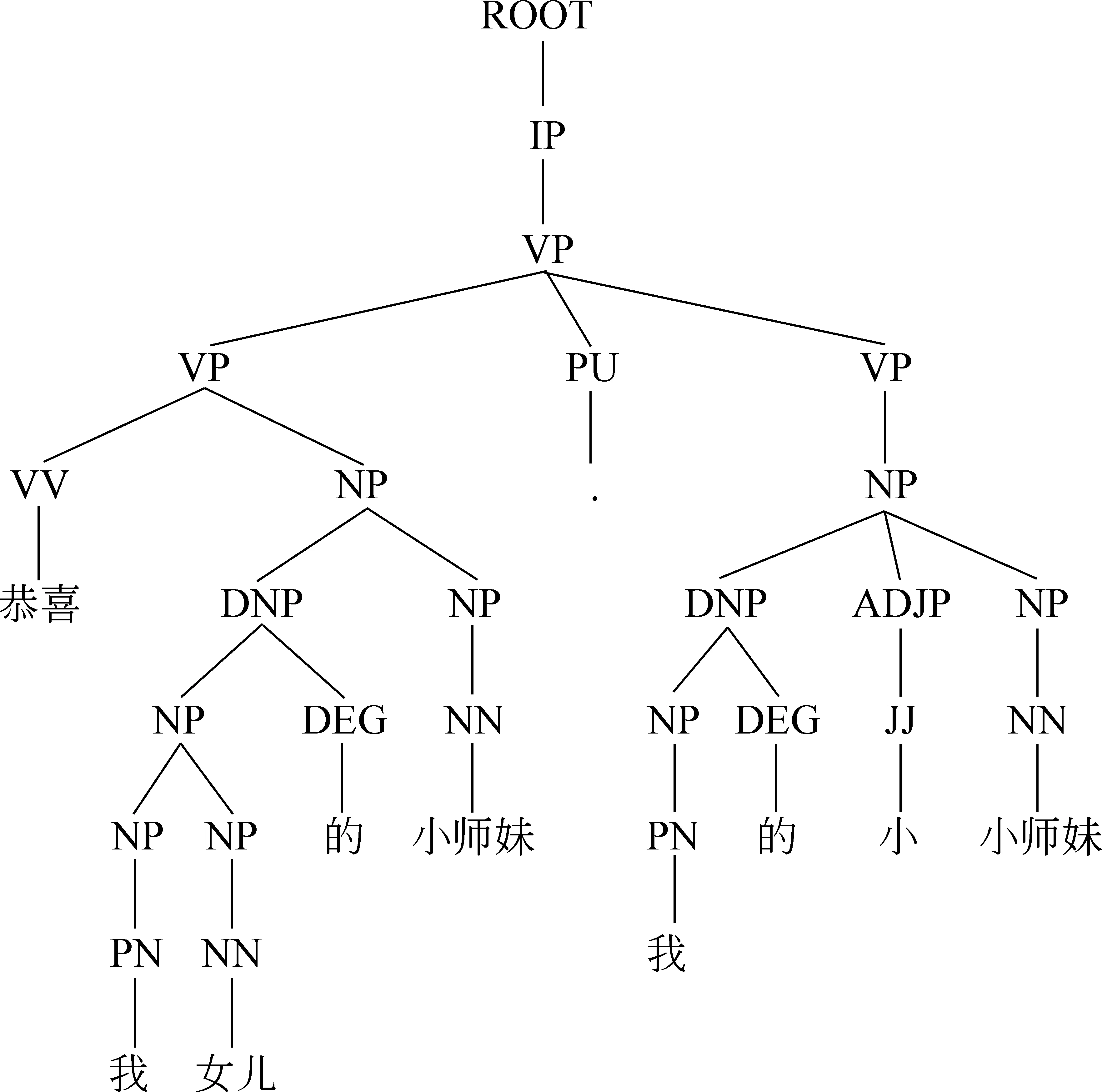
图2 微博实例短语结构树
然而,社交网络用语的多样语言现象使得句子内部情感词的倾向性发生转移。如微博实例“整个店面的装修不是很漂亮”、“演技一点也没进步”、“表演极不自信”,其中“漂亮”、“进步”、“自信”本来都是褒义词,但是前面加上否定词“不是”、“没”、“不”,整个句子的语义就转变为贬义了。本文对上述否定句的处理方法是进行否定规则匹配,被匹配上的词汇褒贬义性质变反,以正确反映语料的观点。首先从2万条微博内容语料库*www.nlpir.org中提取出含有否定意义的句子6 639个,在这些句子中提炼出高频的否定规则127个形成规则集。然后将否定规则与语料中否定句匹配,如果否定中心恰好为有褒贬倾向的词汇,则将其极性取反,以消除情感倾向性转移。
该算法中否定词的获取是通过知网实现的。在知网中选取具有否定意义的义原,例如,{neg|否},{impossible|不会},{OwnNot|无},{inferior|不如}等,从中抽取出包含否定义原的概念,经人工过滤得到21个否定词。
6 微博话题情感分类器构建
本文方法二采用基于有指导的分类方法实现微博话题情感倾向性判定,将情感词联合情感符号、网络用语词汇、主谓关系、动宾关系、定中关系、状中关系、比较关系、否定关系等特征训练分类器来完成微博话题的情感分类。为了解决微博数据的特征稀疏性问题,上述类型特征作为微博话题情感分类的特征是必不可少的。
文本分类常用的分类器包括朴素贝叶斯分类器、最大熵分类器、支持向量机等[3,17-19],Go和Barbosa等人针对Twitter进行情感分类实验,得出支持向量机比其他分类器更适合短文本信息情感分类的结论[17]。利用LIBSVM分类器进行微博话题情感倾向性判定,其采用的特征属性包含两部分,其一是文中第三部分描述的情感符号、网络词汇、情感词等微博内容特征属性,利用统计方法计算出其情感值作为LIBSVM的特征属性值。其二对微博内容进行依存结构解析,如果评价对象与情感词之间存在以下关系,则将下述关系的情感倾向性判定值作为情感分类器的特征属性值。
1) 动宾关系。情感词作为动词,评价对象是动词的宾语,此时根据情感词的情感极性做出评价对象的情感倾向性判断。
2) 主谓关系。情感词作为谓语,评价对象作为情感词的主语,此时根据情感词的情感极性做出评价对象的情感倾向性判断。
3) 定中关系。情感词作为定语,评价对象作为定语中心语,此时根据情感词的情感极性做出评价对象的情感倾向性判断。
4) 状中关系。情感词作为状语,评价对象作为状语中心语,此时根据情感词的情感极性做出评价对象的情感倾向性判断。
5) 比较关系。适用于“A比B情感词”句型,A作为评价对象时,它的情感倾向性与情感词的情感极性保持一致;当B作为评价对象时,它的情感倾向性与情感词的情感极性相反。
6) 情感倾向性转移。情感词与评价对象之间出现情感倾向性转移现象,按照第五部分方法处理。
7 微博话题情感倾向性判定优化算法
由于微博话题具有特征稀疏性、奇异性、动态性、交错性等特点,使得只依赖于微博内容进行情感倾向性分析是有一定局限性的,因此将微博间的关系考虑到情感倾向性分析中,可以进一步优化情感倾向性判定算法,提高情感倾向性判定的正确率。
微博内容是通过转发、评论等方式传播的。微博的转发、评论过程往往是对博主观点认同的过程,他们的情感倾向性往往具有一致性。并且同一人针对同一话题在一定时间段内*实验时以天(24小时)为单位的情感倾向性是不会发生变化的。基于上述三种关系,将给定话题的微博集构造成图[20],如图3所示。图中每一个节点表示一条微博,节点间的圆点线表示同一人所发布关于话题的微博,节点间的实线表示微博间转发关系,节点间的短划线表示微博间评论关系。图中孤立节点则表示与其他微博没有任何关系的微博。
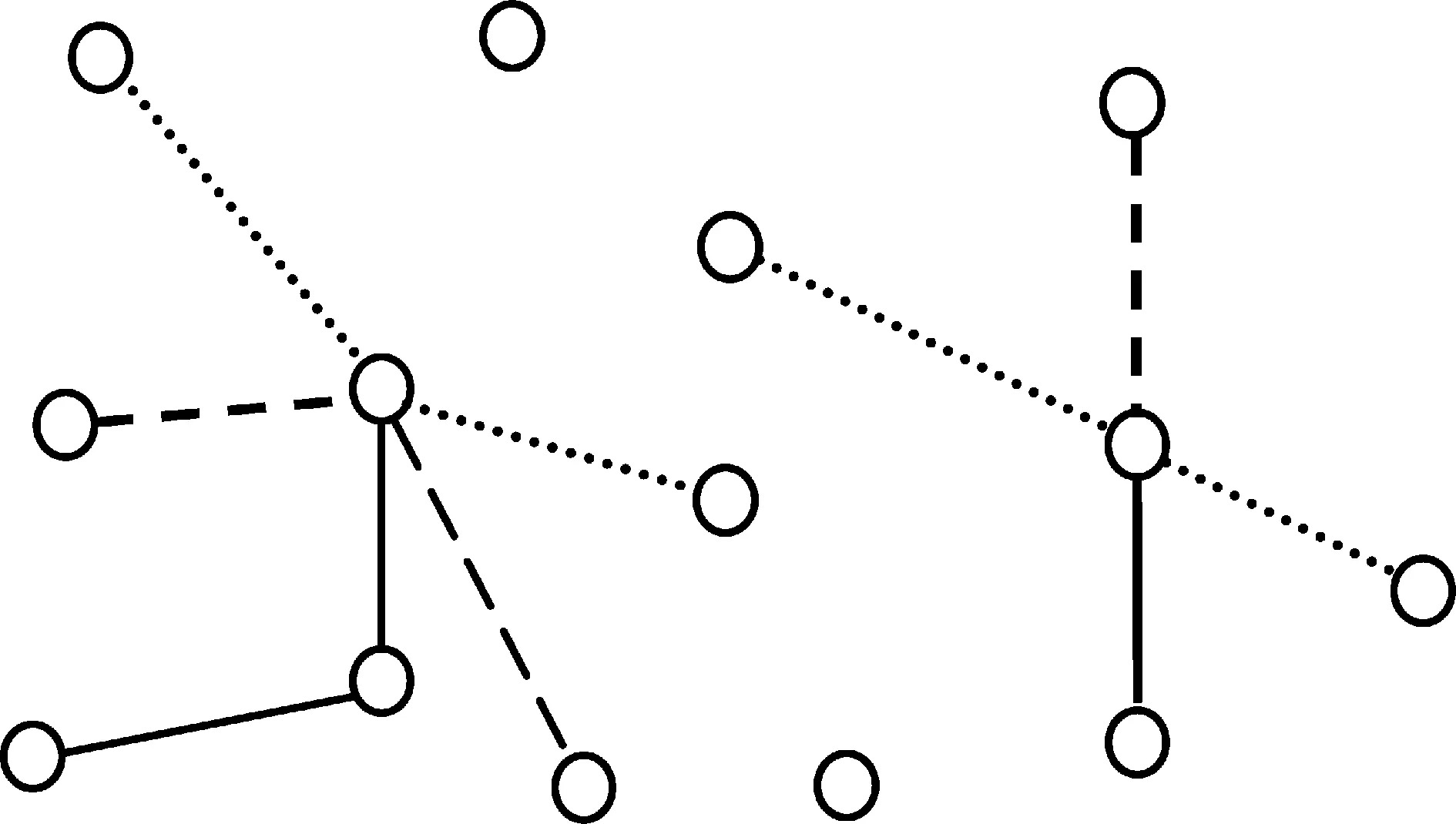
图3 给定话题的微博间关系图
先验假设: 微博的情感倾向性判定只依赖于其内容本身和与其相邻节点的情感倾向性,那么我们构造式(3)数学模型来判断当前节点的情感倾向性。
式(3)中λ(d) 表示节点d的情感倾向性标签,c表示情感倾向性标签的取值,值域为{正向,负向,中立};τ(d) 表示节点d基于内容的特征向量;N(d) 表示与当前节点d相邻的节点;依赖于节点内容特征的情感倾向性记作πc,d=p(λ(d)=c|τ(d)) ,则式(3)简化如下:
依据松弛标记原理[20],以迭代方式求得节点d的最终情感倾向性,即:
式(5)中r为迭代上标,并将p(λ(d)=c∧λ(d′)=c′) 记作φc,c′,则式(5)进一步简写为:
图3关系图中每个节点的初始情感标签是由微博内容的情感特征决定的,即由第六部分方法实现。在拥有转发、评论、同一人发布等关系的微博集中(孤立节点除外),统计微博情感倾向性一致的概率并形成3 × 3(正向、负向、中立)概率矩阵以供迭代使用[20],终止迭代条件是节点的情感标签不再发生变化。
8 实验及其结果分析
8.1 评价指标
微博话题情感倾向性分析的评价指标采用正确率(Precision)、召回率(Recall)、F值(F-measure)以及覆盖率(Coverage),并从微平均和宏平均两个方面进行测评。微平均以整个数据集为一个评价单元,计算整体的评价指标。宏平均以每个话题为一个评价单元,计算在该话题中的评价指标,最后计算所有话题上各指标的平均值。覆盖率是用来度量测试完整性的一个手段,是测试有效性的一个度量,通过覆盖率数据,可以知道测试的是否充分,测试的弱点在哪些方面,进而指导我们去设计能够增加覆盖率的测试用例。
其中,#system_correct表示微博话题情感倾向性判定结果与人工标注匹配的微博数目;#system_proposed表示微博话题情感倾向性判定出的微博总数;#person_correct表示微博话题情感倾向性人工标注的微博数目;#weibo_topic表示话题出现在微博中的微博数目;#weibo_total表示与话题相关的微博集。
8.2 评测数据集与结果分析
本文使用两种数据集进行验证。一种是CCF TCCI主办的NLP&CC 2012会议*http://tcci.ccf.org.cn/公布的中文微博情感分析评测数据集*http://tcci.ccf.org.cn/conference/2012/pages/page04_evares.html,全部来自腾讯微博*http://t.qq.com/,共包括20个话题,每个话题采集大约1 000条微博,共约20 000条微博,其中只有小部分微博具有转发和评论信息。基于微博关系的微博情感倾向性判定算法评测结果如表7所示。
另一种数据集来自新浪微博*http://s.weibo.com/,利用主题网络爬虫针对当下热门话题{iphone5,末日, 切糕, 官二代,中国好声音}五个话题分别爬取2 000条微博,包含了具有转发和评论关系的微博,经过微博内容去重预处理,获得共9 932条。由实验室两位人员对每一条微博进行话题情感倾向性人工标注,其中283条微博话题的主、客观性有歧义,另有603条微博话题的情感正负倾向性有歧义。对于微博话题主、客观性有歧义的,全部假设微博话题是客观性的,这样做利于下一步微博话题情感倾向性的判定。对于微博话题情感正负倾向性有歧义的,采用三人投票法,人工标出微博话题的情感正负倾向性。最终通过人工对微博话题的情感倾向性标注,得到情感为中立的微博1 921条,为正向的微博3 526条,为负向的微博4 485条,并分别用2 000条正向、2 000条负向以及1 000条中立微博作为LIBSVM的训练语料,其余 4 932条作为测试集用。LIBSVM选用RBF核函数,其余参数采用默认值。通过对上述五个话题的4 932条微博进行情感倾向性判定,结果如表7所示。
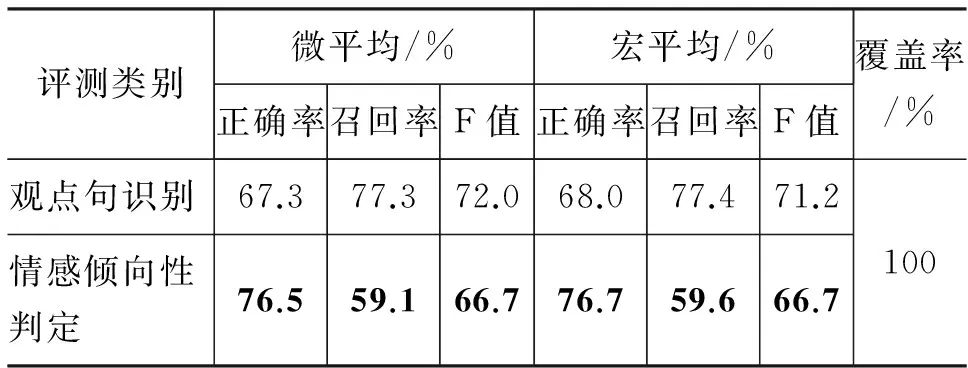
表7 基于微博关系的倾向性判定评测结果
从表8实验结果我们看出,微博话题的扩展与否对微博话题的情感倾向性分析起着至关重要的作用。尤其是对短语路径法判定话题倾向性的影响比较大,这是因为话题词与情感词的距离影响着话题情感倾向性的判定,话题扩展后在很大程度上缩短了话题词与情感词的距离,并且提高了话题词的覆盖率,促进了话题情感倾向性判定的效果。通过表7和表8中基于微博关系的情感倾向性判定实验结果对比,发现本文算法受到微博间关系的影响,当微博集中转发、评论或者同一人发布的微博越多时,算法性能越好。Jiang等人[5]提出的针对tweets倾向性判定算法同样适用于中文,我们用其算法在同样的数据集中进行了验证,但其正确率仅达到83.9%,分析其原因,我们总结出两点: 其一,Jiang等人并未将社交网络中经常用到的网络用语作为情感倾向性判定的依据;其二,Jiang等人设计的算法重度依赖tweet文本内容中的target,但由于数据集中部分微博内容中是没有他们所需的target,从而导致算法性能下降。下面分别描述微博内容特征以及微博间关系对微平均正确率的影响。

表8 情感倾向性判定效果对比
情感词汇在传统媒体(如新闻、博客)中进行情感倾向性分析的作用是比较重要的[21],但是在新媒体(如微博、微信)的情感倾向性分析中,从表9实验结果中看出,网络用语、表情符号等特征的作用大于情感词汇在新媒体中的作用,主要归因于新颖、奇特的网络用语、表情符号比较受青年人的欢迎,在社交网络中使用比较广泛,而青年人又是我国互联网用户的主流人群。
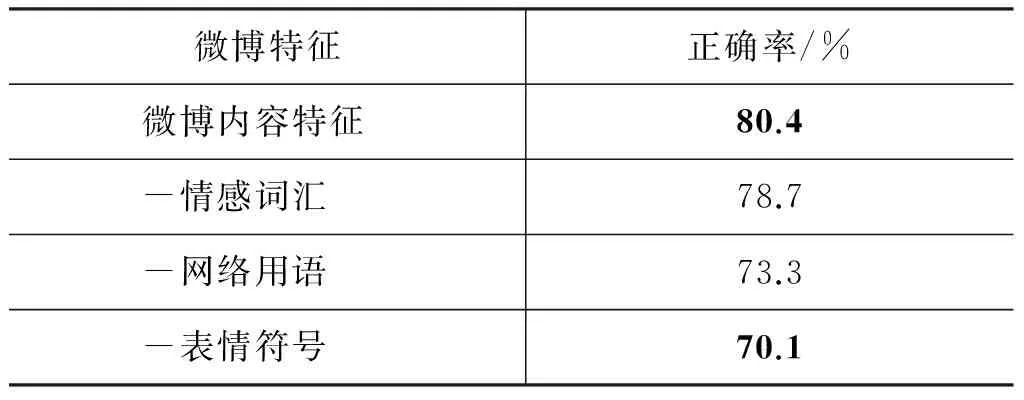
表9 网络用语及表情符号对支持向量机法性能的影响
然而与微博中网络用语、表情符号对情感倾向性分析起着同样重要作用的还有微博间的转发、评论等关系。从图3中可以看出微博集中存在一些孤立节点,这些孤立节点与其他节点没有任何关系,因此基于微博关系的倾向性判定优化算法对这些孤立节点不起作用。表10统计出{iphone5,末日,切糕,官二代,中国好声音}微博集中,拥有转发、评论或者属于同一人发布等关系的微博在微博集中的比重。
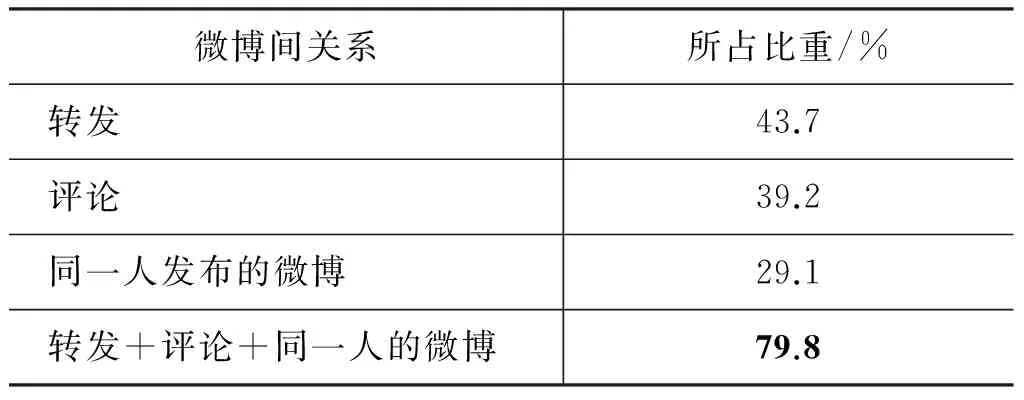
表10 拥有关系的微博在微博集中的比重
根据表10的统计结果,微博集中拥有转发、评论和同一人发布等关系的微博占到79.8%,充分利用这些微博间的关系,可以在很大程度上提高微博话题倾向性判定的正确率。如表11所示,实验结果显示了每一种关系对情感倾向性正确率的影响。

表11 各种关系对倾向性判定的贡献对比
9 总结与展望
微博话题情感倾向性判定是社交网络舆情分析中的研究热点,也是情感倾向性分析中新的研究趋势。针对微博话题扩展、微博内容特征以及微博间多种关系特征,设计不同策略实现微博话题情感倾向性判定,其微平均正确率达到85.3%,微平均F值达到79.4%。本文将来的工作重点会放在以下两个方面:
(1) 微博话题扩展算法。一个完善的话题扩展算法能够改善情感倾向性判定效果。
(2) 微博用户间关注关系以及粉丝数量对微博话题情感倾向性分析的影响。
微博用户层面的关系与微博间的转发、评论等关系有着同样重要的作用,他们同样对微博话题的情感倾向性分析起着积极作用。
[1] Kang J H, Lerman K, Plangprasopchok A. Analyzing Microblogs with affinity propagation [C]//Proceedings of the 1st KDD Workshop on Social Media Analytic. New York: ACM, 2010: 67-70.
[2] 张晨逸, 孙建伶, 丁轶群. 基于MB-LDA模型的微博主题挖掘 [J]. 计算机研究与发展, 2011, 48(10): 1795-1802.
[3] Alec Go, Richa Bhayani, Huang Lei. Twitter Sentiment Classification using Distant Supervision[R]. CS224N Project Report, Stanford, 2009.
[4] Luciano Barbosa, Feng Junlan. Robust Sentiment Detection on Twitter from Biased and Noisy Data [C]//Proceedings of COLING 2010. Beijing, China, 2010:36-44.
[5] Jiang Long, Yu Mo, Zhou Ming, et al. Target-dependent Twitter Sentiment Classification[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. Portland, Oregon, 2011: 151-160.
[6] 徐琳宏, 林鸿飞, 杨志豪. 基于语义理解的文本倾向性识别机制 [J]. 中文信息学报, 2007, 21(1): 96-100.
[7] 夏云庆, 杨莹, 张鹏洲等. 基于情感向量空间模型的歌词情感分析 [J]. 中文信息学报, 2010, 24(1): 99-103.
[8] Turney P D, Littman M L. Measuring praise and criticism: inference of semantic orientation from association [J]. ACM Trans on Information Systems, 2003, 21(4): 315-346.
[9] 杜伟夫, 谭松波, 云晓春等. 一种新的情感词汇语义倾向计算方法 [J]. 计算机研究与发展, 2009, 46(10): 1713-1720.
[10] 王素格, 李德玉, 魏英杰. 基于赋权粗糙隶属度的文本情感分类方法 [J]. 计算机研究与发展, 2011, 48(5): 855-861.
[11] 朱嫣岚, 闵锦, 周雅倩等. 基于HowNet的词汇语义倾向计算 [J]. 中文信息学报, 2006, 20(1): 14-20.
[12] Apoorv Agarwal, Xie Boyi, Ilia Vovsha, et al. Sentiment Analysis of Twitter Data [C]//Proceedings of the Workshop on Language in Social Media (LSM 2011). Portland, Oregon, 2011: 30-38.
[13] 姚天昉, 聂青阳, 李建超等. 一个用于汉语汽车评论的意见挖掘系统[R]. 曹右琦, 孙茂松, 编. 中国中文信息学会成立25周年学术年会论文集. 北京: 清华大学出版社, 2006: 260-281.
[14] 周强, 赵颖泽. 汉语功能块自动分析 [J]. 中文信息学报, 2007, 21(5): 18-24.
[15] Cheng Yuchang, Masayuki Asahara, Yuji Mmtsumotoy. Machine Learning-based Dependency Analyzer for Chinese [C]//Proceedings of the International Conference on Chinese Computing 2005. Singapore: COLIPS Publication, 2005: 66-73.
[16] 赵妍妍, 秦兵, 车万翔等. 基于句法路径的情感评价单元识别 [J]. 软件学报, 2011, 22(5): 887-898.
[17] Adam Bermingham, Alan Smeaton. Classifying Sentiment in Microblogs: Is Brevity an Advantage? [C]//Proceedings of the 19th ACM international conference on Information and knowledge management. Toronto, Ontario, Canada: CIKM’10, 2010: 1833-1836.
[18] Rakesh Agrawal, Sridhar Rajagopalan, Ramakrishnan Srikant, et al. Mining Newsgroups Using Networks Arising From Social Behavior [C]//Proceedings of the 12th international conference on World Wide Web. Budapest, Hungary: WWW’03, 2003: 529-535.
[19] Pang B, Lee L, Vaithyanathan S. Thumbs up? Sentiment Classification using Machine Learning Techniques [C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Philadelphia, PA: Association for Computational Linguistics, 2002: 79-86.
[20] Ralitsa Angelova, Gerhard Weikum. Graph-based Text Classification: Learn from Your Neighbors [C]//Proceedings of the 29th annual international ACM SIGIR conference on research and development in information retrieval. Seattle, Washington, USA: SIGIR’06, 2006: 485-492.
[21] 赵妍妍, 秦兵, 刘挺. 文本情感分析 [J]. 软件学报, 2010, 21(8): 1834-1848.
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
体育科技文献通报(2022年3期)2022-05-23
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
海峡姐妹(2016年2期)2016-02-27
中国卫生(2015年12期)2015-11-10
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
